
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Моделирование произвольного закона распределения.
Для получения непрерывных случайных величин с заданным законом распределения существует несколько подходов, но наиболее эффективным по вычислительным затратам и общим является метод обратной функции. Метод обратной функции. Он основывается на следующей теореме: Если случайная величина (СВ) х имеет плотность распределения Р(х), то
2) Решают интегральное уравнение относительно верхнего предела: Здесь для каждой случайной величины ji с равномерным распределением на интервале (0, 1) находится соответствующая величина хi, у которой плотность распределения P(x). Пример. Необходимо получить случайные числа с экспоненциальным законом распределения. Для экспоненциальной случайной величины хi, распределенной по закону
имеем
Пример. Необходимо получить случайные числа с законом распределения
Воспользовавшись приведенным выше алгоритмом, получим
Отсюда
или
Достоинство метода: малые вычислительные затраты при реализации вычисления в аналитическом виде.
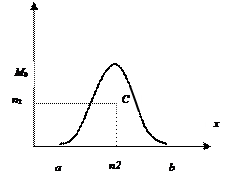
Поэтому в практике моделирования часто пользуются другими, более универсальными и иногда приближенными способами. Метод Неймана. Если случайная величина х определена на конечном интервале (а, в) и плотность ее ограничена Р(х) 1) Генерируются два значения 2) Вычисляются координаты точки С(n1; n2): n1 = a + n2 = 3) Если точка С лежит под кривой необходимого закона распределения Р(х), то в качестве очередного СЧ по заданному закону Р(х) выбирают n1, а если над кривой, то пара Достоинством метода является его высокая надежность и применимость к любому закону распределения. К недостатку следует отнести большие вычислительные затраты. Приближенный метод кусочной аппроксимации функции плотности распределения. Пусть требуется получить последовательность случайных чисел с функцией плотности Алгоритм реализации метода сводится к следующим шагам: 1. Генерация случайного равномерно распределенного числа 2. С помощью этого числа случайным образом выбирается интервал 3. Генерируется число 4. Вычисляется случайное число Достоинством этого приближенного метода является небольшое число операций, так как операция масштабирования (2) выполняется только один раз перед моделированием, и количество операций не зависит от точности аппроксимации, т.е. от количества интервалов m.
|
Последнее изменение этой страницы: 2017-03-15; Просмотров: 553; Нарушение авторского права страницы
 подчиняется равномерному закону распределения в интервале (0, 1) независимо от вида P(x). Отсюда вытекает способ моделирования случайных чисел х с произвольной плотностью вероятности Р(х). Алгоритм:
подчиняется равномерному закону распределения в интервале (0, 1) независимо от вида P(x). Отсюда вытекает способ моделирования случайных чисел х с произвольной плотностью вероятности Р(х). Алгоритм: 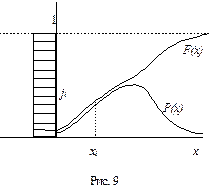 1) Моделируют СВ ji с равномерным законом распределения в диапазоне (0, 1).
1) Моделируют СВ ji с равномерным законом распределения в диапазоне (0, 1).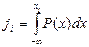 . Значение верхнего предела хi и будет СВ по закону Р(х). Если Р(х)=0 при х< х0, то вместо
. Значение верхнего предела хi и будет СВ по закону Р(х). Если Р(х)=0 при х< х0, то вместо  нижний предел можно заменить на х0. Графически эта процедура представлена на рис. 9.
нижний предел можно заменить на х0. Графически эта процедура представлена на рис. 9.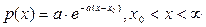
 откуда
откуда  .
.
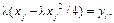
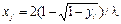
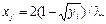

 Недостаток: не все законы распределения можно представить в аналитическом виде. Приходится прибегать к численным методам решения, что увеличивает машинное время на получение каждого случайного числа. Даже в тех случаях, когда интеграл берется в аналитическом виде, получаются формулы, содержащие действия логарифмирования, извлечения корня и т.п., которые приводят к увеличению вычислительных затрат.
Недостаток: не все законы распределения можно представить в аналитическом виде. Приходится прибегать к численным методам решения, что увеличивает машинное время на получение каждого случайного числа. Даже в тех случаях, когда интеграл берется в аналитическом виде, получаются формулы, содержащие действия логарифмирования, извлечения корня и т.п., которые приводят к увеличению вычислительных затрат. (рис. 10), то можно использовать следующий алгоритм:
(рис. 10), то можно использовать следующий алгоритм:  и
и  случайной величины, равномерно распределенной на интервале (0, 1).
случайной величины, равномерно распределенной на интервале (0, 1). (b - a);
(b - a);  Mo.
Mo.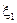 и
и  отбрасывается и выбирается новая пара.
отбрасывается и выбирается новая пара. возможные значения которой ограничены интервалом (a, b). Представим
возможные значения которой ограничены интервалом (a, b). Представим 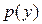 в виде кусочно-постоянной функции, т.е. разобьем интервал (a, b) на m интервалов (рис. 11) и будем считать
в виде кусочно-постоянной функции, т.е. разобьем интервал (a, b) на m интервалов (рис. 11) и будем считать  на каждом интервале постоянной. Тогда случайную величину
на каждом интервале постоянной. Тогда случайную величину  можно представить в виде
можно представить в виде  где
где  - абсцисса левой границы k-го интервала;
- абсцисса левой границы k-го интервала; 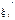 - случайная величина, возможные значения которой располагаются равномерно внутри k-го интервала, т.е. считается равномерной. Обычно разбивают (a, b) на
- случайная величина, возможные значения которой располагаются равномерно внутри k-го интервала, т.е. считается равномерной. Обычно разбивают (a, b) на  интервалы так, чтобы вероятность попадания в любой интервал
интервалы так, чтобы вероятность попадания в любой интервал  была постоянной, т.е. не зависела от номера интервала k:
была постоянной, т.е. не зависела от номера интервала k: 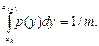 (2)
(2) из интервала (0, 1).
из интервала (0, 1). .
. и масштабируется с целью приведения его к интервалу
и масштабируется с целью приведения его к интервалу 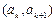 , т.е. домножается на коэффициент
, т.е. домножается на коэффициент  .
. .
.