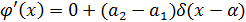|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Модель искусственного нейронаСтр 1 из 4Следующая ⇒
Рассмотрим модель биологической нервной клетки (нейрона), связанную с первыми попытками формализации описания функционирования такого типа клеток. В основе данной модели лежит тот факт, что нервная клетка, принимает сигналы от соседних с помощью специальных отростков, называемых синапсами, при этом каждый из синапсов может либо усиливать, либо ослаблять входящий сигнал. Затем нейрон суммирует полученные сигналы и если получение значение выше некоторого порога, то формируется некоторый выходной сигнал, пересылаемый другим нейронам с помощью специального отростка – аксона. Перейдем теперь к математическому описанию искусственного нейрона, структурная схема которого представлена на рисунке 1.
Рис.1 Схема искусственного нейрона На данном рисунке использованы следующе обозначения:
Таким образом, формула, описывающая функционирование данного нейрона, может быть представлена в следующем виде:
При этом вид функции Функции активации[1-2] Биполярная (пороговая) функция активации исторически первая, применяемая в теории и практике нейронных сетей. Осуществляет преобразование входного сигнала по следующему принципу – если входной сигнал больше некоторого значения
В большинстве случаев принимают Сигмоидальная (логистическая) функция монотонно возрастающая всюду дифференцируемая S-образная нелинейная функция с насыщением. Осуществляет преобразование по схожему принципу, что и биполярная функция, с той лишь разницей, что является непрерывной на всей числовой оси.
Данная функция является достаточно распространённой ввиду непрерывности, а также достаточно легкой интерпретации результата как вероятности принадлежности входного вектора к определенному классу. Изменяя параметр Еще одной S-образной функцией является гиперболический тангенс, также достаточно часто применяемый на практике в качестве функции активации. График и формула данной функции представлены на рисунке 4.
С помощью параметра Наконец еще одной часто используемой функцией активации в искусственных нейронных сетей является так называемая функция «выпрямителя» или ReLU. Нейроны, использующие данную функцию активации, реализуют простой пороговый переход в нуле, подобно однополупериодному выпрямителю в электротехнике.
Ключевым отличием функции ReLU от предыдущих функций активации является отсутствие насыщения, что в определённых случаях позволяет увеличить скорость обучения в насколько раз, по сравнению с сигмоидальной функцией. Как и в предыдущих случаях параметр
Искусственные нейронные сети [2] Рассмотрим простейший вид искусственного нейрона – однослойный персептрон с n входами и единственным выходом. Причем в качестве функции активации применяется биполярная функция, определяемая выражением:
Таким образом, данный персептрон разделяет множество входных сигналов на два класса –
Из вышесказанного следует, что персептрон способен решать задачу классификации входных объектов, однако для корректного решения (то есть правильного разделения объектов по классам) необходима настройка синаптических весов Поэтому было предложено объединять одиночные нейроны в сети, при этом выходные сигналы одних нейронов являются входными сигналами для других. Такая модель носит название многослойного персептрона или нейронной сети. Обобщённая структурная схема нейронной сети представлена на рисунке 6. Рис. 6 Многослойный персептрон На данной схеме видно, что каждый из компонентов входного вектора поступает на каждый из нейронов входного слоя, после чего выходные сигналы данного слоя воспринимаются нейронами скрытых слоев как входные. В результате формируется m выходных сигналов, на основании которых принимается решение о принадлежности входного вектора к определенному классу. Такой подход позволяет формировать границы между классами достаточно произвольной формы, что и обуславливает широкое применение данного типа сетей в настоящее время. Обучение нейронных сетей[1] Процесс определения синаптических весов при решении определенной задачи называется обучением. Заметим, что при построении нейронной сети, начальные синаптические веса обычно назначают случайным образом. Различают два основных способа обучения – обучение с учителем и без него. Обучение с учителем возможно только тогда, когда исследователь имеет в своем распоряжении некоторый набор входных векторов Рассмотрим наиболее распространённый способ определения синаптических весов, называемый алгоритм обратного распространения ошибки, относящийся к методам обучения с учителем. Для более наглядного объяснения принципа данного алгоритма, рассмотрим нейронную сеть, состоящую из двух слоев – входного и одного скрытого. При этом каждый из нейронов имеет сигмоидальную активационную функцию и нулевое смещение (см. формулу 1). Структура такой сети показана на рисунке 7. Рис. 7 Двухслойная нейронная сеть На данном рисунке использованы следующие обозначения:
