
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Ініціалізація елементів масивів
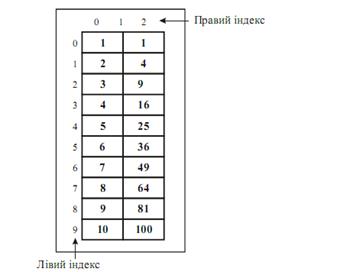
Ознакою масиву при описі є наявність парних дужок []. Константа або константний вираз в квадратних дужках задає число елементів масиву. При описі масиву може бути виконана ініціалізація його елементів. Існує два методи ініціалізації елементів масивів: розмірних і безрозмірних масивів. Ініціалізація елементів "розмірних" масивів У мові програмування C++ передбачено можливість ініціалізації елементів масиву. Формат ініціалізації елементів масиву подібний до формату ініціалізації інших змінних: тип ім'я_масиву[розмір] = [перелік_значень]; У цьому записі елемент перелік_значень є перелік значень ініціалізації елементів масиву, розділених між собою комами. Тип кожного значення ініціалізації повинен бути сумісний з базовим типом масиву (елементом тип). Перше значення ініціалізації буде збережено в першій позиції масиву, друге значення – в другій і т.д. Зверніть увагу на те, що крапка з комою ставиться після закритої фігурної дужки (}). Наприклад, в такому прикладі 10-елементний цілочисельний масив ініціалізувався числами від 1 до 10: int Array[10] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10}; Після виконання цієї настанови елемент Array[0] набуде значення 1, а елемент Array[9] –значення 10. Для символьних масивів, призначених для зберігання рядків, передбачено скорочений варіант ініціалізації, який має таку форму: char ім'я_масиву[розмір] = "рядок"; Наприклад, такий фрагмент коду програми ініціалізує масив str фразою "привіт". char str[7] = "привіт"; Це рівнозначно по-елементній ініціалізації: char str[7] = {'п', 'p', 'и', 'в', 'і', 'т', '\0'}; Оскільки у мові програмування C++ рядки повинні завершуватися нульовим символом, то переконайтеся, що під час оголошення масиву його розмір вказано з врахуванням ознаки кінця. Саме тому в попередньому прикладі масив str оголошений як 7-елементний, хоча у слові "привіт" тільки шість букв. Під час використання рядкового літерала компілятор добавляє нульову ознаку кінця рядка автоматично. Багатовимірні масиви ініціалізуються за аналогією з одновимірними. Наприклад, такий фрагмент коду програми масив Array ініціалізувався числами від 1 до 10 і квадратами цих чисел. int Array[10][2] = {1, 1, 2, 4, 3, 9, 4, 16, 5, 25, 6, 36, 7, 49, 8, 64, 9, 81, 10, 100}; Тепер розглянемо, як елементи масиву Array розташовуються в пам'яті .
Рисунок. Схематичне представлення ініціалізованого масиву Array Під час ініціалізації багатовимірного масиву перелік ініціалізацій кожної розмірності (підгрупу ініціалізацій) можна помістити у фігурні дужки. Ось, наприклад, як виглядає ще один варіант запису попереднього оголошення: int Array[10][2] = { {1, 1), {2, 4}, {3, 9}, {4, 16}, {5, 25}, {6, 36}, {7, 49}, {8, 64}, {9, 81}, {10, 100} }; Під час використання підгруп ініціалізацій відсутні члени підгрупи ініціалізуються нульовими значеннями автоматично. У наведеному нижче коді програми масив Array використовують для пошуку квадрата числа, введеного користувачем. Програма спочатку здійснює пошук заданого числа в масиві, а потім виводить відповідне йому значення квадрата. Код програми . Демонстрація механізму пошуку потрібного елемента у двовимірному масиві #include <iostream> // Потокове введення-виведення using namespace std; // Використання стандартного простору імен int Array[10][2] = { {1, 1}, {2, 4}, {3, 9), {4, 16), (5, 25}, (6, 36}, {7, 49}, (8, 64}, (9, 81}, {10, 100} }; int main() { int i, j; for(;;) { cout << "Введіть число від 1 до 10: "; cin >> i; if(i>=1)&&(i<=10) break; } // Пошук значення i. for(j=0; j<10; j++) if(Array[j][0] == i) break; cout << "Квадрат числа " << i << " дорівнює " << Array[j][1]; getch(); return 0; } Глобальні масиви ініціалізувалися на початку виконання програми, а локальні – під час кожного виклику функції, у якій вони містяться. Розглянемо такий приклад: Код програми . Демонстрація механізму ініціалізації елементів двовимірного масиву #include <iostream> // Потокове введення-виведення #include <cstring> // Робота з рядковими типами даних using namespace std; // Використання стандартного простору імен void Fun1(); int main() { Fun1(); Fun1(); getch(); return 0; } void Fun1() { char str[80] ="Це просто тест\n"; cout << str; strcpy(str, "Змінено\n"); // Змінюємо