
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Конвейерная организация работы идеального микропроцессора.Стр 1 из 13Следующая ⇒
Виртуальная память. Виртуальная память - это программно-аппаратное средство расширения пространства памяти, представляемой программе в качестве оперативной. Физически реализуется с помощью оперативной и дисковой памяти под управлением операционной системы. Виртуальное пространство памяти разбито на страницы фиксированного размера. В физической памяти присутствует лишь часть из них. Остальные находятся на диске, откуда ОС может программно организовать замещение страниц, называемое свопингом (swapping).
Конвейерная организация работы идеального микропроцессора. Ø Выполнение каждой команды складывается из ряда последовательных этапов (шагов, стадий), суть которых не меняется от команды к команде. Ø С целью увеличения быстродействия процессора и максимального использования всех его возможностей в современных микропроцессорах используется конвейерный принцип обработки информации. Ø Этот принцип подразумевает, что в каждый момент времени процессор работает над различными стадиями выполнения нескольких команд, причем на выполнение каждой стадии выделяются отдельные аппаратные ресурсы. Ø По очередному тактовому импульсу каждая команда в конвейере продвигается на следующую стадию обработки, выполненная команда покидает конвейер, а новая поступает в него. Ø В различных процессорах количество и суть этапов различаются. Рассмотрим принципы конвейерной обработки информации на примере пятиступенчатого конвейера, в котором выполнение команды складывается из следующих этапов: 1. IF (Instruction Fetch) - считывание команды в процессор; 2. ID (Instruction Decoding) - декодирование команды; 3. OR (Operand Reading) - считывание операндов; 4. EX (Executing) - выполнение команды; 5. WB (Write Back) - запись результата. Так как в каждом такте могут выполняться различные стадии обработки команд, то длительность такта выбирается исходя из максимального времени выполнения всех стадий. Кроме того, следует учитывать, что для передачи команды с одной стадии на другую иногда требуется определенное дополнительное время (Δt), связанное с записью промежуточных результатов обработки в буферные регистры. Очевидно, что при достаточно длительной работе конвейера его быстродействие будет существенно превышать быстродействие, достигаемое при последовательной обработке команд. Это увеличение будет тем больше, чем меньше длительность такта конвейера и чем больше количество выполненных команд. Сокращение длительности такта достигается, в частности, разбиением выполнения команды на большое число этапов, каждый из которых включает в себя относительно простые операции и поэтому может выполняться за короткий промежуток времени. Так, если в микропроцессоре Pentium 4 длина конвейера составляла 5 ступеней (при максимальной тактовой частоте 200 МГц), то в Pentium-4 - уже 20 ступеней (при максимальной тактовой частоте на сегодняшний день 3,4 ГГц).
Конфликты по управлению. Конфликты по управлению возникают при конвейеризации команд переходов и других команд, изменяющих значение счетчика команд.
В то же время команда условного перехода уже в такте 3 должна прочитать необходимые ей признаки, чтобы правильно сформировать адрес следующей команды. Если конвейер имеет большую глубину (например, 20 ступеней), то промежуток времени между формированием признака результата и тактом, где он анализируется, может быть еще большим. В инженерных задачах примерно каждая шестая команда является командой условного перехода, поэтому приостановки конвейера при выполнении команд переходов до определения истинного направления перехода существенно скажутся на производительности процессора. Наиболее эффективным методом снижения потерь от конфликтов по управлению служит предсказание переходов. Суть данного метода заключается в том, что при выполнении команды условного перехода специальный блок микропроцессора определяет наиболее вероятное направление перехода, не дожидаясь формирования признаков, на основании анализа которых этот переход реализуется. Процессор начинает выбирать из памяти и выполнять команды по предсказанной ветви программы (так называемое исполнение по предположению, или "спекулятивное" исполнение). Однако так как направление перехода может быть предсказано неверно, то получаемые результаты с целью обеспечения возможности их аннулирования не записываются в память или регистры (то есть для них не выполняется этап WB), а накапливаются в специальном буфере результатов. Если после формирования анализируемых признаков оказалось, что направление перехода выбрано верно, все полученные результаты переписываются из буфера по месту назначения, а выполнение программы продолжается в обычном порядке. Если направление перехода предсказано неверно, то буфер результатов очищается. Также очищается и конвейер, содержащий команды, находящиеся на разных этапах обработки, следующие за командой условного перехода. При этом аннулируются результаты всех уже выполненных этапов этих команд. Конвейер начинает загружаться с первой команды другой ветви программы. Так как конвейерная обработка эффективна при большом числе последовательно выполненных команд, то перезагрузка конвейера приводит к значительным потерям производительности. Поэтому вопросам эффективного предсказания направления ветвления разработчики всех микропроцессоров уделяют большое внимание.
Конфликты по данным. Конфликты по данным возникают в случаях, когда выполнение одной команды зависит от результата выполнения предыдущей команды. При обсуждении этих конфликтов будем предполагать, что команда i предшествует команде j Программные объекты A и B (команды, операторы, программы) являются независимыми и могут выполняться параллельно, если выполняется следующее условие:
где In(A) - набор входных, а Out(A) - набор выходных переменных объекта A. Если условие (1) не выполняется, то между A и B существует зависимость и они не могут выполняться параллельно. Если условие (1) нарушается в первом терме, то такая зависимость называется прямой. ПРИМЕР: A: R = R1 + R2 Здесь операторы A и B не могут выполняться одновременно, так как результат A является операндом B. Если условие нарушено во втором терме, то такая зависимость называется обратной: A: R = R1 + R2 B: R1 = C1 + C2 Здесь операторы A и B не могут выполняться одновременно, так как выполнение B вызывает изменение операнда в A. Наконец, если условие не выполняется в третьем терме, то такая зависимость называется конкуренционной: A: R = R1 + R2 B: R = C1 + C2 Здесь одновременное выполнение операторов дает неопределенный результат. Увеличение параллелизма любой программы заключается в поиске и устранении указанных зависимостей. Типы конфликтов по данным 1) Конфликты типа RAW (Read After Write): команда j пытается прочитать операнд прежде, чем команда i запишет на это место свой результат. При этом команда j может получить некорректное старое значение операнда. 2) Конфликты типа WAR (Write After Read): команда j пытается записать результат в приемник, прежде чем он считается оттуда командой i, При этом команда i может получить некорректное новое значение операнда.
