
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
ИПС на тезаурусе. Классификация и рубрицирование
Общие понятия Тезаурус (греч. – клад, сокровищница, запас) – словарь, отражающий смысловые связи между словами и иными смысловыми элементами языка. Тезаурус состоит из: – списка слов и устойчивых словосочетаний, сгруппированных по смысловым рубрикам; – «ключа» алфавитного словаря, где для каждого слова указаны соответствующие рубрики. Тезаурус позволяет определять семантические отношения иерархического и неиерархического (синонимия, антонимия, ассоциация) типов. Информационно-поисковым тезаурусом (ИПТ) называется тезаурус, предназначенный для ИПЯ. ИПТ позволяет: – однозначно переводить текст с ЕЯ на ИПЯ; – находить нужные дескрипторы для адекватного выражения информационной потребности; – обеспечивать возможность избыточного индексирования; – варьировать ПОЗ. Формальное определение тезауруса Тезаурусом называется непустое множество V слов v, отвечающее условиям: 1. Имеется непустое множество V0МV, называемое множеством дескрипторов. Множество V\V0 называется множеством аскрипторов. 2. Имеется симметричное транзитивное рефлексивное отношение R=VґV такое, что v1№v2Зv1Rv2 и (v1ОV\V0)È (v2ОV\V0) и v1ОV\V0и($vОV0)(vRv1), где R называется синонимическим отношением, v1 и v2 – синонимическими дескрипторами. 3. Имеется транзитивное и несимметричное отношение K = V0 ґ V0, называемое обобщающим отношением: если v1Kv2, то v1 – более общий, чем v2. Многозначному слову ЕЯ соответствует несколько дескрипторов, а нескольким синонимичным словам – один. ИС с тезаурусом называется четверка < V, D, M, d>, где V – тезаурус; D – коллекция документов; M – множество вопросов; d: M®2D – отображение, сопоставляющее каждому вопросу множество документов. Для dОD v(d)={v1, v2, …, vk} – описание документа. Никакие два дескриптора не встречаются в одном v(d), если они удовлетворяют отношению K. Можно считать, что вопрос mОM является ПОЗ. Вводят отношение включения " d1, d2ОD: v(d1) Таким образом, описание документа d1 включается в описание документа d2 в том и только том случае, если для любого слова из описания d1 можно подобрать слово из описания d2, тождественное ему или являющееся менее общим (более частным). Ответ на вопрос mОM представим следующим образом: Q = d(m) = {d: dОD З m То есть результатом выполнения запроса является множество документов, в каждый из которых запрос может быть включен. Классификация документов Во время поиска часто бывает важно получить по возможности наибольшее значение полноты, то есть выдать максимальную часть релевантных документов, имеющихся в массиве. Исчерпывающий поиск может понадобиться, например, экспертам организации, регистрирующей изобретения, которым необходимо составить обзор всех существующих патентов. Увеличение числа релевантных документов обычно приводит к выдаче дополнительных нерелевантных документов, то есть снижается его точность. Для улучшения полноты поиска необходимы дополнительные совпадения терминов запроса и документа. Это достигается использованием дополнительных терминов-заместителей. Термины-заместители либо добавляются к уже существующим терминам запросов и документов, либо используются вместо них. Наиболее известным методом здесь является применение словаря синонимов (тезауруса), в котором термины сгруппированы в классы синонимии (классы эквивалентности). С помощью тезауруса можно заменить каждый имеющийся в начальный момент поиска термин идентификаторами соответствующих классов тезауруса. При использовании другого подхода идентификаторы этих классов можно добавлять к исходным терминам. В любом случае цель состоит в том, чтобы получить дополнительные совпадения для тех терминов запроса и документа, которые отнесены к одним и тем же классам тезауруса. Сами эти термины могут быть и различными. В ИПС в основном применяется два типа классификаций: терминов и документов. Целью классификации терминов является группировка терминов в синонимические классы в расчете повысить вероятность совпадения терминов запроса и документа. Классификация документов способна улучшить результаты и оперативность поиска за счет обращения только к определенным частям информационного массива. Эти два типа классификаций взаимосвязаны: присваиваемые документам термины при формировании их поисковых образов служат основой для построения классов, получаемых в результате группировки документов. При хорошей классификации терминов обычно удается сгруппировать различные низкочастотные родственные термины в общие классы тезауруса. Термины, входящие в один класс, могут заменять друг друга в процессе поиска, следовательно, можно ожидать улучшения полноты выдачи. Классификации документов позволяют сузить область поиска до наиболее существенных классов документов и обеспечить высокую точность. При совместном использовании систематизированных массивов данных и тщательно проработанного тезауруса можно получить высокие показатели и по полноте, и по точности поиска. В основе любой классификации лежит принцип распределения информационных объектов (терминов или документов) по некоторым классам. Совокупность таких классов называется классификатором, а сами классы – разделами классификатора, или рубриками. Классификаторы обычно разрабатываются вручную. Примерами классификаций могут служить общепринятые библиотечные классификации УДК (универсальная десятичная классификация) и ББК (библиотечно-библиографическая классификация). Класс определяется как множество терминов, обозначающих некоторую предметную область. В процессе классификации каждому информационному объекту для обозначения его смыслового содержания (тематики) приписывается идентификатор какого-либо класса. Разбиение