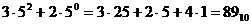|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Розвиток мов системного програмування
Мова Асемблера – це символічне представлення машинної мови. Він полегшує процес програмування в порівнянні з програмуванням в машинних кодах. Програмісту не обов'язково вживати справжні адреси елементів пам'яті з розміщеними в них даними, що беруть участь в операції, а також адреси тих команд, до яких програма не звертається. Замість них вказується їх символьне позначення (MOV ax, bx). Деякі завдання, наприклад, обмін з нестандартними пристроями обробки даних складних структур неможливо вирішити за допомогою мов програмування високого рівня. Це під силу асемблеру. У принципі, мова Асемблер є машинною мовою. І програміст що реалізовує яке-небудь завдання на мовах високого рівня, за допомогою Асемблера може визначити чи осмислено рішення даної задачі, з погляду використання ЕОМ. Але на Асемблері програмувати складно, тому у більшості випадків інтерфейс програми складається на мовах високого рівня, а команди обміну даними із пристроями вводу/виводу складаються на Асемблері. Тому практично всі компілятори мов програмування високого рівня дозволяють розміщувати асемблерні вставки у програмах користувача. Сі – це мова програмування загального призначення, добре відома своєю ефективністю, економічністю, і переносимістю. Вказані переваги Сі забезпечують хорошу якість розробки майже будь-якого виду програмного продукту. Використання Сі як інструментальна мова дозволяє одержувати швидкі і компактні програми. У багатьох випадках програми, написані на Сі, порівнянні за швидкістю з програмами, написаними на мові асемблера. При цьому вони мають кращу наочність і їх простіше супроводжувати. Сі поєднує ефективність і потужність у відносно малій за розміром мові. Сі – це чудова мова, і хоча деяким він не подобається, але все таки більшість програмістів його люблять. На Сі ви можете створювати програми, які роблять все, що ви побажаєте. Немає іншої такої мови, яка б так само стимулювала до програмування. Створюється враження, що решта мов програмування споруджує штучні перешкоди для творчості, а Сі – ні. Використання цієї мови дозволяє скоротити витрати часу на створення працюючих програм. Сі дозволяє програмувати швидко, ефективно і передбачено. Ще одна перевага Сі полягає в тому, що він дозволяє використовувати всі можливості вашої ЕОМ. Ця мова створена програмістом для використання іншими програмістами, чого про інші мови програмування сказати не можна. Мова Сі має свої істотні особливості, давайте перерахуємо деякі з них: Сі забезпечує повний набір операторів структурного програмування. Сі пропонує незвично великий набір операцій. Багато операцій Сі відповідають машинним командам, і тому допускають пряму трансляцію в машинний код. Різноманітність операцій дозволяє вибирати їх різні набори для мінімізації результуючого коду. Тобто один і той самий алгоритм можна описати з використанням різних операторів. Сі підтримує покажчики (вказівники) на змінні і функції, тобто дозволяє працювати з динамічною пам’яттю. Покажчик на об'єкт програми відповідає машинній адресі цього об'єкта. За допомогою розумного використання покажчиків можна створювати ефективно-виконувані програми, оскільки покажчики дозволяють посилатися на об'єкти тим же самим шляхом, як це робить машина. Сі підтримує арифметику покажчиків, і тим самим дозволяє здійснювати безпосередній доступ і маніпуляції з оперативною пам'ятю не гірше ніж мова Асемблера. Очевидно, що мова Сі також має ряд недоліків. Зокрема вона пред'являє достатньо високі вимоги до кваліфікації програміста. При вивченні Сі бажано мати уявлення про структуру і роботу комп'ютера. Велику допомогу і глибше розуміння ідей Сі, як мови системного програмування, забезпечать хоч би мінімальне знання мови асемблер. Рівень старшинства деяких операторів не є загальноприйнятим, деякі синтаксичні конструкції могли б бути краще, оскільки завдяки їх простоті вони часто втрачають зрозумілість. Проте, як виявилося Сі – надзвичайно ефективна і виразна мова, придатна для широкого класу завдань. Назва Сі++ - винахід літа 1983-його. Раніші версії мови використовувалися починаючи з 1980-го і були відомі як "Cі з Класами". Спочатку мова була придумана тому, що автор хотів написати покроково керовані моделі для чого був би ідеальний Simula67, якщо не брати до уваги ефективність. "Cі з Класами" використовувався для крупних проектів моделювання, в яких строго тестувалися можливості написання програм, що вимагають (тільки) мінімального простору пам'яті і часу на виконання. У "Cі з Класами" не вистачало перевантаження операцій, посилань, віртуальних функцій і багатьох деталей. Сі++ був вперше введений за межами дослідницької групи автора в липні 1983-го. Проте тоді багато особливостей Сі++ були ще не придумані. Назву Сі++ вигадав Рік Масситті. Назва указує на еволюційну природу переходу до нього від Cи. "++" - це операція інкременту в Cи. Трохи коротше ім'я Cі+ є синтаксичною помилкою, крім того, його вже було