|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Информационно-поисковые системы и языкиСтр 1 из 14Следующая ⇒
Информационные системы Для Работы с документами
Учебное пособие Киров 2018 УДК 004(07) Л хх Рекомендовано к изданию методическим советом факультета автоматики и вычислительной техники ФГБОУ ВО «Вятский государственный университет»
Допущено редакционно-издательской комиссией методического совета ФГБОУ ВО «Вятский государственный университет» в качестве учебного пособия для студентов направления 09.03.02 «Информационные системы и технологии», а также других направлений факультета автоматики и вычислительной техники.
УДК 004(07) Рассматриваются принципы построения и способы реализации различных информационно-поисковых систем и систем автоматизации электронного документооборота
© ФГБОУ ВО «Вятский государственный университет», 2018
СОДЕРЖАНИЕ Введение. 6 1. Информационно-поисковые системы и языки. 7 1.1. Основные понятия. 7 1.2. Основные информационно-поисковые режимы.. 8 1.3. Основные типы ИПС.. 9 1.4. Основные характеристики и параметры ИПС.. 11 1.5. Схема функционирования ИПС.. 15 1.6. Понятие критерия смыслового соответствия. 16 1.6.1. Булева модель поиска. 16 1.6.2. Алгоритм расширенного булева поиска. 19 1.6.3. Алгоритм наибольшего цитирования. 20 1.6.4. Векторный алгоритм поиска. 20 1.6.5. Расширенный векторный алгоритм поиска. 22 1.7. Информационно-поисковые языки. 22 2. ИПС на тезаурусе. Классификация и рубрицирование. 27 2.1. Общие понятия. 27 2.2. Формальное определение тезауруса. 27 2.3. Классификация документов. 28 2.4. Формирование рубрик. 33 2.5. Автоматическое рубрицирование. 35 2.5.1. Методы автоматического рубрицирования. 35 2.5.2. Рубрицирование, основанное на обучении по примерам. 37 3. Функциональные разновидности современных ИПС.. 40 3.1. Словарные информационно-поисковые системы.. 40 3.2. Классификационные информационно-поисковые системы.. 44 3.3. Метапоисковые системы.. 47 4. Обзор современных информационно-поисковых систем. 51 4.1. Поисковая система Google. 51 4.1.1. Структура Google. 51 4.1.2. Концепция PageRank. 51 4.1.3. Поисковые запросы Google. 53 4.1.4. Базовые возможности Google. 54 4.1.5. Сервисы Google. 54 4.1.6. Инструменты Google. 59 4.1.7. Аппаратное обеспечение Google. 60 4.1.8. Будущеее Google. 60 4.2. Поисковая система Яндекс. 62 4.2.1. Структура Яндекса. 62 4.2.2. Алгоритмы Яндекса. 63 4.2.3. Роботы Яндекса. 65 4.2.4. Показатели внешней оптимизации Яндекса. 66 4.3. Автоматизированные библиотечные ИПС.. 71 4.3.1. АБИС «Руслан». 71 4.3.2. АБИС Greenstone. 71 4.3.3. ИРБИС.. 72 5. Системы управления электронными документами. 73 5.1. Общие положения. 73 5.2. Жизненный цикл документа. 77 5.3. Статические архивы.. 78 5.3.1. Задачи статических архивов. 78 5.3.2. Трансформация бумажных документов в электронную форму. 80 5.3.3. Компоненты статического электронного архива. 80 5.3.4. Индексирование и поиск документов. 81 5.3.5. Технологические принципы построения электронного архива. 82 5.3.6. Сканеры потокового ввода. 83 5.4. Динамические архивы.. 84 5.4.1. Задачи динамических архивов. 84 5.4.2. Маршрутизация и контроль исполнения. 85 5.4.3. Свободная маршрутизация документов с контролем исполнения. 85 5.4.4. Жесткая маршрутизация. 85 5.4.5. Регистро-ориентированные системы управления документооборотом. 86 6. Обзор основных систем документооборота. 88 6.1. Docs Fusion и Docs Open. 88 6.2. Documentum.. 89 6.3. LanDocs. 91 6.4. Microsoft SharePoint Portal Server 92 6.5. Optima Workflow.. 93 6.6. «БОСС-Референт». 94 6.7. «Дело». 95 6.8. «Евфрат». 96 6.9. Другие системы.. 97 7. Система управления документооборотом на базе Lotus Notes. 99 8. Системы документооборота на базе MS Exchange + MS Outlook. 106 8.1. Общие положения. 106 8.2. Microsoft Outlook. 107 8.3. Microsoft Exchange Server 108 8.4. Согласование документов в MS Outlook. Практические действия. 112 Библиографический список. 116
Введение Множество информационных систем офисного назначения можно классифицировать в соответствии с областью их применения, рассматривая при этом каждую разновидность как некоторую предметно- или проблемно-ориентированную систему (банковского бухгалтерского, казначейского и т. п. назначения). В настоящем пособии предлагается классификация информационных систем по функциональному признаку. Поэтому классы информационных систем, рассматриваемые в пособии, можно обозначить как функционально-ориентированные системы (по аналогии с предметно- или проблемно-ориентированными). В качестве основных функций рассматриваются информационный поиск, автоматизация управления документами и документооборотом, аналитическая обработка данных. Соответственно выделяются информационно-поисковые системы, системы управления электронными документами, информационно-аналитические системы. Заведомо не рассматриваются системы преимущественно производственного назначения, например, информационно-управляющие системы. Необходимо отметить, что если рассматривать информационные системы с точки зрения практики их использования, крайне редко можно встретить функционально-ориентированную систему «в чистом виде». В реальных административно-офисных информационных системах поддерживаются и функции поиска, и функции аналитики, и работа с документами. Существуют системы, интегрирующие в себе эти функции. Существует огромное множество примеров работ по интеграции систем различного функционального назначения для решения комплексных задач предприятия, выполняемых ИТ-специалистами. Обособленное рассмотрение функционально-ориентированных систем интересно в первую очередь с точки зрения детального анализа их функций и средств их технической реализации.
Основные понятия Информационно-поисковые системы (ИПС) представляют собой совокупность лингвистических, алгоритмических, программных и технических средств, предназначенных для поиска, хранения и выдачи по запросам информации [9]. Выделение данного класса информационных систем объясняется тем, что: 1. Поиск информации по запросам является их основной функцией. 2. Сложность всей ИС практически сводится: – к сложности используемых алгоритмов поиска; – к сложности реализации предметно-ориентированных языковых средств формирования запросов. 3. Сложность алгоритмов поиска, как правило, объясняется требованием многопользовательского доступа, большими объемами информационного фонда, его распределенностью или территориальной удаленностью, что влечет повышенные требования к производительности. Вообще же, ИПС входят как подсистемы в подавляющее большинство ИС, поскольку наличие информационного фонда ИС предполагает реализацию функций поиска в нем и обработки запросов. Три основных проблемы информационного поиска [9]: 1. Проблема общения связана с необходимостью разработки языковых средств формирования запросов со своими грамматическими правилами и словарями, а также обработчика запросов. Возможна, в частности, двухступенчатая структура средства формирования запросов. Например, при использовании в качестве информационного фонда SQL-сервера разрабатывают: – средство формирования запросов пользователя, максимально приближенное к его предметной области: языковое либо визуальное; – транслятор с языка формирования запросов на SQL. Роль обработчика запросов играет сам сервер. 2. Проблема установления соответствия имеет значение в ИС, где присутствует требование уникальности искомых информационных единиц по критерию смыслового соответствия. В случае неопределенности, неполноты, некорректности формирования запроса возможна неоднозначная выборка данных из информационного фонда. Данная проблема частично решается путем многократной корректировки запросов с учетом критерия смыслового соответствия и характера хранимой информации. 3. Проблема организации возникает в случае большого объема информационного фонда и семантической структурированности или иерархичности предметной области. Оба эти случая влекут необходимость декомпозиции информационного фонда и, как следствие, усложнения алгоритмов доступа к нему. В состав ИПС входят: – технические средства; – информационно-поисковый язык; – программные средства; – БД; – словарь метаданных. Формат информационной единицы ИПС, представленный в терминах информационно-поискового языка, называют предмашинным форматом. Представление информационной единицы в соответствии с предмашинным форматом называется поисковым образом документа (ПОД). При формировании информационного фонда ИПС поисковый образ документа формируется согласно предмашинному формату и вводится в ИПС. При запросе к информационному фонду составляется поисковый образ запроса (ПОЗ) или поисковое предписание (ПП) [9]. Основные типы ИПС Выделяют следующие основные типы ИПС: – документальные ИПС; – фактографические ИПС (информационно-справочные системы – ИСС); – информационно-логические системы. Документальная ИПС предназначена для выдачи документов либо адреса их хранения по данному запросу. В памяти такой системы хранятся либо сами документы, либо их рефераты, либо поисковые образы документов для отсылок [9]. Фактографическая ИПС выдает хранящиеся в памяти факты в соответствии с запросами пользователей. Память фактографической ИПС хранит поисковые образы соответствующих фактических сведений и их номера либо сами фактические сведения. Различия между документальной и фактографической ИПС нагляднее всего описываются при помощи понятия поисковой функции. Поисковой называется функция Р, которая задает параметры поиска [9]:
где G — полнота поиска (характеризует способность ИПС находить все требуемые документы); R — точность (характеризует неспособность ИПС находить нетребуемые документы); п – коэффициент, значения которого для документальной ИПС 0 < п < 1, для фактографической п = 0. Таким образом, для фактографической ИПС P = R, для нее не стоит вопрос о степени полноты обработки запроса, запрос может быть либо выполнен, либо не выполнен. Для документальной ИПС запрос может быть сформулирован так, чтобы поиск производился, например, по рефератам. Полнота такого поиска может быть оценена количественно. Информационно-логическая система хранит как набор данных, так и алгоритмическое и программное обеспечение, позволяющее в ответ на запросы пользователя осуществлять не только поисковые процедуры, но и анализировать имеющиеся сведения, синтезировать новые, не содержащиеся в памяти системы в явной форме [9]. Информационно-логические системы могут применяться при составлении аналитических обзоров, прогнозировании, в научных и проектных работах, требующих делать выводы на основании анализа большого количества фактов. В этом проявляется их сходство с системами поддержки принятия решений. Составные части ИПС называют подсистемами. Разделение на подсистемы необходимо и полезно как в целях разработки, так и для описания технологии функционирования систем. Оно может иметь разную основу. Обычно рассматривают два типа разбиения ИПС на подсистемы: по функциональному принципу (функциональные подсистемы) и по типу средств (обеспечивающие подсистемы). Различные средства, реализующие функции ИПС, получили название обеспечивающих подсистем, или «обеспечений». Выделяют следующие подсистемы: информационное обеспечение, лингвистическое обеспечение, техническое обеспечение, программное обеспечение, технологическое обеспечение, кадровое обеспечение. Информационное обеспечение – это информационные массивы (документы, запросы, метаданные), а также средства и способы их описания, построения и классификации. Лингвистическое обеспечение – это логико-семантический аппарат, состоящий из информационно-поискового языка, правил применения (методик индексирования), критерия выдачи и других языковых средств. Программное обеспечение – это алгоритмы и программные средства, реализующие все функции ИПС, выполняемые с помощью компьютера. Техническое обеспечение – это технические средства (компьютеры, средства телекоммуникаций), обеспечивающие хранение, поиск и передачу информации. Технологическое обеспечение – это набор и порядок выполнения автоматизированных и неавтоматизированных процессов и процедур обработки информации в ИПС, включая их описание, информационно-технологические схемы и инструктивно-методические материалы. Кадровое (или штатное) обеспечение – это люди, взаимодействующие с системой и обеспечивающие ее эксплуатацию (обслуживающий персонал). ИПС также делят на составные части (подсистемы) по функциональному признаку, когда каждая подсистема выполняет определенную функцию в технологическом процессе: ввод документов, индексирование документов, ввод и корректировка запросов, индексирование запросов, поиск, ведение словарей, ведение статистики, обработка результатов поиска, выдача документов и др. Такие части получили название функциональных подсистем. Схема функционирования ИПС Унифицированная схема функционирования ИПС в режимах обработки запроса и ввода документа в информационный фонд системы приведена на рис. 1.2 [9].