Способы обращения к памяти Существуют различные способы выбора той ячейки, для которой выполняется операция записи или чтения. Средства выбора ячейки и передачи информации в ячейку или из нее образуют средства доступа (или выборки). Сверхоперативное ОЗУ Сверхоперативное ОЗУ – это быстродействующая память, размещенная в одном кристалле с МП или же внешняя по отношению к кристаллу МП, но находящаяся на той же плате вычислителя, и используемая в качестве высокоскоростного буфера между МП и относительно медленной оперативной памятью. К СОЗУ относится кэш-память (в переводе слово «кэш» означает склад или тайник), которая в современных компьютерах строится по двухуровневой схеме: 1) первичный КЭШ или L1 Cache (Level 1Cache) – кэш 1 уровня (это внутренний кэш МП 486 и старше) 8 Кбайт в процессорах 486DX и 32, 64 Кбайт и более в современных моделях. 2) вторичный кэш или L2 Cache (Level2Cache) – кэш второго уровня. Обычно это внешний кэш, установленный на системной плате. В МП Pentium Pro и Pentium II-IV вторичный кэш расположен в одном корпусе с процессором. В настоящее время размер в некоторых компьютерах применяется кэш 3 уровня. Кэш — это быстродействующая память, предназначенная для временного хранения программного кода и данных. Обращения к встроенной кэш-памяти происходят без состояний ожидания, поскольку ее быстродействие соответствует возможностям процессора, т.е. кэш-память первого уровня (или встроенный кэш) работает на частоте процессора. Использование кэш-памяти сглаживает традиционный недостаток компьютера, состоящий в том, что оперативная память работает более медленно, чем центральный процессор (так называемый эффект “бутылочного горлышка”). Благодаря кэш-памяти процессору не приходится ждать, пока очередная порция программного кода или данных поступит из относительно медленной основной памяти, что приводит к ощутимому повышению производительности. Кэширование дисковой памяти Система кэширования (буферизации) может быть применена и для обмена данными между основной памятью и памятью на магнитных дисках. Используя кэш-память емкостью несколько десятков мегабайт, реализованную на запоминающих элементах СБИС, можно увеличить эквивалентную скорость обращения к магнитным дискам примерно в 2-10 раз.
Динамическая память. Ø Используется динамическая память (DRAM) в современных ПК в качестве оперативной памяти общего назначения, а также как память для видео-адаптера. Ø Моделью одной ячейки динамической памяти служит конденсатор. Ø Заряд конденсатора способен сохраняться относительно небольшой промежуток времени. Из-за малой емкости конденсатора и паразитных утечек время хранения заряда на конденсаторе ограничено. Поэтому периодически информацию необходимо восстановить, осуществить процесс регенерации данных. Ø Для восстановления при считывании или записи содержимое целой строки переносится в регистр, а затем содержимое регистра переносится в строку ячеек динамической памяти. То есть происходит перезаряд конденсаторов. Однако, учитывая информационную емкость, низкую стоимость, малое число транзисторов в одном запоминающем элементе, этот тип памяти во многих случаях предпочтительнее памяти статического типа. В режиме хранения ключевые транзисторы заперты. При выборке данного ЗЭ транзисторы открыты. Запоминающая емкость через открытые транзисторы подключается к разрядной шине (РШ), и в зависимости от заряженного или разряженного состояния конденсатора различно влияет на потенциал разрядной шины. При записи потенциал от РШ передается на конденсатор и заряжает его, определяя состояние запоминающей емкости. Для сокращения времени доступа к динамической памяти применяются специальные режимы работы оперативной памяти: Ø режим расслоения (интерливинг) Ø страничный режим.
155. Интерливинг (режим расслоения) Память организовывается таким образом, что возможно к параллельных обращений в память по адресам из различных блоков. Использование режима интерливинга предполагает не совсем обычное разбиение памяти на банки (части). Если при обычном разбиении (последовательной адресации) адреса следующего банка начинаются после окончания адресов предыдущего, то при интерливинге адреса банков чередуются. То есть, например, после первого адреса первого банка следует первый адрес второго банка, затем второй адрес первого банка и второй адрес второго банка и т.д. Получается, что в одном банке четные слова, а в другом — нечетные. Таких чередующихся банков может быть не только два, а четыре, восемь, шестнадцать. Объемы банков при этом должны быть одинаковыми. В результате такого подхода появляется возможность начинать обращение к следующему слову еще до окончания процесса доступа к предыдущему.
Обработка прерываний.
Процессор заканчивает выполнение команды из адреса 5000. Затем он сохраняет в стеке текущее значение счетчика команд (5001) и текущее значение PSW. После этого процессор читает из адреса 4 памяти код вектора прерывания. Пусть этот код равен 6000. Процессор переходит в адрес памяти 6000 и приступает к выполнению программы обработки прерывания, начинающейся с этого адреса. Пусть эта программа заканчивается в адресе 6100. Дойдя до этого адреса, процессор возвращается к выполнению прерванной программы. Для этого он извлекает из стека значение адреса (5001), на котором его прервали, и бывшее в тот момент PSW. Затем процессор читает команду из адреса 5001 и дальше последовательно выполняет команды основной программы. Отметим, что в более сложных случаях в таблице векторов прерываний могут находиться не адреса начала программ обработки прерываний, а так называемые дескрипторы (описатели) прерываний. Но конечным результатом обработки этого дескриптора все равно будет адрес начала программы обработки прерываний.
Ярусно-параллельная форма
Для скалярного параллелизма часто используют термин мелкозернистый параллелизм (МЗП), в отличие от крупнозернистого параллелизма (КЗП), к которому относят векторный параллелизм и параллелизм независимых ветвей.
