
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Специальные реляционные операции
1. Выборка (сокращенное название операции - Θ (тета) - выборка):
Θ - выборкой из отношения S по атрибутам X и Y называется отношение, имеющее тот же заголовок, что и отношение S, и тело, содержащее множество всех кортежей отношения S таких, для которых проверка условия «XΘY» дает значение «истина». Ясно,что атрибуты X и Y должны быть определены на одном и том же домене, а операция на этом домене должна иметь смысл. На практике эта операция используется, как правило, в модификации, когда вместо X или Y указано скалярное значение, чаще всего в форме S WHERE X Θ C, где C - литеральная константа. В результате выполнения этого оператора получается «горизонтальное» подмножество исходного отношения. Пример 3. Пусть задано отношение S (поставщики) S
Результатом выполнения операции S WHERE Город = «Томск», будет отношение
В указанной форме оператор выборки включает только простое сравнение. Однако, благодаря тождествам: 1. S WHERE Q1 AND Q2 ≡ (S WHERE Q1) INTERSECT (S WHERE Q2) 2. S WHERE Q1 OR Q2 ≡ (S WHERE Q1) UNION (S WHERE Q2) 3. S WHERE NOT Q ≡ S MINUS (S WHERE Q) оператор выборки можно расширить до формы, в которой условие в выражении WHERE будет содержать произвольное число логических сочетаний простых сравнений. 2. Проекция. Проекцией отношения S по атрибутам X1, X2, …, Xn и обозначаемой как S[X1, X2, …, X n ], называется отношение с заголовком {X1, X2, …, Xn}и телом, содержащим множество всех кортежей {X1:x1, X2:x2, …, Xn:xn} таких, для которых в отношении S значение атрибута X1 равно x1, атрибута X2 равно x2, …, атрибута Xn равно xn. Пример 4. Результатом выполнения операции S [Фио] для отношения S предыдущего примера будет отношение
Таким образом, операция проекции строит «вертикальное» подмножество искомого отношения, то есть, подмножество, получаемое исключением всех атрибутов, не указанных в операторе, с последующим удалением дублируемых кортежей. Замечание. Некорректное применение операции проекции может привести к потере информации; для нашего примера такая ситуация могла бы возникнуть, если в отношении S хранились бы сведения о двух разных поставщиках с одинаковой фамилией. 3. Естественное (экви) соединение. Пусть отношения S и P имеют заголовки{X1, X2, …, Xm, Y1, Y2, … , Yn} и {Y1, Y2,… , Yn, Z1, Z2, … , Zp, соответственно, причем атрибуты {Y1, Y2, … , Yn}по именам и доменам в обоих отношениях совпадают. Рассмотрим три совокупности {X1, X2, …, Xm}, {Y1, Y2, … , Yn} и { Z1, Z2, … , Zp} как три составных атрибута {X}, {Y} и {Z}. Тогда естественным соединением отношений S и P S JOIN P называется отношение с заголовком {X, Y, Z} и телом, содержащим множество всех кортежей {X:x, Y:y, Z:z} таких, для которых в отношении S значение атрибута X равно x, атрибута Y равно y, а в отношении P значение атрибута Y равно y, а атрибута Z равно z. 5. Деление. Пусть заголовки отношений S (делимое) и P (делитель) имеют вид{X1, X2, …, Xm, Y1, Y2, … , Yn}и {Y1, Y2, … , Yn},соответственно, причем атрибуты {Y1, Y2, … , Yn}в обоих отношениях представлены одинаковыми именами и определены на одних и тех же доменах. Будем рассматривать выражения{X1, X2, …, Xm} и {Y1, Y2, … , Yn}как два составных атрибута {X} и {Y}. Тогда результатом деления отношения S на отношение P, обозначаемое как S DEVIDEBY P, называется отношение с заголовком {X} и телом, содержащим множество всех кортежей{X:x} таких, что для каждого xЄX существует множество кортежей {X:x, Y:y} отношения S таких, у которых множество составляющих {Y:y} включает все кортежи {Y:y} отношения P. Или нестрого: результат содержит такие X-значения из отношения S, для которых соответствующие Y-значения включают все Y-значения из отношения P. Запросы к базе данных, включающей отношения S, P, и SP, могут быть реализованы следующими цепочками операций реляционной алгебры. Запрос 1. Получить имена поставщиков, поставляющих деталь «Колено» (((SP JOIN P) WHERE Назв _ дет = « Колено ») JOIN S) [ Фио ] Запрос 2. Получить имена поставщиков, поставляющих все детали. ((( SP [Ном_пост, Ном_дет]) DEVIDEBY ( P [Ном_дет])) JOIN S ) [Фио] Запрос 3. Получить имена поставщиков, которые не поставляют деталь «Кран». ( S [Ном_пост,Фио] MINUS ((( SP JOIN P ) WHERE Назв_дет=«Кран») JOIN S ) [Ном_пост,ФИО]) [Фио] Учитывая, что каждый экземпляр схемы отношения можно представить как значение некоторой переменной, выполнение этого запроса может быть реализовано следующей иллюстративной программой:
