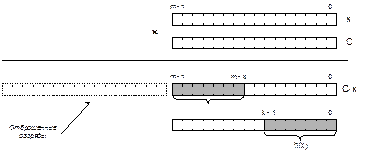|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Способы построения хеш-функций
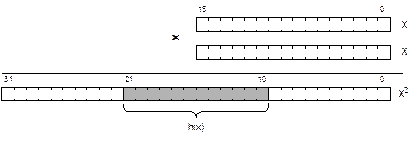
6.2.1. Общие требования к хеш-функциям Прежде всего, сформулируем два требования, которым должна удовлетворять хорошая хеш-функция. Первое требование простое и очевидное. Хеш-функция должна вычисляться быстро. Действительно, замена обычного поиска на вычисление хеш-функции имеет смысл только в том случае, если это вычисление не отнимет больше времени, чем цикл поиска. Хорошей можно считать такую хеш-функцию, вычисление которой требует примерно десятка машинных команд. Чтобы достичь такой скорости, надо, во-первых, выбрать простой алгоритм вычисления, а во-вторых, не пожалеть усилий на оптимизацию кода. Часто вычисление хеш-функции программируют на Ассемблере или с ассемблерными вставками, если же используется язык высокого уровня, то следует, как минимум, очень хорошо понимать, в какие машинные команды будет транслироваться данный фрагмент программы. Второе требование обычно формулируют так: хеш-функция должна хорошо рассеивать значения ключей. Что под этим понимается? Во-первых, функция должна принимать все значения из множества индексов I, причем на каждое значение из I должно отображаться примерно одинаковое количество ключей. Во-вторых, если множество ключей, реально встретившихся в конкретной задаче, неравномерно распределено по всему множеству допустимых ключей X, то эта неравномерность должна устраняться при хешировании. Поясним подробнее. Что понимается под неравномерностью распределения ключей? Если речь идет о числовых ключах, то может, например, оказаться, что большая часть ключей лежит в небольшом диапазоне или что в качестве ключей часто используются «круглые» числа, или, скажем, все ключи – четные числа. Если ключами являются российские фамилии, то можно ожидать много значений, заканчивающихся на «-ов», «-ин», «-ский» и т.п., при этом фамилий на букву «К» наверняка будет намного больше, чем на «Ф» или «Щ». Если ключи – даты рождения студентов, то почти все они будут сгруппированы в пределах одного десятилетия. Во всех этих примерах требуется, чтобы хеш-функция «разбросала» ключи более или менее равномерно по всей хеш-таблице, поскольку любое сгущение значений в некоторой части таблицы приведет к более частым коллизиям и к трудностям при их разрешении. Поскольку заранее редко бывает известно, какого именно вида неравномерности могут встретиться, наиболее разумным является такой выбор хеш-функции, при котором «похожие» значения ключа преобразуются в «непохожие» значения индекса. Значения хеш-функции должны быть «как бы случайны», они не должны сохранять какой-то очевидной связи со значениями ключа. Поэтому методы построения хеш-функций во многом схожи с методами программной генерации псевдослучайных чисел. Рассмотрим наиболее известные методы хеширования числовых ключей. Алгоритм деления Этот алгоритм является самым простым, хотя и далеко не лучшим. Он выражается следующей формулой: h(x) = x mod N. Здесь N – размер хеш-таблицы, так что вычисленное значение индекса будет в пределах от 0 до N–1, как принято в программах на C. Если массив описан от 1 до N (как обычно бывает в Паскале), то нужно еще прибавить к индексу единицу. Вычисление по этой формуле требует выполнения всего одной команды целочисленного деления с остатком. Хотя для большинства процессоров это не самая быстрая команда, требование быстрого вычисления можно считать вполне удовлетворенным. С требованием хорошего рассеивания дело обстоит гораздо хуже. Хотя данная функция покрывает все значения индексов, отображая на каждый из них примерно одинаковое количество допустимых ключей, она плохо справляется с рассеиванием неравномерностей. Во-первых, легко видеть, что соседние (отличающиеся на 1) значения ключей будут почти всегда отображаться на соседние позиции хеш-таблицы. Это уже нехорошо с точки зрения разрешения возможных коллизий. Во-вторых, если значительная часть ключей отстоят друг от друга на расстояние, имеющее общий множитель с размером таблицы N, то число используемых позиций таблицы резко уменьшается, что приведет к частым коллизиям. Поясним сказанное таким примером. Пусть N = 10 000, а значения всех используемых ключей заканчиваются на 0. Очевидно, что тогда и все значения h(x) тоже будут заканчиваться на 0, т.е. будет использоваться лишь 1/10 часть всех позиций таблицы, что приведет к частым коллизиям. Чтобы избежать описанной неприятности, в случае использования алгоритма деления стараются в качестве размера хеш-таблицы выбирать простое число, не имеющее общих делителей ни с какими другими числами. Но даже с этим уточнением данный алгоритм используют лишь в задачах, не требующих особо качественного хеширования. Алгоритм середины квадрата Он работает следующим образом. Значение ключа x возводится в квадрат (с двойной точностью, чтобы избежать переполнения разрядной сетки), а затем из двоичного представления результата вырезается такое количество средних разрядов, которое достаточно для представления индекса таблицы. Суть алгоритма иллюстрируется на рис. 6.1, где принято, что значение ключа есть 16-разрядное число, его квадрат занимает 32 разряда, а для представления индекса используется 12 разрядов.