Критерии классификации параллельных компьютеров. Основные понятия классификации. Критерии классификации параллельных ЭВМ могут быть разными: Ø вид соединения процессоров, Ø способ функционирования процессорного поля, Ø область применения и т.д. Одна из наиболее известных классификаций параллельных ЭВМ предложена Флинном и отражает форму реализуемого ЭВМ параллелизма. Гетерогенные процессоры. Отдельные кластеры могут быть объединены в единую кластерную конфигурацию –кластер высшего уровня, или метакластер (Metacluster). Метакластерный принцип позволяет создавать распределенные метакластерные конфигурации на базе локальных или глобальных сетей передачи данных. При этом, естественно, уменьшается степень связности подкластеров метакластерной конфигурации. Системное программное обеспечение метакластера обеспечивает возможность реализации гетерогенных систем (неоднородная система, состоящая из однородных частей), включающих подкластеры различной архитектуры на различных программно-аппаратных платформах. Для оптимизации организации на суперкомпьютерах «СКИФ» параллельного счета задач как с крупноблочным (явным статическим или скрытым динамическим) параллелизмом, так и с конвейерным или мелкозернистым явным параллелизмом, с большими потоками информации, требующими обработки в реальном режиме времени, концепция предусматривает возможность реализации универсальной двухуровневой архитектуры суперкомпьютеров: Ø 1-й уровень – базовый (кластерный) архитектурный уровень; Ø 2-й уровень – потоковый архитектурный уровень, реализующий модель потоковых вычислений (data-flow). Концепция предусматривает реализацию потокового архитектурного уровня как на базе однородной вычислительной среды (ОВС) с использованием оригинальных СБИС ОВС, разрабатываемых в рамках Программы, так и на базе других структурных и технических. По сути вычислительные модули потокового уровня являются сопроцессорами вычислительных ресурсов кластерной конфигурации. Предпосылкой объединения двух программно-аппаратных решений (кластерного и потокового) для организации параллельной обработки в рамках одной вычислительной системы является то, что эти два подхода своими сильными сторонами компенсируют недостатки друг друга. Тем самым, в общем случае, каждая прикладная проблема может быть разбита на: − фрагменты со сложной логикой вычисления, с крупноблочным, эффективно реализуемые на кластерном уровне с использованием Т-системы и других систем поддержки параллельных вычислений; − фрагменты с простой логикой вычисления, с конвейерным или мелкозернистым явным параллелизмом, с большими потоками информации, требующими обработки в реальном режиме времени, эффективно реализуемые на потоковом уровне. Рассмотренные архитектурные принципы создания суперкомпьютеров семейства «СКИФ» позволяют эффективно реализовать любые виды параллелизма. Архитектура является открытой и масштабируемой, т.е. не накладывает жестких ограничений к программно-аппаратной платформе узлов кластера, топологии вычислительной сети, конфигурации и диапазону производительности суперкомпьютеров. Модуль потокового уровня, или базовый вычислительный модуль (БВМ) однородной вычислительной среды (ОВС) предназначен для потоковой обработки информации с помощью матрицы процессорных элементов. Потоковая обработка информации построена на принципах параллельной конвейерной обработки. Матрица процессорных элементов является основным вычислительным устройством базового вычислительного модуля (БВМ). Она состоит из нескольких плат с установленными на них БИС ОВС, соединенных шлейфами. Управление матрицей процессорных элементов осуществляется с помощью платы управления. Таблица функций неисправностей Таблица функций неисправностей Пусть Е = {e1, е2, …, еn} – множество всех возможных последовательностей входных наборов, любую из которых можно подать на объект в процессе диагностирования; S = {s1,..., sr} – множество всех возможных состояний объекта; s0 – исправное техническое состояние объекта. Множество контролируемых выходов объектов, то есть тех выходов, значения сигналов на которых определяют реакцию объекта на элементарные проверки, обозначим через W = {w1,w2, ..., wm}. Таблица функций неисправностей в общем случае представляет собой прямоугольную таблицу, которая содержит матрицу исправного объекта M0 и матрицы M1, M2, …, Mr объектов с неисправностями из множества S. Строки матриц соответствуют элементарным проверкам из множества Е, а столбцы – контролируемым выходам из множества W.
Обозначим Мi (Е) и Мi (Т) – матрицы ТФН i-го технического состояния (i=0, 1,..., r) для некоторых последовательностей Е и Т.Последовательность Т є Е называется контролирующим тестом, если для любой неисправности sk є S, для которой выполняется условие: То есть контролирующий тест обеспечивает проверку всех неисправностей, которые, в принципе, могут быть проверены. Последовательность называется диагностическим тестом, если для любой пары si, sj неисправностей, для которой выполняется условие: Другими словами, диагностический тест – это тест, на котором различимо максимально возможное число пар неисправностей. Очевидно, что данные два определения могут выполняться для нескольких тестов, обладающих разной избыточностью и длиной. При проведении диагностирования желательно иметь тесты как можно меньшей длины. Это сокращает время диагностирования и объем необходимого информационного обеспечения. Задача построения такого теста – одна из главных и наиболее сложных в технической диагностике. Как правило (!!!?), современные системы автоматизации проектирования электронных устройств имеют специальные подсистемы построения тестов.
Методы построения тестов. Различают методы случайного и детерминированного формирования тестов. Методы направленного поиска тестов настолько сложны, что порой их просто невозможно построить. Процесс построения тестов на основе методов направленного поиска состоит из следующих этапов: 1) определение списка рассматриваемых неисправностей; 2) вычисление тестового набора для очередной неисправности из списка; 3) моделирование схемы на тестовом наборе для выявления подмножества обнаруживаемых неисправностей; 4) определение полноты проверки схемы на построенном тесте. Процесс построения тестов на основе методов случайного поиска состоит из следующих этапов: 1) определение списка рассматриваемых неисправностей; 2) моделирование схемы на случайном наборе для выявления подмножества обнаруживаемых неисправностей; Решение относительно включения случайного набора в тест. Существует два подхода к построению тестов, основанные на 1) Методах направленного поиска; 2) Методах случайного поиска. К методам направленного построения тестов относятся: Метод Рота; Метод разностных нормальных форм; Метод Армстронга и др. Задача построения тестов методами направленного построения формулируется следующим образом: 1. Определить множество неисправностей заданного класса; 2. Выбрать очередную неисправность и вычислить тест, покрывающий данную неисправность. Генерация тестовых последовательностей с помощью алгоритмических способов (направленного построения тестов) позволяет определить тесты для всех обнаруживаемых неисправностей. В этом смысле алгоритмические способы являются полными способами генерации тестов. Вместе с тем при больших размерах схемы время генерации тестового множества сильно возрастает. Теоретически время растет экспоненциально с ростом числа вентилей; для реальных схем время генерации пропорционально 2—3-й степени числа вентилей. Задача построения тестов методом случайного по поиска формулируется следующим образом: 1) Определить множество неисправностей заданного класса; 2) Случайным образом выбрать входной вектор – претендент в тесты; 3) Определить контролирующую способность вектора; 4) Принять решение относительно приема претендента в тест. В связи с этим метод случайного поиска теста еще называют методом построения теста на основе моделирования неисправностей. Метод позволяет получить за короткое время высокий коэффициент обнаружения неисправностей. Моделирование неисправностей заключается в следующем. Проводится логическое моделирование неисправной схемы на некотором входном наборе. Если при этом выходные значения исправной и неисправной схем различаются, то входной набор считается тестовым набором для данной неисправности. Другими словами, моделирование неисправностей является методом определения обнаруживаемых неисправностей для заданного набора. На практике задача построения тестов решается с применением обоих подходов: Ø На первом этапе применяется случайный подход; Ø В последующем в случае крайней необходимости подключается направленный поиск, если имеются необходимые средства поиска. Для построения системы генерации тестов необходимо эффективно решать задачу моделирования неисправностей и анализа контролирующей способности тестов.