значення рядка str. cout << str; } Внаслідок виконання ця програма відображає на екрані такі результати: Це просто тест Змінено Це просто тест Змінено У цьому коді програми масив str ініціалізувався під час кожного виклику функції Fun1(). Той факт, що під час її виконання масив str змінюється, ніяк не впливає на його повторну ініціалізацію при подальших викликах функції Fun1(). Тому під час кожного входження в неї на екрані монітора з'являється такий текст: Це просто тест "Безрозмірна" ініціалізація елементів масивів Припустимо, що ми використовуємо такий варіант ініціалізації елементів масиву для побудови таблиці повідомлень про помилки: char e1[14] = "Ділення на 0\n"; char е2[23] = "Кінець файлу\n"; char е3[21] = "У доступі відмовлено\n"; Неважко припустити, що вручну незручно підраховувати символи у кожному повідомленні, щоб визначити коректний розмір масиву. На щастя, у мові програмування C++ передбачено можливість автоматичного визначення довжини масивів шляхом використання їх "безрозмірного" формату. Якщо в настанові ініціалізації масиву не вказано його розмір, то мова програмування C++ автоматично створить масив, розмір якого буде достатнім для зберігання всіх значень ініціалізацій. При такому підході попередній варіант ініціалізації елементів масиву для побудови таблиці повідомлень про помилки можна переписати так: char e1[] = "Ділення на 0\n"; char e2[] = "Кінець файлу\n"; char е3[] = "У доступі відмовлено \n"; Крім зручності в первинному визначенні масивів, метод "безрозмірної" ініціалізації дає змогу змінити будь-яке повідомлення без переліку його довжини. Тим самим усувається можливість внесення помилок, викликаних випадковим прорахунком. "Безрозмірна" ініціалізація елементів масивів не обмежується одновимірними масивами. Під час ініціалізації багатовимірних масивів Вам треба вказати усі дані, за винятком крайньої зліва розмірності, щоб С++-компілятор міг належним чином індексувати масив. Використовуючи "безрозмірну" ініціалізацію масивів, можна створювати таблиці різної довжини, даючи змогу компіляторові автоматично виділяти область пам'яті, достатню для їх зберігання. У такому прикладі масив Array[][] оголошується як "безрозмірний": int Array[][2] = { 1, 1, 2, 4, 3, 9, 4, 16, 5, 25, 6, 36, 7, 49, 8, 64, 9, 81, 10, 100 }; Перевага такої форми оголошення перед "габаритною" (з точним указанням усіх розмірностей) полягає у тому, що програміст може подовжувати або укорочувати таблицю значень ініціалізації, не змінюючи розмірності масиву. 2. Порядок практичного використання багатовимірних масивів під час створення програм. C++ надає прямокутні багатовимірні масиви, хоча на практиці вони набагато рідше вживані ніж масиви покажчиків. Уявіть собі задачу по перетворенню дати з дня місяця в день року і навпаки. Наприклад, 1-го березня — це 60-ий день звичайного року і 61-ий день високосного. Давайте визначимо дві функції для здійснення перетворення: day_of_year перекладає місяць і день у день року, іmonth_day, яка переводить день року в місяць і день. Так як остання функція обчислює два значення, аргументи місяця і дня будуть покажчиками: month_day(1988, 60, &m, &d)присвоїть m значення 2, а d значення 29 (29-го лютого). Обидві ці функції потребують тієї самої інформації — таблиці з кількістю днів у кожному місяці («рівно 30 днів у вересні ...»). Так як кількість днів відрізняється в високосному і невисокожному році, буде легше розділити їх на два ряди у двохвимірному масиві, після чого звертати увагу на лютий під час обчислень. Масив і функції для здійснення перетворень слідують: static char daytab[2][13] = { {0, 31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31}, {0, 31, 29, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31} }; /* day_of_year: отримати день року маючи місяць і день */ int day_of_year(int year, int month, int day) { int i, leap; leap = year%4 == 0 && year%100 != 0 || year%400 == 0; for (i = 1; i < month; i++) day += daytab[leap][i]; return day; } /* month_day: отримати місяць і день з дня року */ void month_day(int year, int yearday, int *pmonth, int *pday) { int i, leap; leap = year%4 == 0 && year%100 != 0 || year%400 == 0; for (i = 1; yearday > daytab[leap][i]; i++) yearday -= daytab[leap][i]; *pmonth = i; *pday = yearday; }Якщо пригадуєте, арифметичним значенням логічного виразу, як у випадку leap (англ. високосний), може бути або нуль (хибно), або один (істина), тож це значення можна також використати як індекс масиву daytab. Масив daytab повинен бути зовнішнім для обох, day_of_year і month_day, щоб обидва могли користуватись ним. Ми оголосили масив як char для ілюстрації того як використовуватиchar для збереження малих незнакових цілих. daytab — це перший двовимірний масив з яким ми досі стикалися. У C, двовимірний масив, це насправді одновимірний, кожен елемент якого також являється масивом. Тому індекси записуються як daytab[i][j] /* [рядок][стовпчик] */замість daytab[i,j] /* НЕПРАВИЛЬНО */За винятком цієї різниці в нотації, двовимірні масиви можна трактувати майже так само як і в інших мовах. Елементи зберігаються рядами, тож індекс з правого боку (або стовпчик), змінюється найшвидше, коли до елементів звертаються в послідовності, в які їх збережено. Такий масив ініціалізується за допомогою, включеного у фігурні дужки, списку ініціалізаторів; кожний рядок двовимірного масиву ініціалізується відповідним другорядним списком. Ми почали масив daytab зі стовпчика, який містить 0, тож цифри місяців можна відраховувати природнішим 1 до 12, замість 0 до 11. Оскільки неможливо використати пропуск у цій ситуації, це зрозуміліше ніж пізніша зміна індексів. При передачі двовимірного масиву як аргумент функції, оголошення параметра функції повинно включати кількість стовпчиків; кількість рядків не є важливим так як те, що передається, як ми це раніше засвоїли, це покажчик на масив рядків, кожен з яких містить масив з 13-ти елементів типу int. У цьому конкретному випадку, це покажчик на об'єкти, що являють собою масиви з 13-и int. Таким чином, якщо масив daytab передати функції f, оголошенням f буде: f(int daytab[2][13]) { ... }Також це могло би бути f(int daytab[][13]) { ... }так як кількість рядків не є важливою, або це могло б також бути f(int (*daytab)[13]) { ... }що вказує на те, що параметр — це покажчик на масив з 13-и цілих. Дужки потрібні, оскільки квадратні дужки [] мають більший пріоритет за *. Без дужок оголошення int *daytab[13]буде масивом з 13 покажчиків на цілі int. Як узагальнення, тільки перший вимір (індекс) масиву є вільним, решту потрібно вказувати. Розділ 5.12 включає подальше обговорення складних оголошень. знати : v Означення масиву. v Види масивів v Організацію двовимірних масивів. v Організацію багатовимірних масивів. v Ініціалізацію елементів масивів. v Ініціалізацію елементів «розмірних» масивів. v «Безрозмірну» ініціалізацію елементів масивів. вміти : v Оголошувати та працювати з двовимірними масивами. v Оголошувати та працювати з багатовимірними масивами. v Використовувати багатовимірні масиви при створення власних програм. 1. Дайье означенняння масиву. 2. Назвіть види масивів 3. Як здійснити організацію двовимірних масивів? 4. Як здійснити організацію багатовимірних масивів? 5. Як здійснити ініціалізацію елементів масивів? 6. Як здійснити ініціалізацію елементів «розмірних» масивів? 7. Як здійснити «безрозмірну» ініціалізацію елементів масивів? [1] с. 78-82, [4] c. 112-114 Питання для опрацювання 1. Порядок задання і створення масивів структур. 2. Порядок практичного використання масивів структур під час створення програм Під час вивчення даної теми студенти повинні освоїти особливості роботи з масивами структур у С++, навчитись використовувати масиви структур під час складання власних програм . 1. Порядок задання і створення масивів структур. Уявімо собі, що нам треба написати програму, яка би рахувала кількість знайдених ключових слів C. Нам потрібен би був масив символьних ланцюжків, який би містив назви, і масив цілих для відліку. Одним з можливих варіантів було би використання двох паралельних масивів keyword і keycount, як от char *keyword[NKEYS]; int keycount[NKEYS];Але самий факт того, що масиви паралельні, підказує відмінну організацію — масив структур. Кожне ключове слово складатиметься з пари: char *word; int cout;і ці пари утворюватимуть масив. Оголошення структури struct key { char *word; int count; } keytab[NKEYS];заявляє про структуру типу key, і означує масив keytab, що міститиме структури цього типу, відводячи для них місце в пам'яті. Кожен елемент масиву буде структурою. Це можна також написати як struct key { char *word; int count; }; struct key keytab[NKEYS];Оскільки структура keytab містить сталий набір імен, найлегшим буде зробити її зовнішньою змінною й ініціювати раз і назавжди під час її означення. Ініціалізація структури аналогічна попереднім — за визначенням слідує список ініціалізаторів, включених у фігурні дужки: struct key { char *word; int count; } keytab[] = { "auto", 0, "break", 0, "case", 0, "char", 0, "const", 0, "continue", 0, "default", 0, /* ... */ "unsigned", 0, "void", 0, "volatile", 0, "while", 0 };Ініціалізатори перелічено парами, згідно елементів структури. Було би точніше включити ініціалізатори кожного «рядка» структури у фігурні дужки, як от { "auto", 0 }, { "break", 0 }, { "case", 0 }, ...