використано як ім'я зовсім іншої мови. Назви D мова не одержала, оскільки вона є розширенням Cі і в ній не робиться спроб зцілитися від проблем шляхом викидання різних особливостей. Сі++ - це універсальна мова програмування, задумана так, щоб зробити програмування приємнішим для серйозного програміста. За винятком другорядних деталей Сі++ є надбудовою мови програмування Cи. Крім можливостей, які дає Cи, Сі++ надає гнучкі і ефективні засоби визначення нових типів. Використовуючи визначення нових типів, що точно відповідають концепціям застосування, програміст може розділяти програму, що розробляється, на частини, що легко піддаються контролю. Такий метод побудови програм часто називають абстракцією даних. Програмування із застосуванням таких об'єктів часто називають об'єктно-орієнтованим. При правильному використанні цей метод дає коротші програми, що простіше розуміються і легше контрольовані. Спочатку Сі++ був розроблений, щоб автору і його друзям не доводилося програмувати на асемблері, Cі або інших сучасних мовах високого рівня. Основним його призначенням було зробити написання хороших програм простішим і приємнішим для окремого програміста. Плану розробки Сі++ на папері ніколи не було. Проект, документація і реалізація рухалися одночасно. Зрозуміло, зовнішній інтерфейс Сі++ був написаний на Сі++. Ніколи не існувало "Проекту Сі++" і "Комітету з розробки Сі++". Тому Сі++ розвивався і продовжує розвиватися на всіх напрямках, щоб справлятися з складнощами, з якими стикаються користувачі, а також в процесі дискусій автора з його друзями і колегами. Як базова мова для Сі++ був вибраний Cі, тому що він: · багатоцільовий, лаконічний і щодо низького рівня: · відповідає більшості завдань системного програмування: · придатний для роботи на різних типах ЕОМ і під керуванням різних операційних систем; Сі++ був розвинений з мови програмування Cі і за дуже небагатьма виключеннями зберігає Cі як підмножину. Базова мова, Cі підмножина Сі++, спроектована так, що є дуже близька відповідність між його типами, операціями і операторами і комп'ютерними об'єктами, з якими безпосередньо доводиться мати справу: числами, символами і адресами. Одним з первинних призначень C було застосування його замість програмування на асемблері в найнасущніших завданнях системного програмування. Коли проектувався Сі++, були вжиті заходи, щоб не ставити під загрозу успіхи в цій області. Відмінність між Cі і Сі++ полягає в першу чергу в ступені уваги, що приділяється типам і структурам. Особлива увага, приділена при розробці Сі++ структурі, відобразилася на зростанні масштабу програм, написаних з часу розробки Cі. Маленьку програму (менше 1000 рядків) ви можете примусити працювати за допомогою грубої сили, навіть порушуючи всі правила хорошого стилю. Для програм великих розмірів це не зовсім так. Якщо програма в 10000 рядків має погану структуру, то ви виявите, що нові помилки з'являються так само швидко, як віддаляються старі. Сі++ був розроблений так, щоб дати можливість розумним чином структурувати великі програми так, щоб для однієї людини не було непомірним справлятися з програмами в 25 000 рядків. Існують програми набагато більших розмірів, проте ті, які працюють, в цілому, як виявляється, складаються з великого числа майже незалежних частин, розмір кожної з яких набагато нижче вказаних меж. Природно, складність написання і підтримки програми залежить від складності розробки, а не просто від числа рядків тексту програми, так що точні цифри, за допомогою яких були виражені попередні міркування, не слід сприймати дуже серйозно. Винахід мови програмування вищого рівня дозволив нам спілкуватися з машиною, розуміти її (якщо звичайно Вам знайома використовувана мова), як розуміє американець небагато знайомий з російською мовою стародавню азбуку Кирилиці. Простіше кажучи, ми в нашому розвитку науки програмування поки що з ЕОМ на ВИ. Повірте – це не сарказм ви тільки подивитеся як розвинулася наука програмування з того часу, як з'явилися мови програмування, адже мова програмування вищого рівня, судячи з усього ще немовля. Але якщо ми звернемо увагу на темпи зростання і розвитку новітніх технологій у області програмування, то можна припустити, що в найближчому майбутньому, людські пізнання в цій сфері, допоможуть породити мови, що уміють приймати, обробляти і передавати інформації у вигляді думки, слова, звуку або жесту. Так і хочеться назвати це дітище комп'ютеризованого майбутнього: (мови програмування "високого" рівня). Можливо, концепція рішення цього питання проста, а найближче майбутнє цього проекту вже не за горами, і у цей момент, де нібудь в Запоріжжі, Амстердамі, Токіо або Єрусалимі, перед стареньким Pentium3 горбить молодою, ніким не визнаний фахівець і розробляє новітню систему штучного інтелекту, яка нарешті дозволить людині, за допомогою своїх машинних мов, вести діалог з машиною на ТИ. Роздумуючи над цим, хочеться вірити в прогрес науки і техніки, у високо - комп'ютеризоване майбутнє людства, як єдиної істоти на планеті, хай і що не використовує один, певна