Симптомы неисправностей. Допустим, что на первой контрольной точке обнаруживается множество неисправностей F 1 = { a , b , k , m }, на второй – F 2 = { a ,с, d }, на третьей – F 3 = { b , m }и на четвёртой – F 4 = { a , d , m }. В этом случае 1100 – это симптом неисправности a, 1010 – неисправности b,
F 1 = { a , b , k , m }, F 2 = { a ,с, d }, F 3 = { b , m } F 4 = { a , d , m }. Словари неисправностей содержат симптомы неисправностей и помогают локализовать какую-либо неисправность из полученного списка подозреваемых неисправностей. Но из-за сложности моделируемых электронных схем применение словарей не всегда эффективно. Переферия компьютера. Как правило периферийные устройства компьютеров делятся на устройства ввода, устройства вывода и внешние запоминающие устройства (осуществляющие как ввод данных в машину, так и вывод данных из компьютера). Основной обобщающей характеристикой устройств ввода/вывода может служить скорость передачи данных. Любая ЭВМ представляет собой сложную систему, включающую в себя большое количество различных устройств. Связь устройств ЭВМ между собой осуществляется с помощью сопряжений, которые в вычислительной технике называются интерфейсами. Интерфейс - это совокупность программных и аппаратных средств, предназначенных для передачи информации между компонентами ЭВМ, включающая электронные схемы, линии, шины и сигналы адресов, данных и управления, алгоритмы передачи сигналов и правила интерпретации сигналов устройствами. Интерфейсы характеризуются следующими параметрами: 1) пропускная способность - количество информации, которая может быть передана через интерфейс в единицу времени; 2) максимальная частота передачи информационных сигналов; 3) максимально допустимое расстояние между устройствами; 4) общее число проводов (линий) в интерфейсе; 5) информационная ширина интерфейса - число бит или байт данных, передаваемых параллельно через интерфейс. Динамическим параметром интерфейса является время передачи отдельного слова и блока данных с учетом продолжительности процедур подготовки и завершения передачи. Разработка систем вв-выв требует решения целого ряда проблем: 1) Необходимо обеспечить возможность реализации ЭВМ с переменным составом оборудования, в первую очередь, с различным набором устройств ввода-вывода, с тем, чтобы пользователь мог выбирать конфигурацию машины в соответствии с ее назначением, легко добавлять новые устройства и отключать те, в использовании которых он не нуждается; 2) Для эффективного и высокопроизводительного использования оборудования компьютера следует реализовать параллельную во времени работу процессора над вычислительной частью программы и выполнение периферийными устройствами процедур ввода-вывода; 3) Необходимо упростить для пользователя и стандартизовать программирование операций ввода-вывода, обеспечить независимость программирования ввода-вывода от особенностей того или иного периферийного устройства; 4) В ЭВМ должно быть обеспечено автоматическое распознавание и реакция процессора на многообразие ситуаций, возникающих в УВВ. Главным направлением решения проблем является магистрально-модульный способ построения ЭВМ: все устройства, составляющие компьютер, включая и микропроцессор, организуются в виде модулей, которые соединяются между собой общей магистралью. Обмен информацией по магистрали удовлетворяет требованиям некоторого общегоинтерфейса, установленного для магистрали данного типа. Каждый модуль подключается к магистрали посредством специальных интерфейсных схем(Иi) -адаптеров. На интерфейсные схемы модулей возлагаются следующие задачи: Ø обеспечение функциональной и электрической совместимости сигналов и протоколов обмена модуля и системной магистрали; Ø преобразование внутреннего формата данных модуля в формат данных системной магистрали и обратно; Ø обеспечение восприятия единых команд обмена информацией и преобразование их в последовательность внутренних управляющих сигналов. Эти интерфейсные схемы могут быть достаточно сложными и по своим возможностям соответствовать универсальным микропроцессорам. Такие адаптеры схемы принято называть контроллерами. Контроллеры обладают высокой степенью автономности, что позволяет обеспечить параллельную во времени работу периферийных устройств и выполнение программы обработки данных микропроцессором. Недостатком магистрально-модульного способа организации ЭВМ является невозможность одновременного взаимодействия более двух модулей, что ставит ограничение на производительность компьютера. Поэтому этот способ, в основном, используется в ЭВМ, к характеристикам которых не предъявляется очень высоких требований, например в персональных ЭВМ.