але внутрішні дужки необов'язкові, якщо ініціалізатори складаються з простих змінних або символьних ланцюжків, і коли всі присутні. Зазвичай, кількість елементів масиву keytabобчислюється автоматично, при наявності ініціалізаторів і порожньому []. Програма відліку ключових слів почнеться з означення keytab. Функція main читатиме ввід шляхом повторного виклику getword, яка добуватиме по одному слову за раз. Кожне слово шукатиметься вkeytab за допомогою нашої версії функції бінарного пошуку. Список ключових слів потрібно буде сортувати в зростаючій послідовності в таблиці. 2. Порядок практичного використання масивів структур під час створення програм. #include <stdio.h> #include <ctype.h> #include <string.h> #define MAXWORD 100 int getword(char *, int); int binsearch(char *, struct key *, int); /* відлік ключових слів C */ main() { int n; char word[MAXWORD]; while (getword(word, MAXWORD) != EOF) if (isalpha(word[0])) if ((n = binsearch(word, keytab, NKEYS)) >= 0) keytab[n].count++; for (n = 0; n < NKEYS; n++) if (keytab[n].count > 0) printf("%4d %s\n", keytab[n].count, keytab[n].word); return 0; } /* binsearch: знаходить слово word у tab[0]...tab[n-1] */ int binsearch(char *word, struct key tab[], int n) { int cond; int low, high, mid; low = 0; high = n - 1; while (low <= high) { mid = (low+high) / 2; if ((cond = strcmp(word, tab[mid].word)) < 0) high = mid - 1; else if (cond > 0) low = mid + 1; else return mid; } return -1; }Ми покажемо функцію getword за якусь мить; поки-що досить знати, що кожний її виклик знаходить нове слово, яке копійовано в масив, вказаний як її перший аргумент. Кількість NKEYSє числом ключових слів у keytab. Хоча ми могли би самі порахувати це число, набагато легше і безпечніше залишити це машині, особливо якщо список може змінитися пізніше. Однією з можливостей буде завершити список ініціалізаторів нульовим покажчиком, після чого ітерувати через keytab до досягнення кінця. Але це вкрай потрібно, оскільки розмір масиву повністю визначається під час компіляції. Розмір масиву складає розмір одного елемента помножено на кількість елементів, тож кількість складатиме просто розмір keytab / розмір struct keyC забезпечує унарним компіляційним оператором під назвою sizeof, який можна застосувати для визначення розміру будь-якого об'єкту. Вирази sizeof об'єкті sizeof (назва типу)повертають ціле число, рівне розмірові в байтах вказаного об'єкту або типу. (Точніше, sizeofповертає беззнакове ціле значення, чий тип size_t визначено в файлі заголувку <stddef.h>.) Об'єктом може служити як змінна, так і масив або структура. Назва типу також може бути однією з назв основних типів, таких як int або doble, або ж назвою похідного типу, як структура або покажчик. В нашому випадку, кількість ключових слів дорівнюватиме розмірові масиву, поділено на розмір одного елемента. Це обчислення використано в твердженні #defineдля того, щоб встановити значення NKEYS: #define NKEYS (sizeof keytab / sizeof(struct key))Іншим шляхом буде ділення масиву на розмір певного елемента: #define NKEYS (sizeof keytab / sizeof(keytab[0]))Останнє має перевагу в тому, що його не потрібно міняти, якщо тип змінено. sizeof неможливо використати в рядку #if, оскільки препроцесор не розуміє назв типів. Зате вираз у #define не обчислюється препроцесором, тож цей код чинний. Тепер, щодо функції getword. Ми написали більш узагальнену getword, ніж ця програма потребує, але вона не є складною. getword добуває наступне «слово» зі вводу, де словом може служити або ланцюжок з літер і цифр, що починається з літери, або один символ, що не являється пробілом. Функція повертає перший знак слова, або EOF у випадку кінця файла, або самий знак, якщо він