Пусть в обучающей выборке
Понятно, что чем меньше полученное отклонение, тем лучше работает нейронная сеть. Поэтому задача процесса обучения – это минимизация отклонения
В соответствии, с формулой (1) выходной сигнал
Предварительно выразим производную сигмоидальной функции, которая используется в данном примере в качестве активационной, через неё саму:
Вычислим теперь частную производную выходного сигнала
Подставив данное выражение в формулу 2 окончательно получим:
Изменим теперь синаптические веса нейронов скрытого слоя как:
Здесь k – номер итерации, 0< h< 1 – множитель задающий скорость изменения весов. Осуществив аналогичные выкладки для весов входного слоя получим следующее выражение (пример для веса
Предлагаем читателям самостоятельно убедиться в достоверности представленного выражения. Синаптические веса нейронов скрытого слоя изменятся также как в формуле (4):
То есть, изменяя веса нейронной сети в соответствии с формулами (4) и (5), значения выходных переменных будут приближаться к эталонным. Отметим, что сначала происходит изменение весов скрытого слоя, а затем входного, то есть против хода сигнала при обычном функционировании сети, поэтому данный метод обучения и называется алгоритмом обратного распространения ошибки. Данный алгоритм может быть представлен с помощью следующей блок-схемы (рис. 8): Рис. 8 Блок-схема алгоритма обратного распространения ошибки После окончания процесса обучения происходит проверка правильности настройки синаптических весов с помощью векторов из тестовой выборки. Одной из проблем возникающей при таком алгоритме – это выбор стратегии обучения, которая во многом зависит от конкретной задачи. Например, в какой последовательности брать вектора из обучающей выборки, подавать ли их повторно и т.п. Также существенное влияние на успех обучения оказывает объем и состав обучающей выборки. Таким образом, в результате корректного обучения нейронной сети можно весьма успешно решать задачи классификации входных векторов, используя самое главное свойств искусственных нейронных сетей – способность к обобщению. Некоторые замечания[3-4] Ввиду многообразия применяемых на практике активационных функций, а также широкого использования градиентных методов для обучения искусственных нейронных сетей, представляется целесообразным расширить понятие дифференцирования на класс разрывных функций. Функции, называемые обобщёнными, определяются с помощью выражений вида:
где Для такого рода функций определены все математические операции, что и для обычных функций, однако они имеют некоторые особенности. Так, интересующая нас операция дифференцирования определяется как [3]:
где Напомним здесь, что дельта-функция определяемая как:
тоже, в свою очередь относиться к классу обобщённых. Однако, данная функция обладает следующим свойством:
где Таким образом, для биполярной функции, которая относится к классу обобщённых, производная будет определяться как:
Или с учетом замены дельта-функции получим:
|
|||||||||||||||||||||||||||||||||||
Последнее изменение этой страницы: 2019-10-24; Просмотров: 192; Нарушение авторского права страницы
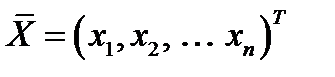 – вектор входных сигналов;
– вектор входных сигналов;  – значения синаптических весов;
– значения синаптических весов;  – количество входов нейрона;
– количество входов нейрона;  – смещение;
– смещение;  – выходной сигнал нейрона;
– выходной сигнал нейрона;  – функция активации.
– функция активации.
 может быть достаточно разнообразным и выбор конкретного выражения во многом зависит от типа решаемой задачи. Рассмотрим основные типы функции активации, применяемые в теории и практике нейронных сетей.
может быть достаточно разнообразным и выбор конкретного выражения во многом зависит от типа решаемой задачи. Рассмотрим основные типы функции активации, применяемые в теории и практике нейронных сетей. , то значение функции равно некоторому числу
, то значение функции равно некоторому числу 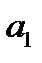 , в противном случае
, в противном случае  . Математическая запись и график данной функции представлен ниже:
. Математическая запись и график данной функции представлен ниже: 
 , а границы
, а границы  , что может затруднить выполнение такой математической операции, как дифференцирование.
, что может затруднить выполнение такой математической операции, как дифференцирование.

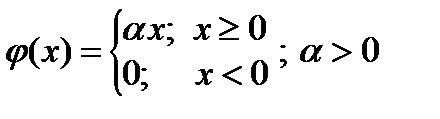
 ).
).