T 1 = S [Ном_пост, Фио]; T2 = SP JOIN P; T3 = T2 WHERE Назв _ дет = « Кран »; T4 = T3 JOIN S; T5 = T4[ Ном _ пост , Фио ]; T6= T1 MINUS T5; T7 = T6[ Фио ]. Замечание. Если посмотреть на общий обзор реляционных операций, то видно, что домены атрибутов результирующего отношения однозначно определяются доменами отношений-результатов. Однако с именами атрибутов результата не всегда бывает все так просто. Например, представим себе, что у отношений-операндов операции прямого произведения имеются одноименные атрибуты с одинаковыми доменами. Каким должен был бы быть заголовок результирующего отношения? Поскольку заголовок - это множество, в нем не должны содержаться одинаковые элементы. Но и потерять атрибут в результате недопустимо. А это значит, что в этом случае вообще невозможно корректно выполнить операцию прямого произведения. Аналогичные проблемы могут возникать и в случаях других двуместных операций. Для их разрешения в состав операций реляционной алгебры вводится операция переименования. Ее следует применять в любом случае, когда возникает конфликт именования атрибутов в отношениях-операндах одной реляционной операции. Тогда к одному из операндов сначала применяется операция переименования, а затем основная операция выполняется уже безо всяких проблем.
10.Перечислите достоинства и недостатки реляционных систем. К числу наибольших достоинств реляционного подхода можно отнести: · наличие небольшого набора абстракций, которые позволяют сравнительно просто моделировать большую часть распространенных предметных областей и допускают точные формальные определения, оставаясь интуитивно понятными; · наличие простого и в то же время мощного математического аппарата, опирающегося главным образом на теорию множеств и математическую логику и обеспечивающего теоретический базис реляционного подхода к организации баз данных; · возможность ненавигационного манипулирования данными без необходимости знания конкретной физической организации баз данных во внешней памяти. Среди основных недостатков реляционной модели в настоящее время выделяют: · слабая система типов данных; этим системам присуща некоторая ограниченность (прямое следствие простоты) при использовании в так называемых нетрадиционных областях применения (наиболее распространенными примерами являются системы автоматизации проектирования), в которых требуются предельно сложные структуры данных, · невозможность адекватного отражения семантики предметной области; другими словами, возможности представления знаний о семантической специфике предметной области в реляционных системах очень ограничены, · сложности интеграции в новые технологические среды, которые основаны главным образом на объектных моделях. Современные исследования в области постреляционных систем главным образом посвящены именно устранению этих недостатков (см. раздел 8.). КОНТРОЛЬНЫЕ ВОПРОСЫ ПО РАЗДЕЛУ «Навигационные модели данных» 1. Сформулируйте основные понятия иерархической модели. Перечислите ее основные. Основные понятия. Основным типом логической структуры, поддерживаемой иерархическими СУБД, является иерархическая (древовидная) структура (или просто иерархия). Иерархическая структура определяется на соответствующих типах записей согласно схеме базы данных (дереву определений, типу дерева). В этом дереве типы записей являются узлами, а дуги представляют иерархические связи («исходный-порожденный», «род-вид», «элемент-класс» и т.п.) между узлами дерева различных уровней. Тип дерева состоит из одного «корневого» типа записи и упорядоченного набора (из нуля или более) типов поддеревьев (каждое из которых является некоторым типом дерева). Тип дерева в целом представляет собой иерархически организованный набор типов записей. Содержимое иерархической БД представляется упорядоченным набором нескольких экземпляров типа дерева. В общем случае иерархия должна удовлетворять следующим условиям: 1. Одно дерево может иметь только один корень (исходный узел). 2. Узел должен иметь один или несколько атрибутов, описывающих семантику объекта. 