розмовна мова, але здатного так швидко прогресувати і розвивати свій інтелект, що і переходу від багатомовної системи до загального розуміння довго чекати не доведеться. Завершити свою працю добре б на такій оптимістичній ноті, але ні, наприкінці хочеться процитувати людину, фрагменти роботи якого, у вигляді інформації про мову Сі, вам вже попадалися на сторінках цього тексту: Єдиний спосіб вивчати нову мову програмування – писати на ній програми. Б ’ єрн Страуструп знати : v Означення мови програмування. v Класифікацію мов програмування. v Означення мови високого рівня програмування та її основні види. v Означення мови низького рівня програмування та її основні види. v Поняття машинно-орієнтованих мов програмування. v Поняття машинно-незалежних мов програмування. v Поняття проблемно-орієнтованих мов програмування. v Поняття універмальних мов програмування. v Розвиток системного програмування. вміти : v Дати порівняльну характеристику мов програмування. v Описувати розвиток системного програмування. 1. Сформулюйте означення мови програмування. 2. Назвіть основні види мов програмування. 3. Сформулюйте означення мови високого рівня програмування. 4. Сформулюйте означення мови низького рівня програмування. 5. Сформулюйте означення машинно-орієнтованої мови програмування. 6. Сформулюйте означення машинно-незалежної мови програмування. 7. Сформулюйте означення проблемно-орієнтованої мови програмування. 8. Назвіть прорблемно-орієнтовані мови програмування. 9. Сформулюйте означення універсальної мови програмування. 10. Сформулюйте означення діалогової мови програмування. 11. Назвіть основні етапи розвитку системного програмування. 1.http://uk.wikipedia.org/wiki/%D0%9C%D0%BE%D0%B2%D0%B0_%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D1%83%D0%B2%D0%B0%D0%BD%D0%BD%D1%8F –Мова програмування та її види 2. http://melkon.com.ua/ua/novosti-i-statii/article-hpc-software-trends.html- Розвиток мов системного програмування. 1.2. Історія створення та різновиди стандартів мови програмування Сі Питання для опрацювання 1. Історія виникнення мови програмування С. 2. Сфери застосування мови програмування С. 3. Основні відмінності мови С++ від мови С. Під час вивчення даної студенти повинні звернути увагу на мов и програмування Сі та С++ як на головн і засоби створення системних програм . 1. Історія виникнення мови програмування С C(англ.C)— універсальна, процедурна,імперативна мова програмування загального призначення, розроблена у 1972 році Денісом Рітчі у Bell Telephone Laboratories з метою написання нею операційної системи UNIX. Хоча С і було розроблено для написання системного програмного забезпечення, наразі вона досить часто використовується для написання прикладного програмного забезпечення. С імовірно, є найпопулярнішою у світі мовою програмування за кількістю вже написаного нею програмного забезпечення, доступного під вільними ліцензіями коду та кількості програмістів, котрі її знають. Версії компіляторів для мови С існують для багатьох операційних систем та апаратних архітектур. C здійснила великий вплив на інші мови програмування, особливо на C++, яка спочатку проектувалася, як розширення для С, а також на Java та C#, які запозичили у С синтаксис. Як і більшість імперативних мов, заснованих на традиції АЛГОЛ, C має можливості для структурного програмування і дозволяє здійснювати рекурсії, у той час, як система статичної типізації даних запобігає виникненню багатьох непередбачуваних операцій. У С увесь виконуваний код міститься у функціях. Параметри функції завжди передаються за значеннями. Передача параметрів за вказівником реалізовується шляхом передачі значення вказівника. Гетерогенні сукупності типів даних (структури) дозволяють пов'язаним типам даних бути об'єднаними і маніпулювати ними, як єдиним цілим. C також має такі специфічні властивості: · змінні можуть бути прихованими у вкладених блоках; · слабка типізація; наприклад, символи можуть використовуватися, як цілі числа; · низькорівневий доступ до оперативної пам'яті шляхом перетворення машинних адрес вказівники; · вказівники на функції і дані підтримують динамічний поліморфізм; · масив індексів як вторинне поняття, визначається у термінах арифметики вказівників; · стандартизований препроцесор C для макроозначення, включення файлу з джерельним кодом, умовної трансляції, і т. д. · комплексна функціональність, як то I/O, маніпуляція рядками, і делегування математичних функцій бібліотекам; · відносно невелика кількість зарезервованих слів (32 у С89, і 37 у C99); · Лексичні структури, які нагадують B більше за ALGOL, наприклад: · { ... } на відміну від ALGOL'івського begin ... end · знак рівності для призначення (копіювання), як це робиться у мові Fortran · два знаки рівності використовуються для перевірки рівності (подібно до .EQ. у Fortran'і або одного знаку рівності уBASIC) · && та || на відміну від ALGOL'івських and та or (цим вона семантично відрізняється від бітових операторів & та |). · велика кількість операторів об'єднання, на кшталт +=, ++, …… Початковий етап розробки