
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Выделяют четыре типа страниц: ⇐ ПредыдущаяСтр 6 из 6
· страницы данных, · страницы индексов, · страницы blob-объектов, · битовые страницы. Страница данных. Основная единица осуществления операций обмена. Структура страницы данных представлена на рис. 32.
Рис. 32. Структура страницы данных
Заголовок страницы включает внутрисистемную информацию, используемую СУБД в механизме управления страницами. Данные на странице представляются в виде строк. Каждая строка соответствует некоторому кортежу отображаемого отношения. Слоты характеризуют размещение строк данных на странице. В базе данных каждый кортеж имеет уникальный внутрисистемный идентификатор, включающий номер страницы и номер строки на странице, в которую отображается данный кортеж. Содержимое слота и составляет идентификатор соответствующей ему (по номеру на странице) строки. При упорядочивании кортежей отношения по значению какого-либо атрибута физического перемещения строк на соответствующих страницах не происходит. Вместо этого производится перестройка содержимого слотов. Страница индексов. Страницы индексов предназначены для хранения индексных структур, используемых СУБД в реализации методов доступа, и организованы в виде В-деревьев. Страница blob. Страницы blob (Binary Large Object) предназначены для хранения слабоструктурированной информации, содержащей тексты большого объема, графическую информацию, двоичные коды. Эти данные рассматриваются как потоки байтов произвольного размера, а в страницах данных формируются ссылки на эти страницы. Данные таких типов в ранних СУБД относились к типу MEMO. Битовая страница. Битовые страницы содержат описатели других типов страниц. Описатель страницы включает две составляющих – тип страницы и ее состояние (свободна/занята).
КОНТРОЛЬНЫЕ ВОПРОСЫ ПО РАЗДЕЛУ «Особенности объектно-ориентированных СУБД» 1. Перечислите побудительные мотивы к началу исследований по созданию ООСУБД. В середине 70-х годов XX века начали рождаться новые идеи, которые привели впоследствии к формированию объектного подхода в технологиях баз данных. 1. Объектный подход в программировании в значительной мере побудил интерес к воплощению объектной парадигмы в технологиях баз данных, поскольку возникла необходимость в обеспечении эффективной среды хранения объектных данных для поддержки многочисленных прикладных программных систем, реализованных средствами объектных языков. Эту функцию было естественно возложить на СУБД, основанные на объектных моделях данных, и обладающие интерфейсами прикладного программирования (API) для объектных языков. Объектно-ориентированная СУБД (ООСУБД) — средство, которое обеспечивает запись объектов в базу данных «как есть». Данное обстоятельство стало решающим аргументом в пользу разработки технологии ООСУБД как средства для переноса семантики объектов и процессов реального мира в сферу информационных систем, то есть переноса объектов реального мира в виртуальный мир. 2. Исследования по созданию ООСУБД связаны со сложившимся пониманием неэффективности использования реляционных систем в целом ряде приложений. Многие из таких приложений нуждаются в более богатых по сравнению с предоставляемыми реляционными СУБД средствами моделирования предметной области (с более развитыми системами типов данных, возможностями структурирования данных, обеспечивающих во многих случаях более естественное отображение семантики предметной области в базах данных). Дело в том, что одним из основных положений реляционной модели данных является требование нормализации отношений: поля кортежей могут содержать лишь атомарные значения, то есть, по существу, требование примитивности структур данных, лежащих в основе реляционной модели. Для традиционных приложений реляционных СУБД (РСУБД) - банковских систем, систем резервирования (билетов, посадочных мест и т.д.) - это вовсе не ограничение, а даже преимущество, позволяющее проектировать экономные по памяти БД с предельно простой и понятной структурой. Запросы с соединениями в таких системах сравнительно редки, для динамической поддержки целостности используются соответствующие средства SQL. Заметим, что плоские нормализованные отношения универсальны и теоретически достаточны для представления данных любой предметной области. Однако такой подход является весьма неестественным при управлении наборами данных или данными, которые необходимо описать с большей степенью детализации. Допустим, в столбце Адрес таблицы СЛУЖАЩИЙ может быть указан полный домашний адрес, причем различные приложения могут обрабатывать различные компоненты адресов. Однако РСУБД будет трактовать данные столбца Адрес как единое целое (строку символов), не замечая компонентные элементы данных; поэтому либо каждому приложению придется распаковывать содержимое поля, либо, что более соответствует духу реляционной модели, для каждой компоненты адреса будет выделен отдельный столбец. Еще большие проблемы возникают при использовании РСУБД в прикладных системах, основанных на знаниях – системах автоматизированного проектирования (САПР), системах искусственного интеллекта и т.