|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Правила нормализации. Первая, вторая, третья, четвертая нормальные формы. ⇐ ПредыдущаяСтр 4 из 4
Нормализация отношений
Первая нормальная форма Отношение называется приведенным к первой нормальной форме, если все его атрибуты простые. Первая нормальная форма предписывает, что все данные, содержащиеся в таблице, должны быть атомарными (неделимыми). Правило означает, что в каждом поле каждой записи должна находиться только одна величина, но не массив и не какая-либо другая структура данных.
Так как значение поля Оценки не является атомарным, таблица не соответствует требованиям 1НФ.
Вторая нормальная форма Отношение находится во второй нормальной форме, если оно находится в первой нормальной форме и значения в каждом неключевом атрибуте однозначно определяются значением первичного ключа. Другими словами, значение каждого поля должно полностью определяться значением первичного ключа. Важно отметить, что зависимость от первичного ключа понимается именно как зависимость от ключа целиком, а не от отдельной его составляющей (в случае составного ключа). Приведем пример таблицы, которая не находится во 2НФ.
Как мы помним, данная таблица имеет составной ключ Дата+Время суток. Поле Температура полностью зависит от первичного ключа — с ним проблем нет. А вот поле Восход зависит лишь от поля Дата, Время суток на время восхода естественным образом не влияет. Здесь уместно задаться вопросом: а в чем практический смысл 2НФ? Какая польза от этих ограничений? Оказывается — большая. Допустим, что в приведенном выше примере разработчик проигнорирует требования 2НФ. Во-первых, скорее всего возникнет так называемая избыточность — хранение лишних данных. Ведь если для одной записи с данной датой уже хранится время восхода, то для всех других записей с данной датой оно должно быть таким же и хранить его, вообще говоря, незачем. Третья нормальная форма Отношение находится в третьей нормальной форме, если оно находится во второй нормальной форме и все неключевые атрибуты не зависят друг от друга. Взаимную зависимость столбцов удобно понимать следующим образом: столбцы являются взаимно зависимыми, если нельзя изменить один из них, не изменяя другой. Приведем пример таблицы, которая не находится в 3НФ. Рассмотрим пример простой записной книжки для хранения домашних телефонов людей, проживающих, возможно, в различных регионах страны. В этой таблице присутствует зависимость между не ключевыми столбцами Город и Код города, следовательно, таблица не находится в 3НФ. Четвертая нормальная форма Отношение находится в четвертой нормальной форме, если оно находится в третьей нормальной форме и если в нем не содержатся независимые группы атрибутов, между которыми существует отношение «многие-ко-многим». В теории реляционных баз данных рассматриваются и формы высших порядков — нормальная форма Бойса — Кодда, 4НФ, 5НФ и даже выше. Большого практического значения эти формы не имеют, и разработчики, как правило, всегда останавливаются на 3НФ. Правила целостности БД. Индексация.
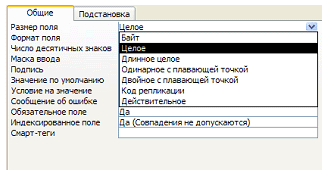
Реляционная модель определяет два общих правила целостности базы данных: целостность объектов и ссылочная целостность. Правило целостности объектов очень простое. Оно требует, чтобы первичные ключи таблиц не содержали неопределенных (пустых) значений. Правило ссылочной целостности требует, чтобы внешние ключи не содержали несогласованных с родительскими ключами значений. Возвращаясь к рассмотренному выше примеру, мы должны потребовать, например, чтобы ученики относились лишь к классу, номер которого указан в таблице “Классы”. Большинство СУБД умеют следить за целостностью данных (разумеется, это требует соответствующих усилий и от разработчика на этапе описания структур данных). В частности, для поддержания ссылочной целостности используются механизмы каскадирования операций. Каскадирование подразумевает, в частности, то, что при удалении записи из “родительской” таблицы, связанной с другой таблицей отношением “один ко многим”, из таблицы “многих” автоматически (самой СУБД, без участия пользователя) удаляются все связанные записи. И это естественно, ведь такие записи “повисают в воздухе”, они более ни с чем не связаны. Индексация Индексация — крайне важная с точки зрения практического применения. Основное назначение индексации — оптимизация (убыстрение) поиска (и, соответственно, некоторых других операций с базой данных). Индексация в любом случае требует дополнительных ресурсов (на физическом уровне чаще всего создаются специальные индексные файлы). Операции, связанные с модификацией данных, индексация может даже замедлять, поэтому индексируют обычно редко изменяемые таблицы, в которых часто производится поиск. Индексный файл очень похож на индекс обычной книги. Для каждого значения индекса хранится список строк таблицы, в которых содержится данное значение. Соответственно, для поиска не надо просматривать всю таблицу — достаточно заглянуть в индекс. Зато при модификации записей может потребоваться перестроить индекс. И на это уходит дополнительное время. Типы данных Когда говорят о свойствах сущности (объекта), явно или неявно имеют в виду, что каждое конкретное свойство (в таблице — поле записи) принимает значения из некоторого множества. Указанное множество и называется типом данных. Все реляционные СУБД поддерживают данные следующих основных типов: · числовые; · строковые; · логические; · даты. Приведенный список не является исчерпывающим. Как правило, СУБД также имеют типы для хранения больших текстовых и двоичных данных, специальные “денежные” типы и т.д. На следующем рисунке — снимке экрана конструктора таблиц Microsoft Access — показаны типы, поддерживаемые этой системой.
Отметим также, что, как правило, типы могут снабжаться модификаторами, уточняющими соответствующее множество данных (диапазон значений). Например, в Microsoft Access данные числового типа могут быть просто “целыми”, “длинными целыми”, “вещественными” и т.д. — см. рисунок.
11.Правила Кодда (требования к реляционным БД)
Большинство СУБД, распространённых на ПК, принято считать реляционными, хотя они таковыми не являются в полной мере. Кроме представления данных в виде двумерных таблиц, принадлежность к разряду реляционных систем определяется рядом признаков, сформулированных Коддом, получивших название правил Кодда. Перечислим эти правила: 1) Явное представление данных. Все данные должны быть представлены явно и их значения должны рассчитываться косвенными алгоритмами (исключение – однозначные отображения). Пример: если, явно не указан пол, то его нельзя (ошибочно) получать из фамилии, т.к. различные алгоритмы интерпретации фамилии в различных приложениях могут вызвать противоречия (нарушить целостность) в БД. Для явного представления нужны типы: числа, строки, даты, время и т.д. 2) Гарантированный доступ к данным. Вся информация в БД должна быть доступной для приложения. Выделение любого значения в РБД выполняется при указании: а) имени отношения; б) указателя на кортеж (например, значение первичного ключа кортежа); в) имени атрибута; ( имя_отношения, первичный ключ, атрибут) 3) Полная обработка неопределенных значений. Неопределенные значения, отличные от любого определенного значения, должны поддерживаться для всех типов данных при выполнении всех операций. 4) Доступ к базе данных в терминах реляционной модели. Описание БД (перечень отношений, определения схем отношений и ключей, статистическая информация и т.д.) должно быть выполнено на реляционном языке. Пользователь должен иметь доступ к этой информации с помощью реляционного языка. Т.е. должна быть возможность администрирования баз данных независимо от приложений. 5) Полнота подмножества реляционного языка. Реляционная схема может поддерживать несколько языков, по крайней мере, язык DDL и DML. Однако хотя бы один из языков должен иметь синтаксис предложений, поддерживающий следующие понятия: - определение данных (отношения, атрибуты, домены, ключи, ограничения целостности); - определение виртуальных (мнимых) отношений образованных с помощью реляционных выражений на основе одного или нескольких отношений (определение представлений); - манипулирование данными (интерактивное или программное); - ограничение целостности; - санкционированный доступ; - управление транзакциями (начало транзакции, фиксация выполнения, отказ от выполнения).