Сі відбувся у стінах Bell Labs між 1969 та 1973 роками; Деніс Рітчі стверджує, що найбільш творчим був 1972 рік. Мову було названо «Сі» через те, що багато її можливостей було отримано від раніше створеної мови B. Існує чимало легенд щодо походження мови Сі, і пов'язаної з нею операційної системи UNIX, серед них: · Розробка Сі стала результатом того, що його майбутні автори любили комп'ютерну гру, схожу на популярну гру Asteroids (Астероїди). Вони вже давно грали у неї на головному сервері компанії, який був недостатньо потужним, і повинен був обслуговувати близько ста користувачів. Томпсон і Рітчі вирішилили, що їм не вистачає контролю над космічним кораблем для того, щоб уникати зіткнень з деякими каменями. Тому вони вирішили перенести гру на вільний PDP-7, що стоїть в офісі. Проте цей комп'ютер не мав операційної системи, що змусило їх її написати. Врешті-решт, вони вирішили перенести цюопераційну систему ще й на офісний PDP-11, що було дуже важко, оскільки її код був цілком написаний на асемблері. Було винесено пропозицію використати якусь високорівневу портативну мову, щоб можна було легко переносити ОС з одного комп'ютера на іншій. Мова B, яку вони спершу хотіли використати, виявилася позбавленою функціональності, здатної використовувати нові можливості PDP-11. Тому вони і зупинилися на розробці мови С. · Найперший комп'ютер, для якого була спочатку написана UNIX, призначався для створення системи автоматичного заповнення документів. Перша версія UNIX була написана на асемблері. Пізніше для того, щоб переписати цю операційну систему, була розроблена мова С. До 1974 року мова С стала достатньо функціональною для того, щоб переписати на ній більшу частину ядра UNIX, котре спершу було написане на асемблері PDP-11. Це було перше ядро операційної системи реалізоване не на асемблері. У 1978 році Рітчі та Керніган опублікували першу редакцію книги «Мова програмування Сі». Ця книга, відома серед програмістів як «K&R». Описану у ній версію мови Сі, часто називають «K&R». Друга редакція цієї книги присвячена пізнішому стандартуANSI C, описаному нижче. K&R описує такі особливості мови: · Тип даних struct · Тип даних long int · Тип даних unsigned int · Оператор =- було змінено на -=, щоби позбутися семантичної двозначності створюваної конструкціями, на зразок i=-10, яка могла інтерпретуватися, як i =- 10 або i = -10 K&R часто вважають найголовнішою частиною мови, яку повинен підтримувати компілятор С. Багато років, навіть після виходуANSI C, він вважався мінімальним рівнем, якого слід було дотримуватися програмістам, охочим добитися від своїх програм максимальної портативності, оскільки не всі компілятори тоді підтримували ANSI C, а код на K&R C був сумісним і з ANSI C. У ранніх версіях C, лише функції, що повертають значення з типом відмінним від int повинні були бути оголошеними, якщо вони використовувалися перед визначенням функції; функції без попереднього оголошення повинні повертати лише ціле число. Для прикладу: long int SomeFunction(); int OtherFunction(); int CallingFunction() { long int test1; int test2; test1 = SomeFunction(); if (test1 > 0) test2 = 0; else test2 = OtherFunction(); return test2; }У цьому прикладі, як SomeFunction, так і OtherFunction були оголошені перед своїм використанням. У K&R оголошенням OtherFunction можна було знехтувати. Оскільки декларація функцій у K&R C не включає ніякої інформації про аргументи функції, перевірка типу параметрів не виконується, хоча деякі компілятори видають попереджувальне повідомлення, якщо до локальної функції звертаються із неправильним числом аргументів, або якщо багаторазові виклики до зовнішньої функції використовувають різну кількість аргументів. Наступні декілька років після публікації K&R C, до мови було додано декілька неофіційних можливостей (у той час, як офіційного нового стандарту не було), котрі підтримувалися компіляторами від AT&T та деяких інших постачальників. Серед них: · функції з типом результату void; · функції, що повертають значння типу struct або union (а не вказівник); · присвоєння для типу struct; · визначник const, котрий робив об'єкт доступним лише для читання; · перечислювані типии. Велика кількість доповнень і відсутність стандартної бібліотеки, разом із великою популярністю мови, створили нагальну потребу у стандартизації. Наприкінці 1970-х, мова C випередила BASIC, і стала найпопулярнішою мовою програмування для мікрокомп'ютерів. Протягом1980-х, її прийняли для використання в IBM PC, і її популярність почала зростати досить стрімкими темпами. У той же час, Бьярн Страуструп та інші працівники Bell Labs розпочали роботу над доданням об'єктно-орієнтованих конструкцій до C, що призвело до виникнення C++. У 1983, Американський Національний Інститут Стандартів (ANSI) сформував комітет X3J11 для створення стандартної специфікації для мови C. У 1989, стандарт був ратифікований як ANSI X3.159-1989 «Мова Програмування C». Цю версію часто називають ANSI C, Стандартний C, або С89. У 1990, стандарт (з декількома незначними модифікаціями) ANSI C ратифікувала