на предметные классы или рубрики должно быть предсказуемым, а подчиненные тематические классы легко отличимым от вышестоящих. От четкости такой иерархической структуры зависит эффективность регулирования глубины поиска путем расширения или сужения запроса. Маловероятно, чтобы можно было найти такую структуру, которая могла бы удовлетворять этим требованиям. Строго заданные иерархические отношения между тематическими классами призваны подчеркнуть определенные типы предметных ассоциаций и одновременно пренебречь другими. Статичный характер общепринятых классификационных схем порождает проблемы в случае расширение предметных областей и развития знаний. Существующие иерархические схемы весьма сложны, и на практике часто оказываются обязательными ручные (неавтоматические) процессы классификации. Это приводит к тому, что согласованности между разными системами классификации и поиска в процессах анализа содержания и распределения документов по рубрикам добиться трудно. В ИПС процесс классификации документов происходит во время их индексирования. Термины запроса распределяются по рубрикам классификатора непосредственно во время поиска. В обоих случаях документы и термины составляют множество классифицируемых объектов. Если множество объектов необходимо сопоставить множеству классов, обычно требуется, чтобы получающаяся при этом классификация обладала следующими свойствами: 1. Классификация должна быть корректно определенной так, чтобы для любого заданного множества данных получался один результат. 2. Результаты классификации не должны зависеть от порядка обработки объектов (независимость от порядка), то есть любая перестановка анализируемых объектов не должна влиять на результат классификации. 3. Классификация должна быть устойчивой: незначительные изменения данных должны вызывать незначительные изменения результатов классификации. 4. Классификация должна быть независимой от масштаба, поскольку умножение на константу значений характеристик, идентифицирующих объекты (идентификаторов классов), не должно влиять на классификацию. 5. Объекты, обладающие большим сходством, не должны оказываться отнесенными к разным классам. Первые два свойства (корректность определения и независимость от порядка) взаимосвязаны. Они могут быть обеспечены только при условии предварительного анализа всех возможных подмножеств объектов, удовлетворяющих классификационным критериям. Однако при большом количестве объектов, подлежащих классифицированию, такой исчерпывающий анализ может потребовать значительных затрат времени, что имеет место, например, в сети Интернет. Если первый и второй критерии не удовлетворяются, то особую важность приобретает критерий устойчивости классификации. Он гарантирует, что добавление новых свойств объектов, устранение уже выделенных свойств, а также исправление незначительных ошибок вызовут лишь незначительные изменения в самих классах. В классификациях, используемых в ИПС, обычно стараются получать устойчивые классы терминов и документов особенно потому, что векторы свойств, характеризующие объекты, не всегда точны и надежны. Это связано, например, с тем, что некоторые термины, несущие важную смысловую нагрузку, могут игнорироваться при автоматическом анализе содержания документов. Системы классификации имеют также ряд формальных свойств. Если все члены одного и того же класса обладают одним общим признаком, то классификация называется монотетической. В противном случае классификация становится политетической. Классы могут быть непересекающимися, где объекты относятся самое большее к одному классу, и пересекающимися. Наконец, классификация может быть упорядоченной путем установления систематических отношений между различными классами, а может быть и неупорядоченной. В процессе разработки и проектирования систем классификации во всех случаях предпочтительнее менее жесткие требования. Обычно ни документы, ни термины не бывают определены настолько точно, чтобы имело смысл строить монотетические классификации терминов или документов. По этой же причине наилучшими классами должны считаться пересекающиеся классы, чтобы элемент (термин или документ) мог включаться более чем в один класс. В некоторых случаях целесообразно создание либо упорядоченных классификаций терминов (иерархий терминов), либо упорядоченных классов документов. Однако, когда не налагается никаких специальных требований, неупорядоченная классификация, как правило, дает более адекватное деление на классы. Таким образом, в общем случае наиболее предпочтительными являются политетические пересекающиеся неупорядоченные классификации. В любой ИПС существует тесная взаимосвязь между индексированием и классификацией. Часто два этих процесса осуществляются параллельно. Целью классификации терминов является формирование для каждого термина дополнительных заместителей. Эти же термины используются и для идентификации документов. Представление и классификация документов в ИПС также связаны между собой. При индексации каждому документу обычно сопоставляется некоторый набор индексационных терминов. Поэтому фактически используемые термины непосредственно оказывают влияние как на классификацию терминов, так и на классификацию документов. Например, во время автоматической классификации документов определяется мера близости между классифицируемым документом и некоторым эталонным документом, который заведомо принадлежит какому-либо определенному классу. Эта мера часто вычисляется в зависимости от терминов, входящих в векторы этих документов. Поэтому классы документов непосредственно зависят от методов индексирования. Формирование рубрик Типичный процесс формирования рубрик (классов) включает три основных процесса (рис. 2.1).