 и
и  ; если сигнал
; если сигнал  , то соответствующий вектор
, то соответствующий вектор  относится к классу
относится к классу 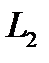 , если
, если  . То есть можно сказать, что в этом случае происходит разделение n-мерного пространства входных векторов на два подпространства, причем границей будет являться (n-1)-мерная гиперплоскость, задаваемая уравнением:
. То есть можно сказать, что в этом случае происходит разделение n-мерного пространства входных векторов на два подпространства, причем границей будет являться (n-1)-мерная гиперплоскость, задаваемая уравнением: 
 . Однако, число практических задач, в которых можно разделить пространство входных векторов на классы с помощью плоскости весьма ограничено и, следовательно, они не могут быть решены таким способом.
. Однако, число практических задач, в которых можно разделить пространство входных векторов на классы с помощью плоскости весьма ограничено и, следовательно, они не могут быть решены таким способом.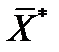 для которых заранее известно к какому из классов они принадлежат или иными словами – для каждого вектора данного набора известен выходной вектор
для которых заранее известно к какому из классов они принадлежат или иными словами – для каждого вектора данного набора известен выходной вектор  . Набор входных векторов
. Набор входных векторов  – входные переменные;
– входные переменные;  – нейроны входного слоя;
– нейроны входного слоя;  – нейроны скрытого слоя;
– нейроны скрытого слоя;  – матрица синаптических весов нейронов входного слоя;
– матрица синаптических весов нейронов входного слоя;  – выходные переменные нейронов входного слоя;
– выходные переменные нейронов входного слоя;  – матрица синаптических весов нейронов скрытого слоя;
– матрица синаптических весов нейронов скрытого слоя;  – выходные переменные.
– выходные переменные. , которому должен соответствовать эталонный набор
, которому должен соответствовать эталонный набор  . Так как при инициализации нейронной сети обе матрицы весов были заданы случайно, то после подачи набора
. Так как при инициализации нейронной сети обе матрицы весов были заданы случайно, то после подачи набора  . Определим меру отклонения полученных значений от эталонного набора следующим образом:
. Определим меру отклонения полученных значений от эталонного набора следующим образом:  .
. для каждого из векторов, входящих в обучающую выборку. Так как параметрами, которые можно изменять, в данном являются синаптические веса, то очевидно, что отклонение
для каждого из векторов, входящих в обучающую выборку. Так как параметрами, которые можно изменять, в данном являются синаптические веса, то очевидно, что отклонение  и
и  . Таким образом, для минимизации
. Таким образом, для минимизации  :
: 
 будет определятся как:
будет определятся как:  ;
; 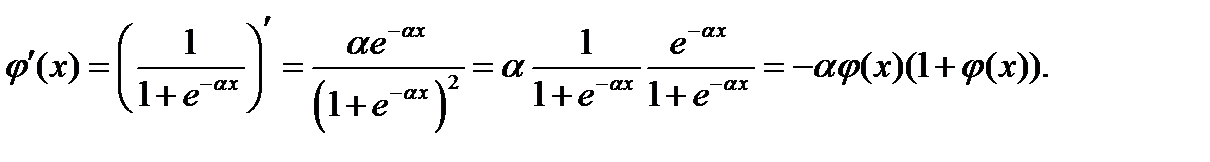



 ):
): 


 некоторые гладкие функции,
некоторые гладкие функции,  – произвольные значения. Строго говоря, такое определение не совсем соответствует академическому понятию обобщённой функции, но оно достаточно полно передает характеристики такого рода функций; для расширения знаний по теории обобщенных функций читатель может обратиться к специализированной литературе [3-4].
– произвольные значения. Строго говоря, такое определение не совсем соответствует академическому понятию обобщённой функции, но оно достаточно полно передает характеристики такого рода функций; для расширения знаний по теории обобщенных функций читатель может обратиться к специализированной литературе [3-4].
 – производная, определяемая обычным способом,
– производная, определяемая обычным способом, 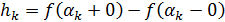 – величина скачка в точке
– величина скачка в точке  ,
,  – дельта-функция смещенная в точку
– дельта-функция смещенная в точку 
 , что позволяет с достаточной для практики точностью заменить её при моделировании следующим выражением [4]:
, что позволяет с достаточной для практики точностью заменить её при моделировании следующим выражением [4]: 
 означает степень приближения.
означает степень приближения.