Міжнародна Організація із Стандартизації (ISO), ISO/IEC 9899:1990. Цю версію іноді називають C90. Тому, терміни «C89» і «C90» по суті, позначають одну мову. ANSI, як і інші інститути із стандартизації, більше самотужки не займається розвитком стандарту мови програмування С. Прийняття стандарту національними інститутами, як правило, відбувається протягом року після публікацію стандарту ANSI. Одна з цілей процесу стандартизації мови С полягала у розробці надмножини над K&R C, яка включала б чимало неофіційних можливостей. Комітети зі стандартизації також додали чимало додаткових функцій, як то прототипи функцій (запозичені в C++), вказівники void, підтримку міжнародних наборів символів та мов і локалей, а також низку розширень для препроцесора. Синтаксис декларації параметрів також було розширено використовуючи запозичення з С++, хоча, інтерфейс K&R також допускається для збереження зворотної сумісності зі старим кодом. C89 наразі підтримується усіма компіляторами С, і більшість існуючого коду написано на базі даного стандарту. Будь яка програма на писана на стандартній С, і без використання апаратно залежних засобів може бути скомпільована і запущена на будь якій операційній системі та апаратній архітектурі без будь яких обмежень ресурсів. Після процесу стандартизації ANSI, специфікація мови C протягом якогось часу залишилася відносно статичною, тоді як C++продовжувала еволюціонувати, у значній мірі завдяки своїм власним зусиллям зі стандартизації. Нормативна Поправка 1, створила новий стандарт для мови C у 1995, але лише для того, щоб виправити деякі деталі стандарту C89 і додати обширнішу підтримки міжнародних наборів символів. Проте, стандарт піддався подальшому перегляду в кінці 1990-х, привівши до публікації ISO 9899:1999 у 1999 році. Цей стандарт зазвичай іменують, як «C99». Він був прийнятий, як стандарт ANSI у березні 2000. Стандарт C99 ввів декілька нових особливостей, багато з яких вже були реалізовані у декількох компіляторах: · Вкладені функції. · Змінні можуть оголошуватися будь-де (як у C++). · Введено декілька нових типів даних, зокрема, long long int, явний логічний (булевий) тип даних, і комплексний тип для представлення комплексних чисел. · Масиви зі змінними довжинами. · Підтримка коротких, однорядкових коментарів, що починаються з //, як у BCPL та C++. · Нові бібліотечні функції, як наприклад sprintf. · Нові заголовні файли, як то stdbool.h та inttypes.h · Вдосконалена підтримка стандарту IEEE для роботи з плаваючою крапкою · Виправлено друкарські огріхи. C99 сумісний з C90, однак, має деякі відмінності; зокрема, якщо в декларації ідентифікатора не вистачає специфікатора типу, змінна чи функція надалі не сприймається оголошеною неявно як int. Комітет стандартів вирішив, що важливіше, щобикомпілятори діагностували неуважне упущення специфікатора типу, ніж мовчки обробляли код. На практиці, компілятори, ймовірно, діагностують упущення, але й приймають змінну оголошеною як int і продовжують переклад програми. GCC та інші компілятори C наразі підтримують багато з нових можливостей C99. Проте, вони меншою мірою підтримуються компіляторами таких компаній, як Microsoft і Borland, котрі зосередилися переважно на C++, відтоді, як C++ забезпечує подібну функціональність. Міжнародна організація зі стандартизації (ISO) у грудні 2011 опублікувала оновлений варіант стандарту для мови Сі - ISO/IEC 9899:2011, що був створений під кодовим ім'ям C1X і прийшов на зміну стандарту C99. Оскільки стандарт розвивався досить тривалий час, пройшовши стадії випуску декількох чорнових редакцій, сучасні компілятори, такі як GCC 4.6 і LLVM 3.0, уже підтримують більшість описаних у специфікації можливостей. У новій специфікації збільшена сумісність з мовою С++ і представлені деякі нові можливості, такі як: · підтримка багатонитевості, · підтримка Unicode, · вилучена функція gets, · інтерфейс для перевірки допустимих меж і діапазонів значень, · анонімні структури та об'єднання (наприклад, можна вкласти блок union в struct), · додаткова функція для миттєвого виходу з програми quick_exit, · статичні твердження (Static assertions), · задіяння додаткових макросів для перевірки чисел з плаваючою комою. Фінальний текст стандарту не доступний для вільного завантаження (тільки платна завантаження), але можна завантажити останню чорнову редакцію (PDF, 3.6 Мб, 701 стор), яка майже не відрізняється від затвердженої специфікації. 2. Сфери застосування мови програмування С Одним із наслідків значного поширення та ефективності С є те, що компілятори, бібліотеки та інтерпретатори багатьох інших високорівневих мов програмування реалізуються на С. С використовується, як проміжна мова деякими високорівневими мовами програмування. Це здійснюється одним із двох наступним способів: · Продукується текст програми мовою C паралельно з іншим вихідним кодом: машинним, об'єктним та/або двійковим. Наприклад, така поведінка характерна для деяких діалектів мови Lisp (Lush). · Продукується виключно текст на С. Приклади: Eiffel, Sather; Esterel. Вихідний текст програми на С передається компілятору С, який видає кінцевий машинний або двійковий код. Це зроблено задля переносимості (компілятори мови С існують майже для усіх платформ) і уникання необхідності розвитку специфічних для машини генераторів команд. Завдяки величезній популярності мови програмування C, останні стандарти мови Фортран ввели механізм сумісності, що дозволяє просту і стандартизовану взаємодію між програмами на Фортран та C. Сумісність досягається на майже усіх основних рівнях: вбудованих і похідних типів, вказівників, змінних, функцій та процедур. 