|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Поиск в словаре и нагруженные деревья
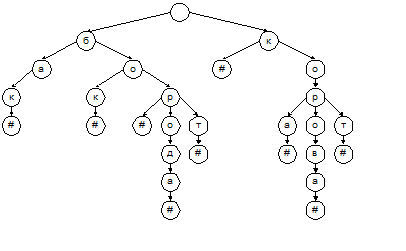
Рассмотрим один важный частный случай задач поиска. Пускай поиск ведется по строковому ключу не слишком большой длины. Практически имеются в виду ключи, являющиеся словами некоторого естественного или искусственного языка, поэтому рассматриваемая задача называется задачей поиска в словаре. Один из важных примеров применения такого поиска – распознавание команд, введенных пользователем с клавиатуры в диалоге с операционной системой или с прикладной программой. Применим для хранения словаря совершенно иную структуру данных, чем использовались в предыдущих разделах. Весь словарь будет представлен деревом, вершины которого (кроме корневой) помечены буквами. Используется также специальный символ «конец слова», который мы будем обозначать знаком #. Подобное представление принято называть нагруженным деревом[6]. На рис. 5.1 показано представление небольшого словаря из 9 слов: «бак», «бок», «бор», «борода», «борт», «к», «кора», «корова», «корт».
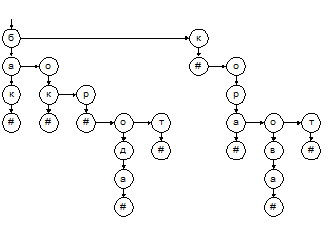
Рис. 5.1. Нагруженное дерево Выполнение поиска по такому дереву понятно без особых пояснений. Отметим только, что вместо привычных сравнений «меньше/больше» здесь используются сравнения «равно/не равно» для очередной буквы ключа. Вставка и удаление слов также делаются без труда. Следует, однако, выбрать подходящую структуру данных для хранения небинарного дерева. Типовой способ преобразования дерева к бинарному виду предполагает, что для каждой вершины один из указателей направлен к «правому брату» вершины, а другой – к ее «старшему сыну». Результат преобразования показан на рис. 5.2.
Рис. 5.2. Бинарное представление нагруженного дерева Довольно трудно провести корректное сравнение поиска по нагруженному дереву с традиционными алгоритмами бинарного поиска по массиву или по дереву. Если время бинарного поиска зависит от числа записей в таблице, то время поиска по нагруженному дереву определяется длиной ключа. С точки зрения расхода памяти нагруженные деревья весьма избыточны (на каждую хранимую букву приходится по два указателя), но, с другой стороны, одинаковые начальные части разных слов хранятся лишь один раз. Удовлетворимся поэтому экспериментальными оценками, которые показывают, что нагруженные деревья все же заметно уступают традиционным структурам данных по памяти, но по скорости поиска превосходят ранее описанные методы и работают наравне с описанными ниже алгоритмами хеширования или даже быстрее. Вопросы и упражнения 1. Дан массив дат A. Для упрощения принято, что номер года и номер дня лежат в пределах от 01 до 10. Выполнить поразрядную сортировку массива. Показать результаты каждого прохода. A = (06.12.03; 09.03.07; 01.01.01; 01.05.01; 10.10.10; 02.05.10; 06.01.03; 07.04.05; 07.11.05; 09.12.06; 09.12.02; 05.12.03). 2. Постройте нагруженное дерево для следующего словаря: «в», «век», «вена», «венок», «вентиль», «вентилятор», «у», «уха», «ухо», «юг». Преобразуйте дерево к бинарному виду. Хеширование Основные понятия хеширования В предыдущих разделах были рассмотрены весьма эффективные алгоритмы сортировки и поиска, причем в подразд. 5.1 показано, что при определенных условиях время сортировки может быть сделано линейным. Казалось бы, пора успокоиться, трудно надеяться на возможность еще большего повышения эффективности. В отношении сортировки это, пожалуй, так и есть, однако оказывается, что использованы еще не все возможности ускорения поиска. Вспомним, что до сих пор мы считали наилучшим возможным алгоритмом поиска процедуру бинарного поиска, выполняющуюся за время порядка O(log(n)). Можно ли добиться лучшего результата? Ответ на этот вопрос следующий. Если речь идет об алгоритме поиска, пригодном для произвольных ключей, т.