Средства реализации критерия смыслового соответствия в ИПС называются логикой поисковой системы , включающей в себя два основных элемента – базисные отношения и правила сравнения. Базисными отношениями называется смысловая связь, существующая между кодируемыми понятиями вне ИПС. Сюда входят обычные отношения между понятиями, в первую очередь отношения структуризации. Правила сравнения есть правила или алгоритм процедуры сопоставления ПОЗ и ПОД. Они называются критерием смыслового соответствия (КСС), или критерием выдачи. Булева модель поиска На практике повсеместное распространение получили ИПС с логическим критерием выдачи, когда ПП строятся с использованием логических (булевых) операторов конъюнкции (& ), дизъюнкции (\/), отрицания (~). В этом случае логическое выражение запроса представляет собой набор поисковых элементов (обычно ключевых слов), объединенных логическими операторами и скобками, необходимыми для указания порядка выполнения операторов. Ключевые слова поискового предписания играют роль булевых пе ременных, принимающих значение 1 («истина»), если данное слово содержится в документе, и 0 («ложь»), когда оно там отсутствует. Документ признается релевантным запросу, если логическая формула запроса в целом получает для данного документа значение «истина», и нерелевантным, если результат вычисления логической формулы дает «ложь». Принятые в логике для обозначения конъюнкции, дизъюнкции и отрицания значки (&, \/, ~) в информационном поиске обычно заменяют на операторы AND, OR и NOT соответственно. В России чаще используются обозначения И, ИЛИ, НЕ. Однако в общем случае в каждой конкретной ИПС обозначения для булевых операторов выбираются свои, причем иногда для удобства пользователя вводится несколько значков для одного и того же оператора (например, в ИПС «Апорт» оператор конъюнкции может быть задан следующими знаками: &, пробел, AND, И, +). Использование булевых операторов обеспечивает логику сравнения документов и запросов, понятную пользователю. Поиск (вычисление истинности для элементов поискового предписания), как правило, проводится по специальным индексным (инвертированным) файлам, построенным на основе словника документального массива, и характеризуется высокой скоростью. ИПС, работающие с булевой моделью поиска, имеют ряд недостатков: 1. Обычные булевы запросы затрудняют варьирование глубины поиска с целью выдачи большего или меньшего количества документов в зависимости от требований пользователя. Для получения желаемого уровня эффективности необходимо найти правильную формулировку запроса: не слишком широкую и не слишком узкую. Оператор AND может привести к резкому сокращению числа найденных документов, а оператор OR, напротив, может чрезмерно расширить запрос и выделить нужную информацию из информационного шума будет трудно. Результат поиска также сильно зависит от того, насколько типичными для базы данных ключевых слов являются термины запроса. Поэтому для успешного применения булевой модели следует хорошо ориентироваться в предметной лексике. Для повышения результативности создаются специальные словари – тезаурусы, которые содержат информацию о связи терминов друг с другом. 2. При использовании булевой логики нельзя получить эффект от функций совпадения векторов, которые дают непрерывный спектр совпадений (полных, частичных или нулевых) между запросами поисковыми образами документов. Это обстоятельство приводит к жесткому требованию «все или ничего» на выходе. 3. Еще одним минусом является тот факт, что множество выданных документов не может быть представлено пользователю в ранжированном виде, например в порядке уменьшения сходства между документом и запросом. Документ либо полностью соответствует запросу, либо не соответствует совсем. Эта проблема может быть решена с помощью взвешенного булева поиска, при котором производится частичное ранжирование с использованием весов терминов. Результаты поиска располагаются в порядке уменьшения весов совпавших терминов. Несмотря на описанные недостатки, булева модель поиска широко применяется в современных ИПС из-за простоты ее реализации. Негативные свойства, характерные для булевого алгоритма поиска, обусловлены употреблением в запросе логических операторов, приводящих к жестким условиям поиска. Одним из решений этой проблемы является отказ от их использования и, как следствие, разработка каких-либо других алгоритмов поиска. Многие современные ИПС реализуют модели поиска информации, основанные на вычислении мер близости документов и запросов. ИПЯ, используемые в таких моделях, называются языками типа «найти похожее». В этих языках необязательно формулировать запросы с помощью булевых операторов. Для вычисления меры подобия документов и запросов существует более тридцати различных алгоритмов. На сегодняшний день используется лишь несколько из них. Мы рассмотрим четыре алгоритма: – расширенного булевого поиска, – наибольшего цитирования, – векторный алгоритм поиска, – расширенный векторный алгоритм поиска. Алгоритмы расширенного булевого поиска и наибольшего цитирования основаны на метаинформации гипертекстовых страниц. Векторный алгоритм использует статистические частотные оценки встречаемости терминов. Расширенный векторный алгоритм работает как с частотными оценками, так и с гипертекстами. Введем некоторые обозначения: – – – – – – – – – Векторный алгоритм поиска Векторный алгоритм поиска является одним из самых распространенных. Он основан на векторной модели информационного массива, в которой для определения меры близости документов и запросов используется значение косинуса угла между их векторами в многомерном пространстве информационного массива. Запросы и документы в векторной модели представляют множествами наборов взвешенных терминов. Вектор запроса в таком случае будет выглядеть так: Функция совпадения векторов запроса и документа имеет вид:
Числитель дроби (1.2) определяет скалярное произведение векторов документа и запроса, знаменатель – произведение их длин, а релевантность
Окончательное выражение для релевантности q и
где
Вычисление длины вектора документа (знаменатель выражения (1.4)) занимает очень много времени. Поэтому часто применяют упрощенный векторный алгоритм:
Практика показывает, что упрощенный алгоритм (1.5) при поиске в Интернете является более эффективным, чем полный алгоритм (1.4). Общие понятия Тезаурус (греч. – клад, сокровищница, запас) – словарь, отражающий смысловые связи между словами и иными смысловыми элементами языка. Тезаурус состоит из: – списка слов и устойчивых словосочетаний, сгруппированных по смысловым рубрикам; – «ключа» алфавитного словаря, где для каждого слова указаны соответствующие рубрики. Тезаурус позволяет определять семантические отношения иерархического и неиерархического (синонимия, антонимия, ассоциация) типов. Информационно-поисковым тезаурусом (ИПТ) называется тезаурус, предназначенный для ИПЯ. ИПТ позволяет: – однозначно переводить текст с ЕЯ на ИПЯ; – находить нужные дескрипторы для адекватного выражения информационной потребности; – обеспечивать возможность избыточного индексирования; – варьировать ПОЗ. Классификация документов Во время поиска часто бывает важно получить по возможности наибольшее значение полноты, то есть выдать максимальную часть релевантных документов, имеющихся в массиве. Исчерпывающий поиск может понадобиться, например, экспертам организации, регистрирующей изобретения, которым необходимо составить обзор всех существующих патентов. Увеличение числа релевантных документов обычно приводит к выдаче дополнительных нерелевантных документов, то есть снижается его точность. Для улучшения полноты поиска необходимы дополнительные совпадения терминов запроса и документа. Это достигается использованием дополнительных терминов-заместителей. Термины-заместители либо добавляются к уже существующим терминам запросов и документов, либо используются вместо них. Наиболее известным методом здесь является применение словаря синонимов (тезауруса), в котором термины сгруппированы в классы синонимии (классы эквивалентности). С помощью тезауруса можно заменить каждый имеющийся в начальный момент поиска термин идентификаторами соответствующих классов тезауруса. При использовании другого подхода идентификаторы этих классов можно добавлять к исходным терминам. В любом случае цель состоит в том, чтобы получить дополнительные совпадения для тех терминов запроса и документа, которые отнесены к одним и тем же классам тезауруса. Сами эти термины могут быть и различными. В ИПС в основном применяется два типа классификаций: терминов и документов. Целью классификации терминов является группировка терминов в синонимические классы в расчете повысить вероятность совпадения терминов запроса и документа. Классификация документов способна улучшить результаты и оперативность поиска за счет обращения только к определенным частям информационного массива. Эти два типа классификаций взаимосвязаны: присваиваемые документам термины при формировании их поисковых образов служат основой для построения классов, получаемых в результате группировки документов. При хорошей классификации терминов обычно удается сгруппировать различные низкочастотные родственные термины в общие классы тезауруса. Термины, входящие в один класс, могут заменять друг друга в процессе поиска, следовательно, можно ожидать улучшения полноты выдачи. Классификации документов позволяют сузить область поиска до наиболее существенных классов документов и обеспечить высокую точность. При совместном использовании систематизированных массивов данных и тщательно проработанного тезауруса можно получить высокие показатели и по полноте, и по точности поиска. В основе любой классификации лежит принцип распределения информационных объектов (терминов или документов) по некоторым классам. Совокупность таких классов называется классификатором, а сами классы – разделами классификатора, или рубриками. Классификаторы обычно разрабатываются вручную. Примерами классификаций могут служить общепринятые библиотечные классификации УДК (универсальная десятичная классификация) и ББК (библиотечно-библиографическая классификация). Класс определяется как множество терминов, обозначающих некоторую предметную область. В процессе классификации каждому информационному объекту для обозначения его смыслового содержания (тематики) приписывается идентификатор какого-либо класса. Разбиение на предметные классы или рубрики должно быть предсказуемым, а подчиненные тематические классы легко отличимым от вышестоящих. От четкости такой иерархической структуры зависит эффективность регулирования глубины поиска путем расширения или сужения запроса. Маловероятно, чтобы можно было найти такую структуру, которая могла бы удовлетворять этим требованиям. Строго заданные иерархические отношения между тематическими классами призваны подчеркнуть определенные типы предметных ассоциаций и одновременно пренебречь другими. Статичный характер общепринятых классификационных схем порождает проблемы в случае расширение предметных областей и развития знаний. Существующие иерархические схемы весьма сложны, и на практике часто оказываются обязательными ручные (неавтоматические) процессы классификации. Это приводит к тому, что согласованности между разными системами классификации и поиска в процессах анализа содержания и распределения документов по рубрикам добиться трудно. В ИПС процесс классификации документов происходит во время их индексирования. Термины запроса распределяются по рубрикам классификатора непосредственно во время поиска. В обоих случаях документы и термины составляют множество классифицируемых объектов. Если множество объектов необходимо сопоставить множеству классов, обычно требуется, чтобы получающаяся при этом классификация обладала следующими свойствами: 1. Классификация должна быть корректно определенной так, чтобы для любого заданного множества данных получался один результат. 2. Результаты классификации не должны зависеть от порядка обработки объектов (независимость от порядка), то есть любая перестановка анализируемых объектов не должна влиять на результат классификации. 3. Классификация должна быть устойчивой: незначительные изменения данных должны вызывать незначительные изменения результатов классификации. 4. Классификация должна быть независимой от масштаба, поскольку умножение на константу значений характеристик, идентифицирующих объекты (идентификаторов классов), не должно влиять на классификацию. 5. Объекты, обладающие большим сходством, не должны оказываться отнесенными к разным классам. Первые два свойства (корректность определения и независимость от порядка) взаимосвязаны. Они могут быть обеспечены только при условии предварительного анализа всех возможных подмножеств объектов, удовлетворяющих классификационным критериям. Однако при большом количестве объектов, подлежащих классифицированию, такой исчерпывающий анализ может потребовать значительных затрат времени, что имеет место, например, в сети Интернет. Если первый и второй критерии не удовлетворяются, то особую важность приобретает критерий устойчивости классификации. Он гарантирует, что добавление новых свойств объектов, устранение уже выделенных свойств, а также исправление незначительных ошибок вызовут лишь незначительные изменения в самих классах. В классификациях, используемых в ИПС, обычно стараются получать устойчивые классы терминов и документов особенно потому, что векторы свойств, характеризующие объекты, не всегда точны и надежны. Это связано, например, с тем, что некоторые термины, несущие важную смысловую нагрузку, могут игнорироваться при автоматическом анализе содержания документов. Системы классификации имеют также ряд формальных свойств. Если все члены одного и того же класса обладают одним общим признаком, то классификация называется монотетической. В противном случае классификация становится политетической. Классы могут быть непересекающимися, где объекты относятся самое большее к одному классу, и пересекающимися. Наконец, классификация может быть упорядоченной путем установления систематических отношений между различными классами, а может быть и неупорядоченной. В процессе разработки и проектирования систем классификации во всех случаях предпочтительнее менее жесткие требования. Обычно ни документы, ни термины не бывают определены настолько точно, чтобы имело смысл строить монотетические классификации терминов или документов. По этой же причине наилучшими классами должны считаться пересекающиеся классы, чтобы элемент (термин или документ) мог включаться более чем в один класс. В некоторых случаях целесообразно создание либо упорядоченных классификаций терминов (иерархий терминов), либо упорядоченных классов документов. Однако, когда не налагается никаких специальных требований, неупорядоченная классификация, как правило, дает более адекватное деление на классы. Таким образом, в общем случае наиболее предпочтительными являются политетические пересекающиеся неупорядоченные классификации. В любой ИПС существует тесная взаимосвязь между индексированием и классификацией. Часто два этих процесса осуществляются параллельно. Целью классификации терминов является формирование для каждого термина дополнительных заместителей. Эти же термины используются и для идентификации документов. Представление и классификация документов в ИПС также связаны между собой. При индексации каждому документу обычно сопоставляется некоторый набор индексационных терминов. Поэтому фактически используемые термины непосредственно оказывают влияние как на классификацию терминов, так и на классификацию документов. Например, во время автоматической классификации документов определяется мера близости между классифицируемым документом и некоторым эталонным документом, который заведомо принадлежит какому-либо определенному классу. Эта мера часто вычисляется в зависимости от терминов, входящих в векторы этих документов. Поэтому классы документов непосредственно зависят от методов индексирования. Формирование рубрик Типичный процесс формирования рубрик (классов) включает три основных процесса (рис. 2.1).