3. Основні відмінності мови С++ від мови С Мова програмування C++ розроблена на основі С, і була отримана у наслідок додавання Б'ярном Страуструпом до неї об'єктно-орієнтованої функціональності із C-подібним синтаксисом. Мова Сі++ багато в чому є надмножиною Сі. Нові можливості Сі++ включають оголошення у вигляді виразів, перетворення типів у вигляді функцій, оператори new і delete, тип bool, посилання, розширене поняття константності та змінності, функції, що підставляються, аргументи за замовчанням, перевизначення, простори імен, класи (включаючи і всі пов'язані з класами можливості, такі як успадкування, функції-члени (методи), віртуальні функції, абстрактні класи і конструктори), перевизначення операторів, шаблони, оператор ::, обробку винятків, динамічну ідентифікацію і багато що інше. Сі++ є також мовою строгого типування і накладає більше вимагань щодо дотримання типів, порівняно з Сі. У Сі++ з'явилися коментарі у вигляді подвійної косої риски («//»), які були в попереднику Сі — мові BCPL. Деякі особливості Сі++ пізніше були перенесені в Сі, наприклад ключові слова const і inline, оголошення в циклах for і коментарі в стилі Сі++ («//»). У пізніших реалізаціях Сі також були представлені можливості, яких немає в Сі++, наприклад макроси vararg і покращена робота з масивами-параметрами. знати : v хронологію та історія виникнення мови програмування С; v сфери застосування мови програмування С; v основні відмінності мови С++ від мови С. вміти : v застосовувати мову програмування С; v здійснювати порівняльну характеристику мов С++ та С. 1. Дайте означення мови С. 2. Перелічіть можливості структурного програмування мовою С. 3. Назвіть спеціальні властивості мови С. 4. Дайте коротку характеристику функцій компілятора AT&T. 5. Перелічіть можливості мови програмування С. 6. Назвіть сфери застосування мови програмування С. 7. Назвіть основні відмінності мови програмування С++ та мови С. [3] c. 41-53, [4] c. 7-11 Питання для опрацювання 1. Двійкова, вісімкова та шістнадцятвова системи числення. 2. Формати представлення чисел у різних системах числення. 3. Стандарти представлення чисел зі знаком. 4. Стандарт ASCII для кодування символьної інформації. Під час вивчення даної теми студенти повторять матеріал з дисциплін «Комп’ютерна логіка» та «Архітектура комп’ютерів», який стосується особивостей зберігання різних даних в комп’ютері. Крім того, слід звернути увагу на формати представлення чисел у різних системах числення та на стандарти представлення чисел із знаком. 1. Двійкова, вісімкова та шістнадцяткова системи числення. Системою числення, або нумерацією, називається сукупність правил і знаків, за допомогою яких можна відобразити (кодувати) будь-яке невід'ємне число. До систем числення висуваються певні вимоги, серед яких найбільш важливими є вимоги однозначного кодування невід'ємних чисел 0, 1,… з деякої їх скінченної множини — діапазону Р за скінченне число кроків і можливості виконання щодо чисел арифметичних і логічних операцій. Крім того, системи числення розв'язують задачу нумерації, тобто ефективного переходу від зображень чисел до номерів, які в даному випадку повинні мати мінімальну кількість цифр. Від вдалого чи невдалого вибору системи числення залежить ефективність розв'язання зазначених задач і її використання на практиці. Двійкова система числення використовує для запису чисел тільки два символи, зазвичай 0 (нуль) та 1 (одиницю). Детальніше, двійкова система числення є позиційною системою числення, база якої дорівнює двом. Завдяки тому, що таку систему доволі просто використовувати у електричних схемах, двійкова система отримала широке розповсюдження у світі обчислювальних пристроїв. Двійкове число можна представити як послідовність будь-яких об'єктів, які можуть знаходитися в одному з двох можливих станів. Наприклад: Числа, що можуть приймати значення 0 або 1: 1 0 1 0 0 1 1. Позиції, на яких можуть стояти хрестики або нулики: х о х о о х х. Вузли електричної схеми, які може бути, а може не бути зіструмлено. Ділянки магнітної смужки, які може бути, а може не бути намагнічено. Зазвичай, для позначення двійкових чисел використовують нулі та одиниці. Перші персональні комп'ютери для відображення чисел мали ряд електричних лампочок (кожна з яких, зрозуміло, може або світитися, або бути вимкненою). Лічити у двійковій системі не складніше, ніж у будь-якій іншій. Скажімо, у десятковій системі, коли число у поточному розряді сягає десяти, то розряд обнуляється і одиниця додається