3. У родительского узла может быть несколько потомков. 4. Потомок может быть связан только с одним родительским узлом. 5. Порожденные узлы могут быть добавлены как в горизонтальном, так и в вертикальном направлениях. Ограничения, например, на глубину иерархии, могут накладываться только требованиями конкретной иерархической СУБД. Если разность уровней двух связанных узлов равна единице, связь является непосредственной; кроме того, любые две вершины дерева, принадлежащие одной его ветви, транзитивно связаны друг с другом. 2. Каково представление концептуального и внешнего уровней иерархической модели. Концептуальная модель. Совокупность взаимосвязанных ФБД образует концептуальную иерархическую модель данных. Очевидно, что в простейшем случае дереву определений («бумажной» модели) соответствует одна ФБД. Каждая ФБД на физическом уровне реализуется отдельным набором физических записей. Для каждой ФБД на языке описания данных должно присутствовать как описание ее логической структуры, так и структуры хранения. Внешняя модель. При работе с иерархической моделью внешняя представляет собой совокупность поддеревьев для физических баз данных, с которыми работает данное приложение. Каждое поддерево внешней модели в обязательном порядке должно содержать корневой тип сегмента соответствующей ФБД концептуальной модели. Представление внешней модели часто называют логической базой данных и определяется она совокупностью блоков связи данного приложения с ФБД, входящими в состав концептуальной схемы иерархической базы данных. 3. Опишите принципы организации физического хранения записей в иерархической модели. Принципы организации физического хранения записей. Набор всех экземпляров записей, подчиненных одному экземпляру корневой записи, называется физической записью. Порядок хранения экземпляров типов записей в физической записи зависит от особенностей реализации, определяющих способ отображения логических деревьев в физические структуры файлов конкретной СУБД. Наиболее простой способ состоит в линеаризации дерева; при этом экземпляры типов записей хранятся последовательно в порядке обхода дерева сверху вниз слева направо. Пример. Физическая запись, хранящая экземпляры R1 и R2 при линеаризации, будет выглядеть следующим образом: 4.
Ясно, что при этом в общем случае физические записи будут иметь различную длину, причем длина некоторых из них может оказаться недопустимо большой (как с точки зрения занимаемых ресурсов памяти, так и времени поиска нужной информации). Поэтому в иерархических СУБД широко используется аппарат разделения графа, представляющего дерево определений, на подграфы (поддеревья), хранящиеся (реализуемые) отдельно, но в целом (в совокупности) представляющие единую логическую структуру – дерево определений. Такое расчленение обычно соответствует делению предметной области на фрагменты, каждый из которых описывается своим подграфом дерева определений.
Рис. 15. Упрощенный вид дерева определений ПО «Университет» В данном дереве можно выделить такие фрагменты, как например, Деканат, Ректорат, Кадры, Финансы и т.п. Каждый из фрагментов предметной области представляется отдельной физической базой данных (ФБД). 4. Сформулируйте основные понятия сетевой модели. Основные понятия. Сетевой подход к организации данных является расширением иерархического. В иерархических структурах запись-потомок должна иметь в точности одного предка; в сетевой структуре данных потомок может иметь любое число предков. С точки зрения теории графов сетевой модели соответствует произвольный граф (возможно, имеющий циклы и петли). Например,
Стандарт сетевой модели впервые был определен в 1975г. организацией CODASYL (Conference of Data System Languages), которая определила базовые понятия модели и формальный язык ее описания. Базовыми объектами модели являются: · элемент данных, · агрегат данных, · запись, · набор данных. Элемент данных – минимальная информационная единица, доступная с помощью СУБД. Агрегат данных – соответствует следующему после элемента данных уровню обобщения. Например, агрегат с именем Адрес может быть представлен в виде
Запись - в общем случае совокупность элементов данных и/или агрегатов, моделирующая некоторый класс объектов реального мира. Набор – двухуровневый граф, связывающий отношением 1:M два типа записей.