е. не использующем никаких свойств ключей, кроме возможности их сравнения, то бинарный поиск оптимален. Однако возможны и другие подходы, позволяющие при определенных условиях и для определенных типов ключей добиться значительного ускорения поиска. Основная идея заключается в том, чтобы вместо выполнения поиска как такового попытаться по известному значению ключа сразу вычислить индекс в массиве, по которому должна размещаться запись с данным ключом. Рассмотрим эту мысль более подробно. Пусть в некоторой прикладной задаче поиска используются ключи, принадлежащие множеству допустимых ключей X. В качестве такого множества в конкретной задаче может выступать, например, множество всех двухбайтовых (или четырехбайтовых) целых чисел или множество всех строк длиной не более 20 символов, или множество всех дат в пределах XX и XXI веков, в зависимости от типа и диапазона данных, используемых в качества ключа. Для хранения записей таблицы, среди которых будет производиться поиск, отведем массив из N элементов (будем использовать N большое для размера таблицы в отличие от n малого – числа фактически имеющихся записей). Пусть I – множество значений индексов этого массива. В зависимости от используемого языка и других соображений, I может представлять собой интервал [1 … N] или [0 … N–1], или другой интервал из N чисел. Изначально массив записей пуст, он будет заполняться по мере добавления записей в таблицу. Теперь самое главное: определим на множестве ключей X некоторую функцию h, принимающую значения из множества I. Другими словами, придумаем такую функцию, которая по значению ключа x вычисляет позицию в массиве i = h(x), в которой должна находиться запись с ключом x (если такая запись вообще имеется в таблице). Если такая функция построена, то задача поиска (со вставкой) сводится к вычислению i = h(x) и проверке, присутствует ли в позиции i запись с ключом x или же данная позиция массива пуста и в нее можно вставить новую запись. Как определить, что позиция пуста? В некоторых случаях можно инициализировать поля ключа всех записей каким-то «невозможным» значением, которое не может встретиться как реальный ключ. Более универсальное решение – добавить в каждую запись булевское поле «свободно/занято». При описанном подходе получается, что время поиска вообще не зависит от числа записей, уже имеющихся в таблице. Это время сводится к времени вычисления функции h(x). Подобный подход к организации поиска называется хешированием, функция h – функцией хеширования или хеш-функцией, или функцией расстановки, а массив, в котором размещаются записи, – хеш-таблицей. Однако все не так просто, как может показаться на первый взгляд. Для эффективного использования хеширования следует решить несколько проблем. Главная проблема заключается в следующем. Может ли случиться так, что при попытке занести новую запись в хеш-таблицу будет обнаружено, что данная позиция уже занята другой записью? Другими словами, может ли функция хеширования h(x) принимать одно и то же значение для разных x? Ответ на этот вопрос неутешительный: да, такая ситуация (ее называют коллизией хеширования) вполне возможна, и более того: в большинстве случаев нельзя построить такую хеш-функцию, которая полностью исключала бы коллизии. Причина этого очень проста. Как правило, множество допустимых ключей X значительно больше, чем множество индексов хеш-таблицы I. А раз так, то хотя бы на некоторые значения индекса i должны отображаться несколько разных значений ключа x. Действительно, если в качестве ключа используются, например, четырехбайтовые целые числа, то мощность множества X равна 232 Конечно, из огромного множества допустимых ключей в действительности понадобится только небольшая часть: несколько сотен или тысяч чисел или фамилий, которые реально встретятся в обрабатываемых данных. Но это никак не облегчает проблему, ибо, как правило, заранее неизвестно, какие именно значения ключа понадобятся. Из проблемы коллизий вытекают две конкретные задачи, которые должны быть решены для успешной реализации хеширования. Первая задача – подбор удачной хеш-функции. Хотя ни одна самая хорошая хеш-функция не может совсем исключить коллизии, плохая хеш-функция может значительно увеличить их число. Вторая задача – обработка ситуации, когда коллизия все-таки случилась. Эту задачу обычно называют разрешением коллизий. Ни одна из двух поставленных задач не может быть однозначно решена раз и навсегда, для всех случаев жизни. Выбор наиболее удачного решения зависит от типа и длины ключа, от размера выделенной хеш-таблицы, от предполагаемого максимального количества записей и еще от ряда факторов. Таким образом, выбор конкретной реализации хеширования должен делаться по-новому для каждого разрабатываемого приложения. При этом можно и нужно руководствоваться общими рекомендациями, наиболее важные из которых приведены ниже. Популярное:
|
Последнее изменение этой страницы: 2016-04-11; Просмотров: 714; Нарушение авторского права страницы