|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Основні параметри виведенняСтр 1 из 10Следующая ⇒
Введення Почати опис можливостей продукту Rational Purify хочеться перефразуванням одного дуже відомого вислову: «з точністю до мілліБАЙТА ». Дане порівняння не випадково, адже саме цей продукт спрямований на вирішення всіх проблем, пов'язаних з витоками пам'яті. Ні для кого не секрет, що багато програмних продуктів поводять себе «Не надто скромно », замикаючи на себе під час роботи всі системні ресурси без великої на то необхідності. Подібна ситуація може виникнути внаслідок небажання програмістів доводити створений код «до розуму », але частіше подібне відбувається не з-за ліні, а через неуважність. Це зрозуміло - сучасні темпи розробки ПЗ в умовах найжорстокішого пресингу з боку конкурентів не дозволяють приділяти занадто багато часу оптимізації коду, адже для цього необхідні і висока кваліфікація, і наявність достатньої кількості ресурсів проектного часу. Як мені бачиться, маючи в своєму розпорядженні надійний інструмент, який би сам в процесі роботи над проектом вказував на всі чорні діри в використанні пам'яті, розробники почали б його повсюдне впровадження, підвищивши надійність створюваного ПЗ. Адже і тут ні для кого не секрет, що в більшості складних проектів першочергове завдання, що стоїть перед розробниками полягає в заміщенні стандартного оператора «new» в С ++, так як він НЕ зовсім адекватно себе поводить при розподілі пам'яті.
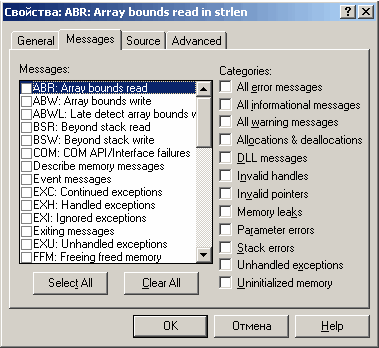
Загальні можливості по управлінню Purify схожі з Quantify, за винятком специфіки самого продукту. Тут також можна тестувати багатопотокові програми, також можна робити «зліпки» пам'яті під час тестування програми. Особливості використання цього додатка стосуються специфікою відловлюючих помилок і способом видачі інформації. Основні параметри виведення · Address. IP адреса модуля, в якому виявлено помилку або попередження; · Error Location. Опис модуля з помилкою. В випадку тестування модуля з вихідними текстами, то в даному полі можна переглянути фрагмент коду, який викликав появу помилки; · Allocate Location. Різновид «Error Location », показує фрагмент коду, в якому був розподілений блок пам'яті, робота з яким, призвела до помилки Робота з Purify можлива як при наявності вихідних текстів і налагоджувальної інформації, так і без неї. В разі відсутності debug-інформації аналіз помилок ведеться тільки по ip-адресах. Так само як і в випадку з Quantify, можливий детальний перегляд функцій з dll-бібліотек. В цьому випадку наявність налагоджувальної інформації не є необхідністю. Повідомлення про помилки та попередження Для того, щоб мати уявлення про можливості продукту, опишемо те, які помилки і потенційні помилки можуть бути присутніми в тестованому додатку. Відзначимо різницю між помилкою і потенційної помилкою і опишемо: · Помилка - Доконаний факт нестабільної або некоректної роботи програми, призводить до неадекватних дій додатка або системи. Прикладом подібної помилки можна вважати вихід за межі масиву або спроба запису даних за 0 адресою; · Потенційна помилка - в додатку є фрагмент коду, який при нормальному виконанні не призводить до помилок. Помилка виникає тільки в разі збігу обставин, або не проявляє себе ніколи. До даної категорії можна віднести такі особливості, як ініціалізація масиву з ненульової адреси, скажімо, є масив на 100 байт, але кожен раз звернення до нього виробляється з 10 елемента. В цьому випадку Purify вважає, що є потенційний витік пам'яті розміром в 10 байт. Природно, що подібна поведінка може бути викликана специфікою додатка, наприклад, так поводитися може текстовий редактор. Тому в Purify застосується поділ інформації на помилки і потенційні помилки (які можна сприймати як специфіку). Список помилок і потенційних помилок досить об'ємний і постійно поповнюється. Коротко опишемо основні повідомлення, що виводяться після тестування: · Array Bounds Read Вихід за межі масиву при читанні; · Array Bounds Write Вихід за межі масиву при записі; · Late Detect Array Bounds Write Повідомлення вказує, що програма записала значення перед початком або після кінця розподіленого блоку пам'яті; · Beyond Stack Read Повідомлення вказує, що функція в програмі збирається читати поза поточного покажчика вершини стека; · Freeing Freed Memory Спроба звільнення вільного блоку пам'яті; · Freeing Invalid Memory Спроба звільнення некоректного блоку пам'яті; · Freeing Mismatched Memory Повідомлення вказує, що програма пробує; · Free Memory Read Спроба читання вже звільненого блоку пам'яті; · Free Memory Write Спроба запису вже звільненого блоку пам'яті; · Invalid Handle Операції над неправильним дескриптором; · Invalid Pointer Read \ Write Помилка при читанні \ записі з недоступного блоку пам'яті; · Memory Allocation Failure Помилка в запиті на розподіл пам'яті; · Memory Leak Витік пам'яті; · Potential Memory Leak Потенційний витік пам'яті; · Null Pointer Read Спроба читання з нульової адреси; · Null Pointer Write Спроба запису в нульовий адрес; · Uninitialized Memory Copy Спроба копіювання непроініціалізірованного блоку; · UMR: Uninitialized Memory Read Спроба читання непроініціалізірованного блоку. Попередження і помилки зручно групувати за певними ознаками, щоб легше можна було відшукати потрібне попередження і відкинути непотрібні. Відзначимо категорії і приналежність до них різних повідомлень: · Allocation And deallocation. Робота з пам'яттю; · DLL messages. Інформаційні повідомлення по зовнішнім бібліотекам; · Invalid handles. Неправильний дескриптор; · Invalid pointers. Неправильний покажчик; · Memory leaks. Витік пам'яті; · Parameter errors. Помилка параметра; · Stack errors. Помилка при роботі зі стеком; · Unhandled exception. Виняток; · Uninitialized memory. Використання непроініціалізірованного блоку пам'яті. Багато статичних помилок можуть виловлювати компілятори на етапі розробки програмного модуля або програми. На цьому етапі переваги Purify НЕ дуже видно. Всі механізми аналізу помилок відкриваються при виконанні додатка, при динамічно мінливих умовах. Розглянемо більш докладно список відловлювальних помилок, визначивши їх приналежність до категорій з прикладами на C ++ / C: ABR: Array Bounds Read. Вихід за межі масиву при читанні. #include < iostream.h> ptr [0] = 'e'; ABW: Array Bounds Write. Вихід за межі масиву при записі. Відзначимо, що пам'ять можна визначити статично, масовому, як показано в прикладі. А можна динамічно (наприклад, виділивши блок пам'яті по ходу виконання додатка). За замовчуванням, Purify успішно справляється тільки з динамічним розподілом, чітко виводячи повідомлення про помилку. В випадку статичного розподілу, все залежить від розмірів «Купи» і налаштувань компілятора. #include < iostream.h> BSR: Beyond Stack Read. Повідомлення вказує, що функція в програмі збирається читати поза поточного покажчика вершини стека Категорія: Stack Error #include < windows.h> int main (int, char **) cerr < < «element # " < < i < < «Is " < < block [i] < < '\ n'; FFM: Freeing Freed Memory. Спроба звільнення вільного блоку пам'яті. В великому додатку важко відстежити момент розподілення блоку і момент звільнення. Дуже часто методи реалізуються різними розробниками, і, відповідно, можлива ситуація, коли розподілений блок пам'яті звільнюєтьсядвічі на різних ділянках програми. Категорія: Allocations And deallocations #include < iostream.h> FIM: Freeing Invalid Memory. Спроба звільнення некоректного блоку пам'яті. Розробники часто плутають прості статичні значення і покажчики, намагаючись звільнити те, що НЕ звільняється. Компілятор завжди здатний проаналізувати і нейтралізувати даний вид помилки. Категорія: Allocations And deallocations #include < iostream.h> int main (int, char **) FMM: Freeing Mismatched Memory. Повідомлення вказує, що програма пробує звільняти пам'ять з неправильним ВИКЛИКОМ API для того типу пам'яті. Категорія: Allocations And deallocations #include < windows.h> int main (int, char **) HeapDestroy (heap_first); FMR: Free Memory Read. Спроба читання вже звільненого блоку пам'яті Все та ж проблема з покажчиком. Блок розподілений, звільнений, а потім, в відповідь на подію, по покажчику починають записуватися (Або читатися) дані. Категорія: Invalid pointers #include < iostream.h> FMW: Free Memory Write. Спроба запису вже звільненого блоку пам'яті Категорія: Invalid pointers #include < iostream.h> HAN: Invalid Handle. Операції над неправильним дескриптором Категорія: Invalid handles #include < iostream.h> HIU: Handle In Use. Індикація витоку ресурсів. Неправильна індикація дескриптора. #include < iostream.h> cerr < < «Помилка відкриття, створення файлу \ n "; if (ptr == NULL) { IPR: Invalid Pointer Read. Помилка звернення до пам'яті, коли програма намагається зробити читання з недоступної області. Категорія: Invalid pointers #include < iostream.h> #include < windows.h> for (Int I = 0; i < 2; i ++) { IPW: Invalid Pointer Write. Помилка звернення до пам'яті, коли програма намагається зробити запис з недоступної області Категорія: Invalid pointers #include < iostream.h> for (Int I = 0; i < 2; i ++) { MAF: Memory Allocation Failure. Помилка в запиті на розподіл пам'яті. Виникає в випадках, коли проводиться спроба розподілити занадто великий блок пам'яті, наприклад, коли вичерпано файл підкачки. Категорія: Allocations And deallocations #include < iostream.h> MLK: Memory Leak. Витік пам'яті Поширений варіант помилки. Багато сучасних програм грішать тим, що НЕ віддають системі розподілені ресурси по закінченні своєї роботи. Категорія: Memory leaks #include < windows.h> MPK: Potential Memory Leak. Потенційний витік пам'яті Категорія: Memory leaks #include < iostream.h> NPR: Null Pointer Read. Спроба читання з нульової адреси Категорія: Invalid pointers #include < iostream.h> NPW: Null Pointer Write. Спроба запису в нульовий адрес Категорія: Invalid pointers #include < iostream.h> UMC: Uninitialized Memory Copy. Спроба копіювання непроініціалізірованного блоку пам'яті Категорія: Unitialized memory #include < iostream.h> int main (int, char **) } delete [] pointer; UMR: Uninitialized Memory Read. Спроба читання непроініціалізірованного блоку пам'яті Категорія: Unitialized memory #include < iostream.h> Робота з фільтром Щоб не захаращувати користувальницький інтерфейс зайвими даними, в Purify передбачена система гнучких фільтрів. Фільтри створюються і призначаються і модифікуються через верхнє меню (View → CreateFilter і View → FilterManager). За замовчуванням Purify виводить всі повідомлення і попередження.