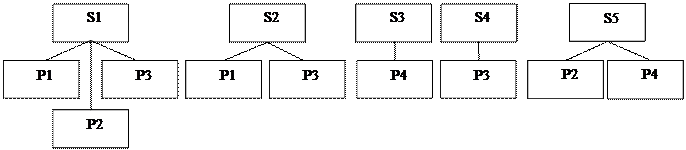
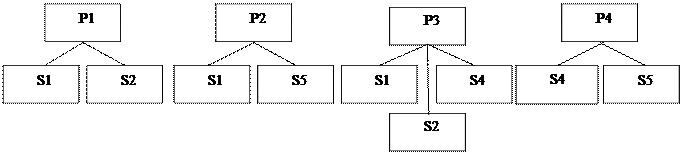
Набор фактически отображает иерархическую связь между двумя типами записей - родительским типом записи (предком), называемым владельцем набора, и дочерним типом записи (потомком) – членом набора. Экземпляр типа связи состоит из одного экземпляра типа записи предка и упорядоченного набора экземпляров типа записи потомка. Для любых двух типов записей может быть задано любое количество наборов, которые их связывают. Наличие подобных возможностей позволяет промоделировать отношение M:N между двумя объектами реального мира, что выгодно отличает сетевую модель от иерархической. Пример. На рис.16. представлены два набора, связывающие сущности «Преподаватель» и «Группа».
Рис.16. Наборы данных, связывающие сущности «Преподаватель» и «Группа» Пусть связь между экземплярами типов записей в наборах представляется содержимым таблицы1. Экземпляров набора «Ведет занятия у» – 3 (по количеству преподавателей), а экземпляров набора «Занимается у» – 4 (по количеству групп). Таблица 1.
Учитывая первоначальные рекомендации CODASYL и результаты последующих соглашений, можно сформулировать следующие основные свойства и ограничения, присущие набору: 1. Набор – это поименованная совокупность связанных записей. 2. В каждом экземпляре набора имеется только один экземпляр записи-владельца. 3. Тип набора представляет логическую взаимосвязь 1:M между владельцем и членом 4.
5. В сетевых моделях допускаются записи-члены, не участвующие в наборах. Это соответствует порожденным узлам дерева, не имеющим исходных. 6. Между двумя типами записей можно определить любое количество наборов, то есть, между ними могут быть определены любые типы отношений. 7. Экземпляр набора существует после заполнения записи-владельца. На формирование типов связи не накладываются особые ограничения; возможны, например, ситуации: · Тип записи потомка в одном типе связи может быть типом записи предка в другом типе связи (как в иерархии). · Данный тип записи может быть типом записи предка в любом числе типов связи. · Данный тип записи может быть типом записи потомка в любом числе типов связи. · Предок и потомок могут быть одного типа записи. 5. Каково представление концептуального и внешнего уровней сетевой модели. Концептуальная модель. Таким образом, сетевая БД состоит из набора записей и набора связей между ними, на концептуальном уровне образующих некоторый граф, а если говорить более точно, из набора экземпляров каждого типа из заданного в схеме БД набора типов записи и набора экземпляров каждого типа из заданного набора типов связи. Внешняя модель. При сетевой организации данных внешняя модель поддерживается путем описания соответствующей части общего связного графа. 6. Достоинства и недостатки навигационных моделей. Особенности: · Навигационные модели активно использовались в течение многих лет, дольше, чем какая-либо из реляционных СУБД. На самом деле некоторые из ранних систем используются даже в наше время, накоплены громадные базы данных, и одной из актуальных проблем информационных систем является использование их совместно с современными системами. · Все ранние системы не основывались на каких-либо абстрактных моделях. Понятие модели данных фактически вошло в обиход специалистов в области БД только вместе с реляционным подходом. Абстрактные представления ранних систем появились позже на основе анализа и выявления общих признаков у конкретных систем. · В ранних системах доступ к БД производился на уровне записей. Пользователи этих систем осуществляли явную навигацию в БД, используя языки программирования, расширенные функциями СУБД. Интерактивный доступ к БД поддерживался только путем создания соответствующих прикладных программ с собственным интерфейсом. · Навигационная природа ранних систем и доступ к данным на уровне записей заставляли производить всю оптимизацию доступа к БД самого пользователя, без какой-либо поддержки системы. · После появления реляционных систем большинство ранних систем было оснащено «реляционными» интерфейсами. Однако в большинстве случаев это не сделало их по-настоящему реляционными системами, поскольку оставалась возможность манипулировать данными в естественном для них режиме. Достоинства: · Иерархическая модель естественным образом реализует отображение 1:N между исходным и порожденными типами записей. Это отображение полностью функционально, так как дерево не может содержать порожденный узел без исходного. · Большая выразительность сетевой модели, достигаемая, прежде всего, возможностью установления между сущностями отношений любого типа. · Развитые средства управления данными во внешней памяти на низком уровне. · Возможность построения вручную эффективных прикладных систем. · Возможность экономии памяти за счет разделения подобъектов (в сетевых системах). Недостатки: · Для представления отображения типа M:N в иерархических системах необходимо дублирование деревьев. Пример. Связь