п., которые обычно оперируют с объектами сложной структуры. Для формирования (воссоздания) цельного объекта из плоских таблиц РСУБД приходится выполнять запросы, почти всегда требующие соединения отношений. Поэтому попытки использования РСУБД в соответствии с требованиями таких нетрадиционных приложений приводят к появлению в базе данных сотен и тысяч таблиц, над которыми постоянно выполняются дорогостоящие операции соединения, необходимые для воссоздания сложных структур данных, присущих предметной области. Другими словами, в руки проектировщиков даются настолько же мощные и гибкие средства структуризации данных, как те, которые были присущи иерархическим и сетевым системам баз данных. 3. Проблема, название которой можно перевести как импеданс (или расхождение) моделей. Она выражается в том, что модель данных, используемая в приложении, отличается от модели данных базы данных. Это различие, в свою очередь, приводит к двум проблемам в приложениях, в результате которых и возникает расхождение: · Программист, разрабатывающий приложение, должен оперировать двумя различными языками программирования, с различным синтаксисом, семантикой и типами систем, а именно, прикладным языком программирования (например, Си++) и языком манипулирования базами данных (то есть, SQL). Логика приложения реализуется средствами прикладного языка, в то время как SQL используется для создания и манипулирования данными в базе. · При извлечении данных из реляционной базы, они должны быть переведены из представления, в котором они там хранились, в представление, соответствующее представлению данных в памяти, характерному для данного приложения. Аналогично, все обновления данных должны быть переданы базе данных при помощи другого предложения SQL, то есть требуется еще одно преобразование из представления, используемого в приложении, в представление базы данных. Весь обмен данными между базой данных и приложением приводит к ненужной дополнительной обработке, которой можно было бы избежать, будь модели данных приложения и базы данных одинаковыми.
2. Каковы особенности объектной модели данных. В связи с объектной парадигмой был предложен новый подход, при котором модель данных рассматривается как система типов. Такой подход обеспечивает естественные возможности интеграции баз данных и языков программирования. Ориентируясь на современное понимание типа данных как носителя свойств, определяющих и состояние экземпляров типа, и их поведение, можно дать следующее определение понятия модели данных (ср. с определением этого понятия, приведенным в п. 2.4.): Модель данных – это система типов данных, типов связей между ними и допустимых видов ограничений целостности, которые могут быть для них определены. Стандарт на ООСУБД выработан консорциумом Object Database Management Group (ODMG), состоящим в основном их производителей таких СУБД. В соответствии со стандартом ODMG, объектная модель данных характеризуется следующими свойствами. · Базовыми примитивами являются объекты и литералы. Каждый объект имеет уникальный идентификатор, литерал не имеет идентификатора. · Объекты и литералы различаются по типу. Все элементы одного типа имеют одинаковый диапазон изменения состояния (множество свойств) и одинаковое поведение (множество определенных операций). Объект, на который можно установить ссылку, называется экземпляром; он хранит определенный набор данных. · Состояние объекта определяется набором значений множества свойств. Этими свойствами могут быть атрибуты объекта или связи между объектом и одним или несколькими другими объектами. · Поведение объекта определяется набором операций, которые могут быть выполнены над объектом или самим объектом. Операции могут иметь список входных и выходных параметров строго определенного типа. Каждая операция может также возвращать типизированный результат. · База данных хранит объекты, позволяя совместно использовать их различным пользователям и приложениям. База данных основана на схеме данных, определяемой языком определения данных, и содержит экземпляры типов, определенных схемой. Каждый тип имеет внешнюю спецификацию и одну или несколько реализаций. Спецификация определяет внешние характеристики типа: пользователю для работы с объектом предоставляется набор операций и набор атрибутов объекта, при помощи которых можно работать с реальными экземплярами. Реализация определяет внутреннее содержание объектов, например операции. Тип также является объектом. ООСУБД обслуживает множество баз данных, каждая из которых содержит определенное множество типов. В базах данных могут содержаться объекты соответствующего типа из этого множества. Тип имеет набор свойств, а объект характеризуется состоянием в зависимости от значения каждого свойства. Операции, определяющие поведение типа, едины для всех объектов одного типа. Свойство едино для всего типа, а все объекты типа также имеют одинаковый набор свойств. Значение свойства относится к конкретному объекту. Таким образом, одним из принципиальных отличий объектных баз данных от реляционных является возможность создания и использования новых типов данных. Основные элементы ООСУБД представлены на рис.36., а применение базовых понятий объектной модели в ООСУБД на рис.37.