не є частиною алфавіта. /* getword: одержує наступне слово зі вводу */ int getword(char *word, int lim) { int c, getch(void); void ungetch(int); char *w = word; while (isspace(c = getch())) ; if (c != EOF) *w++ = c; if (!isalpha(c)) { *w = '\0'; return c; } for ( ; --lim > 0; w++) if (!isalnum(*w = getch())) { ungetch(*w); break; } *w = '\0'; return word[0]; }getword використовує getch і ungetch. Коли набір буквенно-цифрових лексем закінчився, це означає, що getword зайшла на один символ задалеко. Викликungetch проштовхує символ назад на ввід для наступного виклику функції. getword також використовує isspace, для ігнорування пробілів, isalpha, щоб розпізнати літери, і isalnumдля розрізнення літер і цифр; усі зі стандартного файла заголовка <ctype.h>. знати : v Особливості роботи з масивами. v Особливості роботи із структурами. v Взаємозв’язок між масивами і структурами. v Особливості роботи з масивами структур. вміти : v Використовувати масиви структур під час складання власних програм. 1. Назвіть особливості роботи з масивами. 2. Назвіть особливості роботи із структурами. 3. В чому полягає взаємозв’язок між масивами і структурами? 4. Назвіть особливості роботи з масивами структур. [4] c. 133-137 1.10. Використання динамічної пам’яті у мові С++ Питання для опрацювання 1. Створення динамічних масивів за допомогою вказівників. 2. Передача аргументів процедур та функцій з використаннм вказівників. 3. Використання масивів вказівників. Під час опрацювання даної теми студенти повинні в ивчити порядок роботи із динамічною пам’яттю у С++, а також порядок використання динамічних структур даних під час складання програм . 1. Створення динамічних масивів за допомогою вказівників. Вказівник — це символічне представлення адреси. Він використовується для непрямої адресації змінних і об'єктів. В мові С++ є операція визначення адреси — &, за допомогою якої визначається адреса комірки пам’яті, що містить задану змінну. Наприклад, якщо vr — ім’я змінної, то &vr — адреса цієї змінної. В С++ також існують і змінні типу вказівник. Значенням змінної типу вказівник є адреса змінної або об'єкта. Нехай змінна типу вказівник має ім'я ptr, тоді в якості значення їй можна присвоїти адресу за допомогою наступного оператора: ptr=&vr; В мові С++ при роботі з вказівниками велике значення має операція непрямої адресації — *. Операція *дозволяє звертатися до змінної не напряму, а через вказівник, який містить адресу цієї змінної. Ця операція є одномісною і має асоціативність зліва направо. Цю операцію не слід плутати з бінарною операцією множення. Нехай ptr — вказівник, тоді *ptr — це значення змінної, на яку вказує ptr. Опис змінних типу вказівник здійснюється за допомогою операторів наступної форми: <тип> *<ім'я вказівника на змінну заданого типу>; Приклад1. Опис вказівників. int *ptri; //вказівник на змінну цілого типу char *ptrc; //вказівник на змінну символьного типу float *ptrf; //вказівник на змінну з плаваючою точкою Такий спосіб оголошення вказівників виник внаслідок того, що змінні різних типів займають різну кількість комірок пам'яті. При цьому для деяких операцій з вказівниками необхідно знати об'єм відведеної пам'яті. Операція * в деякому розумінні є оберненою до операції &. Вказівники використовуються для роботи з масивами. розглянемо оголошення двовимірного масиву: int mas[4][2]; int *ptr; Тоді вираз ptr = mas вказує на перший стовпець першого рядка матриці. Записи mas і &mаs[0][0]рівносильні. Вираз ptr+1 вказує на mas[0][1], далі йдуть елементи: mas[1][0], mas[1][1], mas[2][0] і т. д.;ptr+5 вказує на mas[2][1]. Двовимірні масиви розташовані в пам’яті так само, як і одновимірні масиви, займаючи послідовні комірки пам’яті