должна быть реализована двумя схемами:
(а) (б) Пусть загрузочная база данных по схеме (а) включает экземпляры:
Тогда загрузочная база данных по схеме (б) должна включать экземпляры:
Очевидно, что расплатой за необходимость такой реализации отношений M:N выступает высокая степень дублирования данных в базе. · Моделью слишком сложно пользоваться. Фактически необходимы знания о физической организации. · Прикладные системы зависят от физической организации. Их логика перегружена деталями организации доступа к БД. · Разработчик приложения должен детально знать логическую структуру БД, поскольку ему необходимо осуществлять навигацию среди различных экземпляров наборов и типов записей, то есть, программист должен представлять текущее состояние в экземплярах наборов при «продвижении» по БД. · Проблемой поддержки иерархической модели является невозможность хранения в базе данных порожденных узлов без соответствующих исходных. Следует заметить, что в процессе проектирования такая ситуация встречается достаточно часто (например, когда о родительском узле нет достоверной информации). В этом случае необходимо ввести пустой исходный узел. Наличие пустых узлов создает дополнительные трудности при проектировании некоторых приложений. · Определенная сложность операций включения информации о новых объектах в иерархическую базу данных и удаления устаревшей (проблема сохранения целостности базы данных: при удалении узла в общем случае удаляется целое поддерево, что может привести к потере информации). В более общей формулировке: возможность потери независимости данных при реорганизации БД (разрушение целостности БД). Произвольность структуры сети приводит к принципиальным сложностям в реализации такой модели, поскольку в ней отсутствуют ограничения на способы соединения типов записей в схеме БД. КОНТРОЛЬНЫЕ ВОПРОСЫ ПО РАЗДЕЛУ «Система управления базой данных» 1. Перечислите основные функции СУБД. Как уже было отмечено, традиционных возможностей файловых систем оказывается недостаточно для построения даже простых информационных систем (см. п.1.2.). Было выявлено несколько потребностей, которые не покрываются возможностями систем управления файлами: · поддержание логически согласованного набора файлов; · обеспечение языка манипулирования данными; восстановление информации после разного рода сбоев; · реально параллельная работа нескольких пользователей. Можно считать, что система управления данными, обладающая перечисленными свойствами, является системой управления базами данных (СУБД). Таким образом, СУБД играет центральную роль в функционировании автоматизированного банка данных. В общем случае СУБД – это набор программных средств, выполняющих следующие основные функции: 1. Обеспечение пользователей языковыми средствами определения и манипулирования данными. 2. Обеспечение поддержки моделей данных пользователей, то есть средств определения логического представления данных, относящихся к некоторому приложению. Таким образом, здесь под термином модель данных понимаются средства определения именно логического представления данных. 3. Обеспечение защиты данных. 4. Обеспечение целостности данных. Вопрос о сохранении целостности данных имеет несколько аспектов, например: · проверка корректности данных связана с выполнением для новых данных, заносимых в БД, условий, связанных с ограничениями на их значения, например, год рождения служащего не может датироваться 18.. годом, · неправильное управление общими данными при коллективном доступе. 5. Управление транзакциями. Транзакция - это последовательность операций над БД, рассматриваемых СУБД как единое целое. Либо транзакция успешно выполняется, и СУБД фиксирует изменения БД, произведенные искомой транзакцией, во внешней памяти, либо ни одно из этих изменений никак не отражается в состоянии БД. 6. Непосредственное управление данными во внешней памяти. 7. Управление буферами оперативной памяти. 8. Обеспечение независимости данных. СУБД должна поддерживать неизменное представление базы данных на одном уровне архитектуры системы независимо от изменения представлений базы данных на других архитектурных уровнях. 9. Обеспечение универсальности. СУБД должна обладать мощными средствами поддержки концептуальной модели данных для отображения пользовательских логических представлений. Другими словами, должна быть способна поддерживать разные модели данных на единой логической и физической основе. 