Рис.36. Основные элементы ООСУБД
Замечание 1. Очевидно родство понятия класса объектно-ориентированной парадигмы программирования и понятия типа объектно-ориентированной технологии баз данных. Замечание 2. Напомним, что термин объект в РСУБД обозначает либо тип объектов, либо экземпляр типа объектов. В ООСУБД и тип, и экземпляр типа являются объектами. Стандартный механизм объектно-ориентированного программирования — наследование, реализуется в ООСУБД путем поддержки иерархии супертипов (родительских типов) и подтипов (типов-потомков). Как правило, в ООСУБД для объектов, которые предполагается хранить в базе (постоянные объекты), требуется, чтобы их предком был конкретный базовый тип, определяющий все основные операции взаимодействия с сервером баз данных. Поэтому для создания своего типа необходимо унаследовать свойства любого имеющегося типа, наиболее подходящего по своему поведению и состоянию к типу, который требуется получить, расширить недостающие операции и атрибуты и переопределить, по необходимости, уже имеющиеся.
3. Каковы достоинства и недостатки ООСУБД. возникло ощущение, что объектно-ориентированные СУБД вытеснят реляционные и в силу согласованности с объектно-ориентированной парадигмой программирования, и в силу возможности навигации по указателям (ссылкам), что позволяет на новом уровне реализовать лучшие изобразительные средства иерархических и сетевых моделей. из-за ряда причин ООСУБД так и не смогли оказать значительного влияния на положение дел в области технологии баз данных: 1. Отсутствие в ООСУБД базовых средства, к которым пользователи систем баз данных привыкли. Чтобы ООСУБД смогли оказать значительное влияние на рынок баз данных, требовалось учесть привычку разработчиков к использованию средств РСУБД и огромный объем прикладного программного обеспечения, использующего реляционные базы данных. Для этого необходимо было: · превратить ООСУБД в системы баз данных, обладающих достаточной совместимостью с РСУБД, чтобы обеспечить сосуществование имеющихся и создающихся новых продуктов, · унифицировать модели данных РСУБД и ООСУБД, · унифицировать архитектуры РСУБД и ООСУБД. 2. Чтобы стать полноценными СУБД, ООСУБД должны поддерживать весь спектр соответствующих средств: · стандартная алгебра, средства обеспечения и оптимизации запросов, · управление транзакциями, · поддержка ограничений целостности, · организация безопасности, · и т.д. 3. Наличие в ООСУБД основных базовых средства, которые пользователи хотели бы видеть; · широкие возможности настройки производительности, присущие РСУБД, · поддержка сложных объектов, · поддержка динамических изменений определений классов, · полная интеграция с объектно-ориентированными системами программирования. Значительные сложности учета перечисленных факторов привел к тому, что рынок ООСУБД в настоящее время, по существу, исчез. Основные трудности объектно-ориентированного моделирования данных проистекают из того, что не существует развитого математического аппарата, на который могла бы опираться общая объектно-ориентированная модель данных. Замечание. Некоторые авторы утверждают, что общая объектно-ориентированная модель данных в классическом смысле и не может быть определена по причине непригодности классического понятия модели данных к парадигме объектной ориентированности. КОНТРОЛЬНЫЕ ВОПРОСЫ ПО РАЗДЕЛУ «Вопросы распределенных баз данных» 1. Перечислите модели доступа и основные стратегии распределения данных, их достоинства и недостатки. · Централизация. Единая копия БД располагается в одном узле. Преимущества: - простота поддержки целостности, - простота обеспечения защиты, - простота реализации, - минимальная степень дублирования данных. Недостатки: - ограниченный объем внешней памяти, - ограничения на надежность, определяемые надежностью работы узла, - возможное значительное (а часто и недопустимое) время отклика на запрос при большом сетевом трафике (ограниченный доступ).