Во время начального процесса происходит определение рубрик. Часто эта операция сводится к выбору (в качестве центра исходных классов) объектов, размещенных в плотных зонах пространства информационных объектов. Такими зонами обычно считаются те, в окрестностях которых имеется большое количество подобных объектов. В процессе распределения информационные объекты систематизируются и распределяются по имеющимся рубрикам путем отнесения объектов к тем классам, с которыми они имеют достаточно высокий коэффициент подобия. Завершающий этап связан с выполнением условий, при которых данный класс считается окончательным и полным. Здесь устанавливается, удовлетворяют ли сформированные рубрики заданному критерию классификации (например, обладают ли они описанными в предыдущем параграфе свойствами). Существует два основных метода классификации: 1. Порождающие методы классификации по принципу снизу вверх. 2. Методы разбиения по принципу сверху вниз. При использовании порождающих методов все объекты первоначально считаются несгруппированными. Формирование групп выполняется снизу вверх путем объединения объектов. Методы разбиения по принципу сверху вниз подразумевают, что все объекты первоначально относятся к одному глобальному классу. Затем этот класс разбивается на более мелкие подклассы, которые в свою очередь могут делиться на еще более мелкие подклассы вплоть до образования окончательных классов. В действующих системах также используется смешанный метод классифицирования по принципу сверху вниз. Количество исходных классов в таком случае задается заранее, и первоначальное деление объектов корректируется путем перегруппировки объектов. Целью перегруппировки является повышение качества рубрик таким образом, чтобы связанность классов стала максимальной, а подобие объектов, относящихся к разным группам, – минимальным. Большая часть методов классификации по принципу сверху вниз устроена таким образом, что они могут использоваться и для образования иерархических структур классов. При поуровневом построении классификации формируются классы, являющиеся подмножествами или компонентами какого-либо класса более высокого уровня. В результате образуется структура в виде дерева. Корень такого дерева (верхний уровень) содержит глобальный класс высшего уровня, представляющий все информационное пространство. Листья (нижний уровень) соответствуют конечным рубрикам документов или группам терминов. При некоторых методах классификации по принципу снизу вверх также формируются иерархические структуры. Неиерархическими структурами считаются такие структуры, в которых между сформированными классами не выполняются свойства формального включения. При построении иерархии классов терминов в виде дерева часто стараются в нижней части помещать узкие специфичные термины, а в верхней – термины более общего характера. На практике особенно во время ручной классификации часты случаи, когда документ или термин может быть одновременно отнесен к нескольким классам. В таких ситуациях используются различные перекрестные ссылки. Информация о документах данной тематической направленности помещается в некоторый базовый раздел, а остальные классы, к которым также можно было бы отнести эти документы, содержат соответствующие ссылки. В описание пересекающихся классов добавляют ссылку типа «смотри», которая направляет пользователя к рубрике, признанной специалистами по классификации базовой. Например, информация о картах стран может быть размещена в разделах «Наука–География–Страна», «Экономика–География–Страна» или «Справочники–Карты–Страна». Специалисты по классификации принимают решение о том, что сведения о картах стран размещаются в рубрике «Экономика–География–Страна». Тогда в остальные два раздела добавляется ссылка на данный. Если выбор базового класса вызывает у специалистов по классификации затруднения, то вероятность отнесения объекта к тому или иному похожему (синонимическому) классу практически одинакова. В этих случаях применяются ссылки типа «смотри также». Они направляют пользователей системы к разделам, которые, возможно, содержат описания интересующих их документов. Модель семантической сети Строится тезаурус в виде сети понятий и отношений между ними Основные этапы полуавтоматического синтеза тезауруса: 1. Автоматическая обработка большого объема документов при помощи программ морфологического и синтаксического анализа с целью выделения терминоподобных групп слов. 2. Исследование выделенных групп экспертами и принятие решений: – о включении группы в тезаурус (группа в этом случае приобретает статус термина); – о наличии синонимии для данного термина; – о наличии прочих отношений для данного термина. Кроме тезауруса, в информационный фонд системы рубрицирования могут включаться БД объектов предметной области (например, географическая, предприятий, организаций, персоналий и т. д.). Обобщающее отношение K позволяет организовать тезаурус в виде иерархической структуры. Процесс рубрицирования состоит в выделении из документа опорных дескрипторов и отношений между ними с последующим сопоставлением их с описаниями рубрик [5]. Продукционная модель Рубрицирование с использованием продукционной модели выполняется в соответствии со схемой, приведенной на рис. 2.2 [5]. БЗ представляет собой набор правил, определяющих понятия. В определение понятия входит набор слов и фраз, объединенных логическими отношениями, а также могут входить:
– отношения следования, совместности между словами; – веса и статистические характеристики слов. Этапы процесса рубрицирования: – выделение понятий из текста. – принятие решения о принадлежности текста к рубрике. Недостатки рубрицирования, основанного на знаниях, аналогичны недостаткам специализированных ЭС [5]: – трудоемкость синтеза тезауруса; – неуниверсальность тезауруса. 2.5.2. Рубрицирование, основанное на обучении по примерам Эти методы основаны на обработке обучающих выборок, состоящих из документов, для которых указывается принадлежность к рубрикам. Методы этой группы делятся на статистические и нейросетевые. Статистические методы. Здесь используются понятия терминологического портрета рубрики и документа. В терминологический портрет входят термины и их веса. Процесс обучения (формирования портретов рубрик) сводится к составлению экспертом выборок для каждой рубрики. Основные критерии формирования выборки: минимизация размеров текстов, максимальная лингвистическая полнота, минимальная избыточность. Выделение терминов производится автоматически. При этом формируется матрица их весов wtr, где t – термин, r – рубрика. Рубрицирование документа выполняется по некоторому решающему правилу, например, такому [5]: Вектор порогов рубрик (kr) также формируется при обучении путем применения решающего правила к обучающей выборке и оценки результата с точки зрения критериев точности и полноты. При этом могут использоваться как математические методы, так и эмпирика. Достоинствами статистических методов являются универсальность, наличие аппарата количественной оценки релевантности документов рубрикам, высокое быстродействие. Недостатком является невысокое качество рубрицирования, по сравнению с методами, основанными на знаниях [5]. Нейросетевые методы. Как очевидно следует из названия, методы этой группы основаны на использовании нейронных сетей (НС), принципы функционирования которых подлежат рассмотрению в рамках отдельных дисциплин. Обучение нейросетевой системы проиллюстрировано рис. 2.3 [5].
Определение вероятности релевантности текста рубрике выполняется в соответствии с рис. 2.4.
Основным недостатком является невозможность обоснования поведения НС, достоинством – более высокое качество, чем у статистических методов [5]. Мета поисковые системы Любая поисковая система имеет собственный информационный массив, который состоит из множества доступных для поиска документов. Это множество документов всегда ограниченно. Локальные поисковые системы по определению работают с некоторым фиксированным объемом информационных объектов. Число документов в сети Интернет постоянно растет, однако скорость увеличения числа доступных для поиска документов всегда меньше скорости их появления в сети. В настоящее время ни одна ИПС не может охватить все ресурсы в Интернет. Поэтому поиск с использованием какой-либо одной ИПС часто не может полностью удовлетворить информационную потребность пользователя. В такой ситуации приходится повторять один и тот же запрос в нескольких поисковых системах. Для увеличения широты охвата и расширения возможностей поиска, а также для облегчения работы пользователей были разработаны так называемые метапоисковые системы. Метапоисковые системы не имеют собственных баз данных поисковых образов документов, средств индексации и классификации. При поиске они используют ресурсы других поисковых систем. За счет одновременного обращения к взаимно дополняющим друг друга базам данных нескольких ИПС в метапоисковых системах достигаются максимальные значения полноты поиска. Порядок работы с метапоисковой системой, структура которой представлена на рис. 3.3, можно упрощенно описать следующим образом.
Пользователь в соответствии со своей информационной потребностью составляет запрос на поиск. Метапоисковая система передает этот запрос другим ИПС, которые и осуществляют поиск по своим информационным массивам. Затем результаты поиска в виде списков найденных документов от различных ИПС поступают обратно в метапоисковую систему, и в ней формируется итоговый список документов, который предлагается вниманию пользователя. Найденные документы ранжируются в порядке их следования в результатах поиска каждой из ИПС. При этом существенно повышается релевантность тех документов, которые были одновременно найдены в нескольких ИПС. Главная проблема, связанная с реализацией данного алгоритма, заключается в том, что поисковые системы используют разные методы индексации, имеют различные информационные массивы и, как следствие, базы индексированных документов различной полноты. Поэтому запрошенная пользователем информация может быть найдена в одной системе и не найдена в другой. В этом случае можно получить несколько полностью релевантных документов от одной ИПС, которые будут перемешаны с частично релевантными документами из другой (например, в случае частичного совпадения документа и запроса). Современные метапоисковые системы позволяют преодолеть эти трудности. Во-первых, каждая ИПС придерживается (в течение достаточно долгого времени) собственных правил ранжирования результатов поиска, что используется метапоисковой машиной при определении релевантности документов, полученных от разных систем. На значение релевантности также влияет рейтинг ИПС, определяемый качеством поиска в ней, и общее количество документов, найденных по запросу (это также позволяет оценить полноту базы поисковых образов конкретной ИПС). Наконец, главный метод корректного ранжирования заключается в статистическом анализе результатов поиска в различных системах. Обычно результаты поиска содержат названия (заголовки) и краткие описания (аннотации) найденных документов. Метапоисковая машина определяет частоты встречаемости терминов запроса в заголовках и аннотациях документов и присваивает каждому документу некоторый вес, используемый затем при ранжировании. Подобная обработка позволяет не только понижать ранг документов, в описании которых вообще нет ключевых слов, как потенциально нерелевантных запросу, но и находить строгое соответствие в том случае, если все ключевые слова встречаются в описании документа. На схеме (рис. 3.3) пользователь помимо запроса к поисковой системе определяет стратегию поиска. Формирование стратегии поиска предполагает выбор пользователем типа информационных объектов, которые нужно найти с помощью ИПС (файлы, новостные сообщения, гипертекстовые документы и другие), выбор области поиска (русскоязычная часть Интернета, англоязычная часть или глобальный поиск по всей всемирной сети), а также выбор ИПС, к которым должна обращаться во время поиска метапоисковая система. В результате объединения текста запроса на ИПЯ и ряда поисковых предписаний формируется так называемый расширенный запрос, который затем ретранслируется метапоисковой машиной другим ИПС.
Поисковая система Google Структура Google Поисковый робот Google имеет User Agent – Googlebot, который является основным роботом, сканирующим содержание страницы для поискового индекса. Помимо него существуют ещё несколько специализированных роботов: Googlebot-Mobile – робот, индексирующий сайты для мобильных устройств; Google Search Appliance (Google) gsa-crawler– поисковой робот нового аппаратно-программного комплекса Search Appliance; Googlebot-Image — робот, сканирующий страницы для индекса картинок; Mediapartners-Google – робот, сканирующий контент страницы для определения содержания AdSense; Adsbot-Google – робот, сканирующий контент для оценки качества целевых страниц AdWords. Существует теория «эффекта песочницы», которая утверждает, что сайты, которые имеют новые доменные имена или частые смены владельцев, помещаются в «песочницу» (зону ожидания) и пребывают там, пока механизм Google не сочтет сайт готовым из нее выйти. Так же существует обратная теория, называющаяся «Бонус новичка», в которой при первоначальной индексации сайта, в силу некоторых аспектов (например, нескольких ссылок с авторитетных ресурсов), сайту сразу присваивается высокий Page Rank и хорошие места в поисковой выдаче. По истечении некоторого времени, после снятия этого эффекта, сайту присваиваются его реальные показатели. 4.1.2. Концепция PageRank Google заставил мир поисковых систем перевернуться с ног на голову благодаря своей концепции PageRank, которая оказалась настоящим технологическим прорывом и которую сейчас использует большинство ведущих поисковых систем для обеспечения более качественного поиска. Технология поиска PageRank компании Google работает путем установления, в первую очередь, структуры ссылок во всей сети, а затем, ранжируя каждую отдельную страницу, основываясь на числе и значимости ссылок на нее на других страницах. Таким образом, значимость ссылок (популярность и релевантность обратных ссылок) намного более важна, чем их число. Показатель PageRank определяется по формуле
где d – демпфирующий коэффициент, отражающий какую долю веса может передать страница-донор на страницу-акцептор; n – количество страниц, ссылающихся на страницу-акцептор (на которые не наложен фильтр); T i – i-ая ссылающаяся страница; C – количество внешних ссылок на странице-доноре. Google использует интеллектуальную технику анализа текстов, которая позволяет искать важные и, вместе с тем, релевантные страницы по вашему запросу. Для этого Google анализирует не только саму страницу, которая соответствует запросу, но и страницы, которые на нее ссылаются, чтобы определить ценность этой страницы для целей вашего запроса. Кроме того, Google предпочитает страницы, на которых ключевые слова, введенные вами, расположены недалеко друг от друга. Программное обеспечение, используемое для реализации технологии поиска Google, проводит ряд одновременных вычислений, которые занимают не больше доли секунды. Традиционные поисковые системы в большей степени основываются на том, как часто слово появляется на веб-странице. Google же изучает всю структуру веб-ссылок и определяет, какие страницы наиболее важны, с помощью PageRank. Затем проводится анализ соответствия гипертекста и выбор страниц, наиболее подходящих для конкретного поиска. На основании общей значимости и соответствия запросу Google отображает в первую очередь наиболее релевантные и достоверные результаты. Технология PageRank объективно оценивает значимость веб-страниц, основываясь на уравнении, включающем более 500 миллионов переменных и 2 миллиарда терминов. Вместо того, чтобы подсчитывать прямые ссылки, PageRank рассматривает ссылку со страницы А на страницу Б как голос в пользу страницы Б от страницы А. Затем по количеству полученных голосов PageRank определяет значимость данной страницы. PageRank также оценивает важность каждой страницы, принимающей участие в голосовании. При получении голосов от страниц с большей значимостью ссылка становится более ценной. Значимые страницы получают более высокий рейтинг PageRank и отображаются в начале результатов поиска. Технология Google использует совокупные интеллектуальные веб-средства, чтобы определить значимость страницы. Человеческий фактор или подтасовка результатов невозможны, и именно поэтому пользователи доверяют Google как источнику объективной информации, в результатах поиска которого отсутствуют проплаченные рекламные объявления. Анализ соответствия гипертекста: поисковая система Google, как и другие системы, также анализирует содержание страницы. Однако вместо простого сканирования текста страницы (который может выполнить веб-издатель с помощью метатегов) технология Google анализирует все содержание страницы, особенности шрифтов, разбивки текста и точное расположение каждого слова. Google также анализирует содержание соседних веб-страниц, чтобы убедиться в том, что полученные результаты наиболее точно соответствуют запросу пользователя. 4.1.3. Поисковые запросы Google Интерфейс Google содержит довольно сложный язык запросов, позволяющий ограничить область поиска отдельными доменами, языками, типами файлов и т. д. Например, поиск «intitle: Google site: wikipedia.org» даст все статьи Википедии на всех языках, в заголовке которых встречается слово Google. 4.1.4. Базовые возможности Google Google значительно выделяется в рядах поисковых систем-конкурентов своим предельно простым и легко узнаваемым интерфейсом стартовой страницы, на которой расположены только ссылки на основные базы данных Google, страницу настроек, расширенный поиск и языковые инструменты. Опция «I’m Feeling Lucky» («Мне повезет») выдаст на запрос одну-единственную ссылку, которая была бы первой в результатах обычного поиска. Важнейший элемент, с помощью которого происходит взаимодействие с поисковой системой, – это строка запроса. В различных базах данных Google сохраняются общие принципы поиска, но при этом у каждого раздела могут быть и собственные, актуальные только для него, операторы. Например, для поиска в Google Groups может применяться оператор inauthor, малополезный для поиска в других базах. Во многих случаях для того, чтобы найти нужную информацию, достаточно просто набрать нужное слово и просмотреть первый десяток-полтора результатов. Существует три основных способа работы с Google. Это строка простого поиска, которую мы видим по адресу google.com (или google.ru), расширенный поиск и прямая работа с URL. Каждый из способов имеет свои достоинства. Простейший запрос к Google – это одно слово или же сочетание слов. В более сложных случаях после отработки первоначального запроса начинается работа по коррекции запроса и постепенному отбрасыванию ненужных ссылок. Еще один широко распространенный вид простого поиска – поиск на точное совпадение фразы. Фраза в данном случае – это несколько слов, заключенных в кавычки. При этом поиск ведется по всем словам без исключения, учитывается также их порядок в запросе. Эти виды поиска можно комбинировать. Значительно расширить гибкость поиска позволяет использование операторов – специальных команд поиска, позволяющих уточнить запрос. 4.1.5. Сервисы Google Google Answers – сервис для коллективного получения ответов на возникающие вопросы. Google AdSense – сервис контекстной рекламы, позволяющий заработать хозяевам страниц с большой посещаемостью. Программа автоматически доставляет текстовые и графические объявления, рассчитанные на веб-сайт и его содержание. Google AdWords – сервис контекстной рекламы, работает с ключевыми словами. Google Alerts – отправление на почту результатов поиска с заданной периодичностью. Google Analytics – бесплатный сервис, предоставляющий детальную статистику по трафику веб-сайта. Google App Engine – платформа для создания и хостинга масштабируемых веб-приложений на серверах компании Google. Google Apps – сервис для использования служб Google вместе со своим доменом. Google Merchant Center (ранее Google Base) позволяет владельцам контента помещать структурированную информацию в хранилище, автоматически получая возможность поиска по этой информации. Blogger – это сервис для ведения блогов, позволяющий держать на своём хостинге только программное обеспечение, а всю информацию: записи, комментарии и персональные страницы – в СУБД на серверах Google. Google Bookmarks – позволяет отмечать сайты закладками, добавлять к ним ярлыки и примечания. По ярлыкам и примечаниям можно делать поиск, закладки хранятся на сервере и доступны с любого компьютера. Google Buzz – инструмент социальной сети, разработанный компанией Google и интегрированный в Gmail. Google Calendar – онлайновый сервис для планирования встреч, событий и дел с привязкой к календарю. Возможно совместное использование календаря группой пользователей. Кроме того, сервис интегрирован с Gmail. Google Checkout – сервис обработки онлайновых платежей, имеющий целью упростить процесс оплаты онлайновых покупок. Веб-мастера могут использовать данный сервис в качестве одной из форм оплаты. Работает по всему миру. Google Docs – веб-ориентированное приложение для работы с документами, допускающее совместное использование документа. Google Directory (ранее Catalogs) – содержимое сети, организованное по разделам в категориях. Google Dictionary – сервис для перевода отдельных слов на другие языки. Google Finance – сайт-агрегатор биржевой информации. iGoogle (ранее Google Portal, Google Fusion и Personalized Homepage) – сервис для создания персональных страниц, использующих AJAX. Gmail – бесплатная электронная почта с большим объёмом места для хранения сообщений (более 7, 2 Гб), с доступом по POP3 и удобным веб-интерфейсом. Также является OpenID-провайдером для всех служб Google. Google Groups – архив конференций Usenet. Google Knol – вики-энциклопедия, состоящая из авторских статей по заданным темам. Google Labs – инкубатор идей для новых сервисов, предназначенный для тестирования интерфейса и т. п. Google Maps – набор карт, построенных на основе бесплатного картографического сервиса. Google Maps API – интерфейс, позволяющий встраивать карты на внешние сайты с помощью JavaScript. Google Mars – карты Марса. Google Moon – карты Луны. Google Mobile – интерфейс для использования приложений Google с помощью мобильных устройств. Google News – автоматически создаваемый новостной сайт, на котором собраны заголовки более чем из 400 источников новостей по всему миру: похожие статьи группируются, а затем показываются в соответствии с личными интересами каждого читателя. Google Orkut – социальная сеть, в которой пользователи могут указывать свою персональную и профессиональную информацию, создавать связи с друзьями и объединяться в сообщества по интересам. Google Picasa Web – персональные галереи фотографий. Google Public DNS – альтернативный DNS-сервер Google. Google Reader – RSS-аггрегатор, позволяющий читать потоки новостей в форматах Atom и RSS. Google Talk – программа для обмена мгновенными сообщениями (на основе протокола XMPP) и интернет-телефон. Google Search History – история поисковых запросов пользователя. Google Sites – бесплатный хостинг, использующий вики-технологию. Google Translate – система статистического машинного перевода слов, текстов, фраз, веб-страниц между любыми парами языков. Google Wave – сайт, объединяющий в себе функции электронной почты, вики, социальной сети, системы мгновенных сообщений. Google Webmasters – инструменты для вебмастеров. YouTube – сервис, предоставляющий услуги видеохостинга. Пользователи могут добавлять, просматривать и комментировать те или иные видеозаписи. Благодаря простоте и удобству использования, YouTube стал популярнейшим видеохостингом и третьим сайтом в мире по количеству посетителей. Google Blog Search – сервис поиска по блогам. В результаты поиска включены все блоги на всех языках. Google Book Search – полнотекстовый поиск по книгам, оцифрованным компанией Google (свыше 10 миллионов книг из крупнейших библиотек США). Google Code Searсh – поиск по исходным кодам, выложенным в Интернет в открытом виде. Froogle – это поисковый сервис Google для получения информации о предложениях товаров, которые можно заказать в интернет-магазинах. В настоящий момент действует только для США и Канады. Hackser Style Google – интерфейс поиска на языке Leet. Google Images – сервис поиска картинок в поисковой системе Google. Google Government Search Google – поиск по правительственным сайтам Соединённых Штатов Америки. Special Searches – поиск на специализированных сайтах (BSD, Linux, Mac OS X и Microsoft). Movie Showtimes – киноафиша. Google Patents Search – поиск по патентам среди свыше 7 миллионов доступных в базе данных. Google Scholar – сервис для поиска по научным источникам: статьям, книгам, диссертациям, опубликованным различными научными организациями и профессиональными сообществами. Google Suggest – часть поиска Google, технология автозаполнения строки поискового запроса на основе общей статистики самых популярных запросов. Google Video – сервис для поиска, просмотра и сохранения видео. Google Weather – часть поиска Google, позволяет получать 4-дневный прогноз погоды для городов мира. Телефонная книга – служба Google, которая позволяет найти телефонные номера и адреса, опубликованные в общедоступных источниках. Результаты поиска из адресной книги Google появляются над остальными результатами при вводе определенных типов запросов (имени, фамилии, города и т. д.). Языковые инструменты (Переводчик) – инструмент, позволяющий использовать Google на множестве различных языков. Калькулятор – сервис для расчетов, встроенный в строку поиска. Сервис знает множество математических функций, умеет соблюдать приоритет операций. Конвертер валют – например, 600 USD in RUR – сколько будет $600 в рублях. 4.1.6. Инструменты Google Google Code – сайт для разработчиков, интересующихся разработкой открытого программного обеспечения, связанного с продуктами компании Google. Сайт содержит исходные коды и список их сервисов с публичным API. Project Hosting – бесплатный специализированный хостинг GPL-проектов и др. свободных проектов. Google Pack – установочный пакет, объединяющий пакеты ряда продуктов Google (Google Earth, Picasa, Google Desktop и др.) и несколько сторонних продуктов (Mozilla Firefox, Adobe Reader и др.). Google Deskbar – размещает поиск Google на рабочем столе. Google Desktop – средство поиска на компьютере пользователя. Программа устанавливается локально и индексирует сообщения электронной почты, текстовые документы, документы Microsoft Office, обсуждения из AOL Instant Messanger, историю переходов в веб-браузере, PDF-документы, музыкальные файлы, изображения, видеофайлы. Google Earth – модель планеты Земля, созданная при помощи спутниковых снимков. Picasa – программа для работы с цифровыми фотографиями, интегрированная с Google Blogger и Gmail. Hello – дополнение к программе Picasa, позволяющее делиться своими фотографиями с друзьями без использования веб-сайта или электронной почты. Изображения пересылаются непосредственно от одного клиента к другому. Google Toolbar – плагин для браузеров Internet Explorer и Mozilla Firefox, представляющий собой панель поискового сервиса Google и выполняющий ряд дополнительных функций. Google Web Accelerator — программа, ускоряющая работу браузера путём кеширования и предварительного скачивания информации, которая, возможно, будет интересовать пользователя. Программа использует прокси-сервера, принадлежащие Google. 4.1.7. Аппаратное обеспечение Google Google Search Appliance – это аппаратно-программное решение, предназначенное для корпоративной интранет-сети. Это устройство выполняет периодический просмотр и индексирование документов (в базовой модели – до 500 000 документов) для поиска на внутренних или внешних корпоративных веб-сайтах или других ресурсах, доступных через веб. Google Mini – мини-версия устройства Search Appliance, названная Google Mini и предназначенная для небольших и средних компаний. Базовая модель устройства индексирует 100 000 документов. В январе 2006 года были предложены ещё две модели, на 200 000 и на 300 000 документов. Кроме того, 2 марта 2006 года была анонсирована модель на 50 000 документов. 4.1.8. Будущеее Google Google хочет получить более глубокий, чаще обновляющийся и более персонализированный индекс. Будущее будет в меньшей степени касаться отдельных возможностей и в большей – общей полезности и эффективности работы системы. Руководство и разработчики Google считают, что пользователям нужны, в первую очередь, релевантные результаты, но они также хотят и быстрого, чистого и честного поиска. Главное достоинство HTML-кода – это то, что написать его может почти каждый. Это одна из причин столь бурного роста WWW в последние годы. XML – превосходная возможность для связи между электронными системами, но составлять его вручную намного сложнее. Основное преимущество поисковой системы Google – это простота ее использования. Разработчики этого поисковика стремились сделать поисковую систему, которая могла быть доступной каждому пользователю сети без владения какими-либо специальными знаниями. Реализовать данную задачу у разработчиков успешно получилось. Google является самым удобным и простым Интернет-ресурсом. При введении ключевых слов она не требует использования специальных знаков (кавычек, заглавных букв и тому подобное), а это значительно облегчает процесс поиска нужной информации. Кроме этого, среди положительных качеств Google можно отметить ее огромную базу данных. На настоящий момент она насчитывает более трех миллиардов страниц, поэтому база этого поисковика входит в список самых больших. Еще одно, безусловно, хорошее и важное качество поисковой системы Google – это высокая скорость работы. Перед рабочими компании Google стояла задача сделать поисковую систему быстрой и эффективной. Теперь, сделав запрос, пользователи практически тут же получат результат поиска. Это стало возможно благодаря разработчикам, которые значительно «облегчили» странички с результатами поисков. На них присутствует минимальное количество рекламных объявлений, графики, кроме этого, значительно был сокращен текст с описанием страниц. Главный плюс – поисковая система Google показывает достаточно точную информацию. Результаты поиска обычно соответствуют запрашиваемым запросам. При этом ссылки на сайты, которые наиболее соответствуют указанным запросам, находятся вверху страницы. Также Google является, наверное, единственным поисковиком, в котором учитывается не только количество найденных страниц, но и их качество. Неоспоримое преимущество Google – наличие дополнительных функций. Например, эта поисковая система может позволить пользователю познакомиться с содержанием страниц, которые были уже закрыты. Однако у Google есть и ряд различных недостатков. Например, часто там можно встретить ссылки на сайты с уже ненужной и устаревшей информацией. Также случается, что ссылки, находящиеся в результате поиска, ведут на сайт, который в стадии разработки. Из-за этих сайтов пользователи тратят свое время попусту, и поэтому снижается продуктивность работы системы поиска. Отсутствие возможности отметить конкретную грамматическую особенность слова или ударение тоже значительно ухудшают процесс поиска. Но все же, несмотря на недостатки, система Google считается самой эффективной и быстрой, это ей позволяет завоевывать большее количество пользователей сети Интернет, чем какая-либо другая поисковая система. Кроме того, Google постоянно совершенствуется. Поисковая система Яндекс Структура Яндекса Яндекс – это российский поисковый мультипортал, который специализируется на поиске любой информации. Яндекс с самого начала своей работы: – вел проверку контента на уникальность, отвергая клонированные тексты; – исключал клоны из поиска, либо ранжировал их крайне низко; – вел учет морфологии, стремясь исправлять ошибки; – предложил поиск с учетом удаленности ключевых фраз от начала текста, – вел оценку релевантности страниц; – учитывал, помимо количества запросов определенного слова, частоту его употребления (насыщенность), положение в тексте (разбросанность), расстояние между словами; – реализовал функцию «вопрос-ответ». В структуру Яндекса входят три модуля: – робот или краулер (crawler) или спайдер (spyder); – база данных; – клиентская часть. Робот – подсистема, обеспечивающая просмотр (сканирование) Интернета и поддержание инвертированного файла (индексной базы данных) в актуальном состоянии. Этот программный комплекс является основным средством сбора информации о наличии и состоянии информационных ресурсов сети. Робот представляет собой специальную программу с функцией обхода в сети по расписанию интернет-ресурсов, индексации интересных страниц и с загрузки содержимого в базу данных поисковой системы, которая хранится на особых серверах. Поисковая база данных (так называемый индекс) – специальным образом организованная база (index database), включающая, прежде всего, инвертированный файл, который состоит из лексических единиц, взятых из проиндексированных веб-документов, и содержит разнообразную информацию о них (в частности, их позиции в документах), а также о самих документах и сайтах в целом. Клиентская часть отвечает за обработку запросов, поступающих от пользователей, а также за выдачу нужной информации - релевантных результатов поиска. Для их выдачи Яндекс обращается в ту самую собственную базу данных, определяет и выдает наиболее подходящие под запрос страницы. Алгоритмы Яндекса Поисковая система Яндекс применяет алгоритм ранжирования, который позволяет пользователю осуществить наилучший поиск нужных страниц, максимально соответствующих его запросу. Алгоритм ранжирования можно назвать сложной системой математических формул. С их помощью происходит оценка факторов, по совокупности которых и их анализу поисковик определяет пользу страницы и ее рейтинг. Как и в прежние годы, сохранились основные факторы ранжирования, к которым присоединились дополнительные показатели - характеристики документа. В настоящее время в ранжировании участвуют около 250 факторов, среди них можно выделить: – присутствие слов из запроса в контексте страницы; – присутствие таких слов в мета-тэгах, заголовках; – существование ссылок на ранжируемый документ; – наличие комментариев к ссылкам и изображениям; – авторитетность ресурса. Основой работы поисковых систем как Google, так и Яндекс является система кластеров. Вся информация делится на определенные области, которые относятся к тому или иному кластеру. Индексация сайтов с целью получения данных о размещенной на них информации выполняется роботами-сканерами. Существуют следующие виды сканирующих роботов: основной робот-сканер и робот-сканер, отвечающий за сбор информации на ресурсах с частым обновлением содержания. Второй тип сканирующего робота предназначен для быстрого обновления списка проиндексированных ресурсов и значения их индексов в поисковой системе. Для наиболее полного обеспечения сбора информации в системе Яндекс применяются обновления базы поиска и обновления программного кода. База поисковой информации обновляется несколько раз в течение месяца, при этом на поисковые запросы выдается обновленная информация с сайтов. Такая информация добавляется с помощью основного робота-сканера. При обновлении программного кода выявляются недостатки и изменяются алгоритмы, отвечающие за ранжирование ресурсов в поисковой системе. Как правило, перед выходом таких обновлений Яндекс публикует соответствующие анонсы. Основная особенность системы Яндекс, делающая популярной ее среди русскоязычных пользователей, – это способность определять различные словоформы с учетом морфологических особенностей русского языка. При этом значения запроса с помощью геотаргетинга и формул поиска преобразуется в максимально точную формулировку. Кроме того, Яндекс отличается алгоритмом по определению релевантности индексируемых страниц (релевантностью называют соотношение содержания веб-страницы к содержанию поискового запроса). Также к положительным сторонам можно отнести высокую скорость ответной реакции на запросы и устойчивую, без перегрузок, работу серверов. Большое значение для поисковой системы имеют динамические ссылки, наличие которых может привести к отказу от индексации ресурса поисковым роботом. В процессе индексации Яндекс распознает текстовую информацию в документах с расширениями: .pdf, .rtf, .doc, .xls, .ppt. Последние два относятся к программам входящими в комплект Microsoft Office: Excel и PowerPoint. При индексировании сайта поисковая система считывает данные из файла robots.txt, при этом поддерживается атрибут Allow и часть метатегов, а метатеги Revisit-After и Keywords игнорируются. Так как сниппеты – краткие описания текстовых документов – составляются из фраз на искомой странице, то использование описания в теге не является обязательным, но может использоваться в отдельных случаях. По заявлениям разработчиков кодировка индексируемых документов определяется автоматически, а значит, и метатег кодировки не имеет большого значения. Поисковая система большое значение придает показателю последнего изменения информации (Last-Modified). Если сервер не будет передавать эту информацию, то процесс индексации данного ресурса будет происходить намного реже. Пока что остается нерешенной проблема страниц, использующих фреймовые структуры, но она может быть обойдена с помощью скриптов, отправляющих пользователей поисковой системы в нужное место сайта. Если у сайта существуют «зеркала» (например, http: //www.site.ru, http: //site.ru, https: //www.site.ru, https: //www.site.ru), необходимо принять соответствующие действия для исключения их из процесса индексации. Если индексацию «зеркал» избежать не удалось, можно «склеить» их путем внесения необходимой информации в robots.txt. В случае попадания сайтов в «Яндекс.Каталог» система будет идентифицировать их как заслуживающих отдельного внимания, что может повлиять на продвижение сайтов. Также это способствует упрощению процедуры определения тематики сайта, что в свою очередь означает получение сайтом значимой внешней ссылки. Роботы Яндекса Команда поисковой системы Яндекс держит в секрете IP-адреса своих роботов. Но в лог-файлах отдельных сайтов можно встретить текстовые пометки, оставленные поисковыми роботами Яндекс. Одними из самых интересных роботов-сканеров поисковой системы Яндекс можно назвать: Yandex/1.01.001 (compatible; Win16; I) – основной робот, занимающийся непосредственно индексацией сайтов; Yandex/1.01.001 (compatible; Win16; P) – робот-индексатор изображений; Yandex/1.01.001 (compatible; Win16; H) – робот, который выявляет «зеркала» индексируемых сайтов; Yandex/1.02.000 (compatible; Win16; F) – робот-индексатор пиктограмм ресурсов (favicons); Yandex/1.03.003 (compatible; Win16; D) – робот, который обращается к страницам, добавленным с помощью формы «Добавить URL»; Yandex/1.03.000 (compatible; Win16; M) – задействуется при переходе на страницу посредством ссылки «Найденные слова»; YaDirectBot/1.0 (compatible; Win16; I) – этот робот отвечает за индексацию страниц ресурсов, принимающих участие в рекламной сети Яндекс. Из всех поисковых роботов самый важный так и называется – основной поисковый робот. От того, как он проиндексирует страницы сайта, будет зависеть значимость ресурса для поисковой системы. Работа всех роботов происходит по индивидуальному расписанию, и если сайт проиндексирован одним из них, то это не значит, что скоро будет произведена индексация и другим. В помощь основным созданы и роботы, которые периодически посещают сайты и устанавливают, насколько те доступны. К таким можно отнести роботов «Яндекс.Каталога» и рекламной сети Яндекс. [6] АБИС «Руслан» Характерными чертами автоматизированной библиотечной информационной системы «Руслан» являются: – автоматизация основных процессов; – модульность системы; – кооперация в режиме online со всеми библиотеками. Общие принципы организации системы «Руслан»: – открытые стандарты; – распределенная среда; – интернет/интранет технологии; – многоуровневая архитектура «клиент-сервер». Особенностями системы «Руслан» являются: – открытость; – каталогизация заимствованием; – поддержка UNICODE; – удаленная работа читателя; – удаленная работа сотрудника; – гибкость и адаптивность. 4.3.2. АБИС Greenstone АБИС Greenstone представляет собой эффективное OpenSource-решение для построения цифровых библиотек (ЦБ). Система Greenstone обладает следующими возможностями: – создание коллекции электронных документов; – детальное определение документов в зависимости от метаданных; – сохранение десятков Гб текста и связанных с ним изображений; – полнотекстовый поиск, а также поиск и просмотр документов по полям метаданных; – мультиязычность и мультиформатность; – организация и публикация информации в интернете или на компакт-дисках. ИРБИС Система ИРБИС представляет собой типовое интегрированное решение для автоматизации библиотечных технологий Особенностями системы ИРБИС являются: – использование в локальных вычислительных сетях; – автоматическое формирование словарей; – средства каталогизации; – использование штрих-кодов; – использование нестандартного кодового набора; – удобство и наглядность пользовательского интерфейса; – открытость системы.
О бщие положения Документ – это некая обособленная часть информации, представленная на определенном носителе. Документы различаются по типам носителей (рис. 5.1) [1]: бумага; микрофиши; электронные носители. Основными факторами, определяющими выбор носителя информации являются: – стоимость хранения информации; – стоимость (время) поиска информации; – стоимость коллективного использования информации; – стоимость (время) передачи документа от одного рабочего места другому.
Наиболее полное определение систем управления документами (EDMS - Electronic Document Management Systems) дает аналитическая компания IDC [2]: «Системы управления документами обеспечивают процесс создания, управления доступом и распространения больших объемов документов в компьютерных сетях, а также обеспечивают контроль над потоками документов в организации. Часто эти документы хранятся в специальных хранилищах или в иерархии файловой системы. Типы файлов, которые, как правило, поддерживают системы управления документами включают, текстовые документы, образы, электронные таблицы, аудио-, видео- данные, и документы Web. Общими возможностями систем управления документами являются создание документов, управление доступом, преобразование и безопасность». Сегодняшние предприятия требуют истинно распределенной архитектуры управления документами, т.е. такой, которая удовлетворяет следующим требованиям: 1. Функциональность и гибкость системы. 2. Возможность дальнейшей модернизации и наращивания возможностей системы (в том числе, самостоятельного). 3. Интегрируемость с другими корпоративными системами - система документооборота не может и не должна существовать в отрыве от других систем, например, иногда необходимо интегрировать систему с прикладной бухгалтерской программой. Тогда система документооборота должна иметь открытые интерфейсы для возможной доработки и интеграции с другими системами. 4. Возможность распределенной удаленной работы и взаимодействия с другими филиалами - основные проблемы при работе с документами возникают в территориально-распределенных организациях, поэтому архитектура систем документооборота должна поддерживать взаимодействие распределенных мест. Причем распределенные места могут объединяться самыми разнообразными по скорости и качеству каналами связи. Также архитектура системы должна поддерживать взаимодействие с удаленными пользователями. Распределенное, расширяемое управление документами приводит к резкому повышению продуктивности работы сотрудников, усилению общей конкурентоспособности организации. 5. Масштабируемость - желательно, чтобы система документооборота могла поддерживать, как пять, так и пять тысяч пользователей, и способность системы наращивать свою мощность определялось только мощностью соответствующего аппаратного обеспечения. Выполнение такого требования может быть обеспечено с помощью поддержки серверов баз данных производства таких компаний, как Sybase, Oracle, Informix и др., которые существуют практически на всех возможных программно-аппаратных платформах, тем самым обеспечивая самый широкий спектр производительности. 6. Модульность - вполне возможно, что заказчику может не потребоваться сразу внедрение всех компонентов системы документооборота, а иногда спектр решаемых заказчиком задач меньше, чем весь спектр задач документооборота. Тогда очевидно, что система документооборота должна состоять из отдельных модулей, интегрированных между собой. 7. Открытость и эффективность - обеспечение рационального соотношения между затратами на создание системы и целевыми эффектами, включая конечные результаты автоматизации документооборота; возможность внедрения широкого спектра дополнительных технологий для повышения уровня возврата от средств, затраченных на систему. Средства электронного управления документами можно подразделить на пять категорий. 1. Системы управления документами, ориентированные на бизнес-процессы: Documentum, FileNet (Panagon и Watermark), Hummingbird (PC DOCS). Как правило, предназначены для специфических вертикальных и горизонтальных приложений, иногда ориентированные на использование в определенной индустрии. Эти решения, как правило, обеспечивают полный жизненный цикл работы с документами, включая технологии работы с образами, управления записями и потоками работ, управление контентом и т. д. 2. Корпоративные системы управления документами: Lotus (Domino. Doc), дополнения к Novell GroupWise, Opent Text (LiveLink), Keyfile Corp., Oracle (Context). Обеспечивают корпоративную инфраструктуру для создания, совместной работы над документами и их публикации, доступную, как правило, всем пользователям в организации. Основные возможности этих систем аналогичны системам, ориентированным на бизнес-процессы. Однако их отличительной особенностью является способ использования и распространения. Аналогично таким средствам как текстовые редакторы и электронные таблицы, корпоративные системы управления документами являются стандартным «приложением по умолчанию» для создания и публикации документов в организации. Как правило, эти средства не ориентированы на использование только в какой-то определенной индустрии или для узко определенной задачи. Они предлагаются и внедряются как общекорпоративные технологии, доступные практически любой категории пользователей. 3. Системы управления контентом: Adobe, Excalibur. Обеспечивают процесс отслеживания создания, доступа, контроля и доставки информации вплоть до уровня разделов документов и объектов для их последующего повторного использования и компиляции. Потенциально доступность информации не в виде документов, а в меньших объектов облегчает процесс обмена информацией между приложениями. 4. Системы управления образами. Преобразуют информацию с бумажных носителей в цифровой формат, как правило, это TIFF (Tagged Image File Format), после чего документ может быть использован в работе уже в электронной форме. 5. Системы управления потоками работ (Workflow management): Lotus (Domino/Notes и Domino Workflow), Jetform, FileNet, Action Technologies, Staffware. Эти системы в основном рассчитаны на обеспечение движения неких объектов по заранее заданным маршрутам (так называемая «жесткая маршрутизация»). На каждом этапе объект может меняться, поэтому его называют общим словом «работа» (work). Системы такого типа называют системами workflow – «поток работ». К работам могут быть привязаны документы, но не документы являются базовым объектом этих систем. С помощью таких систем можно организовать определенные работы, для которых заранее известны и могут быть прописаны все этапы. Жизненный цикл документа Жизненный цикл документа (рис. 5.2) состоит из двух основных стадий [1]: стадии разработки документа и стадии опубликованного документа. На стадии разработки документа выполняются разработка содержания документа, оформление документа и утверждение документа. На стадии разработки документ считается неопубликованным, и права на документ определяются правами доступа конкретного пользователя. Для стадии опубликованного документа характерны: – активный (интенсивный) доступ; – архивное хранение документа, в качестве разновидностей которого иногда выделяют краткосрочное и долгосрочное хранение; – уничтожение документа.