10.Обеспечение совместимости и развития. СУБД должна сохранять работоспособность при развитии программного и аппаратного обеспечения. 11.Обеспечение безизбыточности данных. БД должна представлять собой единую совокупность интегрированных данных с минимальной степенью их дублирования. 12.Поддержка как централизованных, так и распределенных по информационно-вычислительной сети БД. 2. Определите понятие транзакции. Назначение и суть механизма журнализации. Поддержка целостности. Понятие транзакции необходимо для поддержания логической целостности БД. Если вспомнить пример информационной системы отдела кадров с файлами СОТРУДНИКИ и ОТДЕЛЫ (см. п.5.2.), то единственным способом не нарушить целостность БД при выполнении операции приема на работу нового сотрудника будет объединение элементарных операций над файлами СОТРУДНИКИ и ОТДЕЛЫ в одну транзакцию. Таким образом, поддержание механизма транзакций - обязательное условие даже однопользовательских СУБД. Но понятие транзакции гораздо существеннее во многопользовательских СУБД. При коллективном режиме возможно параллельное использование общих физических данных. Это требует поддержки согласованности одних и тех же данных при работе различных пользователей. Типичные примеры рассогласования при неправильном управлении одновременными модификациями – продажа большего числа товаров, чем имеется на складе, продажа нескольких билетов на одно место. Другими словами, суть сохранения целостности БД – ее адекватность текущему состоянию предметной области. То свойство, что каждая транзакция начинается при целостном состоянии БД и оставляет это состояние целостным после своего завершения, делает очень удобным использование понятия транзакции как единицы активности пользователя по отношению к БД. При соответствующем управлении параллельно выполняющимися транзакциями со стороны СУБД каждый пользователь может в принципе ощущать себя единственным пользователем СУБД. Защита данных может рассматриваться с нескольких точек зрения, например: · защита для обеспечения секретности связана с разрешением использования тех или иных данных, хранящихся в системе, только пользователям, имеющим на это право, · защита от несанкционированного доступа, как правило, разрешает неограниченный доступ к данным из БД по чтению (выборке), но запрещает обновление и запись новых данных в “чужие” для данного пользователя разделы БД, · защита от разрушения БД при сбоях оборудования предполагает наличие процедур копирования и восстановления (функция журнализации). Журнализация. Одно из основных требований к СУБД - надежное хранение данных во внешней памяти. Под надежностью хранения понимается то, что СУБД должна быть в состоянии восстановить последнее согласованное состояние БД после любого аппаратного или программного сбоя. Обычно рассматриваются два возможных вида аппаратных сбоев: · так называемые мягкие сбои, которые можно трактовать как внезапную остановку работы компьютера (например, аварийное выключение питания), · и жесткие сбои, характеризуемые потерей информации на носителях внешней памяти. Примерами программных сбоев могут быть: · аварийное завершение работы СУБД (из-за ошибки в программе или некоторого аппаратного сбоя), · аварийное завершение пользовательской программы, в результате чего некоторая транзакция остается незавершенной. Первую ситуацию можно рассматривать как особый вид мягкого аппаратного сбоя; при возникновении последней требуется ликвидировать последствия только одной транзакции. В любом случае для восстановления БД нужно располагать некоторой дополнительной информацией. Другими словами, поддержание надежного хранения данных в БД требует избыточности хранения данных, причем та их часть, которая используется для восстановления, должна храниться особо надежно. Наиболее распространенный метод поддержания такой избыточной информации - ведение журнала изменений БД. Журнал - это особая часть БД, недоступная пользователям СУБД, в которую поступают записи обо всех изменениях основной части БД. В разных СУБД изменения БД фиксируются на разных уровнях: иногда запись в журнале соответствует некоторой логической операции изменения БД (например, операции удаления строки из таблицы реляционной БД), а порой запись соответствует минимальной внутренней операции модификации страницы внешней памяти. В некоторых системах одновременно используются оба подхода. Во всех случаях придерживаются стратегии «упреждающей» записи в журнал протокола. Кратко, эта стратегия заключается