Диковые накопители Основной механизм дисковых накопителей выглядит так: Слой носителя информации – магнитный, оптический или, возможно, другой нанесен на рабочие поверхности дисков. Диски вращаются с помощью шпинделя, приводимого в движение двигателем, который обеспечивает требуемую частоту вращения в рабочем режиме. На диске имеется индексный маркер, который, проходя мимо специального датчика, отмечает начало каждого оборота диска. Информация на диске располагается на концентрических треках (дорожках), нумерация которых начинается с внешнего трека (Track 00). Каждый трек разделен на секторы фиксированного размера. Сектор и является минимальным блоком информации, который может быть записан на диск или считан с диска. Нумерация секторов начинается с 1 и привязывается к индексному маркеру. Каждый сектор имеет служебную область, содержащую адресную информацию, контрольные коды и некоторую другую информацию, и область данных, размер которой традиционно составляет 512 байт. Если накопитель имеет несколько рабочих поверхностей (на шпинделе м. б. размещен пакет дисков, а у каждого диска м. б. использованы две поверхности), то совокупность всех треков с одинаковыми номерами составляет цилиндр. Для каждой рабочей поверхности в накопителе имеется своя головка (Head), обеспечивающая запись и чтение. Головки нумеруются начиная с 0. Для того, чтобы произвести элементарную операцию обмена – запись или чтение сектора – шпиндель должен вращаться с заданной скоростью, блок головок должен быть подведен к требуемому цилиндру, и только тогда требуемый сектор подойдет к выбранной головке, начнется физическая операция обмена данными между головкой и блоком электроники накопителя. Контроллер накопителя выполняет сборку и разборку блоков информации (секторов или целых треков), включая формирование и проверку контрольных кодов, осуществляет модуляцию и демодуляцию сигналов головок и управляет всеми механизмами накопителя. Скорость вращения у дисков различна – 4200 об./мин и выше. Высокие скорости вращения порождают проблемы с балансировкой, гироскопическим эффектом и аэродинамикой головок. Для магнитных головок весьма критичным является расстояние от головки до поверхности магнитного слоя носителя. В НГМД в нерабочем положении головка поднята над поверхностью диска на несколько мм, а в рабочем прижимается к поверхности диска специальным электромагнитным приводом. Однако непосредственный контакт с поверхностью допустим лишь при малых скоростях движения носителя. В накопителях с высокой скоростью вращения головки поддерживаются на микроскопическом расстоянии от рабочей поверхности аэродинамической подъемной силой. «Падение» головки на рабочую поверхность, которое произойдет, если диск остановится, может повредить как головку, так и поверхность диска. Чтобы этого не происходило, в нерабочем положении головки «паркуются», т.е. отводятся в нерабочую зону, где допустимо их «приземление». В современных накопителях парковка осуществляется автоматически при снижении напряжения питания или скорости вращения шпинделя ниже допустимого значения. Кроме того, контроллер современных дисков не выпустит головок из зоны парковки, пока шпиндель не наберет заданных оборотов. Высота «полета» головки должна выдерживаться довольно строго, иначе магнитные поля головок будут «промахиваться» мимо рабочего слоя. Для позиционирования головок на нужный цилиндр в современных накопителях применяется привод головок с подвижной катушкой. В таком приводе блок головок связан с катушкой индуктивности, помещенной в магнитное поле постоянного магнита. При протекании тока через катушку на нее начинает действовать сила, пропорциональная силе тока, которая вызовет перемещение катушки, а, следовательно, и блока головок. Привод, обеспечивающий точное позиционирование по сигналу обратной связи, называется сервоприводом. Управление сервоприводом может быть оптимизировано по времени установления головок на требуемую позицию: когда отклонение от заданного положения велико, можно подавать больший ток, вызывающий большое ускорение блока. По мере приближения ток уменьшается. Такая система привода позволяет сократить время доступа до единиц милисекунд и менее. Для получения сигналов обратной связи о местоположении головок прямо на диске размещаются сервометки – вспомогательная информация для «системы наведения». Они записываются при сборке накопителя. По месту размещения сервометок различают накопители с выделенной сервоповерхностью и со встроенными сервометками. Сервоголовка для следящей системы дает информацию практически непрерывно, что улучшает качество процесса поиска и слежения. Недостатком является то, что сервоинформация (сигнал обратной связи) доступна дискретно с периодом в один оборот диска. Для точного позиционирования приходится выжидать несколько оборотов. Более быстродействующий вариант – размещение сервометок перед каждым сектором, что позволяет выйти на заданный трек даже за доли оборота шпинделя. Преимущества встроенных сервометок в том, что возможна компенсация любых изменений геометрии, поскольку система наводит головки именно по тому треку, к которому осуществляется доступ. Информация на дисках записывается и считывается посекторно. В начале каждого сектора имеется заголовок, за которым следует поле данных и поле контрольного кода. В заголовке имеется поле идентификатора, включая номер цилиндра, головки и собственно сектора. В этом же идентификаторе может содержаться и пометка о дефектности сектора, служащая указанием на невозможность его использования для хранения данных. Достоверность поля идентификатора проверяется с помощью контрольного кода заголовка. Заголовки секторов записываются только во время операции низкоуровневого форматирования, причем для всего трека сразу. Поле данных сектора отделено от заголовка небольшой зоной, а завершает сектор контрольный код поля данных. Итак, структура трека – последовательность секторов – задается при его форматировании, а начало трека определяется контроллером по сигналу от индексного датчика. Нумерация секторов может быть произвольной. При обращении к сектору он определяется по идентификатору, а если за оборот диска (или за несколько оборотов) сектор с указанным номером не будет найден, контроллер зафиксирует ошибку – Sector not found – сектор не найден. Забота о поиске сектора по его заголовку, помещение в его поле данных записываемой информации, снабженной контрольным кодом, а также считывание информации и ее проверка лежит на контроллере накопителя. Контроллер управляет, поиском затребованного цилиндра и коммутацией головок, выбирая нужный трек. Низкоуровневое форматирование-это процедура создания секторов диска, которая для каждого накопителя должна быть выполнена перед его использованием по назначению. Процедура сводится к тому, что каждый трек диска размечается и верифицируется. При разметке трека на нем формируются заголовки серверов, а в поля данных записывается некоторый код – заполнитель. Особенности современных контроллеров дисковых накопителей Это сложные электронные устройства, разрабатываемые на основе микропроцессоров. Хранение данных на носителе информации всегда сопровождается появлением ошибок по разным причинам: дефект поверхности носителя, случайное перемагничивание участка носителя, попадание посторонней частицы под головку, неточность позиционирования головки над треком, колебание головки по высоте, вызванное внешней вибрацией, уходом разных параметров. Независимо от причин, ошибки должны быть выявлены и по возможности исправлены. Для этого применяются специальные коды с исправлением ошибок. Если сектор считывается с ошибкой, контроллер автоматически выполнит повторное считывание, и при случайности ошибки велик шанс правильно считывания сектора. Если данные так и не удалось считать верно, контроллер обязан сигнализировать об этом установкой бита ошибки контрольного кода в байте состояния, на что программа может отреагировать сообщением вида «Data Error». Общепринятой технологией кэширования диска является упреждающее считывание: Если контроллер получает запрос на чтение сектора, то он автоматически считает в буфер и секторы, следующие за запрошенным. Весьма вероятный запрос к следующему сектору будет обслужен из буфера без задержки. Более «умные» контроллеры идут дальше: они считывают в буфер весь трек, как только выполняется команда позиционирования.