Рис.47. Методы доступа в распределенных базах данных
· Распределение. Различают два способа распределения данных с целью их приближения к месту использования и сокращения тем самым сетевого трафика - репликация и фрагментация. Репликация (тиражирование, дублирование). Технология, которая предусматривает поддержку полных копий базы данных или некоторых ее фрагментов в нескольких узлах сети. Полная репликация. Все данные дублируются в каждом узле. Частичная репликация. Некоторые, часто используемые на удаленных узлах, данные могут дублироваться в соответствующих узлах. Преимущества: - максимальный уровень надежности, - минимизация времени отклика при выборке данных (повышение степени доступности). Недостатки: - необходимость синхронизации при модификации БД. Фрагментация (расщепление, разделение). Технология, предусматривающая разбиение полной базы данных каким-либо методом на непересекающиеся составные части (фрагменты), хранимые в разных узлах сети. В свою очередь расщепление может быть вертикальным - выделение подмножества полей (атрибутов), и горизонтальным - выделение подмножества записей (кортежей). Преимущества: - максимальная внешняя память (суммарная для всех узлов сети), - минимальное время отклика на локальный запрос, - большая степень распараллеливания, - высокая степень доступности и надежности. Недостатки: - высокая стоимость связи в запросах, касающихся многих «чужих» локальных БД. Замечание. Ключевым фактором, влияющим на доступность и надежность БД, является локализация ссылок, то есть расположение запрашиваемых данных, исходя из удовлетворения запросов пользователей. Если БД распределена по сети так, что данные, расположенные в узле, запрашиваются почти исключительно пользователями этого узла, говорят, что существует высокая степень локализации ссылок. Очевидно, что надежность и доступность БД снижаются при понижении степени локализации ссылок. Возможным подходом к распределению данных может быть и применение смешанной стратегии - сочетанию репликации и фрагментации. Пример стратегий распределения Пусть схема распределенной по трем узлам БД состоит из трех отношений: СЛУЖАЩИЕ(слж#, фио, отд#, зарпл, рук) ОТДЕЛ(подраздел#, отд#) РАЗМЕЩЕНИЕ(подраздел#, город)
В Узел#1 находится головное учреждение и хранятся полные копии всех отношений (СЛУЖАЩИЕ, ОТДЕЛ, РАЗМЕЩЕНИЕ). В Узел#2 обрабатываются данные о зарплатах и налогах. Для этого нужны только атрибуты слж#, фио, зарпл из отношения СЛУЖАЩИЕ. В Узел#3 хранятся полные данные о служащих, зарабатывающих меньше 50000 руб. в год; об остальных служащих хранятся только сведения о номере отдела, в котором служащий работает, и руководителе отдела. Построим в Узел#2 отношение СЛЖ1(слж#, фио, зарпл) как проекцию: СЛЖ1 = СЛУЖАЩИЕ[слж#, фио, зарпл] Построим в Узел#3 отношения СЛЖ2(слж#, фио,отд#,зарпл,рук ) и СЛЖ3(слж#, фио,отд#,рук ), используя операции селекции (выборки) и проекции: СЛЖ2 = СЛУЖАЩИЕ WHERE зарпл < 50000 СЛЖ3 = СЛУЖАЩИЕ WHERE зарпл ≥ 50000[слж#, фио, отд#, рук] Таким образом, в Узел#1 хранятся полные кортежи, в Узел#2 - вертикальный фрагмент (расщепление по вертикали), в Узел#3 - горизонтальный и смешанный фрагменты отношения СЛУЖАЩИЕ. Замечание. Правильное восстановление полных кортежей отношения СЛУЖАЩИЕ по кортежам отношений СЛЖ1, СЛЖ2 и СЛЖ3 осуществляется с использованием значений ключевого атрибута слж#.