Посилання (reference) являє собою видозмінену форму вказівника, яка використовується в якості псевдоніму (другого імені) змінної. У зв’язку з цим посилання не потребують додаткової пам’яті. Для визначення посилання використовують символ & (амперсант), який ставиться перед змінною-посиланням. Змінні типу посилання можуть використовуватися в наступних цілях: · замість передачі у функцію об’єкта за значенням; · для визначення конструктора копії; · для перевантаження унарних операцій; Приклад 2. Використання посилань. В даному випадку ми використовували посилання в якості псевдоніму змінної. В цій ситуації воно називається незалежним посиланням (independent reference) і повинно бути ініціалізоване під час оголошення. Такий спосіб використання посилань може призвести до фатальних помилок, які важко виявити через виникнення плутанини у використанні змінних. Інше застосування посилань — можливість створення параметрів функції, які передаються за допомогою посилання, при цьому перед цим параметром ставиться знак &. Приклад 3. Функція з параметром-посилання. Динамічним називається масив, розмірність якого стає відомою в процесі виконання програми. В С++ для роботи з динамічними об’єктами використовують спеціальні операції new і delete. За допомогою операції new виділяється пам’ять під динамічний об’єкт (який створюється в процесі виконання програми), а за допомогою операції delete створений об’єкт видаляється з пам’яті. Приклад. Виділення пам’яті під динамічний масив. В цьому прикладі mas є вказівником на масив з n елементів. Оператор int *mas=new int[n] виконує дві дії: оголошується змінна типу вказівник, далі вказівнику надається адреса виділеної області пам’яті у відповідності з заданим типом об’єкта. Для цього ж прикладу можна задати наступну еквівалентну послідовність операторів: … Якщо за допомогою операції new неможливо виділити потрібний об’єм пам’яті, то результатом операції newє 0. Іноді при програмуванні виникає необхідність створення багатовимірних динамічних об’єктів. Програмісти-початківці за аналогією з поданим способом створення одновимірних динамічних масивів для двовимірного динамічного масиву розмірності n*k запишуть наступне mas=new int[n][k]; // Невірно! Помилка! Такий спосіб виділення пам’яті не дасть вірного результату. Наведемо приклад створення двовимірного масиву. #include
2. Передача аргументів процедур та функцій з використанням вказівників. У мові C, самі функції не являються змінними, але існує можливість створення покажчиків на функції, які можна присвоїти, розмістити в масиві, передати іншим функціям, бути поверненими іншими функціями тощо. Ми проілюструємо це шляхом модифікації функції сортування, написаної раніше в цьому розділі, в такий спосіб, що якщо задано опцію -n, це сортуватиме ввідні рядки за числовим значенням замість лексикографічного. Процес сортування часто складається з трьох частин: порівнювання — яке визначає порядок пар об'єктів, обмін — що змінює їхню послідовність, і алгоритм сортування — що здійснює порівнювання і обміни до тих пір, доки об'єкти буде упорядковано. Алгоритм сортування повинен бути незалежним від операцій порівнювання і обміну, щоб через передачу йому різноманітних функцій порівнювання і обміну, ми могли добитися сортування за різними критеріями. Саме цей підхід застосовується у нашій новій сортувальній програмі. Лексикографічне порівняння двох рядків здійснюватиметься strcmp, так як і раніше; нам також знадобиться нова функція numcmp, яка би порівнювала два рядки на основі числового значення і повертала такий самий вказівник стану, як це робить strcmp. Ці функції оголошено попередуmain і покажчик до відповідної передаватиметься qsort. Ми занедбали обробку помилок для аргументів, щоб зосередитись на основних питаннях. #include <stdio.h> #include <string.h> #define MAXLINES 5000 /* максимальна кількість рядків для * * сортування */ char *lineptr[MAXLINES]; /* покажчики на текст рядків */ int readlines(char *lineptr[], int nlines); void writelines(char *lineptr[], int nlines); void qsort(void *lineptr[], int left, int right, int (*comp)(void *, void *)); int numcmp(char *, char *); /* сортує рядки вводу */ main(int argc, char *argv[]) { int nlines; /* кількість прочитаних рядків вводу */ int numeric = 0; /* 1, якщо сортування за числовим * * значенням */ if (argc > 1 && strcmp(argv[1], "-n") == 0) numeric = 1; if ((nlines = readlines(lineptr, MAXLINES)) >= 0) { qsort((void**) lineptr, 0, nlines-1, (int (*)(void*,void*))(numeric ? numcmp : strcmp)); writelines(lineptr, nlines); return 0; } else { printf("input too big to sort\n"); return 1; } }У виклику qsort, strcmp і numcmp — це адреси функцій. Оскільки відомо, що це функції, оператор & необов'язковий, так само як його не потрібно перед назвою масиву. Ми написали qsort, таким чином, що вона могла обробляти будь-який тип даних, а не тільки символьні ланцюжки. Як вказує прототипом функції, qsort очікує масиву покажчиків, два цілих і функцію з двома покажчиковими