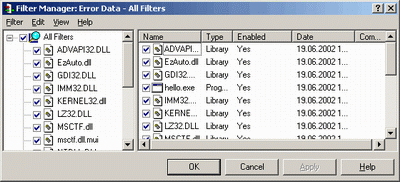
Малюнок показує зовнішній вигляд вікна створення фільтра (View → CreateFilter). Тут ми маємо можливість по вибору повідомлень, які потрібно фільтрувати. Пункт General - управляє ім'ям фільтру і коментарем, його супроводжуючим, Source - визначає місце розташування вихідних файлів, для яких необхідно вивести повідомлення. Підхід використовується в тому випадку, коли відбувається виклик одного модуля з іншого, щоб обмежити кількість інформації в звіті.
Вище згадувалося, що Purify НЕ обмежує число фільтрів. Слід розуміти, що НЕ обмежується НЕ тільки загальне число фільтрів, але і їх кількість на один протестований додаток. Обмеження по модулям, яке також можна виставити в даному діалозі, визначає число зовнішніх модулів, попередження від яких з'являються в звіті. API Rational Purify також має ряд функцій інтерфейсу, впливаючи на які, розробник на етапі створення програми може користуватися всіма благами, що надаються даним додатком. Функції установки статусу розподілених блоків: · PurifyMarkAsInitialized. Встановлює позначку на вказаний блок, роблячи його поміченим, як проініціалізований; · PurifyMarkAsUninitialized. Ставить прапор ініціалізації; Функції тестування станів розподілених блоків · PurifyAssertIsReadable. Перевіряє, чи доступний блок пам'яті для читання; · PurifyAssertIsWritable. Перевіряє, чи доступний блок пам'яті для запису; · PurifyIsInitialized. Перевіряє, проініціалізований блок пам'яті чи ні; · PurifyIsReadable. Перевіряє блок пам'яті на можливість читання; · PurifyIsWritable. Перевіряє блок пам'яті на можливість запису; Функції, що визначають руйнування · PurifySetLateDetectScanCounter. Визначає лічильник сканування купи. Підраховує кількість операцій. За замовчуванням, Purify сканує пам'ять через кожні 200 операцій з пам'яттю, або кожні 10 секунд; · PurifySetLateDetectScanInterval. Визначає інтервал пошуку купи. За замовчуванням - 10 секунд; · PurifyHeapValidate. Примусово перевіряє пам'ять на наявність помилок; Функції, що визначають витоку пам'яті · PurifyAllInuse. Повертає значення, що визначає кількість використаної пам'яті; · PurifyClearInuse. Повертає значення, яке показує кількість пам'яті, розподіленої після останнього дзвінка PurifyClearInuse або PurifyNewInuse; · PurifyAllLeaks. Повертає число знайдених витоків у пам'яті. Знаходить як прямі витоки пам'яті, так і непрямі; · PurifyClearLeaks. Визначає число звільнених блоків пам'яті за час останнього звернення до PurifyClearLeaks або PurifyAllLeaks; · PurifyNewLeaks. Визначає число нових витоків пам'яті за час останнього звернення до PurifyNewLeaks або PurifyClearLeaks. Збереження даних і експорт Purify дозволяє зберігати результати тестування (file → save copy as) в чотирьох різних уявленнях, що дозволяють найбільш ефективним чином отримати інформацію про хід тестування. Розглянемо варіанти збереження: · Purify Error unfiltered. Зберігає дані про тестуванні в вигляді «Як є »без фільтрів; · Purify error filtered. Зберігає дані про тестування з застосованими фільтрами; · Text expended. Зберігає дані в текстовому вигляді про тестування в розширеному поданні (з виведенням знайдених помилок, з коротким описом); · Text view. Зберігається тільки згадка про знайдені помилки, без додаткового опису. При встановленому MS Outlook, можливо відправлення звіту поштою через пункт file → send з верхнього меню Purify. Параметри тестування Перед виконанням тестованої програми, можливо, задати додаткові налаштування, які зможуть налаштувати Purify на ефективне тестування. Запуск програми проводиться точно також як і в випадку з Quantify (по F5 або file → Run). Параметри налаштування знаходяться пункті Settings, вікна, що з'явилося. Перша сторінка діалогу представлена на малюнку
Відзначимо основні особливості, які якісно можуть позначитися на результуючому звіті: · Report AT Exit. Дана група дозволяє отримувати більш детальну інформацію про всіх покажчиках і блоках пам'яті, що не приводили до помилок пам'яті. За замовчуванням, Purify виводить звіти тільки по тим блокам, які були розподілені, але НЕ були звільнені. В більшості випадків такий підхід виправданий, так як зазвичай розробника цікавлять саме помилки. Інші пункти активізують по мірі необхідності, коли потрібно мати загальне уявлення про використання пам'яті тестованим додатком; · Error Suppretion. Група визначає ступенем детальності виведеної інформації. · Call Stack Length. Визначає глибину стека; · Red Zone Length. Управляє числом байтів, яке вбудовується в код тестованої програми при операціях пов'язаних з розподілом пам'яті. Збільшення числа сприяє кращому збору інформації, але істотно гальмує виконання додатка; Закладка PowerCheck дозволить налаштувати рівень аналізу кожного окремо взятого модуля. Існує два способи інструментації тестованої програми: Precise і Minimal. В першому випадку проводиться детальне інструментування коду, але при цьому модуль працює відносно повільно. Під другому випадку, проводиться коротке інструментування, при якому Purify вносить в модуль менше налагоджувальної інформації, і, як наслідок, здатна відловити менше число помилок. Останній підхід виправданий, коли додаток викликає масу зовнішніх бібліотек від третіх фірм, котрі не будуть піддаватися правці. Введення Основне призначення продукту - виявлення ділянок коду, пропущеного при тестуванні додаткиа- перевірка області охоплення коду. Очевидно, що при тестуванні розробнику або тестувальника НЕ вдасться перевірити працездатність всіх функцій. Також неможливо за один прохід тестування виконати додаток з урахуванням всіх умовних розгалужень. За вимогам на розробку програмного коду, програміст повинен надати для функціонального тестування стабільно працюючеийдодаток або модуль, без витоків пам'яті і повністю протестований. Поняття «повністю протестований »визначає керівництво компанії в числовому, відсотковому значенні. Тобто, при оформленні вимог зазначено, що область охоплення коду 70%. Відповідно, при досягненні даної цифри подальші перевірки коду можна вважати недоцільними. Звичайно, питання області охоплення, дуже складний і неоднозначний. Єдиною втіхою може служити те, що 100% області охоплення в великих проектах не буває. З трьох розглянутих інструментів тестування PureCoverage можна вважати найбільш простим, так як інформація їм надається - це перегляд вихідного тексту програми, де вказано скільки разів здійснилася та чи інша рядок в додатку. Особливості запуску Запуск програми ведеться точно таким же чином, як і в інших випадках. Тут нового нічого немає. З особливостей можна відзначити те, що тестувати можна тільки той додаток, що містить зневадження. Дана особливість виділяє PureCoverage з лінійки інструментів тестування для розробників, які можуть тестувати як код з налагоджування, так і без неї. Робота з PureCoverage За принципом роботи PureCoverage злегка нагадує Quantify: також підраховує кількість викликів функцій. Правда, одержувана статистика не настільки вичерпна як в Quantify (В візуальному відношенні), але для перевірки області охоплення коду цілком і цілком придатна. Система звітності представлена 4 різними видами звітів: · Coverage Browser. Основне вікно перегляду, дозволяє переглядати протестований додаток по модулям або по файлам. Видає статистику про наявність пропущених рядків; · Function List. Видає звіт по функціям; · Annotated Source. Перехід до режиму перегляду початкового тексту; · Run Summary. Загальна інформація про протестованому додатку; API Як і Quantify з Purify, даний інструмент має функції розширення інтерфейсу. Розглянемо їх короткий опис. · CoverageAddAnnotation. Дозволяє додати словесний опис, що супроводжує тестування. Інформація, задана розробником цієї функцією може бути залучена з пункту «details» меню тестування і доступна в LOG-файлі. На її основі, тестер може згодом використовувати особливі умови тестування; · CoverageClearData. Очищає незбережені дані. Використовується для обнулення (ініціалізації); · CoverageDisableRecordingData. Заборона на запис даних про хід тестування. Продовження запису не можливо. Використовується для завершення процесу тестування; · CoverageIsRecordingData. З'ясовує чи проводиться процес запису даних про хід тестування. Використовується для визначення поточного статусу; · CoverageIsRunning. Оприділяє, чи запущений інтсрумент тестування; · CoverageSaveData. Збереження тестових даних. Використовується для отримання зліпків. Зазвичай цю функцію зручно викликати перед і після блоку розгалуження в програмі; · CoverageStartRecordingData. Початок процесу запису тестових даних; · CoverageStopRecordingData. Закінчення процесу запису тестових даних; Збереження даних і експорт Дані з інструменту тестування зберігаються в текстовому файлі (як і в двох попередніх випадках). Текстовий формат видачі інформації робить можливим включати різні обробники звітів засновані на скриптових мовах (наприклад, при допомозі Perl, можна «вивудити» специфічні поля з текстового звіту і помістити їх в засіб документування, отримавши звіт). CoverageData WinMain Function D: \ xp \ Rational \ Coverage \ Samples \ hello.c D: \ xp \ Rational \ Coverage \ Samples \ hello.exe 0 1 1 100.0 5 5 10 50.00 36 1 SourceLines D: \ xp \ Rational \ Coverage \ Samples \ hello.c D: \ xp \ Rational \ Coverage \ Samples \ hello.exe PureCoverage