
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Загрузка данных для обучения ⇐ ПредыдущаяСтр 4 из 4
Как известно из первой лабораторной работы для обучения сети необходимо иметь некоторый набор размеченных данных, называемый обучающей выборкой или dataset, которая состоит из двух массивов – собственно выходные данные, обычно обозначаемые как X и выходные данные или метки, обозначаемые как Y. Данная выборка, и соответственно каждый из массивов X и Y, разделяется две на 2 части: тренировочная и проверочная части. Библиотека Keras работает с массивами в формате Numpy, поэтому все данные используемые для обучения и проверки построенной модели должны пройти предварительную обработку. Данный процесс называется препроцессингом. Отметим здесь также, что библиотека Keras уже содержит готовые наборы данных, которые можно использовать для тестирования построенной модели. Например, обучающая выборка Fashion-MNIST, содержит 60000 изображений предметов одежды, разделенные на 10 классов. Для формирования тренировочных и проверочных массивов необходимо записать следующий код: fashion_mnist = keras.datasets.fashion_mnist (X_train_images, Y_train_labels), (X_test_images, Y_test_labels) = fashion_mnist.load_data() X_train_images.shape X_train_images = X_train_images / 255.0 X_test_images = X_test_images / 255.0 Последние две строки необходимы для того, чтобы значения в массивах X_train_images и X_test_images принадлежали интервалу [0; 1]. Отметим, что в документации Keras есть достаточно большое количество примеров с использованием встроенных выборок, которые могут быть рекомендованы для самостоятельного изучения. При использовании сторонних данных можно воспользоваться специальными методами препроцессинга библиотеки Keras. Продемонстрируем использование данного метода на примере загрузки изображений. Для начала необходимо организовать структуру каталогов, где корневым каталогом будет data, а подкаталоги будут обучающая и проверочная части, train и test соответственно. Далее внутри каждого из подкаталогов создаются еще каталоги с названиями классов, естественно, что количество дочерних каталогов в train и test должно быть одинаково. И, наконец, в дочерних каталогах размещаются изображения. Далее необходимо создать экземпляр класса ImageDataGenerator и взывать метод flow_from_directory для каталогов train и test.Указанный метод формирует из изображений, размещенных в директориях соответствующие массивы (строго говоря, данные объекты являются не массивами, а специальными объектами типа DirectoryIterator) пригодные для обучения созданной нейронной сети. Код для формирования, обучающего и тренировочного массивов: datagen = ImageDataGenerator() train_it = datagen.flow_from_directory( 'data/train/', class_mode='binary', batch_size=64) test_it = datagen.flow_from_directory( 'data/test/', class_mode='binary', batch_size=64) Созданные объекты train_it и test_it будут содержать как данные подаваемые на вход сети, так и соответствующие им метки классов. Отметим здесь, что метод flow_from_directory имеет четыре основных параметра: · d irectory – путь до целевой директории; · target_size – размеры до, которых будут подогнаны найденные все изображения, по умолчанию (256, 256); · class_mode – определяет тип меток, имеет значения ‘categorical’, ' binary' и ‘input’; · batch_size – размер «пачки», определяет какое количество изображений будет извлекаться из созданного массива для обучения или проверки нейронной сети. Аналогично классу ImageDataGenerator в Keras реализованы классы TextPreprocessing и TimeseriesGenerator для препроцессинга текстовых данных и временных рядов, соответственно. Обучение модели [1, 2] После формирования обучающей выборки необходимо обучить созданную нейронную сеть, то есть произвести изменение синоптических весов в сети с помощью указанных в методе c ompilation параметров. Для обучения модели на данных из встроенных наборов, в также в тех случаях, когда обучающая выборка сформирована непосредственно в коде программы применяется метод fit, который может быть достаточно гибко настроен. Однако обязательными являются следующие параметры: · x – массив типа Numpy, содержащий данные подаваемые на вход сети; · y – массив типа Numpy, содержащий метки классов для массива x; · batch_size – размер «пачки», количество примеров из x выбираемых для обновления значения градиента; · epochs – число эпох для обучения модели, одна эпох продолжается до тех пор, пока все примеры из x и y не будут использованы для обучения. Для обучения модели используется следующий код: model.fit(X_train_images, Y_train_labels, epochs=10, batch_size=32) При использовании методов препроцессинга для обучения модели служит метод fit_generator, в целом схожий с методом fit. Основными параметрами fit_generator ялвляются: · generator – объект типа DirectoryIterator, содержащий данные для обучения; · steps_per_epoch – количество «пачек» извлекаемых из генератора за одну эпоху, обычно равно частному от деления общего количества примеров на размер «пачки»; · epochs – число эпох для обучения модели. При обучении, в данном случае используется следующий код: model.fit_generator(train_it, steps_per_epoch=16, epochs=10) Оба метода fit и fit _ generator, возвращают объект типа History, содержащий историю изменений функции потерь и метрики за время обучения. Данные массивы могут быть изображены в виде графиков с помощью стандартных методов визуализации языка Python. Наконец, для проверки правильности обучения служит метод test_on_batch, который возвращает массив значений функции потерь для тестовой выборки. Методы predict и predict _ generator возвращают предсказанное значение класса, к которому принадлежат поданные на вход сети данные. Дополнительные техники улучшения процесса обучения (нормализация, регуляризация, дропаут) [1, 2] При обучении созданной нейронной сети достаточно часто разработчики сталкиваются с таким явлением как переобучение. Данное явление выражается как неработоспособность сети на тестовом наборе данных, при этом значение функции потерь является достаточно маленьким (то есть процесс обучения завершен). Одними из основных причин переобучения являются следующие явления: 1. Появление в процессе обучения весов с абсолютными значениями, на порядок большими чем остальные. 2. Чрезмерная совместная адаптация нейронов в процессе обучения, то есть веса нейронов скрытых слоев начинают подстраиваться не под входные данные, а под выходы нейронов вышележащих слоев, что в конечном итоге приводит к их невосприимчивости к тестовым данным. 3. Искажение входного вектора по мере прохождения через нейронную сеть в плане статистических оценок (по математическому ожиданию и дисперсии). Для борьбы с каждым из перечисленных негативных явлений в библиотеке Keras разработаны и реализованы соответствующие методы. Так одним из очевидных способов ограничения абсолютного значения весов является включение дополнительного слагаемого, зависшего от значения весов, (штрафа) в функцию потерь. Данная техника называется регуляризацией. В большинстве случаев штрафом является
где При применении библиотеки Keras регуляризация применяется к каждому из слоев отдельно и указывается при создании слоя: model.add(Conv2D(128, (3, 3), padding=" same" ), kernel_regularizer= regularizers.l2(0.01)) Одним из способов предотвращения совместной адаптации нейронов является выключение определенного процента нейронов сети в процессе обучения (также называемый дропаут). Такой подход исключает из процесса обучения часть нейронов, выбираемых случайно, на каждой итерации обучения, что позволяет «искусственно» выделить блоки, каждый их которых будет отвечать за свой специфический набор признаков. В библиотеке Keras реализован специальный слой типа Dropout, ключевым параметром которого является rate, определяющий долю выключаемых нейронов в предыдущем слое. То есть данный слой случайным образом обнуляет выходы некоторых нейронов. model_dropout.add(Dense(128)) model_dropout.add(Activation('relu')) model_dropout.add(Dropout(0.4)) В данном случае, 40% случайных выходов полносвязного слоя типа Dense, с активационной функцией ReLu будет обнулено. Наконец, для нормализации сигнала применяется специальный тип слоя BatchNormalization. Так, при достаточно большом количестве слоев возникает такое явление, как внутренний ковариационный сдвиг, проявляющееся в том, что веса, изменяемые в процессе обучения, влияют на выходной сигнал нейронов и на его распределение (если считать выходной сигнал случайной величиной). Смещение основных статистических характеристик выходных сигналов промежуточных слоев нейронной сети существенно замедляет скорость обучения ввиду того, что необходимо адаптироваться не только под характеристики входных данных, но и учитывать возникающее смещение. В библиотеке Keras реализована пакетная нормализация, которая преобразует данные «пачки» batch так, чтобы математическое стремилось к нулю, а дисперсия к единице. Реализуется данный подход с помощью добавления в модель дополнительного слоя типа BatchNormalization model_dropout.add(BatchNormalization()) |
Последнее изменение этой страницы: 2019-10-24; Просмотров: 219; Нарушение авторского права страницы
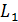 -норма или
-норма или 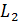 -норма матрицы весов нейронной сети. Например, при использовании
-норма матрицы весов нейронной сети. Например, при использовании 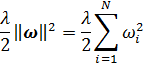
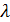 – коэффициент регуляризации,
– коэффициент регуляризации, 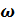 – матрица весов,
– матрица весов, 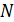 – количество нейронов в сети. При использовании
– количество нейронов в сети. При использовании