
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Обработка и анализ результатов моделирования
При выборе методов обработки результатов моделирования существенную роль играют две особенности машинного эксперимента с моделью. 1) Вероятностное моделирование на ЭВМ требует большого числа прогонов модели и хранения большого числа статистических данных. Для решения этой проблемы используют специальные рекуррентные алгоритмы обработки, которые позволяют по ходу моделирования вычислять оценки, при этом большое число экспериментов позволяет пользоваться достаточно простыми асимптотическими формулами. 2) Сложность ВС и моделей делает невозможным давать априорно суждение о законах распределения характеристик модели, поэтому при моделировании используются непараметрические оценки и оценки моментов распределения, а не сами распределения. Рассмотрим некоторые удобные для программной реализации методы оценки распределений при достаточно большом объеме выборки. Математическое ожидание и дисперсия случайной величины
где f(x) – плотность распределения случайной величины Так как плотность распределения априори неизвестна, то определить эти моменты при проведении эксперимента нельзя, поэтому приходится использовать некоторые оценки моментов при конечном числе реализаций N. В качестве таких оценок используются
К качеству оценок, полученных в результате статистической обработки результатов моделирования, предъявляются следующие требования: 1) Несмещенность оценки - равенство математического ожидания оценки определяемому параметру 2) Эффективность оценки - минимальность среднего квадрата ошибки данной оценки 3) Состоятельность оценки - сходимость по вероятности при При реализации на ЭВМ сложных моделей при большом числе прогонов получается значительный объем информации. Поэтому необходимо так организовать процесс вычислений и хранения результатов моделирования, чтобы оценки искомых характеристик формировались постепенно по ходу моделирования и без специального запоминания всей информации. Рассмотрим более экономичные формулы вычисления оценок: а) расчет вероятности наступления события А. В качестве оценки для искомой вероятности p=P(A) используется частота наступления события m/N, где m - число свершений события А; N - общее число исходов. Такая оценка вероятности является состоятельной, несмещенной и эффективной. В памяти ЭВМ достаточно одной ячейки, где накапливается число m, при условии, что N задано заранее; б) закон распределения. Область возможных значений случайной величины разбивается на n интервалов. Затем накапливается количество попаданий случайной величины в эти интервалы mk, где в) среднее значение. Накапливается сумма возможных значений случайной величины г) оценка дисперсии. В качестве оценки можно использовать выражение д) оценка корреляционных функций. Для двух случайных величин с возможными значениями
Последнее выражение может вычисляться при небольшом числе запоминаемых значений. При обработке результатов моделирования часто возникают следующие задачи: определение эмпирического закона распределения случайной величины, проверка однородности распределений, сравнение средних значений и дисперсий переменных, полученных в результате моделирования. Эти задачи являются типовыми задачами на проверку статистических гипотез. Задача определения эмпирического закона распределения – наиболее общая из перечисленных. В этом случае по результатам эксперимента на ЭВМ: 1. Находят значения выборочного закона распределения FЭ(y) (или функции плотности) и выдвигают нулевую гипотезу HO, что полученное эмпирическое распределение согласуется с каким-либо теоретическим распределением. 2. Проверяют эту гипотезу HO с помощью статистических критериев согласия (например, Колмогорова, Пирсона, Смирнова и т.д.). 3. Для принятия или опровержения гипотезы выбирают некоторую случайную величину U, характеризующую степень расхождения теоретического и эмпирического распределения. Закон распределения этой случайной величины зависит от закона распределения исходной случайной величины и числа реализаций N при статистическом моделировании. 4. Если вероятность расхождения теоретического и эмпирического распределений |
Последнее изменение этой страницы: 2017-03-15; Просмотров: 473; Нарушение авторского права страницы
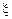 соответственно имеют вид
соответственно имеют вид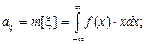
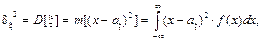
 , принимающей значение x.
, принимающей значение x.
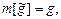 где
где 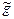 - оценка параметра g.
- оценка параметра g. , где
, где 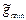 - рассматриваемая оценка,
- рассматриваемая оценка,  - любая другая оценка.
- любая другая оценка. к оцениваемому параметру
к оцениваемому параметру 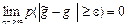 .
.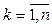 . Оценкой для вероятности попадания случайной величины в интервал с номером k служит величина
. Оценкой для вероятности попадания случайной величины в интервал с номером k служит величина 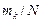 . Необходимо фиксировать n значений mk, т.е. требуется иметь n ячеек памяти;
. Необходимо фиксировать n значений mk, т.е. требуется иметь n ячеек памяти; 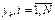 . Тогда среднее значение
. Тогда среднее значение 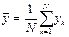 . Требуется всего лишь одна ячейка для накапливаемой суммы.
. Требуется всего лишь одна ячейка для накапливаемой суммы.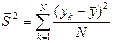 , но непосредственное вычисление по этой формуле нерационально, так как здесь используется среднее значение, которое изменяется в процессе накопления и неизвестно в момент промежуточных вычислений. Более рационально использовать выражение
, но непосредственное вычисление по этой формуле нерационально, так как здесь используется среднее значение, которое изменяется в процессе накопления и неизвестно в момент промежуточных вычислений. Более рационально использовать выражение 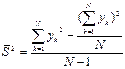
 и накапливать две суммы.
и накапливать две суммы.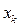 и
и  корреляционный момент
корреляционный момент или
или  .
.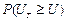 велика в понятиях применяемого критерия согласия, то проверяемая гипотеза о виде распределения HO не опровергается. Выбор вида теоретического распределения F(y) проводится по графикам (гистограммам) FЭ(y).
велика в понятиях применяемого критерия согласия, то проверяемая гипотеза о виде распределения HO не опровергается. Выбор вида теоретического распределения F(y) проводится по графикам (гистограммам) FЭ(y).