в том, что запись об изменении любого объекта БД должна попасть во внешнюю память журнала раньше, чем измененный объект попадет во внешнюю память основной части БД. Самая простая ситуация восстановления - индивидуальный откат транзакции. Физически журнал обычно представляет собой чисто последовательный файл с записями переменного размера, которые можно просматривать в прямом или обратном порядке. Операции обмена производятся стандартными порциями (страницами) с использованием буфера оперативной памяти (см. пп.7.2.1. и 7.3.). Структура (и тем более, смысл) журнальных записей известна только компонентам СУБД, ответственным за журнализацию и восстановление. Поскольку содержимое журнала является критичным при восстановлении базы данных после сбоев, к ведению файла журнала предъявляются особые требования по части надежности. В частности, обычно стремятся поддерживать две идентичные копии журнала на разных устройствах внешней памяти. Очевидно, что в многопользовательском режиме работы вопросы журнализации занимают одно из центральных мест при функционировании СУБД. Управление данными во внешней памяти. Эта функция включает обеспечение необходимых структур внешней памяти (индексов) как для хранения непосредственных данных, входящих в БД, так и для служебных целей, например, для убыстрения доступа к данным (см. пп. 7.2.3. - 7.2.7.). Управление буферизацией. СУБД обычно работают с БД значительного размера; по крайней мере, этот размер обычно существенно превышает доступный объем оперативной памяти. Понятно, если при обращении к любому элементу данных будет производиться обмен с внешней памятью, то вся система будет работать со скоростью устройства внешней памяти. Единственным же способом реального увеличения этой скорости является буферизация данных в оперативной памяти. Поэтому в развитых СУБД поддерживается собственный набор буферов оперативной памяти с собственной дисциплиной замены буферов. При управлении буферами основной памяти приходится разрабатывать и применять согласованные алгоритмы буферизации, журнализации и синхронизации. 3. Какие основные аспекты сохранения целостности учитываются при функционировании СУБД Обеспечение целостности данных. Вопрос о сохранении целостности данных имеет несколько аспектов, например: проверка корректности данных связана с выполнением для новых данных, заносимых в БД, условий, связанных с ограничениями на их значения, например, год рождения служащего не может датироваться 18.. годом, неправильное управление общими данными при коллективном доступе. 4. Какие основные аспекты защиты данных должны учитываться при функционировании СУБД. Защита данных может рассматриваться с нескольких точек зрения, например: · защита для обеспечения секретности связана с разрешением использования тех или иных данных, хранящихся в системе, только пользователям, имеющим на это право, · защита от несанкционированного доступа, как правило, разрешает неограниченный доступ к данным из БД по чтению (выборке), но запрещает обновление и запись новых данных в “чужие” для данного пользователя разделы БД, · защита от разрушения БД при сбоях оборудования предполагает наличие процедур копирования и восстановления (функция журнализации). 5. Сформулируйте понятия логической и физической независимости данных. Независимость данных. Важнейшими аспектами независимости данных являются: Логическая независимость данных. Способность механизмов СУБД поддерживать изменения логического представления данных таким образом, чтобы при этом было возможно сохранить неизменными пользовательские представления данных. В терминологии архитектурной модели ANSI/X3/SPARC это означает возможность вариации концептуальной схемы базы данных без необходимости изменений внешних схем. Физическая независимость данных. Способность механизмов СУБД поддерживать изменения физического представления данных таким образом, чтобы при этом было возможно сохранить неизменным логическое их представление. В терминологии архитектурной модели ANSI/X3/SPARC это означает возможность вариации внутренней схемы базы данных без необходимости изменений концептуальной схемы. 6. Приведите обобщенную схему СУБД. Обобщенную структуру СУБД можно представить схемой на рис. 18. Упрощенно основные этапы реализации СУБД запроса приложения представлены на рис.19. 1. Прикладная программа выдает СУБД запрос на доступ к БД. 2. СУБД анализирует запрос и определяет типы необходимых логических записей, содержащих запрашиваемые данные. 3. СУБД определяет хранимые записи, которые нужно предоставить прикладной программе. 4. СУБД выдает ОС команды поиска и обработки хранимых записей. 5.