також як і Quantify може переносити табличні дані в Microsoft Excel. Підсумок Даний інструмент є найбільш простим з трьох. Основна його відмінність - неможливість роботи з додатками, в яких відсутня налагоджувальна інформація. З достоїнств відзначимо можливість одночасного запуску спільно з Purify, що дозволяє отримати звіти по витокам пам'яті і підрахунок числа рядків за один прохід в тестуванні, що суттєво економить час при налагодженні і тестуванні. Додаткові можливості засобів тестування для розробників Способи запуску Всі інструментальні засоби можуть працювати на 3 рівнях виконання: · Виконання з меню операційної системи. Використовується в більшості випадків, як розробниками так і тестувальниками. Останніми частіше, так як у тестувальників може не бути середовища розробки; · Виконання з середовища розробки (якщо є інтеграція з конкретним засобом). Застосовується в тих випадках, коли інструмент має інтеграцію зі засобом розробки. Представляється найбільш зручним варіантом роботи для розробників; · Виконання з командного рядка. Застосовується в специфічних ситуаціях: при інтеграції з засобами автоматизованого тестування функціонального інтерфейсу, а також при тестуванні особливих додатків (таких як сервіси Win32). Типи тестів Тести продуктивності (Performance Tests) дозволяють визначити, чи працює багатокористувацька система в відповідності з необхідних стандартів при зміненні навантажень. В результаті виконання тестів вимірюються часи відгуку системи на якійсь із запитів, і на основі зібраної статистичної інформації робляться висновки про характеристиках системи. Тести продуктивності виконуються за допомогою програми LoadTest. При цьому тестуванні типово використовується навантаження сервера великою кількістю віртуальних користувачів. Наприклад, ви можете встановити таймер для одного VU, щоб визначити, скільки часу займе виконання запиту, коли тисячі інших VU посилають запити на той же самий сервер в то же самий час. Термін 'тести продуктивності' включає навантажувальні, стресові, конкуруючі і конфігураційні тести. Сукупність цих тестів дозволяє прискорити цикл тестування продуктивності і досягти значущих і точних результатів. Тестування навантаження (Load Tests) виконується тоді, коли потрібно визначити час відгуку серверів або клієнтських додатків при навантаженню, що змінюється. Тестування навантаження також використовується тоді, коли потрібно обчислити, яку максимальну кількість транзакцій може виконати сервер за певний часовий відрізок. Якщо клієнт / серверна система використовує розподілену архітектуру або засоби балансування навантаження - тестування навантаження може бути використано для того, щоб перевірити правильність обраних методів для балансування або конструювання системи. Тестування навантаження виконується як з використанням режиму тільки віртуальних користувачів, коли вимірюється час відгуку тільки серверної частини або комбінації віртуальних користувачів і користувачів графічного інтерфейсу для вимірювання часу відгуку системи для конкретного клієнтського додатку. Стресове тестування (Stress Test) - це перевірка роботи системи в екстремальних умовах, тобто, коли випробовувана система штучно ставиться в умови, які можуть призвести до збою в роботі як клієнтської або серверної частини додатків, так і всієї системи в цілому. Способів організації стресового тестування може бути безліч, наприклад: · тривала робота клієнт / серверних додатків. · виконання великої кількості транзакцій · одночасне звернення до сервера великої кількості користувачів виконують одну й ту ж операцію або комбінацію операцій віртуально в той же самий момент часу. · заповнення клієнтських форм свідомо неправильними або недостатніми даними і виконання транзакцій з цими даними. · створення умов для роботи тестованої системи з недостатньою кількістю пам'яті або поділюваних системних ресурсів. Стресове тестування дозволяє вам бути впевненими в тому, що ваш клієнтський додаток або сервер будуть зберігати працездатність незважаючи на несприятливий розподіл ресурсів в комп'ютерній системі. Конкуруюче тестування (Contention Test) виконується як комбінація GUI і VU на одному або декількох комп'ютерах, для того щоб емулювати дійсне багатокористувацьке оточення. Наприклад, можна створити тест, коли кілька GUI користувачів і безліч віртуальних користувачів в один і той же час будуть звертатися до тієї ж самійої бази даних для виявлення проблем в управлінні багатозадачністю або блокування. Без автоматизованого засобу тестування такі тести, що вимагають точної синхронізації дій великої кількості користувачів, виконати практично неможливо. Засоби тестування дозволяють створювати дуже складні сценарії багатокористувацького тестування з залученням в цей процес декількох комп'ютерів з великою кількістю GUI і VU користувачів. При цьому, наприклад, користувачі одного з комп'ютерів будуть чекати результатів виконання дій користувачами іншого комп'ютера і тільки потім вступати в процес тестування. Наприклад, користувачі на одному з комп'ютерів додають записи в базу, а на другом чекають завершення виконання цього скрипта, а потім читають внесення запису і т.п. Конфігураційне тестування (Configuration Testing). Кожен комп'ютер користувача може мати різну суміш апаратних і програмних особливостей, які створюють ризик того, що створюване програмне забезпечення буде працювати на одному з них, а на одним не буде. Знизити ймовірність виникнення таких ситуацій можна застосуванням конфігураційних тестів, коли один раз створені скрипти для GUI і VU користувачів будуть виконуватися на комп'ютерах з різними OS або конфігураціями програмних і апаратних засобів. Наприклад, якщо ви використовуєте кілька типів мережевих карт, ви можете виконати серію тестів для кожної з них з тим, щоб визначити, яка володіє кращими характеристиками. Розподілене функціональне тестування (Distributed Functional Testing). Повний цикл функціонального тестування складного клієнт / серверного додатка може зажадати виконання великої кількості скриптів. При цьому GUI скрипти будуть послідовно виконуватися з допомогою програми Robot на одному з комп'ютерів в протягом дуже довгого часу. PerformanceStudio дозволяє значно прискорити процес тестування за рахунок залучення в процес тестування більшого числа комп'ютерів і розподілу між ними GUI скриптів для виконання. Все управління процесом тестування в даному випадку бере на себе програма LoadTest, яка збирає інформацію ході процесу тестування, розподіляє скрипти між вивільненими комп'ютерами та в випадку втрати мережевого з'єднання з яким-небудь з них, передає виконуваних ним скрипт на виконання наступної звільнилася машині. Типи записи тестів Виконувана PerformanceStudio інтелектуальний запис на рівні пакетів гарантує, що скрипти, які ви записуєте, точно відображають трафік між клієнтами і серверами, незважаючи на швидкість передачі даних. Засоби тестування IBM Rational підтримують три режими інтерактивного запису скриптів: API - Записує API виклики з клієнтських додатків і клієнтських бібліотек до серверів. API режим запису являється рекомендованим підходом для всіх клієнтів, що працюють на платформі Windows NT. В цьому режимі і PerformanceStudio і клієнтську програму обидва встановлюються на клієнтський комп'ютер. Network - записує трафік по TCP / IP протоколу на рівні мережного інтерфейсу. Цей тип запису рекомендований тоді, коли покупець не підтримує API режим запису. Proxy - в цьому режимі записується той же самий трафік, що і в режимі запису Network, але для передачі пакетів між клієнтом і сервером використовується машрутізація через proxy комп'ютер. Цей спеціалізований тип запису застосовується в високошвидкісних мережах і мережах з комутаторами. Введення в Test Manager Види тестів RUP регламентує і описує безліч різних видів тестів, фокусуючих увагу на різних проектних проблемах. TestManager, будучи засобом планування тестування, відповідає за їх коректне виконання. Не буде зайвим нагадати, що створенням скриптів (бібліотеки скриптів) займається Rational Robot, фізично здійснює запис і відтворення скриптів. Отриманий набір скриптів перетвориться в план тестування, а потім в сценарій тестування безпосередньо в TestManager Розглянемо основні види тестів з RUP: · функціональне тестування; · тестування цілісності баз даних; · тестування бізнес циклів; · тестування користувальницького інтерфейсу; · профілювання продуктивності; · тестування навантаження; · стресове тестування; · об'ємне тестування; · тестування управління доступом. Тестування безпеки; · тестування відновлення після збоїв; · конфігураційне тестування; · інсталяційне тестування. Описані види тестів дозволять здійснити всебічне тестування програмного продукту. RUP регламентує всі види робіт, а також методику підготовки тестових наборів. В тому числі регламентуються такі параметри як: мета тестування, методика тестування, критерії тестування, а також визначаються особливі умови, необхідні для проведення всебічного тестування. Розглянемо докладно основні види тестів, додаткові умови тестування, вимоги до тестів і критерії завершення. Функціональне тестування Функціональне тестування об'єкта-тестування планується і проводиться на основі вимог до тестування, заданих на етапі визначення вимог. В якості вимог виступають діаграми use-case, бізнес-функції і