
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Потоков в системе управления
На предпроектной стадии разработки АСОИУ важно выделить возможные узкие места в проектируемой системе обработки информации данной организации. Это позволит оптимально (рационально) распределить средства вычислительной техники по подразделениям, обеспечить должную загрузку технических средств и гарантировать решение всех управленческих задач в требуемые сроки. Пусть организация состоит из
В общем случае входной поток первичной информации имеет трендовую, сезонную и циклическую составляющие, а также на него могут влиять случайные изменения с нулевым математическим ожиданием и постоянной дисперсией. Поэтому
где:
Принципиально важно, что объем информационного потока, передаваемого от подразделения Рассмотрим с формально - логической точки зрения процесс обработки информации в подразделении Это можно записать так:
Если, однако, пропускная способность подразделения
Поэтому в динамике, т.е. с учетом временного фактора, равенство (2) примет вид:
Равенство (4) гарантирует получение всего требуемого, т.е. «положенного», объема выходной информации за определенный период времени и то лишь в том случае, если подразделение Для формализации введем следующие переменные: - - Тогда, если интервал времени
Поделив выражение (5) на ∆ t при ∆ t→ 0, получим:
Дифференциальное уравнение (6) определяет динамику изменения объема необработанной в подразделении Так как поток входной информации складывается из первичной информации, поступающей из внешней среды, и информационных потоков из других подразделений, то с учетом ранее введенных обозначений можно записать
где Поскольку в действительности
Введем еще одни обозначения. Обозначим через Так как вся вновь созданная в подразделении
Теперь можно определить структуру модели. Основные соотношения из (6), (7), (8) и (9) следующие:
где Wp(t) определяется формулой (1). Будем считать заданными функции Тогда для определения эндогенных (внутренних) n2+2n переменных модели, т.е. функций
имеем Поскольку система уравнений (10) – (12) является неопределенной, то представляет интерес постановка задачи как оптимизационной. Пусть:
Теперь решение вопроса о выборе рациональной организации наращивания пропускных способностей подразделений организации по выпуску информации, при критерии минимума совокупных затрат, может быть сведено к решению задачи математической теории оптимального управления:
Здесь Т – горизонт планирования, а Рассмотренный вариант модели соответствует полностью распределенной обработке данных в организации, т.к. условиями (17) задаются ограничения на пропускные способности каждого подразделения, чем неявно предполагается возможность перераспределения технических средств между ними. При централизованном варианте СОД условия (17) должны быть заменены на:
где Кроме того, вместо системы функций
и требуют переопределения функции Функционал (13) предполагает оптимизацию основных переменных по критерию минимума совокупных затрат. Возможна другая постановка задачи, если в качестве критерия эффективности СОД выбрать минимизацию времени, необходимого для выпуска информации по задачам заданного множества подразделений. Введем множество Р΄ подразделений, выпускающих конечную информационную продукцию. Тогда, если множество Р˝
а ограничения (20) должны быть заменены на
где c(t) – лимит на текущие затраты учреждения в период t, k(t) – лимит на капитальные затраты учреждения. Смысл функционала (24) состоит в том, чтобы свести к минимуму величину необработанной информации в тех подразделениях, от которых требуется наиболее оперативное решение задач. Все перечисленные выше изменения не выводят задачу из класса задач теории оптимального управления. Поэтому как аналитическое исследование, так и численное ее решение можно получить известными методами и алгоритмами. Лекция 7 4.4. Структурный анализ систем средствами IDEF-моделирования Общие положения Постоянное усложнение производственно-технических и организационно-экономических систем – фирм, предприятий, производств, и др. субъектов производственно-хозяйственной деятельности – и необходимость их анализа с целью совершенствования функционирования и повышения эффективности обусловливают необходимость применения специальных средств описания и анализа таких систем. Эта проблема приобретает особую актуальность в связи с появлением интегрированных компьютеризированных производств и автоматизированных предприятий. В США это обстоятельство было осознано еще в конце 70-ых годов, когда ВВС США предложили и реализовали Программу интегрированной компьютеризации производства ICAM ( ICAM - I ntegrated C omputer A ided M anufacturing), направленную на увеличение эффективности промышленных предприятий посредством широкого внедрения компьютерных (информационных) технологий. Реализация программы ICAM потребовала создания адекватных методов анализа и проектирования производственных систем и способов обмена информацией между специалистами, занимающимися такими проблемами. Для удовлетворения этой потребности в рамках программы ICAM была разработана методология IDEF ( I CAM Def inition), позволяющая исследовать структуру, параметры и характеристики производственно-технических и организационно-экономических систем (в дальнейшем, там, где это не вызывает недоразумений – систем ) Методология IDEF в настоящее время поддерживается семейством из 11 стандартов, отражающих различные