Файловые системы. Файловая система - это часть операционной системы, назначение которой состоит в том, чтобы обеспечить пользователю удобный интерфейс при работе с данными, хранящимися на диске, и обеспечить совместное использование файлов несколькими пользователями и процессами. В широком смысле понятие "файловая система" включает: совокупность всех файлов на диске, наборы структур данных, используемых для управления файлами, такие, например, как каталоги файлов, дескрипторы файлов, таблицы распределения свободного и занятого пространства на диске, комплекс системных программных средств, реализующих управление файлами, в частности: создание, уничтожение, чтение, запись, именование, поиск и другие операции над файлами. Имена файлов Файлы идентифицируются именами. Пользователи дают файлам символьные имена, при этом учитываются ограничения ОС как на используемые символы, так и на длину имени. Обычно разные файлы могут иметь одинаковые символьные имена. В этом случае файл однозначно идентифицируется так называемым составным именем, представляющем собой последовательность символьных имен каталогов. Файлы бывают разных типов: обычные файлы, специальные файлы, файлы-каталоги. Обычные файлы в свою очередь подразделяются на текстовые и двоичные. Текстовые файлы состоят из строк символов, представленных в ASCII-коде. Текстовые файлы можно прочитать на экране и распечатать на принтере. Все операционные системы должны уметь распознавать хотя бы один тип файлов - их собственные исполняемые файлы. Специальные файлы - это файлы, ассоциированные с устройствами ввода-вывода, которые позволяют пользователю выполнять операции ввода-вывода, используя обычные команды записи в файл или чтения из файла. Эти команды обрабатываются вначале программами файловой системы, а затем на некотором этапе выполнения запроса преобразуются ОС в команды управления соответствующим устройством. Каталог - это, с одной стороны, группа файлов, объединенных пользователем исходя из некоторых соображений, а с другой стороны - это файл, содержащий системную информацию о группе файлов, его составляющих. В каталоге содержится список файлов, входящих в него, и устанавливается соответствие между файлами и их характеристиками. В разных файловых системах могут использоваться в качестве атрибутов разные характеристики, например: информация о разрешенном доступе, пароль для доступа к файлу, владелец файла, создатель файла, признак "только для чтения", признак "скрытый файл", признак "системный файл", признак "архивный файл", признак "двоичный/символьный", признак "временный" (удалить после завершения процесса), признак блокировки, длина записи, указатель на ключевое поле в записи, длина ключа, времена создания, последнего доступа и последнего изменения, текущий размер файла, максимальный размер файла. Каталоги могут непосредственно содержать значения характеристик файлов, как это сделано в файловой системе MS-DOS, или ссылаться на таблицы, содержащие эти характеристики, как это реализовано в ОС UNIX (рисунок 2.31). Каталоги могут образовывать иерархическую структуру за счет того, что каталог более низкого уровня может входить в каталог более высокого уровня. Логическая организация файла Программист имеет дело с логической организацией файла, представляя файл в виде определенным образом организованных логических записей. Логическая запись - это наименьший элемент данных, которым может оперировать программист при обмене с внешним устройством. Физическая организация и адрес файла Физическая организация файла описывает правила расположения файла на устройстве внешней памяти, в частности на диске. Файл состоит из физических записей - блоков. Блок - наименьшая единица данных, которой внешнее устройство обменивается с оперативной памятью. Непрерывное размещение - простейший вариант физической организации, при котором файлу предоставляется последовательность блоков диска, образующих единый сплошной участок дисковой памяти. Для задания адреса файла в этом случае достаточно указать только номер начального блока. Определить права доступа к файлу - значит определить для каждого пользователя набор операций, которые он может применить к данному файлу. В разных файловых системах может быть определен свой список дифференцируемых операций доступа. Этот список может включать следующие операции: создание файла, уничтожение файла, открытие файла, закрытие файла, чтение файла, запись в файл, дополнение файла, поиск в файле, получение атрибутов файла, установление новых значений атрибутов, переименование, выполнение файла, чтение каталога, Нейрон. Нейронная сеть. Нейрокомпьютинг – это научное направление, занимающееся разработкой вычислительных систем шестого поколения - нейрокомпьютеров, которые состоят из большого числа параллельно работающих простых вычислительных элементов (нейронов). Элементы связаны между собой, образуя нейронную сеть. Они выполняют единообразные вычислительные действия и не требуют внешнего управления. Большое число параллельно работающих вычислительных элементов обеспечивают высокое быстродействие. Прототипом для создания нейрона послужил биологический нейрон головного мозга. Биологический нейрон имеет : тело, совокупность отростков - дендридов, по которым в нейрон поступают входные сигналы, и отросток - аксон, передающий выходной сигнал нейрона другим клеткам. Точка соединения дендрида и аксона называется синапсом. Упрощенно функционирование нейрона можно представить следующим образом: 1) нейрон получает от дендридов набор (вектор) входных сигналов; 2) в теле нейрона оценивается суммарное значение входных сигналов. Однако входы нейрона неравнозначны. Каждый вход характеризуется некоторым весовым коэффициентом, определяющим важность поступающей по нему информации. Таким образом, нейрон не просто суммирует значения входных сигналов, а вычисляет скалярное произведение вектора входных сигналов и вектора весовых коэффициентов; 3) нейрон формирует выходной сигнал, интенсивность которого зависит от значения вычисленного скалярного произведения. Если оно не превышает некоторого заданного порога, то выходной сигнал не формируется вовсе - нейрон "не срабатывает"; выходной сигнал поступает на аксон и передается дендридам других нейронов. Нейрокомпьютеры отличаются от ЭВМ предыдущих поколений не просто большими возможностями. Принципиально меняется способ использования машины. Место программирования занимает обучение, нейрокомпьютер учится решать задачи. Обучение - корректировка весов связей, в результате которой каждое входное воздействие приводит к формированию соответствующего выходного сигнала. После обучения сеть может применять полученные навыки к новым входным сигналам. При переходе от программирования к обучению повышается эффективность решения интеллектуальных задач. В нейронной сети нет локальных областей, в которых запоминается конкретная информация. Вся информация запоминается во всей сети. Отличия нейрокомпьютеров от вычислительных устройств предыдущих поколений: Ø параллельная работа большого числа простых вычислительных устройств обеспечивает огромное быстродействие; Ø нейронная