бізнес-правила. Мета функціональних тестів полягає в тому, щоб перевірити відповідність розроблених графічних компонентів встановленим вимогам. В основі функціонального тестування лежить методика «чорного ящика ". Ідея тестування зводиться до того, що група тестувальників проводить тестування, не маючи доступу до вихідних текстів тестованої програми. При цьому під увагу приймається тільки вхідні вимоги і відповідність їм тестованим додатком. При необхідності (В відповідності до обраної раніше стратегії тестування) можна скористатися на етапі функціонального тестування підходом, званим «скляним ящиком ». В режимі «Скляного ящика »тестувальник повинен володіти мовою реалізації та тестувати код програми в відповідності з прийнятими стандартами на розробку, наприклад такими, як перевірка коду на відсутність операторів переходу (goto). Також на тестувальника покладається відповідальність за установку відповідності поточної розробки на відповідність певним канонам програмування. На етапі функціонального тестування не застосовується тестування «скляного ящика »в чистому вигляді - використовується комбінація двох видів тестування. Підхід «скляного ящика »для функціонального тестування несе ряд обмежень, і здатний проводити тестування по наступним категоріям: · тест на продуктивність; · тест на наявність помилок з пам'яттю; · тест на покриття коду. Комбіноване тестування дозволить отримати тестувальникам на виході найбільш повний звіт про відповідність тестованої програми всім встановленим вимогам на графічний інтерфейс, продуктивність коду та його стійкість. Мета тестування: Переконатися в належному функціонуванні об'єкта тестування. Тестується правильність навігації по об'єкту, а також введення, обробку і виведення даних. Методика: Необхідно виконати (програти) кожен з use-case, використовуючи як вірні значення, так і свідомо помилкові, для підтвердження правильного функціонування, по таким критеріям: · продукт адекватно реагує на всі введені дані (виводяться очікувані результати в відповідь на правильно вводяться дані); · продукт адекватно реагує на неправильно введені дані (з'являються відповідні повідомлення про помилки); · кожне бізнес-правило реалізовано належним (встановленим) чином. Критерії Завершення: Всі заплановані дії по тестуванню виконані. Всі знайдені дефекти були відповідним чином оброблені (документовані і поміщені в базу дефектів). Тестування цілісності даних і баз даних Мета Тестування: Методика: Оцінити правильність внесення даних і переконатися в коректній обробці базою вхідних значень. Критерії Завершення: Всі способи доступу функціонують, в відповідності з вимогами. Дії скрипта не призводять до втрати даних або порушення цілісності бази, або до іншим неадекватних реакцій. Тестування бізнес циклів Тестування Бізнес Циклів повинно емулювати дії, що виконуються в проекті протягом певного часового інтервалу. Період має бути визначений тривалістю в один рік. Всі події, дії і транзакції які імовірно будуть відбуватися протягом цього періоду з додатком, повинні бути відтворені. Включаються всі денні, тижневі, місячні цикли та події, які є чутливими до дати. Мета тестування: Методика: 1. тести, що застосовуються для перевірки функціонування об'єкта тестування, модифіковані для збільшення числа повторень виконання кожної функції програми, моделюванням роботи декількох користувачів протягом заданого тимчасового інтервалу; 2. всі функції, які працюють з датою або часом, коректно виконуються в будь-яких тимчасових інтервалах; 3. всі функції, виконувані в періодичних розкладах виконуються або викликаються в відповідних тимчасових інтервалах; 4. тестування включає використання правильних і неправильних дат для перевірки реакції програми Критерії завершення: Тестування для користувача інтерфейсу Мета Тестування: Перевірити об'єкти і їх характеристики (меню, розміри, положення, стан, фокус наведення і ін.) у відповідності ззагальноприйнятим стандартам на графічний інтерфейс користувача; Методика: Критерії завершення: Всі виявлені дефекти оброблені і задокументовані. Профілювання продуктивності Профілювання продуктивності - оцінка часу відгуку програми або бази, швидкості транзакцій і інших, залежних від часу параметрів. Мета робіт по профілізації - переконатися в тому, що вимоги по продуктивності додатка або бази задоволені. При профілюванні продуктивності реєструються функції поведінки продуктивності об'єкта тестування в залежності від спеціальних умов (робоча нагрузка, апаратна конфігурація, тип операційної системи). Мета Тестування: Методика: Необхідно постійно модифікувати файли даних, для збільшення (ускладнення) кількості транзакцій; Необхідно постійно модифікувати скрипти, для того, щоб збільшити кількість ітерацій, виконання кожної з транзакцій; Скрипти повинні виконуватися на одній машині (найкращий варіант для визначення продуктивності одного користувача, однією транзакцією) і повторюватися для безлічі клієнтів (віртуальних або дійсних). Критерії завершення: Всі виявлені дефекти оброблені і задокументовані. Тестування навантаження Тестування навантаження використовується для визначення поведінки об'єкта тестування в змінюючих робочих навантаженнях, для оцінки здібностей об'єкта правильно функціонувати в мінливих умовах. Мета навантажувального тестування полягає в тому, щоб визначити і гарантувати правильність роботи всіх системних функцій поза максимального робочого навантаження. В доповненні даний вид тестування забезпечує оцінку характеристик роботи об'єкта тестування (час відгуку, час транзакції, а також будь-яких операцій чутливих по часу) Мета Тестування: Методика: Змінювати склад даних, їх число і складність для збільшення часу відгуку Критерії завершення: Всі виявлені дефекти оброблені і задокументовані. Стресове тестування Стресове тестування - підвид навантажувального тестування, мета якого полягає в знаходженні помилок, поява яких спровоковано дефіцитом ресурсів (недостатня кількість вільної оперативної пам'яті або місця на диску, або недостатньої пропускної здатності мережі). Даний вид тестування дозволить ефективно відловити помилки, що не виникають при звичайному, нормальному тестуванні. Також даний вид тестування зручно використовувати для отримання інформації про пікові навантаження, після яких тестований додаток перестає працювати (або працює некоректно) Мета Тестування: · вичерпана вільна пам'ять на сервері, або її розмір близький до критичного; · одночасно до сервера звертається максимально можливе (задане) число клієнтів; · одночасно безліч користувачів виконують однакові дії з одними і тими ж записами (або різними записами). Методика: Для ефективного тестування, машина, для якої проводиться тестування, повинна навмисно мати обмежене число доступних ресурсів Критерії завершення: Всі виявлені дефекти оброблені і задокументовані. Об'ємне тестування Мета об'ємного тестування полягає в знаходженні меж розміру переданих даних. Об'ємне тестування також ідентифікує безперервне максимальне завантаження або обсяг інформації, яка може бути оброблена в заданому інтервалі часу (наприклад, об'єкт тестування обробляє набір записів для генерації звіту, а об'ємне тестування дозволить застосувати великі тестові бази даних і перевірити те, яким чином функціонує програма. Чи призвела вона правильне повідомлення). Мета Тестування: · підключено або змодельоване максимальне число клієнтів; · бізнес-функції на протязі тривалого часу коректно виконуються; · максимальний розмір бази досягнутий, а множинні запити і звіти виконані одночасно. Методика: Імітувати максимальне число клієнтів для проходження найбільш гіршого сценарію роботи системи; Створити максимальну базу і підтримувати звернення клієнтів до неї впродовж тривалого часу. Критерії завершення: Специфічні системні обмеження досягнуті або перевищені без помилок; Всі виявлені дефекти оброблені і задокументовані. Конфігураційне тестування Спеціальний вид тестування, спрямований на перевірку сумісності об'єкта тестування з різним апаратним та програмним забезпеченням. Конфігураційне тестування необхідно для гарантованої сумісності об'єкта тестування з максимально можливим обладнанням, для забезпечення надійної роботи. Також КУ має враховувати тип операційної системи. RUP має розгалужений механізм по плануванню і одночасного запуску конфігураційних тестів на різних платформах одночасно. Тест повинен враховувати такі критерії, як: встановлене програмне забезпечення (і їх версії), наявність і версії драйверів обладнання, наявність обладнання (довільній комбінаціях). Мета Тестування: Методика: До початку тестування відкрити максимальне число загальновідомих додатків; Тестування проводиться на різних платформах. Критерії завершення: Всі виявлені дефекти оброблені і задокументовані. Інсталяційне тестування Останній вид тесту в нашому списку, але перша функція, з якої користувач розпочне ознайомлення з програмним продуктом. Даний вид тестування перевіряє здатність об'єкта тестування коректно і без збоїв встановитися на комп'ютер користувача (доустановити, оновитися) з обробкою всіх можливих виняткових ситуацій (брак місця, збій харчування). Мета Тестування: 1. нова інсталяція, нова машина, що не інстальований на неї раніше; 2. оновлення існуючої версії (перевстановлення); 3. оновлення зі старої версії (апгрейд) 4. спроба установки старої версії поверх нової.