аспекты моделирования систем. Мы ограничимся тремя технологиями моделирования, а именно методом функционального моделирования IDF0, методом описания бизнес-процессов IDF3 и методом построения диаграмм потоков данных DFD. Своим появлением семейство стандартов IDEF во многом обязано появившейся в 80-х гг. технологии автоматизированной поддержки разработки информационных систем CASE (ComputerAidedSoftwareEngineering). До настоящего времени эта технология с успехом применяется при разработке разнообразного программного обеспечения. Однако в последнее время CASE-технологии приобретают все большее распространение для моделирования и анализа деятельности предприятий, предоставляя богатый набор возможностей для оптимизации или, в терминах CASE, реинжиниринга технологических процедур, выполняемых этими предприятиями – бизнес-процессов. Метод функционального моделирования IDEF0, ранее известный как технология структурированного анализа и разработки (StructuredAnalysisandDesignTechnique – SADT), был разработан компанией SofTech, Inc. в конце 60-х гг. как набор рекомендаций по построению сложных систем, которые предполагали взаимодействие механизмов и обслуживающего персонала. Значительная часть SADT была принята ВВС США как часть их программы интегрированной компьютерной поддержки производства (IntegratedComputer-AidedManufacturing – ICAM) в конце 70-х гг. Эта технология, переименованная в IDEF0, довольно быстро стала стандартом технологии моделирования деятельности в министерстве обороны США. В 1993 г. группа пользователей IDEF (IDEFUsersGroup, в настоявшее время SocietyofEnterpriseEngineering – SEE), совместно с Национальным институтом стандартов и технологии (NationalInstituteofStandardsandTechnology – NIST) предприняли попытку создания документированного стандарта для IDEF0, который мог бы использоваться как военными, так и гражданскими департаментами правительства США. Этот стандарт был опубликован как федеральный стандарт обработки информации (FederalInformationProcessingStandard – FIPS). Несколько независимо, но с использованием аналогичных подходов технология DFD (DataFlowDiagrams – диаграммы потоков данных) завоевала популярность для структурной разработки (а впоследствии и структурного анализа) проектов построения информационных систем. Диаграммы потоков данных во многом аналогичны моделям IDEF0 и могут быть использованы при проектировании информационных систем, например, после разработки моделей анализа IDEF0. Стандарт IDEF3 был специально разработан для закрытого проекта ВВС США. Это технология получения описания деталей процесса от экспертов в предметной области и разработки таких моделей процессов, в которых важно понять последовательность выполнения действий и взаимозависимости между ними. Подход SADT относится к классу формальных методов, используемых при анализе и разработке систем. Несмотря на то, что вполне допустима независимая разработка функциональных моделей, методология SADT предполагает ведение структурированного проекта анализа, в процессе которого происходит их создание. В дополнение к функциональному моделированию SADT структурный анализ предполагает построение информационных моделей данных и диаграмм состояний (State-TransitionDiagrams – STD), которые моделируют поведение системы во времени. Основной принцип SADT состоит в том, что тщательный анализ системы обусловливает получение возможного оптимального решения. Использование SADT автоматически приводит к необходимости сбора и обработки значительного количества информации о системе. Традиционно такая информация собирается аналитиком посредством формализованного опроса экспертов предметной области – людей, владеющих информацией о механизме функционирования системы в целом или ее частей. С течением времени некоторые эксперты освоили технологию моделирования, что привело к появлению IDEF3-технологии получения знаний от экспертов. Однако роль системного аналитика в проектах SADT оставалась ключевой. Часто разработка моделей применяется для документирования ситуации, сложившейся к определенному моменту (модели " как есть" – «asis»). Впоследствии они применяются при создании новых моделей функционирования системы (модели " как должно быть" – «tobe»), а также для проверки моделей «tobe», с тем, чтобы удостовериться, что предлагаемые изменения действительно повлекут улучшение функционирования системы. Модели «tobe» используются также для планирования загрузки частей системы; калькуляции бюджета и распределения ресурсов; при построении плана реорганизации системы, определяющего действия по переводу системы из состояния «asis» в состояние «tobe». |
Последнее изменение этой страницы: 2019-03-29; Просмотров: 293; Нарушение авторского права страницы
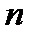 подразделений, имеющих взаимные информационные связи. Каждому подразделению
подразделений, имеющих взаимные информационные связи. Каждому подразделению  поставим в соответствие следующую совокупность функций:
поставим в соответствие следующую совокупность функций:  – входной поток первичной (внешней) информации, поступающей в подразделение
– входной поток первичной (внешней) информации, поступающей в подразделение 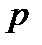 в момент времени
в момент времени  ;
;  – информационный поток из подразделения
– информационный поток из подразделения  данной организации в подразделение
данной организации в подразделение  .