до старшого. Наприклад: 9+1=10, 44+7=51; Аналогічним чином у двійковій системі: коли число в розряді сягає двох - розряд обнуляється і одиниця додається до старшого розряду. Тобто: 1+1=10. Зверніть увагу, "10" у цьому записі - двійкове число, у десятковій системі це число записується як "2". А десяткове 9+1=10 у двійковій системі буде виглядати так: 1001+1=1010 (після додавання одиниці число в останньому розряді дорівнює двом, тож розряд обнуляється і одиниця додається до передостаннього(старшого) розряду). Вісімко́ва систе́ма чи́слення — позиційна цілочисельна система числення з основою 8. Для представлення чисел в ній використовуються цифри 0 до 7. Вісімкова система часто використовується в галузях, пов'язаних з цифровими пристроями. Характеризується легким переводом вісімкових чисел у двійкові і назад, шляхом заміни вісімкових чисел на триплети двійкових. Раніше широко використовувалася в програмуванні і взагалі комп'ютерної документації, проте в наш час[Коли?] майже повністю витіснена шістнадцятковою. У вісімковій системі вказуються права доступу для команди chmod в Unix-подібних операційних системах. Таблиця переведення вісімкових чисел в двійкові: 08 = 000218 = 001228 = 010238 = 011248 = 100258 = 101268 = 110278 = 1112Для переведення вісімкового числа в двійкове необхідно замінити кожну цифру вісімкового на триплет двійкових цифр. Наприклад: 25418 = 010 101 100 001 = 0101011000012 Шістнадцяткова систе́ма чи́слення — це позиційна система числення, кожне число в якій записується за допомогою 16-ти символів. Цю систему часто називають також Hex (початкові літери англ. hexadecimal — шіснадцятковий). Спочатку планувалось вживати латинське sexa замість hexa, проте це слово сприймалось неоднозначно. Для запису чисел в цій системі окрім 10 арабських цифр (від 0 до 9) використовують 6 літер латинської абетки: A, B, C, D, E, F.
3x162 + 14x161 + 8x160 = 768 + 224 + 8 = 1000. Шістнадцяткова система числення широко вживана в інформатиці, оскільки значення кожного байту можна записати у вигляді двох цифр шістнадцяткової системи. Таким чином значення послідовних байтів можна представити у вигляді списку двозначних чисел. В той же час запис 4 бітів можна представити однією шістнадцятковою цифрою. В математиці числа в недесяткових системах позначуються нижнім індексом, що визначає основу позиції. Наприклад, 1016 = 1610. В інформатиці прийняті інші форми запису. В різних мовах програмування шістнадцятковий запис виглядає так: · C, C++, Java — використовують префікс 0x (нуль та ікс) напр. 0x102f, а в текстових послідовностях \x, напр. «\x2f» · Деякі версії Асемблера — за числом ставлять h, напр.102fh. При цьому, якщо число починається не з десяткової цифри, то спереду ставиться «0» (нуль): 0FFh (25510) · Інші асемблери (AT&T, Motorola), а також Паскаль і деякі версії Бейсіку використовують префікс $, напр. $102f · Інші версії Бейсіку використовують для позначення шістнадкових цифр комбінацію «&h». Наприклад, &h5A3. · HTML — кольори RGB (Red — Червоний, Green — Зелений, Blue — Синій) записується як 3 двозначні числа hex від 0 до FF(25510) з попереднім знаком #, наприклад рожевий — #FF8080, сірий — #808080, чорний — #000000. Цей запис стосується 24-бітного кольору, який приписують тому чи іншому графічному елементу документу HTML. 2. Формати представлення чисел у різних системах числення. Системи числення діляться на непозиційні та позиційні, головна відмінність між якими являється в способі визначення значення символу (цифри) в числі. В непозиційних системах числення значення символу не залежить від його положення в числі. Нехай
Як слідує з рівняння (1.1), для запису числа використали К символів. Вираз (1.1) характерний для системи числення, яка виникла в Древньому Єгипті в ХХХ столітті до н.е. Кожен символ зображується нерогліфом (від грецького «священна різьба»). Тому ці системи були названі нерогріфічними. Найбільш відомою системою числення являється римська, в якій є знаки I, V, X, L, C, D, M. Вони відповідають числам 1, 5, 10, 50, 100, 500, 1000 відповідно. В римській системі перші числа натурального ряду від 1 до 10 записуються наступним чином I, II, III, IV, V, VI, VII, VIII, IX, X. На відміну від (1.1) в римській системі використана, як принцип складання, так і розкладання. Так символ І, поставлений зліва от старшого знака (V, X), зменшує його значення на одиницю. В той же час, символ І, поставлений справа від старшого розряду (V, X),збільшує його значення на одиницю. Цей же принцип діє для будь-якої пари знаків. Так, число 1954 представляється МСMLIV, де CM=900, а IV=4. Другим представником класу непозиційних систем являється алфавітна система. Найбільш відома грецька система, виникла близько 500 р. до н.е. в Міллеті. Тут для представлення чисел використовувались всі букви алфавіту і деякі старі, вийшовши з вжитку букви. Непозиційні системи числення мають ряд недоліків: - відсутність нуля - безкінечне число символів - виняткова складність арифметичних операцій. В позиційних системах числення значення кожної цифри визначається як її виглядом, так і місцем (позицією) в числі. Алфавіт позиційних систем мають обмежене (кінцеве) число символів, що являють цифри. Найбільш відомою є десяткова система , що має алфавіт(базу) {0, 1, 2, 3, 4, 5, 6, 7, 8, 9} і основні 10. Наприклад, число 222 включає 3 однакових цифри, та їм відповідають різні значення. Самому лівому символу відповідає число