Обобщенная структура СУБД
6. СУБД выделяет логические записи, которые необходимо передать приложению. 7. СУБД передает выделенные данные из системных буферов в рабочую область прикладной программы, предварительно преобразовав их в формат, указанный в запросе. 8. СУБД передает прикладной программе информацию о результатах обработки запроса. 9.
Рис.19. Схема реализации запроса к СУБД Замечание. Понятия концептуальной и внешней схем для навигационных моделей достаточно очевидны. Для реляционной модели внешнюю схему можно ассоциировать со схемой отношения, являющегося результатом выполнения запроса. понятие концептуальной схемы как результата реализации соответствующей модели инструментарием СУБД заменяется понятием даталогической (логической) схемы базы данных как взаимосвязанного набора схем отношений, формирующих базу. Замечание. Для эффективной работы с внешн памятью СУБД может взять управление на себя, минуя систему управления файлами ОС 7. Приведите упрощенную схему функционирования СУБД.
Рис.20 Взаимодействие компонентов информационной системы КОНТРОЛЬНЫЕ ВОПРОСЫ ПО РАЗДЕЛУ «Основы физического проектирования» 2.Сформулируйте основные понятия физического уровня: хранимая запись, формат хранимой записи, метод доступа, механизм поиска Хранимая запись. Под хранимой записью будем понимать запись какого-либо типа, хранимую во внешней памяти. Очевидно, по аналогии с логическими записями, можно говорить о типе хранимой записи и экземпляре хранимой записи некоторого типа. Метод доступа определим как совокупность технических и программных средств, обеспечивающих возможность хранения и выборки данных (представленных хранимыми записями), расположенных во внешней памяти. В формировании метода доступа важны два компонента: · структура памяти, · механизм поиска. По структуре различают два типа внешней памяти: · память с последовательным доступом (например, магнитные ленты), · память с прямым доступом (например, дисковая память). Механизм поиска задается алгоритмом, определяющим специфический путь доступа, который возможен в рамках конкретной структуры памяти, и количество шагов вдоль этого пути для нахождения искомых данных (хранимых записей). Очевидно, что выбор метода доступа регулируется соображениями эффективности работы с БД (по использованию ресурсов - памяти и времени). Как правило, современные СУБД используют несколько методов доступа к хранимым записям. 1. Сформулируйте основные задачи этапа физического проектирования. Таким образом, в общем случае процесс проектирования физической БД (физическое проектирование) – это процесс создания по заданной логической структуре ее эффективной физической реализации, исходя из информационных требований конечных пользователей. Выделим в процессе физического проектирования следующие задачи: · определение методов доступа, · распределение и управление внешней памятью.
2. Классификация методов доступа
3. Опишите способы последовательной организации. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Последнее изменение этой страницы: 2019-03-31; Просмотров: 544; Нарушение авторского права страницы
 S WHERE XΘY, где Θ ={<, ≤, =, ≠, ≥,>}.
S WHERE XΘY, где Θ ={<, ≤, =, ≠, ≥,>}. Пример. Дерево определений, представляющее структуру университета (до определенного уровня)
Пример. Дерево определений, представляющее структуру университета (до определенного уровня)



 Существенное различие между сетевой и иерархической моделями данных состоит в том, что в сетевой модели каждая запись может участвовать в любом количестве наборов:
Существенное различие между сетевой и иерархической моделями данных состоит в том, что в сетевой модели каждая запись может участвовать в любом количестве наборов:


 ОС интерпретирует команды СУБД, взаимодействует с внешним запоминающим устройством, обнаруживая в БД требуемые записи. Отобранные записи передаются в системные буферы
ОС интерпретирует команды СУБД, взаимодействует с внешним запоминающим устройством, обнаруживая в БД требуемые записи. Отобранные записи передаются в системные буферы При успешном завершении СУБД обработки запроса приложение использует полученные данные для дальнейшей работы, в противном случае запрос должен быть повторен.
При успешном завершении СУБД обработки запроса приложение использует полученные данные для дальнейшей работы, в противном случае запрос должен быть повторен.
 Приведите общую классификацию методов доступа.
Приведите общую классификацию методов доступа.