Методика: Критерії завершення: Виняткові ситуації обробляються коректно. Всі виявлені дефекти оброблені і задокументовані. Введення
Навіщо взагалі це знадобилося? Ми переслідували дві мети - введення автоматичних тестів для наших web-додатків і створення навантажувальних тестів на основі функціональних тестів. Чому для тесту використовувався саме Selenium, а не більш підходящий інструмент - LoadRunner, jMeter? За допомогою LoadRunner's навантажувальний тест був проведений, але результати були поставлені під сумніви - при емуляції двохсот користувачів сторінки завантажувалася за 2 секунди плюс-мінус 2%, хоча при відкритті цих же сторінок з браузера відображення відбувалося більш ніж за 3 секунди. Так що хотілося провести навантажувальні тести максимально наближені до реальності, а це можна зробити тільки за допомогою повної емуляції поведінки користувача. Для цього якраз підходили інструменти для функціонального тестування з їх роботою з браузерами - сайт відкривався б через звичайний браузер, тобто так як робив би це користувач.
Про Selenium
Загальна архітектура
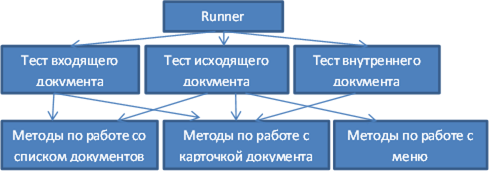
Додаток розділений на рівні (для наочності на схемі елементи кожного рівня мають осмислені назви, а не просто Тест 1, Методи 2). Перший рівень - рівень «запускальщика» тестів. Він просто запускає тести. У налаштуваннях конфігурується кількість потоків, кількість запусків тесту, класи тесту. Другий рівень - самі тести. Вони виконують бізнес операції - авторизацію, відкривають списки документів, відкривають документи, переходять по вкладках документів. Для початку перерахованих дій буде достатньо для забезпечення мінімальної роботи з системою. Надалі вони будуть додаватися. Поділ на ці рівні дає таку ж вигоду - можна запускати тести як з «запускальщика», так і без - просто запуск одного тесту з середовища розробки. Винесення атомарних користувальницьких операцій на окремий рівень дозволить надалі відмовитися від написання тестів на Java, а розробити свій DSL для того, що б тести могли писати будь-які люди.
Запуск тестів
Final Int threadCount = readThreadCount (); Final Int invocationCount = readInvocationCount (); Final List < Class> testClasses = readTestClasses (); ExecutorService taskExecutor = Executors.newFixedThreadPool (threadCount); for ( Int I = 0; i < threadCount; i ++) { taskExecutor.execute ( New TestRunner (invocationCount, testClasses)); } taskExecutor.shutdown (); taskExecutor.awaitTermination (Long.MAX_VALUE, TimeUnit.NANOSECONDS);
Код класу запускає тести
Public Class TestRunner Implements Runnable { Public Void Run () { JUnitCore jUnitRunner = New JUnitCore (); jUnitRunner.addListener ( New TimeListener ()); for ( Int I = 0; i < invocationCount; i ++) { for (Class clazz: testClasses) { jUnitRunner.run (clazz); } Thread.sleep (invocationTimeOut); } } }
Код listener 'а
Public Class TimeListener extends RunListener { Private EtmPoint Point; Public Void testStarted (Description description) throws Exception { point = EtmManager.getEtmMonitor (). createPoint (description.getClassName () + "." + description.getMethodName (); ); } Public Void testFinished (Description description) throws Exception { point.collect (); } Public Void testFailure (Failure failure) throws Exception { log.error ( " Error in test." , failure.getException ()); } }
Тести
Для написання тестів використовувався jUnit. Хоча також можна використовувати TestNG, який підтримує паралельний запуск тестів (а при навантажувальному тестуванні це обов'язкова вимога). Але обраний був саме jUnit з двох причин: 1) у компанії він широко поширений і давно використовується 2) потрібно було все одно писати свій «запускальщик» який би дозволив, не змінюючи тести, запускати їх в різних потоках (у TestNG паралельний запуск налаштовується в самих тестах) і збирати статистику щодо їх виконання. Крім тестів були написані додаткові модулі - pool webdriver'ов (тут слово webdriver використовується в термінології Selenium'а), pool користувачів, pool документів, rule (у термінології jUnit) по зняттю скріншотів при помилку, rule з видачі webdriver тесту, rule авторизації. Pool webdriver'ов - це клас, який управляє отриманням webdriver з сервера Selenium'а і розподіляє їх між тестами. Потрібен для того, що б абстрагувати роботу з Selenium'ом - тести будуть отримувати webdriver'и і віддавати їх цьому pool'у. Webdriver'и при цьому не закриваються (не викликається метод close). Це потрібно тому, що б не перезапускати браузер. Тобто таким чином виходить «реіспользованіе» webdriver'ов іншими тестами. Але повторне використання має свої мінуси - при поверненні webdriver'а в pool потрібно «підчистити» за собою - видалити всі cookie або, якщо це зробити не можна, виконати logout. Pool користувачів потрібний в основному при навантажувальному тестуванні, коли потрібно запускати однакові тести від різних користувачів. Він всього лише по колу віддає логін / пароль чергового користувача. Rule по зняттю скріншотів про помилку, потрібен, як випливає з назви, знімати скріншот про помилку виконання тесту. Він зберігає його в папку і записує в лог назва скриншота зі stacktrace'ом помилки. Дуже допомагає в подальшому «побачити» помилку, а не тільки прочитати її в логах. ( internetka.in.ua/selenium-rule-screenshot/ ) Rule авторизації потрібен так само для автоматизації, тільки тепер авторизація - щоб в кожному тестовому методі не писати login \ logout.
Збір статистики
BasicEtmConfigurator.configure (); EtmMonitor etmMonitor = EtmManager.getEtmMonitor (); etmMonitor.start (); HttpConsoleServer server = New HttpConsoleServer (etmMonitor); server.start ();
Збір статистики походив з двох місць - збирався загальний час виконання тестових методів (з рівня «запускальщика») і час виконання атомарних користувальницьких операцій (з третього рівня). Для вирішення першої проблеми використовувався спадкоємець RunListener'а, в якому перевизначаються методи початку і закінчення тесту і в них збиралася інформація про виконання. Рішення другої проблеми можна було виконати «в лоб» - на початку і наприкінці кожного методу, час виконання якого потрібно записувати, писати код для відліку цього часу. Але так як методів вже зараз більше п'яти, а надалі їх буде набагато більше, то хотілося б це автоматизувати. Для цього скористуємось AOP, а конкретно AspectJ. Був написаний простим аспектом, який додавав підрахунок часу виконання всіх public методів з класів з одними операціями. Час підраховувався тільки успішно виконаних методів, що б методи, що вилетіли з помилкою на середині виконання, не псували статистику. Так само виявився один недолік при зборі статистики за назвами методів - так як методи по роботі з одними операціями були універсальні і викликалися усіма тестами, але статистику потрібно було збирати за типами документів. Тому статистика збиралася не тільки за назвою методів, але ще й по їхніх аргументах, що ідентифікують тип документа. Код методу аспекту
Around ( " execution (public static * < Пакет з класами користувальницьких операцій>. *. * (..))" ) Public Object profileMethod (ProceedingJoinPoint thisJoinPoint) throws Throwable { EtmPoint point = EtmManager.getEtmMonitor (). CreatePoint (getPointName (thisJoinPoint)); Object result = thisJoinPoint.proceed (); point.collect (); Return Result; }
Метод getPointName формує назву точки зрізу часу на основі назви методу і його параметрів.