Символ 10 (1.2) означає, що число записано в десятковій системі числення. В загальному випадку число в позиційній системі записується у вигляді:
При цьому окрема позиція у виглядів числа називається розрядом, а номер позиції – номером розряду. В загальному випадку число
Цей поліном можна представити скорочено в вигляді:
Існують системи числення, основна яких відмінна від 10. Як правило, люди використовували для підрахунку пальці. В цьому зв’язку історично існувала 5 система числення (одна рука), десяткова (пальці двох рук), 12 система, 20 система числення (пальці двох рук і ніг). Першою відомою позиційною системою була 60-річна, виникла в древньому Вавилоні близько 2500 років до н.е. Десяткова система була створена в Індії близько VII століття, при цьому нуль появився тільки в IX столітті. Індійські цифри були позичені арабськими купцями, о від них цифри потрапили у Європу. Нехай для представлення будь-якого розряду числа використовуються цифри
Видно, що р=10 з виразу (1.5) і (1.6) адекватні. Представлені (1.6) відповідають однорідній системі числення, у якій засновані однаково для всіх розрядів. В загальному випадку кожному розряду Прикладом неоднорідної системи числення являється система підрахунку часу, для якої молодший розряд
Далі будемо розглядати тільки однорідні позиційні системи числення і будемо їх називати їх просто «системи». При записі правильних дробів позиції нумеруються в наступному порядку: -1, -2, … . При цьому ваги розрядів будуть негативними. Наприклад дріб представляються у виді виразу
Мішані дроби також можна представити у вигляді поліномів:
де р- основа системи числення. Вираз (1.8) відповідає лінійному запису числа А:
і його значення визначається за формулою:
Нижче в таблиці 1.3.1 наведені вигляд перших 16 чисел в різних системах числення. Вираз (1.9) можна використовувати для знаходження десяткових значень числа, представлених в будь-якій системі числення. При цьому степені основ визначаються за правилом десяткової системи. Наприклад, число
|
Последнее изменение этой страницы: 2019-04-19; Просмотров: 409; Нарушение авторского права страницы
 Студент повинен
Студент повинен  Питання для самоконтролю
Питання для самоконтролю Література
Література Методичні рекомендації
Методичні рекомендації Питання для самоконтролю
Питання для самоконтролю Література
Література Методичні рекомендації
Методичні рекомендації - запис числа системі числення D,
- запис числа системі числення D, 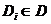 - символи системи, вони складають базу
- символи системи, вони складають базу 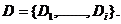 Тоді число
Тоді число  (1.1)
(1.1)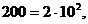 наступному – число
наступному – число 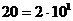 і, на кінець, самому правому – число
і, на кінець, самому правому – число 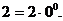 Цю залежність можна виразити формулою:
Цю залежність можна виразити формулою: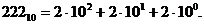 (1.2)
(1.2) (1.3)
(1.3)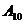 можна задати загальним випадком:
можна задати загальним випадком: (1.4)
(1.4) (1.5)
(1.5)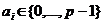 , де р- основні системи числення. Тоді число, записане у вигляді (1.3), відповідає виразу:
, де р- основні системи числення. Тоді число, записане у вигляді (1.3), відповідає виразу: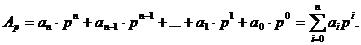 (1.6)
(1.6)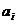 може відповідати своя основа
може відповідати своя основа  . Це характерне для неоднорідних систем числення, де кількість допустимих символів може бути різноманітне для різних розрядів.
. Це характерне для неоднорідних систем числення, де кількість допустимих символів може бути різноманітне для різних розрядів.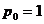 (секунди), другий (хвилини)
(секунди), другий (хвилини) 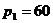 секунд, третій (години)
секунд, третій (години) 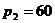 хвилини, четвертий (доба)
хвилини, четвертий (доба) 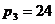 години, п’ятий (роки)
години, п’ятий (роки)  діб. Так час в три роки, 15 діб, 13 годин, 39 хвилин, 28 секунд можна визначити наступним чином:
діб. Так час в три роки, 15 діб, 13 годин, 39 хвилин, 28 секунд можна визначити наступним чином: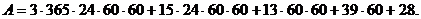

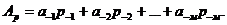 (1.7)
(1.7)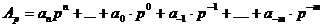 (1.8)
(1.8)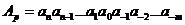
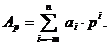 (1.9)
(1.9) можна представити у вигляді (1.9) і знайти, що:
можна представити у вигляді (1.9) і знайти, що: