|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Браузери для навантажувального тестування
З desktop браузерів протестовані були FF і Chrome. З Chrome ситуація була аналогічна, плюс він для своєї роботи вимагав запуску в окремому процесі WebDriver'а на кожен екземпляр Chrome. Що підвищувало вимоги до ресурсів. З FF ситуація була трохи краще - нормально працювало 5 браузерів без додаткового запуску WebDriver'ов. Але ситуацію це не сильно поліпшило. Тоді довелося тестувати headless браузери - браузери, які повністю працюють з сайтом (будують DOM виконують JS), але не відображають його. По ідеї вони повинні працювати швидше. З усіх headless браузерів зупинився на 2 - PhantomJS і HttpUnit. Перспективно виглядав PhantomJS, заснований на Webkit. Але по факту він ні чим не відрізнявся від FF по споживанню ресурсів, але мав наступні мінуси - іноді не знаходив елементи на сторінці і не коректно відображав сайт на скріншотах. Так що не вдавалося зрозуміти, чому сталася помилка. З HtmlUnit все набагато простіше - його webdriver не підтримував alert, а це для нашого web додатка було критично. У підсумку повернулися до використання FF в нагрузочному тестуванні. Хоча в ньому теж виникли проблеми з alert'амі - іноді виникали помилки java.lang.Boolean can not be cast to java.lang.String (java.lang.ClassCastException) (ось посилання на помилку в Google Code code.google.com/p / selenium / issues / detail? id = 3565 ). Виправити цю помилку не вийшло, але зате вийшло відмовитися зовсім від alert'ов. Так що надалі можна спробувати знову використовувати HtmlUnit. Хоча у всіх headless браузерів є одна спільна незручність, пов'язана з їх специфікою, - вони не відображають сторінки і так просто не можна зрозуміти, через що сталася помилка. Можливість зняття скріншота не сильно допомагає - іноді він не інформативний.
Конфігурація Selenium'а
У підсумку прийшли до наступної конфігурації: На одному комп'ютері запускався Selenium в режимі hub з додатковим параметром -timeout 0. Це потрібно було тому, що іноді сесії закривалися по timeout із-за тривалої бездіяльності тестів. На інших комп'ютерах запускався Selenium в режимі node. Для потужних комп'ютерів, здатних забезпечити роботу 15 браузерів, node Selenium'а запускався з додатковим налаштуванням, що дозволяє запускати 15 копій FF і вказує, що одночасно можна працювати з 15 сесіями.
Проведення тестів
Пару слів потрібно сказати про тестові сценарії і підрахунок часу їх виконання. Кожен сценарій включав в себе відкриття документів кожного типу. Тобто спочатку відкривався вхідний документ, потім вихідний документ і т.д. Ось тут потрібно врахувати наступну ситуацію - якщо потрібно зняти час відкриття тільки вхідного документа, і при цьому запустити на всіх машинах виконання тільки по сценарію, то час буде істотно менший (на 50%) ніж, якби знімати час при одночасному виконанні всіх сценаріїв. У моєму випадку, швидше за все це було пов'язано з кешуванням на рівнях web програми та СУБД. І тим, що відкривалося мало унікальних документів. Можливо, при великій кількості різних документів відмінності будуть не настільки істотні. В ідеалі хотілося б отримати розподіл користувачів і документів таким, яким воно буде в реально діючій системі. Тобто, наприклад, в реальній системі буде 10 чоловік працювати з вхідними та 30 з вихідними. І в навантажувальні тести так само відобразити це співвідношення - кількість тестів за вихідними в три рази більше ніж з вхідними документами. Але так як ще тестована система поки не ввійшла в експлуатацію та цих даних поки немає, то тестування відбувалося без їх обліку.
Підведення підсумків
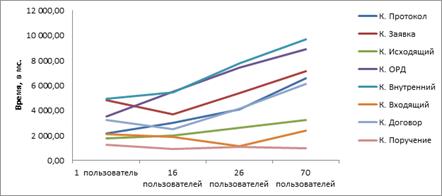
Залежність часу списку документів від кількості працюючих користувачів:
Далі тести будуть продовжуватися, щоб побудувати графік для 200 користувачів. В результаті повинен вийти графік, схожий на цей (узятий з msdn.microsoft.com/en-us/library/bb924375.aspx ):
По ньому вже можна буде точно визначити можливості системи і знайти її вузькі місця. |
Последнее изменение этой страницы: 2019-04-09; Просмотров: 43; Нарушение авторского права страницы