сеть способна к обучению, которое осуществляется путем настройки параметров сети; Ø высокая помехо- и отказоустойчивость нейронных сетей; В настоящее время наиболее массовым направлением нейрокомпьютинга является моделирование нейронных сетей на обычных компьютерах, прежде всего персональных. В основу искусственных нейронных сетей положены следующие черты живых нейронных сетей, позволяющие им хорошо справляться с нерегулярными задачами: Ø простой обрабатывающий элемент - нейрон; Ø очень большое число нейронов участвует в обработке информации; Ø один нейрон связан с большим числом других нейронов (глобальные связи); Ø изменяющиеся веса связей между нейронами; Ø массированная параллельность обработки информации. Поведение искусственной нейронной сети зависит как от значения весовых параметров, так и от функции возбуждения нейронов. Известны три основных вида функции возбуждения: пороговая, линейная и сигмоидальная. Для пороговых элементов выход устанавливается на одном из двух уровней в зависимости от того, больше или меньше суммарный сигнал на входе нейрона некоторого порогового значения. Для линейных элементов выходная активность пропорциональна суммарному взвешенному входу нейрона. Для сигмоидальных элементов в зависимости от входного сигнала, выход варьируется непрерывно, но не линейно, по мере изменения входа. Сигмоидальные элементы имеют больше сходства с реальными нейронами, чем линейные или пороговые, но любой из этих типов можно рассматривать лишь как приближение. Нейронная сеть представляет собой совокупность большого числа сравнительно простых элементов - нейронов, топология соединений которых зависит от типа сети. Чтобы создать нейронную сеть для решения какой-либо конкретной задачи, мы должны выбрать, каким образом следует соединять нейроны друг с другом, и соответствующим образом подобрать значения весовых параметров на этих связях. Задачи, решаемые на основе нейронных сетей В литературе встречается значительное число признаков, которыми должна обладать задача, чтобы применение НС было оправдано и НС могла бы ее решить: Ø отсутствует алгоритм или не известны принципы решения задач, но накоплено достаточное число примеров; Ø проблема характеризуется большими объемами входной информации; Ø данные неполны или избыточны, зашумлены, частично противоречивы. Таким образом, НС хорошо подходят для распознавания образов и решения задач классификации, оптимизации и прогнозирования. Нейронные сети могут быть реализованы двумя путями: первый - это программная модель НС, второй – аппаратная. Большинство сегодняшних нейрокомпьютеров представляют собой просто персональный компьютер или рабочую станцию, в состав которых входит дополнительная нейроплата.
Модели нейронных сетей. Модель Маккалоха Основные положения теории деятельности головного мозга : Ø разработана модель нейрона как простейшего процессорного элемента, выполняющего вычисление переходной функции от скалярного произведения вектора входных сигналов и вектора весовых коэффициентов; Ø предложена конструкция сети таких элементов для выполнения логических и арифметических операций; Ø сделано основополагающее предположение о том, что такая сеть способна обучаться, распознавать образы, обобщать полученную информацию. Недостатком данной модели является сама модель нейрона - "пороговый" вид переходной функции. В формализме У. Маккалоха и У. Питтса нейроны имеют состояния 0, 1 и пороговую логику перехода из состояния в состояние. Каждый нейрон в сети определяет взвешенную сумму состояний всех других нейронов и сравнивает ее с порогом, чтобы определить свое собственное состояние. Пороговый вид функции не предоставляет нейронной сети достаточную гибкость при обучении и настройке на заданную задачу. Если значение вычисленного скалярного произведения, даже незначительно, не достигает до заданного порога, то выходной сигнал не формируется вовсе и нейрон "не срабатывает". Это значит, что теряется интенсивность выходного сигнала (аксона) данного нейрона и, следовательно, формируется невысокое значение уровня на взвешенных входах в следующем слое нейронов. Модель Розенблата. В 1958 году он предложил свою модель нейронной сети. Розенблат ввел в модель Маккаллока и Питтса способность связей к модификации, что сделало ее обучаемой. Эта модель была названа перцептроном. Первоначально перцептрон представлял собой однослойную структуру с жесткой пороговой функцией процессорного элемента и бинарными или многозначными входами. Первые перцептроны были способны распознавать некоторые буквы латинского алфавита. Впоследствии модель перцептрона была значительно усовершенствована. Алгоритм обучения перцептрона выглядит следующим образом: Ø системе предъявляется эталонный образ; если выходы системы срабатывают правильно, весовые коэффициенты связей не изменяются; если выходы срабатывают неправильно, весовым коэффициентам дается небольшое приращение в сторону повышения качества распознавания. Серьезным недостатком перцептрона является то, что не всегда существует такая комбинация весовых коэффициентов, при которой имеющееся множество образов будет распознаваться данным перцептроном. Данная проблема не является единственной трудностью, возникающей при работе с перцептронами - также слабо формализован и метод обучения перцептрона. Модель Хопфилда Начало современному математическому моделированию нейронных вычислений было положено работами Хопфилда в 1982 году, в которых была сформулирована математическая модель ассоциативной памяти на нейронной сети. Показано, что для однослойной нейронной сети со связями типа "все на всех" характерна сходимость к одной из конечного множества равновесных точек, которые являются локальными минимумами функции энергии, содержащей в себе всю структуру взаимосвязей в сети. Хопфилд и Тэнк показали, как конструировать функцию энергии для конкретной оптимизационной задачи и как использовать ее для отображения задачи в нейронную сеть. Привлекательность подхода Хопфилда состоит в том, что нейронная сеть для конкретной задачи может быть запрограммирована без обучающих итераций. Веса связей вычисляются на основании вида функции энергии, сконструированной для этой задачи. Способом обратного распространения называется способ обучения многослойных нейронных сетей В таких НС связи между собой имеют только соседние слои. При этом каждый нейрон предыдущего слоя связан со всеми нейронами последующего слоя. Нейроны обычно имеют сигмоидальную функцию возбуждения. Первый слой нейронов называется входным и содержит число нейронов, соответствующее распознаваемому образу. Последний слой нейронов называется выходным и содержит столько нейронов, сколько классов образов распознается. Между входным и выходным слоями располагается один или более скрытых (теневых) слоев Определение числа скрытых слоев и числа нейронов в каждом слое для конкретной задачи является неформальной задачей. Принцип обучения такой нейронной сети базируется на вычислении отклонений значений сигналов на выходных процессорных элементах от эталонных и обратном "прогоне" этих отклонений до породивших их элементов с целью коррекции ошибки.