Права на опубликованный документ остаются только одни – доступ на чтение. Кроме права доступа на чтение могут существовать права на перевод опубликованного документа в стадию разработки. В зависимости от конкретной стадии жизненного цикла документа, с которым имеет дело архивная система, архивы подразделяются на следующие типы [1]. Статические архивы документов (либо просто архивы) – системы, которые имеют дело только с опубликованными документами. Динамические архивы документов (либо системы управления документами) – системы, имеющие дело как с опубликованными документами, так и с теми, которые находятся в разработке. Статические архивы Задачи статических архивов К задачам статических архивов относятся [1]: 1. Организация хранения произвольного количества электронных документов на разнообразных носителях. При выборе носителя учитываются: стоимость хранения одного мегабайта информации; скорость доступа к информации; характер хранения информации – долгосрочное или краткосрочное. Для оперативного доступа применяются высокоскоростные жесткие диски, а для архивного хранения – роботизированные библиотеки оптических дисков. При наличии разнородных документов создают систему хранения на разнотипных носителях. Для таких систем решаются задачи совместной работы различных носителей и обеспечения миграции документов между носителями. Миграция осуществляется путем настройки системы администратором или автоматически в зависимости от частоты обращения к документам. Программное обеспечение, обеспечивающее автоматическую миграцию документов, называется Hierarchical Storage Management (HSM). 2. Организация учета бумажных и микрографических документов. Система хранит электронную карточку такого документа и поддерживает контроль стандартных архивных операций: выдача документа, возврат документа и т. п. 3. Организация поиска документов. Два основных подхода к поиску документов. Первый подход подразумевает поиск документа, который точно существует в системе. Здесь функция поиска организуется аналогично фактографическим ИПС (факт найден – факт не найден). Второй подход подразумевает поиск всех документов по интересующему вопросу. При этом рассматриваются полнота и шум поиска. Существует два основных типа поиска: атрибутивный и полнотекстовый. При атрибутивном поиске каждому документу присваивается набор определенных атрибутов. Поиск производится по их значениям. Недостатки атрибутивного поиска [1]: – эффективность только при отсутствии ошибок как в документах, так и в запросе; – субъективность формирования набора ключевых слов; – высокая стоимость ручного определения ключевых слов из-за невозможности автоматической индексации; – нестационарность критерия отнесения слова к ключевым. Полнотекстовый поиск производится по содержимому документа. Существует комбинация полнотекстового и атрибутивного поиска, когда атрибуты документа обрабатываются так же, как все содержание документа. При полнотекстовом поиске электронный документ любого формата необходимо предварительно преобразовывать в плоский текст, следовательно, любая такая система должна содержать в своем составе конвертеры форматов. Включение в результаты обработки поискового запроса документов, в которых содержатся все словоформы слов, входящих в запрос, называется нормализацией. Эффективность поиска зависит от применяемого алгоритма нормализации. Для русского языка наиболее эффективен словарный метод, при котором используются словари словоформ. Эвристический метод нормализации: слово нормализуется путем выполнения определенных правил, описывающих алгоритмы нормализации. 4. Поддержка аудита работы и защиты документов от несанкционированного доступа. Архивная система должна иметь защиту с разделением прав пользователей на уровне документа. 5. Поддержка просмотра документов без загрузки ресурсоемких приложений, которые порождают документ. 6. Поддержка аннотирования документа. Аннотации или комментарии (знаки, текст, цветные пометки) хранятся отдельно от основного текста в слоях, которые могут быть привязаны к имени автора, создавшего эти комментарии. Примеры реализации статического архива: WaterMark, PaperWise или ImageWise. Сканеры потокового ввода Такие сканеры ориентированы на документы низкого качества: слипшиеся, выцветшие, порванные, напечатанные с низким качеством на низкокачественной бумаге. Их отличительной особенностью является ротационный механизм перемещения. Основными критериями выбора сканера являются: – производительность; – долговечность; – стоимость; – максимальный размер вводимых документов; – возможность двустороннего ввода; – наличие средств контроля и повышения качества распознавания. Наиболее известны промышленные сканеры фирм Bell & Howell, Fujitsu, Kodak. Динамические архивы Задачи динамических архивов К задачам динамических архивов относятся: 1. Поддержка коллективной работы с документом. Выражается в поддержке целостности документов, что реализуется двумя путями: – реализуются библиотечные функции выписки документов на редактирование и возврата документов c редактирования, что предотвращает одновременное редактирование одного документа несколькими пользователями; – для того чтобы позволить одновременное редактирование одного документа несколькими пользователями, вводится понятие версии и подверсии документа. Кроме того, в рамках одного документа и одной версии (подверсии) может существовать несколько представлений документов (в разных форматах). 2. Поддержка составных документов. Каждый документ может представлять собой совокупность других документов. Такой документ носит название составного или контейнера, а в делопроизводстве такой документ носит название «дело», по своим характеристикам он аналогичен простому документу. Документы могут быть объединены в составной документ с помощью нескольких типов связей, которые определяют правила сборки документов в контейнер (порядок, используемая версия и т. д.). 3. Поддержка распространения опубликованных документов (электронная почта, публикация на Web-сервере). 4. Поддержка расширенного спектра прав доступа к документу. Жесткая маршрутизация Маршруты могут быть более сложными, чем простые последовательные или параллельные: – комбинированные из последовательных и параллельных элементов; – условные, с переходами в зависимости от состояния тех или иных переменных маршрутов. Для создания таких маршрутов используется специализированный графический редактор.
Желательно также обеспечение следующих функций: – контроль безопасности – при отправке документа сотруднику, не имеющему на него прав, выдача запроса о предоставлении прав; – поддержка опубликования документа – по завершении маршрута документ меняет свой статус на опубликованный. Дело» Система «Дело», является типичным представителем систем автоматизации делопроизводства и именно в этом качестве приобрела популярность у нас в стране. Она последовательно поддерживает все правила делопроизводства, унаследованные от советского делопроизводства и принятые в России. Разработчик - компания «Электронные офисные системы» (ЭОС) - взял курс на пересмотр концепции продукта в сторону создания полноценной системы документооборота. Продукт поддерживает идеологию делопроизводства, суть которой в следующем: чтобы было совершено любое действие в организации, нужен документ, к которому «приделываются ноги», то есть обеспечивается его движение. Движение документов (при том, что физически они, естественно, не перемещаются) происходит за счет изменения учетных записей о документах в базе данных. Для хранения документов компания ЭОС недавно представила отдельный продукт, интегрированный с системой «Дело», обеспечивающий функции электронного архива. В системе реализован Web-интерфейс, что удобно для организации удаленного доступа и построения интранет-порталов. Система имеет API, позволяющий интегрировать ее с различными приложениями. «Дело» хранит учетные записи средствами промышленной СУБД - Oracle или Microsoft SQL Server; осуществляет полное протоколирование действий пользователей с документами. Последняя версия интегрирована с системой распознавания FineReader для занесения в нее данных с бумажных документов. Продукт в первую очередь интересен для организаций, которые сталкиваются с необходимостью внедрения формализованного делопроизводства для подразделений секретариатов, канцелярий, общих отделов. Евфрат» «Евфрат» является простым электронным архивом с базовыми возможностями контроля исполнения. Разработан компанией Cognitive Technologies. Компания предлагает спектр продуктов для организаций различного масштаба - от версии для малого офиса до варианта для крупных компаний. В нашем случае речь пойдет о втором варианте, называемом «Евфрат Клиент-сервер», в котором в качестве клиентской части используется «Евфрат-Офис», являющийся самостоятельным продуктом, который может работать независимо от серверного компонента системы. «Евфрат» построен в парадигме «рабочего стола» с папками. Документы раскладываются по папкам, которые могут иметь любую степень вложенности. Собственного хранилища файлов «Евфрат» не имеет - система хранит только ссылки на файлы или на страницы в Internet. Для хранения реквизитов документов используется СУБД собственной разработки. В комплект продукта входят утилиты, позволяющие уплотнять и архивировать базу данных этой СУБД. Отличительной особенностью является возможность открыть и просмотреть любой документ поддерживаемого системой формата с помощью встроенной программы просмотра, правда, без форматирования и иллюстраций, что, впрочем, не составляет проблемы, так как документ можно открыть во внешнем " родном" приложении. К сожалению, «Евфрат» не дает возможности отслеживать получение и возврат документов и хранение версий, что может усложнить коллективную работу с документами. Система позволяет описать категории документов и приписать любой из категорий любые реквизиты. Для ввода информации с бумажных носителей в комплект продукта входит система потокового ввода, основанная на другом продукте компании - системе распознавания текстов Cuneiform. По сути, «Евфрат» представляет собой средство сканирования, распознавания, регистрации документов, присвоения им реквизитов, индексации, полнотекстового поиска, назначения заданий, связанных с документом, и контроля их исполнения. Это недорогое решение, которое может оказаться полезным в малом офисе или на предприятиях, не предъявляющих высоких требований к масштабируемости информационной системы. Другие системы Система Company Media разработана российской компанией «Интертраст» на основе Lotus Notes. Содержит широкий набор сервисов, поддерживающих делопроизводство, коллективное создание документов, контроль исполнения, управление договорами, управление проектами, управление персоналом, учет материальных ценностей и др. Сильной стороной является эффективная поддержка территориально распределенных структур управления за счет специальных методов, гарантирующих доставку заданий независимо от качества линий передач. Система может иметь широкое применение в организации - и как база для автоматизации делопроизводства, и как средство поддержки работы сотрудников в организации в целом. Дополнительные сервисы, реализованные в системе, делают ее еще более привлекательной. Продукт Staffware относится к категории workflow-систем масштаба предприятия. Разработан одноименной компанией, распространяется в России фирмой «Весть-Метатехнология». Это серверная технология для управления потоками работ. Типичными пользователями Staffware (как, впрочем, и любой другой системы workflow) могут стать телекоммуникационные компании, крупные и средние банки, гостиницы, другие организации, изо дня в день выполняющие множество регламентированных типовых операций. «Эффект-Офис» - продукт петербургской компании " Гарант Интернешнл". При невысокой цене он достаточно функционален - содержит электронный архив, средства описания структуры организации, ограничения доступа по ролевому принципу и маршрутизации документов. Основная функция - электронный архив со средствами поиска информации. Кроме того, он включает в себя средства автоматизации делопроизводства, базирующиеся на технологиях маршрутизации документов контроля исполнения. В продукте реализована собственная электронная почта с поддержкой POP3/SMTP и UUCP. Отличительной чертой являются низкие требования к ресурсам оборудования и ориентация на небольшие организации (до 100-150 сотрудников). Отличия западных и российских систем документооборота сведены в табл. 6.1
7. Система управления документооборотом на базе Lotus Notes Lotus Notes – ориентированная на БД собственного формата система клиент-серверной архитектуры, разработанная корпорацией Lotus Development, разработкой и продажами которой в настоящее время занимается IBM [7]. Система работает под управлением различных платформ семейств Windows и UNIX. Lotus Notes изначально разрабатывалась для работы в локальных сетях, но сейчас может работать и в глобальных, например, в Интернете [7]. Основными компонентами Lotus Notes являются клиент, БД, сервер и программное обеспечение промежуточного уровня (Middleware). Каждый клиент или сервер может иметь несколько локальных БД. Каждая БД представляет собой коллекцию заметок (notes). Клиент представляет собой совокупность запускающей подсистемы и модулей просмотра, сопоставимых по функциональности с Web-браузерами. В отличие от браузеров, они предоставляют возможности не только чтения, но и редактирования информации. Основная функция сервера Lotus (Lotus Domino) – управлять коллекцией БД и предоставлять к ним доступ клиентам и другим серверам. Программное обеспечение промежуточного уровня называется NOS – Notes Object Services (службы объектов Notes). Этот связующий компонент организуется поверх базовых ОС и сетей и позволяет связываться клиентам и серверам [7]. Существует программное обеспечение разработки приложений Notes, позволяющее создавать заметки и соответствующие им формы, представления, события, задачи и т. д. Основной элемент данных в Lotus Notes – заметка (note), представляющая собой список элементов (item). Типы элементов [7]: – текстовый; – числовой; – дата/время; – формулы команд макроязыка; – сценарии. Каждая заметка может иметь список ассоциированных с ней дочерних заметок. Любая заметка может иметь не более одного ассоциированного с ней родителя. Связь между заметкой и ответом на нее имеет вид отношения «родитель-потомок». Характеристики типов заметок приведены в табл. 7.1 [7].
Серверное программное обеспечение (Lotus Domino) состоит из основной программы и множества встроенных в нее заданий, выполняющих обработку запросов, управление данными, обеспечение целостности данных и управление кластерами серверов. Кроме встроенных заданий, могут быть дополнительные задания [7]. Взаимодействие между процессами сервера, а также их связь с локальными БД, осуществляются через уровень NOS. Для повышения отказоустойчивости и производительности серверы Domino могут объединяться в кластеры, являющиеся коллекциями двух-шести машин, на которых работают одинаковые серверы с идентичными БД. Ссылка на заметку БД, которую клиент получает для доступа к этой заметке, содержит ссылку на сервер, связанный с БД, содержащей эту заметку. В ответ на обращение клиента сервер БД возвращает ему список серверов своего кластера, упорядоченный по возрастанию текущей загруженности. Клиент обращается к первому серверу списка с запросом. Если сервер отвечает отказом, клиент обращается к следующему серверу и т. д. Загрузка сервера вычисляется как функция от времени отклика [7]. Связь организуется при помощи подсистемы NOS, базовой частью которой является RPC Notes (Remote Procedure Call – вызов удаленных процедур). Получив запрос RPC, сервер запускает отдельное задание, которое в дальнейшем взаимодействует с RPC, обрабатывая данный запрос [7]. Кроме клиент-серверного взаимодействия, осуществляемого через RPC Notes, в Lotus Notes есть средства электронной почты (формат MIME). В Lotus Notes есть средства автоматизации связи: – возможность автоматизации отправки писем в результате реакции на событие БД. – возможность автоматизации обработки принимаемых сообщений электронной почты, в том числе обновление БД. Информация о поименованных сущностях (БД, пользователях, серверах и т. п.) содержится в БД, называемой каталогом Domino (Domino directory), доступ к которой осуществляется так же, как к любой другой БД Notes [7]. Именование осуществляется при помощи строковых имен и идентификаторов. Строковые имена поддерживаются двумя способами: 1. Notes имеет службы различимых имен, которые могут использоваться для доступа к БД путем обращения к функциям ОС и для организации иерархического пространства имен. 2. Доступ при помощи URL. Используется при доступе через Web. URL имеет следующий формат: – имя сервера (например, «http: // domino. cs. vu. nl /»). – путь к БД (например, «lotus / db. nsf /»). – описание операции доступа к заметке, содержащее: –– универсальный идентификатор заметки (строковое 16-ричное представление 16-байтового числа); –– наименование операции БД над заметкой (например, «OpenView»); –– параметры операции (например, «start =124»). Пример: http: // domino. cs. vu. nl / lotus / db. nsf / a 34 bc 1975 ead 20961 d 56 a 4 c 982 ad 57 e? OpenView & start =1. Реплицированные заметки имеют общий UNID и отличаются OID (табл. 7.2).