Рис. 6.1. Выделение середины квадрата ключа Для данного алгоритма, в отличие от предыдущего, в качестве размера хеш-таблицы удобно выбрать некоторую степень двойки, например, 1 024, 4 096, 65 536 и т.п. При этом разряды, вырезанные из середины квадрата (соответственно, 10, 12, 16 разрядов), образуют готовое значение индекса. Почему рекомендуется брать разряды из середины квадрата, а не младшие либо старшие разряды? Потому что на значение средних разрядов в равной степени влияют как младшие, так и старшие разряды ключа. Это позволяет рассеять некоторые виды неравномерностей. Например, если значительная часть ключей – небольшие числа в пределах, скажем, 210, то их квадраты будут в пределах 220, т.е. старшие 12 разрядов будут содержать нулевые значения. И наоборот, если ключами являются числа, кратные некоторой степени двойки, то их квадраты будут содержать много нулей в младших разрядах. Использование средних разрядов позволяет избежать этих неприятностей (если нулей в ключе не слишком много). В вычислительном отношении алгоритм середины квадрата также достаточно экономен. Фактически он требует одной команды целочисленного умножения, а затем команды сдвига средних разрядов вправо и команды конъюнкции для отбрасывания ненужных старших разрядов. Недостатком алгоритма является то, что в случае большого количества нулей в младших или в старших разрядах ключа, результат может содержать много нулей даже в средних разрядах. Алгоритм умножения По сути, он отличается от предыдущего тем, что значение ключа умножается не на себя самого, а на некоторую числовую константу. Алгоритм может быть реализован очень эффективно, если учитывать особенности двоичного представления чисел в компьютере. Первой операцией, которая выполняется в этом алгоритме, является умножение ключа x на константу C с отбрасыванием старших разрядов произведения, не уместившихся в разрядной сетке. Цель этой операции – рассеять ключи по всему множеству допустимых целых чисел. Вторая операция – переход от диапазона всех целых чисел к диапазону индексов хеш-таблицы. Для этого выполняют умножение числа на размер хеш-таблицы N, но из произведения выделяют только те разряды, которые выходят за разрядную сетку целых чисел. Очевидно, что число, образованное этими разрядами, будет находиться в пределах от 0 до N–1, причем, если результат первого умножения был равномерно рассеян по множеству целых чисел, то значение хеш-функции будет так же хорошо рассеяно по множеству индексов. Описанные действия можно записать в виде формул с использованием операций mod и div, однако это намеренно не сделано, чтобы не создавать соблазна использовать mod и div на практике. На самом деле, все гораздо проще, особенно если размер хеш-таблицы N = 2k. При выполнении умножения на константу C старшие разряды произведения просто отбрасываются, а вместо умножения на N с выделением переполняющих разрядов выполняют просто сдвиг числа вправо, так, чтобы оставить только k старших разрядов. Работа алгоритма показана на рис. 6.2.
Рис. 6.2. Хеширование по алгоритму умножения Как видно из рисунка, весь алгоритм сводится к одной операции умножения и одному сдвигу на m – k разрядов вправо. Важную роль в алгоритме умножения играет константа-множитель C. В литературе (например, [5]) можно найти рекомендации по выбору значения C, основанные на глубоком анализе алгоритма с использованием методов теории чисел. Приведем здесь лишь несколько простых советов, позволяющих избежать грубых ошибок при выборе. (Предполагается, что размер хеш-таблицы N = 2k.): · значение C обязательно должно быть нечетным, а еще лучше – простым числом; · не следует выбирать слишком маленькие значения; лучше, если C, по крайней мере, не меньше 1000; · нежелательно также использовать числа, лишь на несколько единиц отличающиеся от одной из степеней двойки, например, такие, как 2 047 (почти равно 211 = 2 048) или 4 099 (близко к 212 = 4 096). Популярное:
|
Последнее изменение этой страницы: 2016-04-11; Просмотров: 1778; Нарушение авторского права страницы