2. Перечислите проблемы распределенных баз данных. · Логическая прозрачность. Необходимость наличия единой концептуальной схемы распределенной по сети БД, другими словами, необходимость наличия общей модели данных распределенной системы. Принцип логической прозрачности позволяет пользователю формировать запросы ко всем данным распределенной БД так, как если бы он работал с централизованной базой. · Прозрачность размещения. Выполнение данного принципа позволяет пользователю при формировании запроса не указывать местоположение узлов, откуда необходимо получить данные для удовлетворения запроса. Очевидно, что реализация прозрачности размещения требует наличия схемы, определяющей местонахождение данных в сети. · Прозрачность преобразования. Распределенные БД могут быть однородными или неоднородными в смысле использования аппаратных и программных (СУБД) средств. Проблема неоднородности аппаратной, но однородности программной решается сравнительно просто. Если же в узлах сети используются разные СУБД, необходимы средства преобразования структур данных и языков. · Управление словарями. Для обеспечения всех видов прозрачности в распределенной БД нужны программы, управляющие многочисленными справочниками и словарями. · Координация процессов. Методы выполнения запросов в распределенных БД отличаются от аналогичных методов централизованных СУБД, поскольку отдельные части запроса нужно выполнять на месте расположения соответствующих данных и передавать частичные результаты на другие узлы, при этом должна быть обеспечена координация всех процессов. · Непротиворечивость данных. Необходим сложный механизм управления одновременной обработкой, который, в частности, должен обеспечивать синхронизацию при обновлениях информации, что гарантирует непротиворечивость данных. · Развитая методика репликации и расщепления данных. Выполнение запросов в распределенных базах данных . Поскольку данные распределены, а также могут быть расщеплены, запросы, составленные пользователем, который рассматривает данные целиком, должны быть приведены к виду, учитывающему разделение и расщепление данных. Таким образом, требуется декомпозиция запроса, так как программа, реализующая запрос, не может быть выполнена полностью в одном узле. Кроме того, поскольку для завершения выполнения программы необходимо перемещать целые отношения (файлы) или результаты промежуточных вычислений, необходимо оптимизировать: · саму программу, · методику выполнения программы (запроса) с учетом необходимых перемещений данных.
3. Перечислите свойства транзакций. Варианты завершения транзакции. Транзакция - это разовый прогон программы, реализующей запрос (другими словами, такая единица работы), при котором БД остается в состоянии целостности до и после выполнения транзакции. Замечание. В процессе выполнения транзакции целостность БД может нарушаться. два варианта завершения транзакции. Вариант 1. Все операции транзакции выполнены успешно и в процессе выполнения не произошло никаких сбоев программного или аппаратного обеспечения. В этом случае транзакция фиксируется, то есть, производится запись во внешнюю память изменений в БД, которые были сделаны в процессе выполнения транзакции. Замечание. До тех пор, пока транзакция не зафиксирована, допустимо аннулирование этих изменений путем восстановления БД в то состояние, в котором она была на момент начала выполнения транзакции. Вариант 2. Если в процессе выполнения транзакции возникла ситуация, которая делает невозможным ее нормальное завершение, БД должна быть возвращена в исходное состояние, то есть, должен быть произведен откат. Таким образом, откат транзакции - это совокупность действий, обеспечивающих аннулирование всех изменений данных в БД, которые были сделаны операторами SQL в теле незавершенной транзакции. Согласно стандартным соглашениям, транзакция завершается одним из 4-х возможны путей: 1) выполнение оператора COMMIT - фиксация успешного завершения транзакции; 2) успешное завершение программы, в которой было инициировано выполнение транзакции; 3) выполнение оператора ROLLBACK - реализация отката; 4) аварийное завершение программы, в которой было инициировано выполнение транзакции. Реализация в СУБД принципа сохранения промежуточных состояний, подтверждения или отката транзакции обеспечивается специальным механизмом, для поддержки которого создается некоторая системная структура, называемая журналом транзакций. Однако, назначение журнала транзакций гораздо шире. Он предназначен для обеспечения надежного хранения данных в БД. Возможны следующие ситуации, при которых требуется произвести восстановление состояние БД. 1) Индивидуальный откат транзакции: a) стандартная ситуация отката и явное аварийное завершение транзакции по оператору ROLLBACK; b) аварийное завершение работы прикладной программы, которое логически эквивалентно выполнению оператора ROLLBACK, но физически имеет иной механизм выполнения; c) принудительный откат транзакции в случае взаимной блокировки при параллельном выполнении транзакций; в подобном случае для выхода из тупика данная транзакция может быть выбрана в качестве «жертвы». 