аргументами. Для останніх використовується загальний тип покажчика void *. Будь-який покажчик можна звести до void * і назад, без втрати інформації, тож ми можемо викликати qsort через зведення аргументів до void *. Складне зведення аргуметів функції зводить також аргументи порівнювальної функції. Це, загалом, не матиме жодного ефекту на дійсному представленні, зате запевнить компілятор, що все гаразд. /* qsort: сортує v[left]...v[right] у зростаючій послідовності */ void qsort(void *v[], int left, int right, int (*comp)(void *, void *)) { int i, last; void swap(void *v[], int, int); if (left >= right) /* не робить нічого, якщо масив містить */ return; /* менше ніж два елементи */ swap(v, left, (left + right)/2); last = left; for (i = left+1; i <= right; i++) if ((*comp)(v[i], v[left]) < 0) swap(v, ++last, i); swap(v, left, last); qsort(v, left, last-1, comp); qsort(v, last+1, right, comp); }Оголошення варте вивчення. Четвертим параметром qsort є int (*comp)(void *, void *)яке вказує, що comp — це покажчик на функцію, яка має два аргументи типу void * і повертаєint. Використання comp у рядку if ((*comp)(v[i], v[left]) < 0)узгоджується з оголошенням — comp є покажчиком на функцію, *comp - це сама функція і (*comp)(v[i], v[left])— це її виклик. Дужки потрібні, щоб складові було приєднано належним чином; без них int *comp(void *, void *) /* НЕПРАВИЛЬНО */вказує на те, що comp — це функція, яка повертає покажчик на int, що являється зовсім не тим, що потрібно. Ми вже продемонстрували функцію strcmp, яка порівнює два ланцюжки. Ось інша, numcmp, що порівнює ланцюжки за початковим числовим значенням, обчисленого викликом atof: #include <stdlib.h> /* numcmp: порівнює s1 і s2 за числовим значенням */ int numcmp(char *s1, char *s2) { double v1, v2; v1 = atof(s1); v2 = atof(s2); if (v1 < v2) return -1; else if (v1 > v2) return 1; else return 0; }Функція swap, яка порівнює два покажчики, є тотожною тій, що ми представили раніше в цьому розділі за винятком того, що оголошення змінено на void *. void swap(void *v[], int i, int j;) { void *temp; temp = v[i]; v[i] = v[j]; v[j] = temp; }Можна також додати багато інших опцій до програми сортування, деякі можуть виявитись цікавими вправами. 3. Використання масивів вказівників. Уявіть собі завдання по написанню функції month_name(n), яка би повертала покажчик на символьний ланцюжок, який містить назву n-нного місяця. Це являє собою ідеальне примінення внутрішнього статичного масиву. month_name включатиме приватний масив символьних ланцюжків, і повертатиме покажчик на відповідний, коли викликати її. Цей розділ демонструє, як ініціалізувати такий масив назв. Синтаксис є подібним до попередніх ініціалізацій: /* month_name: повертає назву n-нного місяця */ char *month_name(int n) { static char *name[] = { "Illegal month", "January", "February", "March", "April", "May", "June", "July", "August", "September", "October", "November", "December" }; return (n < 1 || n > 12) ? name[0] : name[n]; }Оголошення name являється масивом символьних покажчиків, таким самим як lineptr у прикладі з сортуванням. Ініціалізатором служить список символьних ланцюжків; кожному з них призначено відповідне положення в масиві. Символи i-ного ланцюжка розміщено в певному місці і покажчик на них збережено в name[i]. Оскільки розмір масиву name не вказано, компілятор сам порахує ініціалізатори і заповнить розмір правильним числом. знати : v Означення вказівника. v Використання вказівників. v Змінні типу вказівник. v Операцію непрямої адресації. v Способи оголошення вказівників. v Означення динамічного масиву. v Операцію new. v Порядок передачі аргументів процедур та функцій з використанням вказівників. v Порядок використання масивів вказівників. вміти : v Використовувати динамічні структури під час написання власних програм. 1. Дайте означення вказівника. 2. Назвіть методи використання вказівників. 3. Дайте означення змінній типу вказівник. 4. В чому полягає операція непрямої адресації? 5. Перелічіть способи оголошення вказівників. 6. Дайте означення динамічного масиву. 7. В чому полягає операція new? 8. Назвіть порядок передачі аргументів процедур та функцій з використанням вказівників. 9. Назвіть порядок використання масивів вказівників. [4] c. 98-111, 137-145