Конфігурація Selenium'а
У підсумку прийшли до наступної конфігурації: На одному комп'ютері запускався Selenium в режимі hub з додатковим параметром -timeout 0. Це потрібно було тому, що іноді сесії закривалися по timeout із-за тривалої бездіяльності тестів. На інших комп'ютерах запускався Selenium в режимі node. Для потужних комп'ютерів, здатних забезпечити роботу 15 браузерів, node Selenium'а запускався з додатковим налаштуванням, що дозволяє запускати 15 копій FF і вказує, що одночасно можна працювати з 15 сесіями.
Проведення тестів
Пару слів потрібно сказати про тестові сценарії і підрахунок часу їх виконання. Кожен сценарій включав в себе відкриття документів кожного типу. Тобто спочатку відкривався вхідний документ, потім вихідний документ і т.д. Ось тут потрібно врахувати наступну ситуацію - якщо потрібно зняти час відкриття тільки вхідного документа, і при цьому запустити на всіх машинах виконання тільки по сценарію, то час буде істотно менший (на 50%) ніж, якби знімати час при одночасному виконанні всіх сценаріїв. У моєму випадку, швидше за все це було пов'язано з кешуванням на рівнях web програми та СУБД. І тим, що відкривалося мало унікальних документів. Можливо, при великій кількості різних документів відмінності будуть не настільки істотні. В ідеалі хотілося б отримати розподіл користувачів і документів таким, яким воно буде в реально діючій системі. Тобто, наприклад, в реальній системі буде 10 чоловік працювати з вхідними та 30 з вихідними. І в навантажувальні тести так само відобразити це співвідношення - кількість тестів за вихідними в три рази більше ніж з вхідними документами. Але так як ще тестована система поки не ввійшла в експлуатацію та цих даних поки немає, то тестування відбувалося без їх обліку.
Підведення підсумків
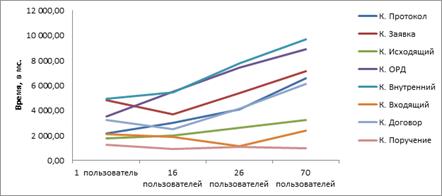
Залежність часу списку документів від кількості працюючих користувачів:
Далі тести будуть продовжуватися, щоб побудувати графік для 200 користувачів. В результаті повинен вийти графік, схожий на цей (узятий з msdn.microsoft.com/en-us/library/bb924375.aspx ):
По ньому вже можна буде точно визначити можливості системи і знайти її вузькі місця. ОРГАНІЗАЦІЯ На виділеному сервері організовується служба, до завдань якої входять: · отримання вихідного коду з репозиторію; · збірка проекту; · виконання тестів; · розгортання готового проекту; · відправка звітів. РОБОТА З репозитарій · Всі дані зберігаються в репозиторії; · Часті коммітов; · Локальна збірка перед коммітов; · Предкоммітная збірка на інтегрованому сервері; · Припинення роботи з репозиторієм до виправлення помилок; ЗБІРКА ПО РОЗКЛАДОМ Локальна збірка може здійснюватися: · за зовнішнім запитом; · за розкладом; · за фактом поновлення сховища та за іншими критеріями. У разі збірки за розкладом (daily build - щоденна збірка), вони, як правило, проводяться кожної ночі в автоматичному режимі - «нічні збірки» (щоб до початку робочого дня були готові результати тестування). Для відмінності додатково вводиться система нумерації збірок - зазвичай, кожна збірка нумерується натуральним числом, яке збільшується з кожною новою збіркою. Вихідні тексти та інші вихідні дані при взятті їх з репозиторію (сховища) системи контролю версій позначаються номером збірки. Завдяки цьому, точно така ж збірка може бути точно відтворена в майбутньому - достатньо взяти вихідні дані по потрібній мітці і запустити процес знову. Це дає можливість повторно випускати навіть дуже старі версії програми з невеликими виправленнями. АВТОМАТИЗАЦІЯ ЗБІРКИ Для безперервної інтеграції потрібна автоматизація збірки, то є можливість автоматично компілювати програмне забезпечення і з'єднувати його в виконуваний файл. Це потрібно робити швидко, тому що на великі складання може піти багато часу. Без швидкого і надійного процесу складання не буде огляду, необхідного для вирішення виникаючих проблем інтеграції. Коли виконувана інтеграція збірки, вирішуються конфлікти між змінами, внесеними різними розробниками. Коли виявлена проблема, програміст, що працював над вирішенням конфлікту попередньої збірки, може перевірити код за допомогою апаратного моделювання, не затримуючи інших розробників. Однак для досягнення такої ефективності процес інтеграції збірок повинен йти безперервно, так що як тільки закінчується робота над попередньою збіркою, з'являється нова. Це значно відрізняється від щоденного або щотижневого випуску збірок, що практикується іншими процесами. Звичайно, для цього потрібна автоматизація процесу складання, тому що непрактично доручати людині задачу багаторазового створення збірок - знову і знову протягом усього робочого дня. Більше того, процес складання повинен виконуватися швидко, для чого часто потрібно багатопоточне складання. При багатопотоковій збірці збірка різних компонентів програмного забезпечення виконується паралельно, що прискорює весь процес. Для цього потрібно більше обладнання і складніший сценарій. А чим складніше сценарій, тим корисніше стають інструменти управління складанням. УПРАВЛІННЯ РОБОТОЮ Основна ідея гнучкої розробки полягає в тому, що робота розбивається на невеликі, керовані фрагменти. Це ж основна передумова CI: виправляти помилки рано і часто. Це запобігає їх переростанню в більші проблеми, які важче вирішити. Одна з переваг цього методу - можливість випускати діючі версії меншого розміру, зібрані і протестовані багато разів по ходу проекту. Кожен випуск зменшує ризик для проекту, так як група перевіряє архітектуру, вимоги і оцінює терміни випуску. У гнучких методах ще не завершена робота називається чергою завдань ( backlog ). Коли починають розподіляти роботу малими кроками, так званими спринті, робота, відведена спринту, називається чергою завдань спринту ( sprint backlog ). Робота, що залишилася для майбутніх спринтів, називається чергою завдань проекту. У спринт має включатися стільки роботи, щоб її можна було виконати в терміни, відведені для спринту. Цей процес сильно залежить від ряду параметрів, так що група може точно передбачити кількість часу, який знадобиться для вирішення завдання, і, отже, кількість завдань, які можна відвести для одного спринту. Однак збір даних для оцінки цих показників - дуже трудомісткий процес, навіть для невеликої групи. Коли такі невеликі групи об'єднуються, щоб справити більш складний продукт, завдання стає занадто грандіозної, щоб її можна було вирішити вручну. На ринку багато інструментів, що допомагають організувати роботу, відслідковувати її завершення і визначити показники, пов'язані з тим, в якому обсязі, як швидко, як добре і т.д. виконана робота. Якщо слідувати методам CI, то до цієї незавершеної роботі потрібно також швидко додавати виявлені помилки інтеграції та переносити її в початок списку високопріоритетних робіт. Кращі продукти цього призначення на ринку забезпечують деякий рівень інтеграції між новими елементами роботи і системою управління збірками, так що помилки, виявлені в кожній збірці, можна швидко виправити і інтегрувати результат з готовими елементами роботи, підвищити його пріоритет і направити потрібної групі. АВТОМАТИЗОВАНЕ ТЕСТУВАННЯ При створенні безлічі збірок група повинна багаторазово тестувати функції, що вже працюють в попередніх збірках. Цей процес повторного тестування, який раніше називали «добротним кодом» (good code), носить ім'я регресійного тестування . Він гарантує, що внесені зміни не призведуть до помилок в раніше протестованому коді. У разі CI в кінці кожної збірки запускаються автоматичні сценарії регресійних тестів. Це дозволяє розробникам негайно отримувати інформацію про помилки, знайдених в новій збірці. Цей крок попереджає розробників, коли знову створений ними код не відповідає вимогам. Без регресійних тестів розробники знають тільки, що складання виконане. Оскільки тести все одно повинні створюватися, то TDD Не додає додаткову роботу. Просто змінюється порядок дій - спочатку створюються тести, а потім код. При традиційній розробці методом «водоспад» проект міг обходитися без всякої автоматизації тестування. Його можна було описувати, виконувати і відчувати нескінченно цілою армією людей. Але як тільки починаються регулярні випуски, цей процес стикається з проблемами. Просто неможливо тестувати систему вручну багато разів на день. Генерації звітів Активне оповіщення: · Mail; · SMS; · Миттєві повідомлення. Пасивне оповіщення: · Web публікація; · Файловий сервер. ПЕРЕВАГИ · Скорочення ручних операцій - етапи створення, збірки і тестування програмного забезпечення проводяться в автоматичному режимі. · Наявність робочої ІТ-системи на всьому протязі процесу розробки - у проектної команди завжди є свіжа версія рішення для демонстрації замовнику, отримання зворотного зв'язку і швидкого доопрацювання. · Якість програмного забезпечення - в рамках Continuous Integration використовуються різні програмні засоби для контролю якості коду, що дозволяє скоротити кількість помилок. · Мінімізація ризиків - дефекти виявляються на ранніх стадіях розробки інформаційної системи, що допомагає уникнути збільшення термінів і вартості проекту. · Окупність інвестицій в ІТ - автоматизація процесу розробки забезпечують високу ефективність і надійність інформаційної системи. 