. , (1)
, (1)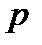 в момент времени
в момент времени  ;
;  – трендовая составляющая потока;
– трендовая составляющая потока;  – сезонная составляющая потока;
– сезонная составляющая потока;  – циклическая составляющая потока;
– циклическая составляющая потока;  – случайная составляющая потока, причем полагают, что
– случайная составляющая потока, причем полагают, что 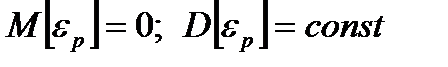 .
. к подразделению
к подразделению  для последующей обработки, является эндогенной для рассматриваемой системы величиной, зависящей от совокупного объема информации, поступившего для обработки в подразделение
для последующей обработки, является эндогенной для рассматриваемой системы величиной, зависящей от совокупного объема информации, поступившего для обработки в подразделение  , укомплектованности его кадрами и оснащенности средствами вычислительной техники.
, укомплектованности его кадрами и оснащенности средствами вычислительной техники.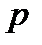 , которое будем считать «черным ящиком», преобразующим входную информацию
, которое будем считать «черным ящиком», преобразующим входную информацию  (совокупный объем входной информации, который поступил в подразделение
(совокупный объем входной информации, который поступил в подразделение  ) в выходную информацию
) в выходную информацию  .
. (2)
(2) , т.е.
, т.е.  таков, что будет справедливо следующее неравенство:
таков, что будет справедливо следующее неравенство: 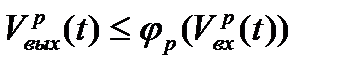 .
.  (3)
(3) . (4)
. (4) обладает определенными вычислительными ресурсами в течение зависящего от величины этих ресурсов времени от поступления «порции» входной информации.
обладает определенными вычислительными ресурсами в течение зависящего от величины этих ресурсов времени от поступления «порции» входной информации. – объем входной информации, который может быть обработан в подразделении
– объем входной информации, который может быть обработан в подразделении 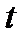 ,
,  – совокупный объем информации, поступившей в подразделение
– совокупный объем информации, поступившей в подразделение  .
. достаточно мал, то можно записать, что прирост, не обработанной за время
достаточно мал, то можно записать, что прирост, не обработанной за время  информации, равен:
информации, равен:  (5)
(5) (6)
(6) информации.
информации. , (7)
, (7) - количество информации, поступившей в подразделение
- количество информации, поступившей в подразделение  из других (n – 1) подразделений.
из других (n – 1) подразделений.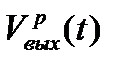 – это объем информации, который является продуктом работы подразделения
– это объем информации, который является продуктом работы подразделения  , то можно записать:
, то можно записать:  (8)
(8) функции, характеризующие объем информации, передаваемой от подразделения
функции, характеризующие объем информации, передаваемой от подразделения  .
.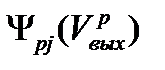 , то можно записать:
, то можно записать: 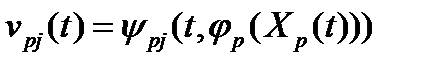
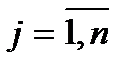 (9)
(9)
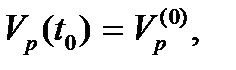
 ,
, 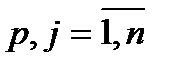 (12)
(12) (они определяется структурой и назначением подразделений организации) и функции
(они определяется структурой и назначением подразделений организации) и функции 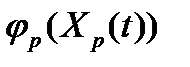 (они определяет общий объем выходной, т.е. созданной информации от количества обработанной входной информации).
(они определяет общий объем выходной, т.е. созданной информации от количества обработанной входной информации). – объемы информации, передаваемой от одного подразделения к другому,
– объемы информации, передаваемой от одного подразделения к другому,  дифференциальных уравнений (10) и
дифференциальных уравнений (10) и 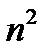 обычных уравнений (12).