Нейрокомпьютеры Нейрокомпьютеры являются перспективным направлением развития современной высокопроизводительной вычислительной техники, а теория нейронных сетей и нейроматематика представляют собой приоритетные направления российской вычислительной науки. Основой активного развития нейрокомпьютеров является принципиальное отличие нейросетевых алгоритмов решения задач от однопроцессорных, малопроцессорных, а также транспьютерных. Для данного направления развития вычислительной техники не так важен уровень развития отечественной микроэлектроники, поэтому оно позволяет создать основу построения российской элементной базы суперкомпьютеров.
Виртуальная память. Виртуальная память - это программно-аппаратное средство расширения пространства памяти, представляемой программе в качестве оперативной. Физически реализуется с помощью оперативной и дисковой памяти под управлением операционной системы. Виртуальное пространство памяти разбито на страницы фиксированного размера. В физической памяти присутствует лишь часть из них. Остальные находятся на диске, откуда ОС может программно организовать замещение страниц, называемое свопингом (swapping).
Конвейерная организация работы идеального микропроцессора. Ø Выполнение каждой команды складывается из ряда последовательных этапов (шагов, стадий), суть которых не меняется от команды к команде. Ø С целью увеличения быстродействия процессора и максимального использования всех его возможностей в современных микропроцессорах используется конвейерный принцип обработки информации. Ø Этот принцип подразумевает, что в каждый момент времени процессор работает над различными стадиями выполнения нескольких команд, причем на выполнение каждой стадии выделяются отдельные аппаратные ресурсы. Ø По очередному тактовому импульсу каждая команда в конвейере продвигается на следующую стадию обработки, выполненная команда покидает конвейер, а новая поступает в него. Ø В различных процессорах количество и суть этапов различаются. Рассмотрим принципы конвейерной обработки информации на примере пятиступенчатого конвейера, в котором выполнение команды складывается из следующих этапов: 1. IF (Instruction Fetch) - считывание команды в процессор; 2. ID (Instruction Decoding) - декодирование команды; 3. OR (Operand Reading) - считывание операндов; 4. EX (Executing) - выполнение команды; 5. WB (Write Back) - запись результата. Так как в каждом такте могут выполняться различные стадии обработки команд, то длительность такта выбирается исходя из максимального времени выполнения всех стадий. Кроме того, следует учитывать, что для передачи команды с одной стадии на другую иногда требуется определенное дополнительное время (Δt), связанное с записью промежуточных результатов обработки в буферные регистры. Очевидно, что при достаточно длительной работе конвейера его быстродействие будет существенно превышать быстродействие, достигаемое при последовательной обработке команд. Это увеличение будет тем больше, чем меньше длительность такта конвейера и чем больше количество выполненных команд. Сокращение длительности такта достигается, в частности, разбиением выполнения команды на большое число этапов, каждый из которых включает в себя относительно простые операции и поэтому может выполняться за короткий промежуток времени. Так, если в микропроцессоре Pentium 4 длина конвейера составляла 5 ступеней (при максимальной тактовой частоте 200 МГц), то в Pentium-4 - уже 20 ступеней (при максимальной тактовой частоте на сегодняшний день 3,4 ГГц).
|
Последнее изменение этой страницы: 2019-04-10; Просмотров: 415; Нарушение авторского права страницы
 Выполнение команд в таком конвейере
Выполнение команд в таком конвейере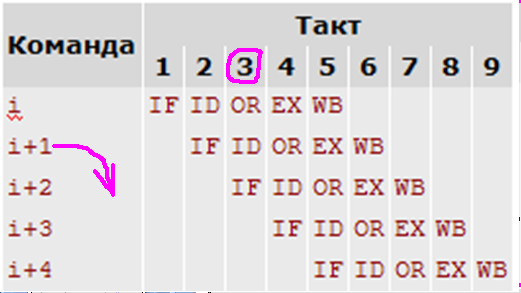 Пусть в программе, представленной таблицей, команда i+1 является командой условного перехода, формирующей адрес следующей команды в зависимости от результата выполнения команды i. Команда i завершит свое выполнение в такте 5.
Пусть в программе, представленной таблицей, команда i+1 является командой условного перехода, формирующей адрес следующей команды в зависимости от результата выполнения команды i. Команда i завершит свое выполнение в такте 5.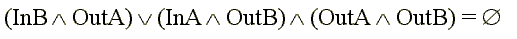
 Процесс регенерации приводит к снижению быстродействия. Это основной недостаток DRAM .
Процесс регенерации приводит к снижению быстродействия. Это основной недостаток DRAM . Пусть, например, процессор выполнял основную программу и команду, находящуюся в адресе памяти 5000 (условно). В этот момент он получил запрос прерывания с номером (адресом вектора) 4.
Пусть, например, процессор выполнял основную программу и команду, находящуюся в адресе памяти 5000 (условно). В этот момент он получил запрос прерывания с номером (адресом вектора) 4. Ширина параллелизма первого яруса этой ЯПФ (первый такт) сильно зависит от числа операций, включаемых в состав ЯПФ. Так, в примере для l1 = 4 параллелизм первого такта равен двум, для l2 = 12 параллелизм равен пяти.
Ширина параллелизма первого яруса этой ЯПФ (первый такт) сильно зависит от числа операций, включаемых в состав ЯПФ. Так, в примере для l1 = 4 параллелизм первого такта равен двум, для l2 = 12 параллелизм равен пяти.  На пересечении i-й строки и j-го столбца k-й матрицы проставляется значение ai,j,k сигнала на выходе wj объекта с неисправностью sk при элементарной проверке еi.
На пересечении i-й строки и j-го столбца k-й матрицы проставляется значение ai,j,k сигнала на выходе wj объекта с неисправностью sk при элементарной проверке еi.
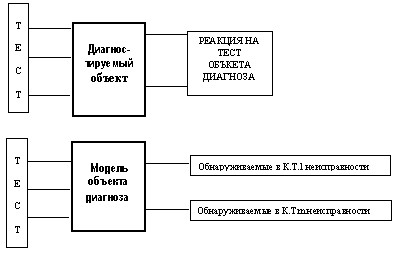 0100 – неисправности c и 1011 – неисправности с.
0100 – неисправности c и 1011 – неисправности с.