OID состоит из UNID, 2-байтового последовательного номера и 8-байтовой отметки времени. Note ID используется совместно с таблицей соответствия, которая имеется в каждой БД. В этой таблице Note ID сопоставлено описание физического положения заметки в БД. Replica ID используется при репликации. Если несколько БД имеют одинаковый Replica ID, то изменения, вносимые в одну копию, должны вноситься в остальные [7]. Репликация основывается на связующих документах (connection documents) – особых заметках, содержащихся в каталоге Domino и описывающих время, способ или схему репликации (табл. 7.3) и объект репликации [7].
Операции изменения представляют собой: – модификация документа; – добавление документа; – удаление документа. Модифицированный документ должен быть разослан на все реплики. Изменения заметки заканчиваются изменением ее OID, предыдущее значение которого копируется в журнал истории документа. При добавлении документа для него создаются новые UNID и OID. При удалении документа на его место в БД помещается заглушка удаления (deletion stub). Заглушка удаления не уничтожается до тех пор, пока не уничтожены все копии удаленного документа. В процессе репликации по схеме извлечение-продвижение для каждой реплики создается список OID. Затем сравниваются списки с двух серверов. Заметки с UNID, отсутствующими на другом сервере, (т. е. добавленные) должны быть переданы на него. Для заметок, имеющих в списках серверов A и B одинаковые UNID, но разные OID, выполняются следующие действия. Задание на репликацию просматривает истории обеих заметок. Если одна из историй является частью другой, то конфликт отсутствует: более новая заметка замещает более старую. Если изменения относятся к различным элементам заметки, то конфликтующие модификации также отсутствуют: в объединенную заметку передаются наиболее новые элементы. Во всех остальных случаях конфликт неразрешим. При этом Notes выбирает один из документов победителем. Им становится копия с большим последовательным номером в OID или (в случае равенства последовательных номеров) с большей отметкой времени [7]. В кластере вместо явного планирования репликации при помощи связующих документов изменения просто немедленно передаются на все реплики кластера. Для этой цели каждый сервер поддерживает очередь событий репликации, в которую заносятся локальные операции изменения. Раз в секунду специальное задание на репликацию просматривает очередь в поисках изменений, которые следует распространить на другие серверы кластера, продвигает их и удаляет события из очереди [7]. Notes поддерживает нераспределенные механизмы блокировки для разграничения доступа к данным и транзакции. Поддержка распределенных блокировок и транзакций отсутствует [7]. Распределенные механизмы отказоустойчивости в Notes отсутствуют. В каждом сервере имеется подсистема восстановления. Она использует журнал, в который записывается перед выполнением каждая операция с БД, входящая в транзакцию. Для защиты используются механизмы аутентификации и управления доступом. Для аутентификации используется криптография с открытым ключом. Управление доступом использует так называемые списки контроля доступа (Access Control Lists, ACL), которые определяют каким пользователям, группам пользователей и серверам разрешено посылать запросы на данный сервер. Каждая БД имеет свой список ACL, который определяет, кто и что может делать. Существует семь уровней доступа к БД – от уровня менеджера до уровня «нет доступа» [7]. Для рабочих станций используются списки контроля исполнения (Execution Control Lists, ECL), описывающие ограничения, налагаемые на исполняемый код. Например, может быть ограничен доступ исполняемого кода к локальной файловой системе рабочей станции, к средствам отправки почты, к определенным сетевым адресам и т. п.
8. Системы документооборота на базе MS Exchange + MS Outlook Общие положения Система электронного документооборота (СЭД) позволяет организовать любое взаимодействие между сотрудниками компании на основе документов. Она обеспечивает создание документов, их движение по организации, контроль исполнения документов и процессов, которые описываются с их помощью, а также хранение документов. Интеграция системы электронного документооборота с существующей почтовой системой и с существующими учетными системами должна осуществлять: – пересылку электронных документов между должностными лицами различных подразделений с использованием локальной вычислительной сети; – временное хранение пересылаемых документов до первого входа получателя в систему; – возможность личной переписки должностных лиц; – отправку и прием сообщений за пределы организации через Internet; – подтверждение доставки и прочтения получателем сообщения или документа; – организовывать удобную для пользования электронную адресную книгу; – обеспечивать планирование и управление личным временем; – организовывать проведение собраний с согласованием времени со всеми участниками работу над коллективным проектом; – использовать общие папки для организации доски объявлений по тематике, электронные телеконференции, проводить голосования. Система электронного документооборота должна обеспечивать: – централизованное управление документами; – поддержку жизненного цикла документов; – коллективную работу над документами; – конфиденциальность; – маршрутизацию документов; – интеграцию с другими системами. – полный контроль документа; – создание новых версий документа, но не редактирование; – аннотирование документ; – просмотр документа. Наличие корпоративного хранилища обеспечивает следующие преимущества: – дает возможность пользователям ознакомиться с базовыми функциями системы и постепенно освоиться с ее использованием; – использование сервисных функций, таких как оповещение об изменении документа, о появлении нового документа и т. п. При внедрении системы электронного документооборота необходимо уделить повышенное внимание описанию и внедрению процедуры фиксации результатов коллективной работы. Так, при работе в рамках системы любое совещание должно сопровождаться ведением протокола, который впоследствии вносится в систему. 8.2. Microsoft Outlook Microsoft Outlook – это набор инструментов для управления корпоративной и личной электронной почтой. В его состав также входит многофункциональный органайзер, позволяющий работать с календарем, планировщиком задач, записной книжкой и менеджером контактов. Использование данного приложения в качестве клиента почтового сервера Microsoft Exchange Server поможет организовать эффективную совместную работу сотрудников любой компании над общим проектом. Преимущества использования Microsoft Outlook: – простота и удобство работы пользователя; – минимизации затрат времени при осуществлении навигации и настройке приложения; – безопасность и сенсорное управление. Если использовать мобильное устройство с сенсорным экраном, то достаточно скрыть Ribbon-панель и дисплей становится пригодным для управления пальцем. Outlook поддерживает работу со множеством серверов и служб электронной почты. Среди них: протокол SMTP, POP3, Internet Mail Access Protocol, версия 4 (IMAP4), интерфейс MAPI для Exchange Server. В Outlook предусмотрены несколько функций для защиты от спама - нежелательной почты (действует специальный фильтр нежелательной почты). Письма, которые «заметил» такой фильтр, перемещаются в отдельную папку для последующего анализа; – высокое удобство общения. При совместной работе над проектом можно создать общую папку, календарь или список задач для членов рабочей группы; – приложение позволяет применять несколько учетных записей электронной почты, что дает возможность одновременного использования различных почтовых ящиков и календарей; – моментальный поиск нужной информации в письмах, календарях и контактах. 8.3. Microsoft Exchange Server Exchange Server – это система корпоративной почты бизнес-класса, которая помимо возможностей почтового сервера предоставляет пользователям широкий набор средств для совместной работы, такие как: календари, задачи, общие контакты и адресные книги, общие папки, доступные через Outlook, в которых могут быть размещены различные общие документы и почта. Ролевая структура Exchange Server приведена на рис. 8.1. Использование Microsoft Exchange Server обеспечивает следующие преимущества: 1. Унифицированная среда работы пользователей. Внедрив Exchange Server, можно получить единый ящик для электронной, голосовой почты, факсов и SMS.
2. Повышение производительности труда пользователей. Outlook в Exchange Server группирует переписки в цепочки сообщений и вместо десятка писем, полученных в разное время и разбросанным по разным папкам, отображает только один элемент. Раскрыв этот элемент, пользователь видит всю переписку сразу. 3. При создании письма пользователю выдаются специальные подсказки (MailTips). 4. Повсеместный доступ. Exchange Server предоставляет пользователям действительно повсеместный доступ, не зависимо от того находится ли человек в офисе, дома, в командировке или в дороге, он всегда сможет получать и отправлять почту, назначать и принимать встречи в календаре, просматривать контакты клиентов и своих коллег. 5. Мобильный доступ. Разработанная Microsoft технология ActiveSync стала стандартом доступа к почте с мобильных устройств. 6. Защита информации. Взаимодействие со службой каталогов Active Direсtory происходит с использованием протокола Kerberos. Для более безопасной работы могут использоваться смарт-карты или системы биометрической аутентификации. Все внешние коммуникации, доступ через WEB или с использованием мобильных устройств шифруются по протоколу SSL. Кроме того пользователи могут использовать шифрование и подпись самих электронных сообщений при помощи технологии S/MIME. Шифрование доступно как из Outlook, так и через WEB или мобильный доступ. Microsoft Exchange Server поддерживает технологию IRM (Information Rights Management), которая позволяет защитить конфиденциальные документы Microsoft Office. 7. Сокращение затрат на обслуживание. Внедрив MS Exchange Server, пользователи сами смогут восстанавливать ошибочно удалённые сообщения, не обращаясь к системному администратору, чтобы тот восстановил их письмо из резервной копии. 8. Антивирусная и антиспам защита. Для проверки электронной почты может использоваться несколько антивирусных ядер одновременно. Среди которых: Kaspersky, McAfee, BitDefender, AVG Antivirus, Norman и др. Кроме того антивирусная проверка может происходить на трёх уровнях: на пограничных серверах (Edge Transport), на внутренних маршрутизирующих серверах (HUB Transport) и на серверах баз данных (Mailbox). 9. Высокая степень интеграции в инфраструктуру. Exchange Server интегрируется с Forefront Threat Management Gateway (ранее называвшийся ISA Server), обеспечивая наивысший уровень защищённости от внешних угроз. Exchange интегрируется с такими продуктами, как Microsoft CRM и SharePoint, а объединение Microsoft Exchange Server и Microsoft Office Communications Server представляет собой мощное решение для объединенных коммуникаций (Unified Communications). 10. Неограниченные возможности масштабирования. Exchange Server обладает практически неограниченными возможностями масштабирования, он может объединять сотни тысяч пользователей под одним почтовым доменом. В организации может быть установлено неограниченное количество почтовых серверов, сами сервера могут быть разбросаны географически по всему миру, каждый из серверов может содержать ящики различных пользователей. 11. Высокая доступность и отказоустойчивость. Использование технологии DAG. Структура технологии DAG приведена на рис. 8.2.
Данная технология позволяет реплицировать почтовые базы данных между узлами кластера. И в случае выхода из строя жёсткого диска, массива или даже целого сервера, содержащего активную базу данных, в работу мгновенно включится пассивная копия. Развёртывание Exchange Server в масштабах предприятия с большим числом пользователей и большим количеством филиалов требует наличия сертифицированных специалистов с большим опытом участия в аналогичных проектах. Помимо разработки самой инфраструктуры серверов MS Exchange, требуется соответствующее планирование структуры домена Active Directory, топологии сайтов, т.к. работа Exchange напрямую зависит от функционирования контроллеров домена и серверов глобального каталога. При разработке отказоустойчивых кластерных конфигураций нужно учесть огромное количество факторов, влияющих на работоспособность почтовой системы. 8.4. Согласование документов в MS Outlook. Практические действия 1. Необходимо открыть программу MS Outlook и выбрать «создать сообщение» (рис. 8.3).
К письму сделать вложение с документом, который требует согласования. В качестве адресатов написать всех согласующих лиц. Затем указать тему письма. 2. Далее нужно завести типовые варианты результатов согласования, которые будут выбирать согласующие лица, ознакомившись с проектом документа. Для этого на панели инструментов электронного письма нужно нажать кнопку «Параметры» (рис. 8.4).
3. После настройки параметров, при необходимости, особенно, если дело касается документов повышенной важности, можно определить время, в течение которого необходимо завершить процесс согласования. Тогда выберите флажок «К исполнению» и нужную строчку. Если ни одна строка не подходит, нажмите «другой» и установите дату сами. Срок согласования проекта документа указывается инициатором в соответствии с утвержденными в организации сроками согласования, которые могут быть прописаны, например, в Инструкции по делопроизводству. MS Outlook позволяет установить конкретную дату. Письмо готово. Если все корректно и хорошо, нажмите «отправить». Процесс согласования. Если письмо с проектом документа получено адресатом или адресатами, то при открытии его увидим, что в этом сообщении группа команд «Ответить» имеет дополнительно кнопку «Голосование» (рис. 8.5).
Согласующее лицо, прочитав вложение, может выбрать один из заданных параметров: согласовано, не согласовано, согласовано с замечаниями.
Если должностное лицо не согласно с проектом документа либо считает необходимым внести в документ некоторые уточнения, то на «Панели голосования» необходимо выбрать вариант «Нет» либо «Да с замечаниями» соответственно. А в открывшемся окне Microsoft Outlook отметить вариант «Изменить ответ перед отправкой». В результате откроется новое электронное письмо (рис. 8.6), где должностное лицо может указать свои комментарии (замечания, возражения) по документу и направить их инициатору документа.
Создание листа согласования начинается с выбора команды «Просмотреть результаты голосования». Для этого открывается любое из присланных согласующими лицами сообщений. Если все должностные лица, с которыми согласовывался документ, полностью согласны с проектом документа, то необходимо распечатать из Microsoft Outlook результаты согласования (рис. 8.7), прикладывая их в качестве листа согласования к печатной форме проекта документа, и направляет данный пакет документов инициатору согласования.
Библиографический список 1. Концепция построения систем автоматизации документооборота [Текст] / А. Гавердовский // Открытые системы. - 1997. - № 1. - С. 29-34 2. Дюк, В. А. Data Mining – интеллектуальный анализ данных [Электронный ресурс] / В.А. Дюк. – Режим доступа: http: //www.olap.ru/basic/dm2.asp 3. Корпоративные информационные системы: технологии и решения [Текст] / М.С. Каменнова // Системы управления базами данных. - 1995. - № 3. - С. 88-99. 4. Средства добычи знаний в бизнесе и финансах [Текст] / Киселев, Е. Соломатин // Открытые системы. - 1997. - № 4. - С. 41-44 5. Корнеев, В.В. Базы данных. Интеллектуальная обработка информации [Текст] / В.В. Корнеев [и др.]. – М.: «Нолидж», 2000. - 352 с.: ил. 6. Создание систем поддержки принятия решений на основе хранилищ данных [Текст] / В. Львов // Системы управления базами данных. - 1997. - № 3. - С.30-40. 7. Таненбаум, Э. Распределенные системы. Принципы и парадигмы [Текст] / Э. Таненбаум, М. ван Стеен. – СПб.: Питер, 2003. – 877с.: ил. 8. Федоров, А. Введение в OLAP-технологии Microsoft [Текст] / А. Федоров, Н. Елманова. – М.: Диалог-МИФИ, 2002. – 268 с. 9. Цымбал, В. П. Информационные системы и структуры данных [Текст]: учеб. пособие / В. П. Цымбал, С. П. Куценко. – Киев: Вища шк., 1980. – 238 с.: ил. 10. Интеллектуальный анализ данных в системах поддержки принятия решений [Текст] / М. Шапот // Открытые системы. - 1998. - № 1. - С.30-35. 11. Способы аналитической обработки данных для поддержки принятия решений [Текст] / Л. В. Щавелев // Системы управления базами данных. - 1998. - № 4-5. - С. 35-48.
Учебное издание
Ланских Юрий Владимирович Ланских Владимир Георгиевич
Информационные системы для работы с документами
Подписано в печать хх.хх.18. Печать цифровая. Бумага для офисной техники. Усл. печ. л. х, хх. Тираж хх экз. Заказ ххх.
«Вятский государственный университет» ПРИП ФГБОУ ВО «Вятский государственный университет» 610000, Киров, ул. Московская, 36 Тел.: (8332) 64-23-56, http: //vyatsu.ru
Информационные системы Для Работы с документами
Учебное пособие Киров 2018 УДК 004(07) Л хх Рекомендовано к изданию методическим советом факультета автоматики и вычислительной техники ФГБОУ ВО «Вятский государственный университет»
Допущено редакционно-издательской комиссией методического совета ФГБОУ ВО «Вятский государственный университет» в качестве учебного пособия для студентов направления 09.03.02 «Информационные системы и технологии», а также других направлений факультета автоматики и вычислительной техники.
УДК 004(07) Рассматриваются принципы построения и способы реализации различных информационно-поисковых систем и систем автоматизации электронного документооборота
© ФГБОУ ВО «Вятский государственный университет», 2018
СОДЕРЖАНИЕ Введение. 6 1. Информационно-поисковые системы и языки. 7 1.1. Основные понятия. 7 1.2. Основные информационно-поисковые режимы.. 8 1.3. Основные типы ИПС.. 9 1.4. Основные характеристики и параметры ИПС.. 11 1.5. Схема функционирования ИПС.. 15 1.6. Понятие критерия смыслового соответствия. 16 1.6.1. Булева модель поиска. 16 1.6.2. Алгоритм расширенного булева поиска. 19 1.6.3. Алгоритм наибольшего цитирования. 20 1.6.4. Векторный алгоритм поиска. 20 1.6.5. Расширенный векторный алгоритм поиска. 22 1.7. Информационно-поисковые языки. 22 2. ИПС на тезаурусе. Классификация и рубрицирование. 27 2.1. Общие понятия. 27 2.2. Формальное определение тезауруса. 27 2.3. Классификация документов. 28 2.4. Формирование рубрик. 33 2.5. Автоматическое рубрицирование. 35 2.5.1. Методы автоматического рубрицирования. 35 2.5.2. Рубрицирование, основанное на обучении по примерам. 37 3. Функциональные разновидности современных ИПС.. 40 3.1. Словарные информационно-поисковые системы.. 40 3.2. Классификационные информационно-поисковые системы.. 44 3.3. Метапоисковые системы.. 47 4. Обзор современных информационно-поисковых систем. 51 4.1. Поисковая система Google. 51 4.1.1. Структура Google. 51 4.1.2. Концепция PageRank. 51 4.1.3. Поисковые запросы Google. 53 4.1.4. Базовые возможности Google. 54 4.1.5. Сервисы Google. 54 4.1.6. Инструменты Google. 59 4.1.7. Аппаратное обеспечение Google. 60 4.1.8. Будущеее Google. 60 4.2. Поисковая система Яндекс. 62 4.2.1. Структура Яндекса. 62 4.2.2. Алгоритмы Яндекса. 63 4.2.3. Роботы Яндекса. 65 4.2.4. Показатели внешней оптимизации Яндекса. 66 4.3. Автоматизированные библиотечные ИПС.. 71 4.3.1. АБИС «Руслан». 71 4.3.2. АБИС Greenstone. 71 4.3.3. ИРБИС.. 72 5. Системы управления электронными документами. 73 5.1. Общие положения. 73 5.2. Жизненный цикл документа. 77 5.3. Статические архивы.. 78 5.3.1. Задачи статических архивов. 78 5.3.2. Трансформация бумажных документов в электронную форму. 80 5.3.3. Компоненты статического электронного архива. 80 5.3.4. Индексирование и поиск документов. 81 5.3.5. Технологические принципы построения электронного архива. 82 5.3.6. Сканеры потокового ввода. 83 5.4. Динамические архивы.. 84 5.4.1. Задачи динамических архивов. 84 5.4.2. Маршрутизация и контроль исполнения. 85 5.4.3. Свободная маршрутизация документов с контролем исполнения. 85 5.4.4. Жесткая маршрутизация. 85 5.4.5. Регистро-ориентированные системы управления документооборотом. 86 6. Обзор основных систем документооборота. 88 6.1. Docs Fusion и Docs Open. 88 6.2. Documentum.. 89 6.3. LanDocs. 91 6.4. Microsoft SharePoint Portal Server 92 6.5. Optima Workflow.. 93 6.6. «БОСС-Референт». 94 6.7. «Дело». 95 6.8. «Евфрат». 96 6.9. Другие системы.. 97 7. Система управления документооборотом на базе Lotus Notes. 99 8. Системы документооборота на базе MS Exchange + MS Outlook. 106 8.1. Общие положения. 106 8.2. Microsoft Outlook. 107 8.3. Microsoft Exchange Server 108 8.4. Согласование документов в MS Outlook. Практические действия. 112 Библиографический список. 116
Введение Множество информационных систем офисного назначения можно классифицировать в соответствии с областью их применения, рассматривая при этом каждую разновидность как некоторую предметно- или проблемно-ориентированную систему (банковского бухгалтерского, казначейского и т. п. назначения). В настоящем пособии предлагается классификация информационных систем по функциональному признаку. Поэтому классы информационных систем, рассматриваемые в пособии, можно обозначить как функционально-ориентированные системы (по аналогии с предметно- или проблемно-ориентированными). В качестве основных функций рассматриваются информационный поиск, автоматизация управления документами и документооборотом, аналитическая обработка данных. Соответственно выделяются информационно-поисковые системы, системы управления электронными документами, информационно-аналитические системы. Заведомо не рассматриваются системы преимущественно производственного назначения, например, информационно-управляющие системы. Необходимо отметить, что если рассматривать информационные системы с точки зрения практики их использования, крайне редко можно встретить функционально-ориентированную систему «в чистом виде». В реальных административно-офисных информационных системах поддерживаются и функции поиска, и функции аналитики, и работа с документами. Существуют системы, интегрирующие в себе эти функции. Существует огромное множество примеров работ по интеграции систем различного функционального назначения для решения комплексных задач предприятия, выполняемых ИТ-специалистами. Обособленное рассмотрение функционально-ориентированных систем интересно в первую очередь с точки зрения детального анализа их функций и средств их технической реализации.
Информационно-поисковые системы и языки Основные понятия Информационно-поисковые системы (ИПС) представляют собой совокупность лингвистических, алгоритмических, программных и технических средств, предназначенных для поиска, хранения и выдачи по запросам информации [9]. Выделение данного класса информационных систем объясняется тем, что: 1. Поиск информации по запросам является их основной функцией. 2. Сложность всей ИС практически сводится: – к сложности используемых алгоритмов поиска; – к сложности реализации предметно-ориентированных языковых средств формирования запросов. 3. Сложность алгоритмов поиска, как правило, объясняется требованием многопользовательского доступа, большими объемами информационного фонда, его распределенностью или территориальной удаленностью, что влечет повышенные требования к производительности. Вообще же, ИПС входят как подсистемы в подавляющее большинство ИС, поскольку наличие информационного фонда ИС предполагает реализацию функций поиска в нем и обработки запросов. Три основных проблемы информационного поиска [9]: 1. Проблема общения связана с необходимостью разработки языковых средств формирования запросов со своими грамматическими правилами и словарями, а также обработчика запросов. Возможна, в частности, двухступенчатая структура средства формирования запросов. Например, при использовании в качестве информационного фонда SQL-сервера разрабатывают: – средство формирования запросов пользователя, максимально приближенное к его предметной области: языковое либо визуальное; – транслятор с языка формирования запросов на SQL. Роль обработчика запросов играет сам сервер. 2. Проблема установления соответствия имеет значение в ИС, где присутствует требование уникальности искомых информационных единиц по критерию смыслового соответствия. В случае неопределенности, неполноты, некорректности формирования запроса возможна неоднозначная выборка данных из информационного фонда. Данная проблема частично решается путем многократной корректировки запросов с учетом критерия смыслового соответствия и характера хранимой информации. 3. Проблема организации возникает в случае большого объема информационного фонда и семантической структурированности или иерархичности предметной области. Оба эти случая влекут необходимость декомпозиции информационного фонда и, как следствие, усложнения алгоритмов доступа к нему. В состав ИПС входят: – технические средства; – информационно-поисковый язык; – программные средства; – БД; – словарь метаданных. Формат информационной единицы ИПС, представленный в терминах информационно-поискового языка, называют предмашинным форматом. Представление информационной единицы в соответствии с предмашинным форматом называется поисковым образом документа (ПОД). При формировании информационного фонда ИПС поисковый образ документа формируется согласно предмашинному формату и вводится в ИПС. При запросе к информационному фонду составляется поисковый образ запроса (ПОЗ) или поисковое предписание (ПП) [9]. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Последнее изменение этой страницы: 2019-06-09; Просмотров: 458; Нарушение авторского права страницы
 ,
, 
 – число терминов в запросе;
– число терминов в запросе;  – запрос, состоящий из
– запрос, состоящий из  терминов (вектор запроса);
терминов (вектор запроса);  –
–  -й термин в запросе;
-й термин в запросе;  – число документов в информационном массиве;
– число документов в информационном массиве;  –
–  -й документ (поисковый образ
-й документ (поисковый образ  – релевантность (мера близости)
– релевантность (мера близости)  к запросу
к запросу  ;
;  – величина, характеризующая наличие
– величина, характеризующая наличие 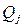 в
в  , определяемая по формуле
, определяемая по формуле  . Для повышения качества поиска в этом выражении вместо 1 можно использовать вес
. Для повышения качества поиска в этом выражении вместо 1 можно использовать вес  термина в документе;
термина в документе;  – величина, характеризующая наличие гиперссылки из
– величина, характеризующая наличие гиперссылки из  в
в  (входящей гиперссылки).
(входящей гиперссылки). 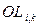 – величина, характеризующая наличие гиперссылки из
– величина, характеризующая наличие гиперссылки из  в
в  (исходящей гиперссылки).
(исходящей гиперссылки).  =0, если гиперссылки нет,
=0, если гиперссылки нет,  =1, если гиперссылка есть.
=1, если гиперссылка есть.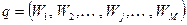 , где
, где  – вес j -ого термина в запросе (вес термина
– вес j -ого термина в запросе (вес термина  в запросе q ). Вектор документа
в запросе q ). Вектор документа 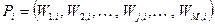 , где
, где  – вес термина
– вес термина  в документе
в документе  (1.2)
(1.2) – косинус угла между этими векторами в евклидовом пространстве. Весовые коэффициенты терминов запроса будут постоянными от документа к документу. Поскольку для оценки релевантности обычно важно знать изменение меры подобия документов, а не ее абсолютное значение, а также для ускорения процесса вычислений, характеристики запроса в выражении (1.2) можно не учитывать:
– косинус угла между этими векторами в евклидовом пространстве. Весовые коэффициенты терминов запроса будут постоянными от документа к документу. Поскольку для оценки релевантности обычно важно знать изменение меры подобия документов, а не ее абсолютное значение, а также для ускорения процесса вычислений, характеристики запроса в выражении (1.2) можно не учитывать: 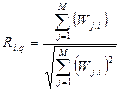 (1.3)
(1.3) , (1.4)
, (1.4) – частота термина
– частота термина  – обратная документная частота, вычисляемая по формуле
– обратная документная частота, вычисляемая по формуле .
. . (1.5)
. (1.5)

 , где ft – частота встречаемости термина t в рассматриваемом документе; kr – пороговое значение для r.
, где ft – частота встречаемости термина t в рассматриваемом документе; kr – пороговое значение для r.


 ,
,