обычных уравнений (12).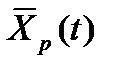 – предельная пропускная способность подразделения p в момент времени t. Ее величина соответствует полной загрузке персонала и технических средств данного подразделения;
– предельная пропускная способность подразделения p в момент времени t. Ее величина соответствует полной загрузке персонала и технических средств данного подразделения;  – предельная пропускная способность подразделения в начальный момент времени;
– предельная пропускная способность подразделения в начальный момент времени; 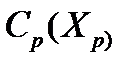 – заданная функция величины затрат на обеспечение пропускной способности подразделения p в размере X единиц информации в единицу времени. Эти затраты складываются из заработной платы сотрудников данного подразделения и средств, необходимых для технического обслуживания ПЭВМ, другой вычислительной и оргтехники, а также затрат на сопровождение ПО;
– заданная функция величины затрат на обеспечение пропускной способности подразделения p в размере X единиц информации в единицу времени. Эти затраты складываются из заработной платы сотрудников данного подразделения и средств, необходимых для технического обслуживания ПЭВМ, другой вычислительной и оргтехники, а также затрат на сопровождение ПО; 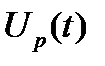 – прирост максимальной пропускной способности подразделения в период t. Отрицательная величина соответствует продаже или выходу из строя тех или иных технических средств, увольнению или болезни сотрудников и т.д.; т.е.
– прирост максимальной пропускной способности подразделения в период t. Отрицательная величина соответствует продаже или выходу из строя тех или иных технических средств, увольнению или болезни сотрудников и т.д.; т.е. 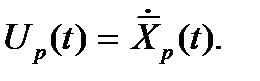
 – заданная функция зависимости величины дополнительных капиталовложений при изменении пропускной способности подразделения
– заданная функция зависимости величины дополнительных капиталовложений при изменении пропускной способности подразделения 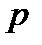 на
на 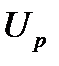 единиц.
единиц.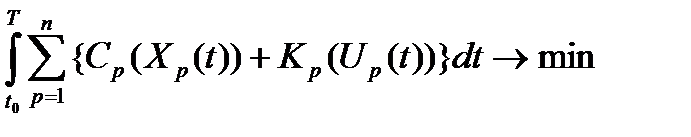 (13)
(13)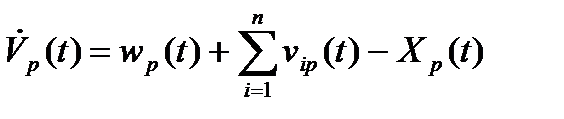 ,
, 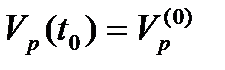 ,
,  ,
,  (16)
(16) ,
,  ,
,  ,
,  ,
,  – ограничения на величину «задолженности» подразделения р по обработке информации. Введение ограничений (20) необходимо для обеспечения формального требования неотрицательной величины необработанной информации, т.к. обработка информации «впрок» до ее получения невозможна. Ограничение сверху на Vp(t) объясняется требованием завершения обработки информации в срок по всем цепочкам процессов ее преобразования.
– ограничения на величину «задолженности» подразделения р по обработке информации. Введение ограничений (20) необходимо для обеспечения формального требования неотрицательной величины необработанной информации, т.к. обработка информации «впрок» до ее получения невозможна. Ограничение сверху на Vp(t) объясняется требованием завершения обработки информации в срок по всем цепочкам процессов ее преобразования.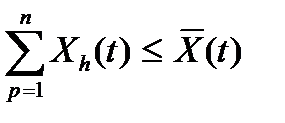 , (21)
, (21)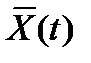 – мощность специализированного вычислительного подразделения (объем информации, который может быть обработан ВЦ учреждения при максимальном уровне загрузки средств вычислительной техники).
– мощность специализированного вычислительного подразделения (объем информации, который может быть обработан ВЦ учреждения при максимальном уровне загрузки средств вычислительной техники). , Up(t) должна рассматриваться лишь пара функций
, Up(t) должна рассматриваться лишь пара функций  , (22)
, (22) , (23)
, (23) и Kp(U).
и Kp(U). Р΄ подразделения, которые должны обеспечить наиболее оперативный выпуск информации, то функционал задачи принимает вид:
Р΄ подразделения, которые должны обеспечить наиболее оперативный выпуск информации, то функционал задачи принимает вид:  (24)
(24)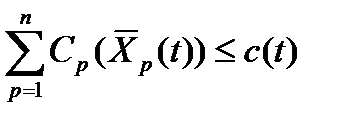 (25)
(25) (26)
(26)