1.4 НЕДОЛІКИ · витрати на підтримку роботи безперервної інтеграції; · потенційна необхідність у виділеному сервері під потреби безперервної інтеграції; · негайний ефект від неповного або непрацюючого коду відучує розробників від виконання періодичних резервних включень коду в репозиторій. · у разі використання системи управління версіями вихідного коду з підтримкою розгалуження, ця проблема може вирішуватися створенням окремої «гілки» (англ. branch) проекту для внесення великих змін (код, розробка якого до працездатного варіанти займе декілька днів, але бажано більш часте резервне копіювання в репозиторій). Після закінчення розробки і індивідуального тестування такої гілки, вона може бути об'єднана (англ. Merge) з основним кодом або «стволом» (англ. Trunk) проекту. ІНСТРУМЕНТИ · Розгортання і підготовка до роботи: VMWare, Microsoft Hyper-V, Citrix Xen, Parallels. · Засоби розробки: Eclipse, MS Visual Studio, Borland Delphi і т. д. · Системи контролю версій: StarTeam, Perforce, CVS, PVCS, VSS, Synergy, Subversion, GIT і т. д. · Компілятори і засоби збирання: Compilers, Linkers, Ant, Make, Nant MSBuild, Maven. · Контроль якості: Mercury Quality Center, LoadRunner, TestDirector, WinRunner, Xunit, Clover, IBM Functional, Performance & Manual Tester · Сервера інтеграції 1. CruiseControl - сервер інтеграції для Java (див. так само CruiseControl ). 2. ThoughtWorks Cruise - комерційний сервер інтеграції від компанії ThoughtWorks (є безкоштовна версія). 3. CruiseControl.NET - сервер інтеграції для.NET (див. так само CruiseControl.NET ) 4. CruiseControl.rb - сервер інтеграції для Ruby. 5. Hudson - open-source сервер інтеграції, створений як альтернатива CruiseControl. Функціональність розширюється плагінами. 6. Bitten - open-source сервер інтеграції написаний на Python, інтегрується з Trac. CruiseControl.NET
Введення Почати опис можливостей продукту Rational Purify хочеться перефразуванням одного дуже відомого вислову: «з точністю до мілліБАЙТА ». Дане порівняння не випадково, адже саме цей продукт спрямований на вирішення всіх проблем, пов'язаних з витоками пам'яті. Ні для кого не секрет, що багато програмних продуктів поводять себе «Не надто скромно », замикаючи на себе під час роботи всі системні ресурси без великої на то необхідності. Подібна ситуація може виникнути внаслідок небажання програмістів доводити створений код «до розуму », але частіше подібне відбувається не з-за ліні, а через неуважність. Це зрозуміло - сучасні темпи розробки ПЗ в умовах найжорстокішого пресингу з боку конкурентів не дозволяють приділяти занадто багато часу оптимізації коду, адже для цього необхідні і висока кваліфікація, і наявність достатньої кількості ресурсів проектного часу. Як мені бачиться, маючи в своєму розпорядженні надійний інструмент, який би сам в процесі роботи над проектом вказував на всі чорні діри в використанні пам'яті, розробники почали б його повсюдне впровадження, підвищивши надійність створюваного ПЗ. Адже і тут ні для кого не секрет, що в більшості складних проектів першочергове завдання, що стоїть перед розробниками полягає в заміщенні стандартного оператора «new» в С ++, так як він НЕ зовсім адекватно себе поводить при розподілі пам'яті.
Загальні можливості по управлінню Purify схожі з Quantify, за винятком специфіки самого продукту. Тут також можна тестувати багатопотокові програми, також можна робити «зліпки» пам'яті під час тестування програми. Особливості використання цього додатка стосуються специфікою відловлюючих помилок і способом видачі інформації. Основні параметри виведення · Address. IP адреса модуля, в якому виявлено помилку або попередження; · Error Location. Опис модуля з помилкою. В випадку тестування модуля з вихідними текстами, то в даному полі можна переглянути фрагмент коду, який викликав появу помилки; · Allocate Location. Різновид «Error Location », показує фрагмент коду, в якому був розподілений блок пам'яті, робота з яким, призвела до помилки Робота з Purify можлива як при наявності вихідних текстів і налагоджувальної інформації, так і без неї. В разі відсутності debug-інформації аналіз помилок ведеться тільки по ip-адресах. Так само як і в випадку з Quantify, можливий детальний перегляд функцій з dll-бібліотек. В цьому випадку наявність налагоджувальної інформації не є необхідністю. Повідомлення про помилки та попередження Для того, щоб мати уявлення про можливості продукту, опишемо те, які помилки і потенційні помилки можуть бути присутніми в тестованому додатку. Відзначимо різницю між помилкою і потенційної помилкою і опишемо: · Помилка - Доконаний факт нестабільної або некоректної роботи програми, призводить до неадекватних дій додатка або системи. Прикладом подібної помилки можна вважати вихід за межі масиву або спроба запису даних за 0 адресою; · Потенційна помилка - в додатку є фрагмент коду, який при нормальному виконанні не призводить до помилок. Помилка виникає тільки в разі збігу обставин, або не проявляє себе ніколи. До даної категорії можна віднести такі особливості, як ініціалізація масиву з ненульової адреси, скажімо, є масив на 100 байт, але кожен раз звернення до нього виробляється з 10 елемента. В цьому випадку Purify вважає, що є потенційний витік пам'яті розміром в 10 байт. Природно, що подібна поведінка може бути викликана специфікою додатка, наприклад, так поводитися може текстовий редактор. Тому в Purify застосується поділ інформації на помилки і потенційні помилки (які можна сприймати як специфіку). Список помилок і потенційних помилок досить об'ємний і постійно поповнюється. Коротко опишемо основні повідомлення, що виводяться після тестування: · Array Bounds Read Вихід за межі масиву при читанні; · Array Bounds Write Вихід за межі масиву при записі; · Late Detect Array Bounds Write Повідомлення вказує, що програма записала значення перед початком або після кінця розподіленого блоку пам'яті; · Beyond Stack Read Повідомлення вказує, що функція в програмі збирається читати поза поточного покажчика вершини стека; · Freeing Freed Memory Спроба звільнення вільного блоку пам'яті; · Freeing Invalid Memory Спроба звільнення некоректного блоку пам'яті; · Freeing Mismatched Memory Повідомлення вказує, що програма пробує; · Free Memory Read Спроба читання вже звільненого блоку пам'яті; · Free Memory Write Спроба запису вже звільненого блоку пам'яті; · Invalid Handle Операції над неправильним дескриптором; · Invalid Pointer Read \ Write Помилка при читанні \ записі з недоступного блоку пам'яті; · Memory Allocation Failure Помилка в запиті на розподіл пам'яті; · Memory Leak Витік пам'яті; · Potential Memory Leak Потенційний витік пам'яті; · Null Pointer Read Спроба читання з нульової адреси; · Null Pointer Write Спроба запису в нульовий адрес; · Uninitialized Memory Copy Спроба копіювання непроініціалізірованного блоку; · UMR: Uninitialized Memory Read Спроба читання непроініціалізірованного блоку. Попередження і помилки зручно групувати за певними ознаками, щоб легше можна було відшукати потрібне попередження і відкинути непотрібні. Відзначимо категорії і приналежність до них різних повідомлень: · Allocation And deallocation. Робота з пам'яттю; · DLL messages. Інформаційні повідомлення по зовнішнім бібліотекам; · Invalid handles. Неправильний дескриптор; · Invalid pointers. Неправильний покажчик; · Memory leaks. Витік пам'яті; · Parameter errors. Помилка параметра; · Stack errors. Помилка при роботі зі стеком; · Unhandled exception. Виняток; · Uninitialized memory. Використання непроініціалізірованного блоку пам'яті. Багато статичних помилок можуть виловлювати компілятори на етапі розробки програмного модуля або програми. На цьому етапі переваги Purify НЕ дуже видно. Всі механізми аналізу помилок відкриваються при виконанні додатка, при динамічно мінливих умовах. Розглянемо більш докладно список відловлювальних помилок, визначивши їх приналежність до категорій з прикладами на C ++ / C: ABR: Array Bounds Read. Вихід за межі масиву при читанні. #include < iostream.h> ptr [0] = 'e'; ABW: Array Bounds Write. Вихід за межі масиву при записі. Відзначимо, що пам'ять можна визначити статично, масовому, як показано в прикладі. А можна динамічно (наприклад, виділивши блок пам'яті по ходу виконання додатка). За замовчуванням, Purify успішно справляється тільки з динамічним розподілом, чітко виводячи повідомлення про помилку. В випадку статичного розподілу, все залежить від розмірів «Купи» і налаштувань компілятора. #include < iostream.h> BSR: Beyond Stack Read. Повідомлення вказує, що функція в програмі збирається читати поза поточного покажчика вершини стека Категорія: Stack Error #include < windows.h> int main (int, char **) cerr < < «element # " < < i < < «Is " < < block [i] < < '\ n'; FFM: Freeing Freed Memory. Спроба звільнення вільного блоку пам'яті. В великому додатку важко відстежити момент розподілення блоку і момент звільнення. Дуже часто методи реалізуються різними розробниками, і, відповідно, можлива ситуація, коли розподілений блок пам'яті звільнюєтьсядвічі на різних ділянках програми. Категорія: Allocations And deallocations #include < iostream.h> FIM: Freeing Invalid Memory. Спроба звільнення некоректного блоку пам'яті. Розробники часто плутають прості статичні значення і покажчики, намагаючись звільнити те, що НЕ звільняється. Компілятор завжди здатний проаналізувати і нейтралізувати даний вид помилки. Категорія: Allocations And deallocations #include < iostream.h> int main (int, char **) FMM: Freeing Mismatched Memory. Повідомлення вказує, що програма пробує звільняти пам'ять з неправильним ВИКЛИКОМ API для того типу пам'яті. Категорія: Allocations And deallocations #include < windows.h> int main (int, char **) HeapDestroy (heap_first); FMR: Free Memory Read. Спроба читання вже звільненого блоку пам'яті Все та ж проблема з покажчиком. Блок розподілений, звільнений, а потім, в відповідь на подію, по покажчику починають записуватися (Або читатися) дані. Категорія: Invalid pointers #include < iostream.h> FMW: Free Memory Write. Спроба запису вже звільненого блоку пам'яті Категорія: Invalid pointers #include < iostream.h> HAN: Invalid Handle. Операції над неправильним дескриптором Категорія: Invalid handles #include < iostream.h> HIU: Handle In Use. Індикація витоку ресурсів. Неправильна індикація дескриптора. #include < iostream.h> cerr < < «Помилка відкриття, створення файлу \ n "; if (ptr == NULL) { IPR: Invalid Pointer Read. Помилка звернення до пам'яті, коли програма намагається зробити читання з недоступної області. Категорія: Invalid pointers #include < iostream.h> #include < windows.h> for (Int I = 0; i < 2; i ++) { IPW: Invalid Pointer Write. Помилка звернення до пам'яті, коли програма намагається зробити запис з недоступної області Категорія: Invalid pointers #include < iostream.h> for (Int I = 0; i < 2; i ++) { MAF: Memory Allocation Failure. Помилка в запиті на розподіл пам'яті. Виникає в випадках, коли проводиться спроба розподілити занадто великий блок пам'яті, наприклад, коли вичерпано файл підкачки. Категорія: Allocations And deallocations #include < iostream.h> MLK: Memory Leak. Витік пам'яті Поширений варіант помилки. Багато сучасних програм грішать тим, що НЕ віддають системі розподілені ресурси по закінченні своєї роботи. Категорія: Memory leaks #include < windows.h> MPK: Potential Memory Leak. Потенційний витік пам'яті Категорія: Memory leaks #include < iostream.h> NPR: Null Pointer Read. Спроба читання з нульової адреси Категорія: Invalid pointers #include < iostream.h> NPW: Null Pointer Write. Спроба запису в нульовий адрес Категорія: Invalid pointers #include < iostream.h> UMC: Uninitialized Memory Copy. Спроба копіювання непроініціалізірованного блоку пам'яті Категорія: Unitialized memory #include < iostream.h> int main (int, char **) } delete [] pointer; UMR: Uninitialized Memory Read. Спроба читання непроініціалізірованного блоку пам'яті Категорія: Unitialized memory #include < iostream.h> Робота з фільтром Щоб не захаращувати користувальницький інтерфейс зайвими даними, в Purify передбачена система гнучких фільтрів. Фільтри створюються і призначаються і модифікуються через верхнє меню (View → CreateFilter і View → FilterManager). За замовчуванням Purify виводить всі повідомлення і попередження.
Малюнок показує зовнішній вигляд вікна створення фільтра (View → CreateFilter). Тут ми маємо можливість по вибору повідомлень, які потрібно фільтрувати. Пункт General - управляє ім'ям фільтру і коментарем, його супроводжуючим, Source - визначає місце розташування вихідних файлів, для яких необхідно вивести повідомлення. Підхід використовується в тому випадку, коли відбувається виклик одного модуля з іншого, щоб обмежити кількість інформації в звіті.
Вище згадувалося, що Purify НЕ обмежує число фільтрів. Слід розуміти, що НЕ обмежується НЕ тільки загальне число фільтрів, але і їх кількість на один протестований додаток. Обмеження по модулям, яке також можна виставити в даному діалозі, визначає число зовнішніх модулів, попередження від яких з'являються в звіті. API Rational Purify також має ряд функцій інтерфейсу, впливаючи на які, розробник на етапі створення програми може користуватися всіма благами, що надаються даним додатком. Функції установки статусу розподілених блоків: · PurifyMarkAsInitialized. Встановлює позначку на вказаний блок, роблячи його поміченим, як проініціалізований; · PurifyMarkAsUninitialized. Ставить прапор ініціалізації; Функції тестування станів розподілених блоків · PurifyAssertIsReadable. Перевіряє, чи доступний блок пам'яті для читання; · PurifyAssertIsWritable. Перевіряє, чи доступний блок пам'яті для запису; · PurifyIsInitialized. Перевіряє, проініціалізований блок пам'яті чи ні; · PurifyIsReadable. Перевіряє блок пам'яті на можливість читання; · PurifyIsWritable. Перевіряє блок пам'яті на можливість запису; Функції, що визначають руйнування · PurifySetLateDetectScanCounter. Визначає лічильник сканування купи. Підраховує кількість операцій. За замовчуванням, Purify сканує пам'ять через кожні 200 операцій з пам'яттю, або кожні 10 секунд; · PurifySetLateDetectScanInterval. Визначає інтервал пошуку купи. За замовчуванням - 10 секунд; · PurifyHeapValidate. Примусово перевіряє пам'ять на наявність помилок; Функції, що визначають витоку пам'яті · PurifyAllInuse. Повертає значення, що визначає кількість використаної пам'яті; · PurifyClearInuse. Повертає значення, яке показує кількість пам'яті, розподіленої після останнього дзвінка PurifyClearInuse або PurifyNewInuse; · PurifyAllLeaks. Повертає число знайдених витоків у пам'яті. Знаходить як прямі витоки пам'яті, так і непрямі; · PurifyClearLeaks. Визначає число звільнених блоків пам'яті за час останнього звернення до PurifyClearLeaks або PurifyAllLeaks; · PurifyNewLeaks. Визначає число нових витоків пам'яті за час останнього звернення до PurifyNewLeaks або PurifyClearLeaks. Збереження даних і експорт Purify дозволяє зберігати результати тестування (file → save copy as) в чотирьох різних уявленнях, що дозволяють найбільш ефективним чином отримати інформацію про хід тестування. Розглянемо варіанти збереження: · Purify Error unfiltered. Зберігає дані про тестуванні в вигляді «Як є »без фільтрів; · Purify error filtered. Зберігає дані про тестування з застосованими фільтрами; · Text expended. Зберігає дані в текстовому вигляді про тестування в розширеному поданні (з виведенням знайдених помилок, з коротким описом); · Text view. Зберігається тільки згадка про знайдені помилки, без додаткового опису. При встановленому MS Outlook, можливо відправлення звіту поштою через пункт file → send з верхнього меню Purify. Параметри тестування Перед виконанням тестованої програми, можливо, задати додаткові налаштування, які зможуть налаштувати Purify на ефективне тестування. Запуск програми проводиться точно також як і в випадку з Quantify (по F5 або file → Run). Параметри налаштування знаходяться пункті Settings, вікна, що з'явилося. Перша сторінка діалогу представлена на малюнку
Відзначимо основні особливості, які якісно можуть позначитися на результуючому звіті: · Report AT Exit. Дана група дозволяє отримувати більш детальну інформацію про всіх покажчиках і блоках пам'яті, що не приводили до помилок пам'яті. За замовчуванням, Purify виводить звіти тільки по тим блокам, які були розподілені, але НЕ були звільнені. В більшості випадків такий підхід виправданий, так як зазвичай розробника цікавлять саме помилки. Інші пункти активізують по мірі необхідності, коли потрібно мати загальне уявлення про використання пам'яті тестованим додатком; · Error Suppretion. Група визначає ступенем детальності виведеної інформації. · Call Stack Length. Визначає глибину стека; · Red Zone Length. Управляє числом байтів, яке вбудовується в код тестованої програми при операціях пов'язаних з розподілом пам'яті. Збільшення числа сприяє кращому збору інформації, але істотно гальмує виконання додатка; Закладка PowerCheck дозволить налаштувати рівень аналізу кожного окремо взятого модуля. Існує два способи інструментації тестованої програми: Precise і Minimal. В першому випадку проводиться детальне інструментування коду, але при цьому модуль працює відносно повільно. Під другому випадку, проводиться коротке інструментування, при якому Purify вносить в модуль менше налагоджувальної інформації, і, як наслідок, здатна відловити менше число помилок. Останній підхід виправданий, коли додаток викликає масу зовнішніх бібліотек від третіх фірм, котрі не будуть піддаватися правці. |
Последнее изменение этой страницы: 2019-04-09; Просмотров: 75; Нарушение авторского права страницы