Во время начального процесса происходит определение рубрик. Часто эта операция сводится к выбору (в качестве центра исходных классов) объектов, размещенных в плотных зонах пространства информационных объектов. Такими зонами обычно считаются те, в окрестностях которых имеется большое количество подобных объектов. В процессе распределения информационные объекты систематизируются и распределяются по имеющимся рубрикам путем отнесения объектов к тем классам, с которыми они имеют достаточно высокий коэффициент подобия. Завершающий этап связан с выполнением условий, при которых данный класс считается окончательным и полным. Здесь устанавливается, удовлетворяют ли сформированные рубрики заданному критерию классификации (например, обладают ли они описанными в предыдущем параграфе свойствами). Существует два основных метода классификации: 1. Порождающие методы классификации по принципу снизу вверх. 2. Методы разбиения по принципу сверху вниз. При использовании порождающих методов все объекты первоначально считаются несгруппированными. Формирование групп выполняется снизу вверх путем объединения объектов. Методы разбиения по принципу сверху вниз подразумевают, что все объекты первоначально относятся к одному глобальному классу. Затем этот класс разбивается на более мелкие подклассы, которые в свою очередь могут делиться на еще более мелкие подклассы вплоть до образования окончательных классов. В действующих системах также используется смешанный метод классифицирования по принципу сверху вниз. Количество исходных классов в таком случае задается заранее, и первоначальное деление объектов корректируется путем перегруппировки объектов. Целью перегруппировки является повышение качества рубрик таким образом, чтобы связанность классов стала максимальной, а подобие объектов, относящихся к разным группам, – минимальным. Большая часть методов классификации по принципу сверху вниз устроена таким образом, что они могут использоваться и для образования иерархических структур классов. При поуровневом построении классификации формируются классы, являющиеся подмножествами или компонентами какого-либо класса более высокого уровня. В результате образуется структура в виде дерева. Корень такого дерева (верхний уровень) содержит глобальный класс высшего уровня, представляющий все информационное пространство. Листья (нижний уровень) соответствуют конечным рубрикам документов или группам терминов. При некоторых методах классификации по принципу снизу вверх также формируются иерархические структуры. Неиерархическими структурами считаются такие структуры, в которых между сформированными классами не выполняются свойства формального включения. При построении иерархии классов терминов в виде дерева часто стараются в нижней части помещать узкие специфичные термины, а в верхней – термины более общего характера. На практике особенно во время ручной классификации часты случаи, когда документ или термин может быть одновременно отнесен к нескольким классам. В таких ситуациях используются различные перекрестные ссылки. Информация о документах данной тематической направленности помещается в некоторый базовый раздел, а остальные классы, к которым также можно было бы отнести эти документы, содержат соответствующие ссылки. В описание пересекающихся классов добавляют ссылку типа «смотри», которая направляет пользователя к рубрике, признанной специалистами по классификации базовой. Например, информация о картах стран может быть размещена в разделах «Наука–География–Страна», «Экономика–География–Страна» или «Справочники–Карты–Страна». Специалисты по классификации принимают решение о том, что сведения о картах стран размещаются в рубрике «Экономика–География–Страна». Тогда в остальные два раздела добавляется ссылка на данный. Если выбор базового класса вызывает у специалистов по классификации затруднения, то вероятность отнесения объекта к тому или иному похожему (синонимическому) классу практически одинакова. В этих случаях применяются ссылки типа «смотри также». Они направляют пользователей системы к разделам, которые, возможно, содержат описания интересующих их документов. |
Последнее изменение этой страницы: 2019-06-09; Просмотров: 277; Нарушение авторского права страницы
 :
: 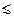 v(d2) у(" v'Оv(d1))ґ($v''Оv(d2)) (v'Kv'')И(v'=v'')
v(d2) у(" v'Оv(d1))ґ($v''Оv(d2)) (v'Kv'')И(v'=v'')