1.11. Форми представлення графів Питання для опрацювання 1. Головні означення та властивості теорії графів. 2. Методи обходу графів. Під час вивчення даної теми студенти мають узагальнити та покращити знання з дисципліни «Дискретна математика», які стосуються особливостей роботи з графами . 1. Головні означення та властивості теорії графів. Теорія графів — розділ математики, що вивчає властивості графів. Наочно граф можна уявити як геометричну конфігурацію, яка складається з точок (вершини) сполучених лініями (ребрами). У строгому визначенні графом називається така пара множин G = (V, E), де V є підмножина будь-якої зліченної множини, а E - підмножина V × V. Визначення графу є настільки загальним, що цим терміном можна описувати безліч подій та об'єктів повсякденного життя. Високий рівень абстракції та узагальнення дозволяє використовувати типові алгоритми теорії графів для вирішення зовнішньо несхожих задач утранспортних і комп'ютерних мережах, будівельному проектуванні, молекулярному моделюваннітощо. Теорія графів знаходить застосування, наприклад, в геоінформаційних системах (ГІС). Існуючі або запроектовані будинки, споруди, квартали і т. п. розглядаються як вершини, а з'єднують їхні дороги, інженерні мережі, лінії електропередачі і т. п. - як ребра. Застосування різних обчислень, вироблених на такому графі, дозволяє, наприклад, знайти найкоротший об'їзний шлях або найближчий продуктовий магазин, спланувати оптимальний маршрут. Теорія графів містить велику кількість невирішених проблем і поки не доведених гіпотез. Формальне означення графа: Нехай X = { x1,…,xn} – деяка скінченна множина (множина вершин), M2 – множина всіх невпорядкованих пар елементів з X, M2 = { (xi,xj ): xi ∈ X, xj ∈ X, i ≠ j}
2. Граф G(X,W) називається повним, якщо W = M2. Якщо множина X містить n вершин, то, очевидно, число ребер повного графа дорівнює Cn2. Повний граф з n вершинами позначається Kn. 3. Граф G(X,W) називається порожнім, якщо W = ∅. 4. Вершини xi та xj графа G(X,W) інцидентні, якщо (xi,xj ) ∈ W. 5. Степенем d( xi ) вершини xi графа G(X,W) називається число вершин xj ,які інцидентні вершині xi (число відрізків, які виходять з вершини xi ). 6. Якщо d( xi ) =1, то вершина xi називається кінцевою вершиною графа G(X,W). Якщо d( xi ) = 0, то вершина xi називаєтьсяізольованою. Термінологія теорії графів не визначена суворо. Зокрема в монографії Гудман, Хідетніемі, 1981 сказано: "У програмістському світі немає єдиної думки про вибір з двох термінів «граф» або «мережа». Зв’язний граф називається ейлеровим графом, якщо існує замкнений ланцюг, який проходить через кожне ребро. Такий ланцюг називатимемо ейлеровим ланцюгом, або ейлеровим циклом. Граф називається напівейлеровим, якщо існує ланцюг, який проходить через кожне його ребро рівно один раз. Лісом називається граф, який не містить циклів. Зв’язний ліс називається деревом. Плоским графом називається граф, у діаграмі якого лінії, що відповідають ребрам, перетинаються лише в точках, які відповідають вершинам графа. Планарним графом називається граф G, ізоморфний деякому плоскому графу. Останній називається плоскою картою графа G. Внутрішньою гранню плоского зв’язного графа називається скінченна область площини, що обмежена замкненим маршрутом графа і не містить усередині ні вершин, ні ребер графа. Частина площини, яка складається з точок, що не належать жодній внутрішній грані, називається зовнішньою гранню. Множина всіх граней плоского зв’язного графа позначається P. Замкнений маршрут, що обмежує грань, називається межею грані, а довжина цього маршруту – степенем грані. Степінь грані позначається Pr. Максимальним планарним графом називається планарний граф, який при додаванні до нього будь-якого ребра перестає бути планарним. Плоский зв’язний граф, кожна грань якого (включаючи й зовнішню) обмежена трикутником, називається триангуляцією. |
Последнее изменение этой страницы: 2019-04-19; Просмотров: 790; Нарушение авторского права страницы
 Студент повинен
Студент повинен  Питання для самоконтролю
Питання для самоконтролю Література
Література Методичні рекомендації
Методичні рекомендації Студент повинен
Студент повинен  Питання для самоконтролю
Питання для самоконтролю Література
Література Методичні рекомендації
Методичні рекомендації Студент повинен
Студент повинен  Питання для самоконтролю
Питання для самоконтролю Література
Література Методичні рекомендації
Методичні рекомендації