2) Восстановление после внезапной потери содержимого оперативной памяти (мягкий сбой): a) при аварийном выключении питания; b) неустранимый сбой процессора и, таким образом, потеря данных, находящихся в оперативной памяти. 3) Восстановление после поломки основного внешнего носителя БД (жесткий сбой). Свойства транзакций Существуют различные модели транзакций, которые могут быть классифицированы на основании различных свойств, включающих: · структуру транзакции, · параллельность внутри транзакции, · продолжительность и т.п. Стандартно выделяют 4 классических свойства транзакций: Атомарность (Atomicity) - транзакция должна быть выполнена в целом или не выполнена вовсе. Согласованность (Consistency) - гарантирует, что по мере выполнения транзакции данные переходят из одного согласованного состояния в другое, то есть транзакция не разрушает взаимной согласованности данных. Изолированность (Isolation) - конкурирующие за доступ к БД транзакции физически обрабатываются последовательно, изолированно друг от друга, но для пользователей это выглядит так, как будто они выполняются параллельно. Долговечность (Durability) - если транзакция завершена успешно, то те изменения в данных, которые были ею произведены, не могут быть потеряны ни при каких обстоятельствах (даже в случае последующих ошибок). Традиционные (плоские) транзакции, обладающие всеми стандартными свойствами, иногда называют ACID-транзакциями.
4. Сформулируйте понятие расписания. Приведите примеры рассогласования. В связи с управлением одновременной работой СУБД по выполнению запросов от разных пользователей, рассматриваются понятия транзакции и расписания. Транзакция - это разовый прогон программы, реализующей запрос (другими словами, такая единица работы), при котором БД остается в состоянии целостности до и после выполнения транзакции. Замечание. В процессе выполнения транзакции целостность БД может нарушаться. Расписанием совокупности транзакций будем называть порядок, в котором выполняются элементарные шаги этих транзакций. Очевидно, что расписание при одновременной работе представляет порядок выполнения транзакций во времени. Примеры расписаний. Введем следующие обозначения: Т - транзакция, R- A - элементарный шаг транзакции, представляющий чтение значения поля А, W-A - элементарный шаг транзакции, представляющий запись значения в поле А. Расписание 1. Т1 : R-A T1 : W-A T2 : R-A T2 : W-A Нарушения целостности (рассогласования) БД возникнуть не может, так как транзакции Т1 и Т2 выполняются последовательно. Расписание 2. Т1 : R-A T2 : R-A T1 : W-A T2 : W-A Модификация транзакции Т1 затирается транзакцией Т2, следовательно, она теряется. Расписание 3. Т1 : W-A T2 : W-A T1 : отменить Потеря модификации транзакции Т2, поскольку после ее окончания следует сигнал отмены модификации. Расписание 4. Т1 : W-A T2 : R-A T1 : прервать Ситуация известна под названием «неправильное считывание», поскольку выбранное транзакцией Т2 значение впоследствии из БД удаляется. Расписание 5 Т2: R-A T1: W-A T2 : R-A Две выборки дадут различные значения. Пример рассогласования БД. Пусть транзакции Т1 и Т2 имеют вид: R-A A=A+1 W-A Шаги выполнения транзакций приведены в следующей таблице
Очевидно, что целостность БД нарушена, поскольку нельзя было допустить чтение и модификацию поля А транзакцией Т2 до того, пока транзакция Т1 свое выполнение не закончит, то есть до записи модифицированного транзакцией Т1 значения в поле А. Согласованные состояния БД обеспечивают последовательные или приводимые к последовательным расписания. Расписание называется последовательным, если все транзакции выполняются строго друг за другом. Расписание называется приводимым к последовательному, если результат применения этого расписания к БД эквивалентен результату последовательного расписания. Для выявления расписаний, приводимых к последовательным и благодаря этому сохраняющих согласованное состояние БД, можно использовать метод, основанный на построении графа зависимостей. В графе зависимостей транзакциям соответствуют узлы, а направленная дуга графа, связывающая узлы Ti и Tj , обозначает, что вход транзакции Tj зависит от выхода транзакции Ti , то есть Tj использует значение поля, определенное Ti. Если граф зависимостей содержит циклы, то это означает, что соответствующее расписание не приводится к последовательному.
Т1 : W-A
T2 : W-A T2 : W-B Пример 2. Расписание , приводимое к последовательному
Т1 : W-A
T1 : W-В T2 : W-B
Пример 3. Расписание , не приводимое к последовательному
Т1 : W-A
T2 : W-В T1 : W-B
5. Управление блокированием. Перечислите основные методы синхронизации распределенных обновлений. В распределенных базах данных в общем случае одновременно выполняются несколько транзакций; при этом могут использоваться одни и те же данные, возможно, продублированные в разных узлах. При чтении для получения нужной информации достаточно одной копии, если СУБД обеспечивает непротиворечивость всех копий. При обновлениях (записи в БД) для сохранения непротиворечивости все копии должны быть своевременно модифицированы. Очевидно, что обновления нужно производить в соответствии с последовательными протоколами. Если учитывать одновременное выполнение транзакций над многочисленными копиями, последовательность обновлений требует развитых средств синхронизации, которая прежде всего предполагает монопольное владение поля транзакцией до полного окончания использования этого поля. Монопольное использование значения поля в процессе работы СУБД можно обеспечить с помощью блокировки (захвата). При этом предполагается, что любая транзакция представима в виде последовательности ЗАХВАТ - ДЕЙСТВИЕ - ОСВОБОЖДЕНИЕ Управление блокированием - это функциональный элемент СУБД, который назначает и регистрирует блокирование, а также играет роль арбитра между несколькими запросами на блокировку одного элемента. Очевидно, что блокировка действует как примитивная синхронизация выполнения транзакций. То есть, если транзакция пытается блокировать (ЗАХВАТ) что-то уже заблокированное, она должна ждать, пока блокировка не будет снята (ОСВОБОЖДЕИЕ) транзакцией, установившей блокировку. Итак, всякая транзакция в конце концов должна разблокировать все, что она ранее заблокировала. Таким образом, в распределенных БД необходимо обеспечить передачу следующих сообщений о блокировках: 1) послать запросы на блокировку во все узлы, 2) получить подтверждение о реализации блокирования (при поступлении запроса на блокировку прежде всего проверяется, не заблокирован ли элемент данных другой транзакцией; если элемент не заблокирован, он блокируется), 3) после завершения операции (чтения или обновления) требуется посылка запросов на снятие блокировки во все узлы, где хранится информация. при работе с блокировками транзакции чтения достаточно блокировать одну копию данных, находящуюся в соответствующем узле сети, а транзакция обновления должна блокировать все копии данных, находящихся в разных узлах сети. При этом, вообще говоря, транзакция может прочитать элемент данных из любой копии, содержащей этот элемент, даже если она блокирована по чтению другой транзакцией. Однако обновить элемент транзакция может только в том случае, если блокированы по записи все копии, содержащие этот элемент данных, именно этой транзакцией. Блокировка по чтению (возможность чтения) будет обеспечена до тех пор, пока другая транзакция не установит блокировку по записи. Для одного и того же элемента данных не могут одновременно существовать блокировки по чтению и записи. Таким образом, блокировка по чтению необходима, в общем случае, только для того, чтобы до завершения чтения никакая транзакция не могла модифицировать этот элемент данных. Метод 1. Использование графа предшествования . В графе предшествования узлам соответствуют транзакции, а ребрам - сведения о блокировках и освобождениях данных. Направленное ребро выходит из узла, который снимает блокировку элемента данных (Освободить), и ведет к узлу, который эти данные блокирует (Захватить). Наличие циклов в таком графе означает существование тупиковых ситуаций, когда ни одна транзакция не закончена, и все они находятся в состоянии ожидания разблокирования элементов данных, необходимых для продолжения их выполнения. Пример. Пусть имеется следующая последовательность запросов и действий транзакций, представленная на рис.49. (А, В, С - элементы данных):тупик (цикл) возникает, если для двух различных элементов данных необходимо исполнение двух транзакций в разном порядке. порядок, в котором различные транзакции блокируют элемент данных, должен соответствовать приводимому к последовательному расписанию. В схеме с основным узлом установка и снятие блокировок для всех транзакций происходят для основного узла. Когда поступает запрос на блокировку, проверяется, не заблокирован ли элемент данных, находящийся в основном узле, другой транзакцией. Если элемент не заблокирован, он блокируется. При синхронизации распределенных обновлений заблокировать можно не один основной узел, а несколько узлов. В узле находится свой локальный граф предшествования, в котором связь с остальной частью сети представлена специальной вершиной В этой схеме возможна глобальная тупиковая ситуация, хотя ни один из локальных графов не содержит циклов. Для обнаружения подобной ситуации узлы связывают свои локальные графы попарно через специальные внешние вершины до тех пор, пока не будет обнаружена тупиковая ситуация.При синхронизации распределенных обновлений на основе блокировок в центральном узле может находиться общий граф предшествования. В этом случае все узлы посылают запросы на установку и снятие блокировок в центральный узел. Расписание и соответствующий граф предшествования Метод 2. Временные метки . При использовании временных меток исключается возможность возникновения тупиковых ситуаций. Каждой транзакции при входе в сеть присваивается уникальная метка, например, показание часов глобальной сети, дополненное идентификатором сети. Каждый элемент в БД имеет временные метки последних выполненных над ним транзакций чтения (метка чтения) и обновления (метка записи). Если транзакция Т1 запрашивает операцию, которая вступает в конфликт с операцией, уже выполняемой в соответствии с более поздней по времени транзакцией Т2, Т1 запускается вновь. Конфликт между Т1 и Т2 возникает: Случай 1. Если операция транзакции Т1 есть операция чтения, но объект уже записан транзакцией Т2. Анализ ситуации: 1) объект прочитан транзакцией Т2, то есть своего состояния не изменил, и конфликт не возникает; 2) конфликт может возникнуть, поскольку объект записан транзакцией Т2, но транзакция Т1 не знает, что объект изменен и может быть настроена на обработку объекта, находящегося в состоянии до его изменения транзакцией Т2. Случай 2. Если операция транзакции Т1 есть операция записи, но объект уже был записан или прочитан транзакцией Т2. Анализ ситуации: Конфликт может возникнуть в любом случае, поскольку транзакция Т2 не знает, что состояние объекта изменено транзакцией Т1. Если транзакция перезапускается, ей присваивается новая временная метка. Замечание. Хотя тупиковые ситуации исключаются, могут возникать избыточные отказы и перезапуски, например, последовательность действий RT2 WT1 RT2 может быть абсолютно корректной, но приводит к рестарту транзакции Т1 (случай 2). Метод 3. Системы с голосованием . Каждому узлу дана возможность «голосовать» в пользу обновления. Известны два подхода. Подход 1. Запрос на обновление выполняется, если за проведение обновления проголосовали все узлы. Подход 2. Запрос на обновление выполняется, если за проведение обновления проголосовало большинство узлов. Замечание. Считается, что ни один узел не может одновременно голосовать за выполнение двух конфликтных транзакций. При наличии запроса на обновление узел может выдать один из следующих сигналов: 1) проведение обновления, 2) отклонение обновления, 3) возможна тупиковая ситуация, 4) узел воздерживается от голосования по данному запросу.
|
Последнее изменение этой страницы: 2019-03-31; Просмотров: 505; Нарушение авторского права страницы



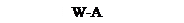 Пример 1. Расписание последовательное
Пример 1. Расписание последовательное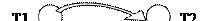 T1 : W-B
T1 : W-B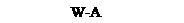
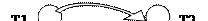 T2 : W-А
T2 : W-А
 T2 : W-А
T2 : W-А