6) Обновляемость представлений. Все представления (виртуальные отношения) должны автоматически обновляться при модификации данных в базовых отношениях. Если, например, A= R È S, и А – это представление, то А должно обновляться как только меняется R или S. 7) Наличие высокоуровнего языка манипулирования данными. Операции вставки, обновления и удаления должны применяться к отношению в целом: обеспечивая контроль над целостностью базы данных при модификации отношений. При выполнении вставки над отношением в целом легко проверить уникальность первичного ключа, ограничения на значения и пр. 8) Физическая независимость данных. Прикладные программы не должны зависеть от используемых способов хранения данных на носителях информации и методов доступа к ним. Физически независимые обеспечивает работоспособность приложений при изменении расположения данных в сети. 9) Логическая независимость данных. Прикладные программы не должны зависеть от реализации любого из используемых представлений (виртуальных отношений). Определив виртуальные отношение в рамках БД, можно разрабатывать приложения, использующие это отношение, не беспокоясь о том, что структура БД изменится и виртуальные отношение будет строиться на основе другого реляционных выражения. 10) Независимость контроля целостности. Все ограничения целостности и внешнее представления (виртуальные отношения, отчеты) должны определяться не в приложениях, а должны быть определены с помощью языка определения данных и сохранения в каталоге (словаре) базы данных. 11) Дистрибутивная независимость. Реляционная система должна быть распространяема и переносима. Создание разнородных компьютерных систем требует обеспечения доступа к базам данных в различных OS и на различных платформах. Дистрибутивная независимость предполагает полную реализацию СУБД для различных платформ или реализацию коммуникационных блоков в составе СУБД, позволяющих обмениваться данными различным СУБД. 12) Согласования языковых уровней. Если реляционная система имеет низкоуровневый язык доступа (элемент доступа – запись) и высокоуровневый язык доступ (элемент доступа – отношения). То выполнение низкоуровневых команд должно производиться с контролем целостности, так же как и при высокоуровневых командах.
12.Формализация даталогической модели на языке конкретной СУБД(на примере Ассess) После того, как структура БД определена, требуется формализовать даталогическую модель на языке конкретной СУБД, иначе говоря — описать таблицы. Большинство современных СУБД предоставляют для этой цели удобные визуальные конструкторы (например, выше мы уже упоминали о конструкторе таблиц Microsoft Access). Описание (конструирование) каждой таблицы включает: · Определение имени таблицы. Если таблица является представлением некоторой сущности, то имя обычно соответствует названию сущности. Имена таблиц связей, как правило, образуют из названий связываемых сущностей. · Определение имен и типов полей. На этом же этапе обычно требуется установить специфические свойства конкретных полей — может ли поле содержать “пустые” (неопределенные) значения, каким должно быть значение “по умолчанию” и т.д. · Определение первичного ключа. Несмотря на то, что реляционная модель требует наличия в каждой таблице первичного ключа, большинство СУБД позволяют не определять ключ в таблице. Этого, разумеется, следует избегать. К чести СУБД они практически всегда стараются “наставить разработчика на путь истинный” (см., например, рисунок).
· Определение (при необходимости) индексированных полей. После конструирования таблиц необходимо установить связи между ними. В Microsoft Access для этого имеется специальное средство — “Схема данных”. На схеме очень удобно “рисовать” связи между таблицами, перетаскивая и накладывая друг на друга связанные поля. В большинстве случаев Access способен определить тип устанавливаемой связи. Например, если первичный ключ одной таблицы связывается с полем другой, не являющимся первичным ключом, то легко понять — и Access понимает, — что речь идет о связи “один ко многим”.
Схожие по функциям и интерфейсу средства визуального конструирования имеют и другие СУБД. Какой бы визуальный интерфейс не предоставляла конкретная СУБД разработчикам, в подавляющем большинстве случаев за кадром находится общий для всех реляционных СУБД язык SQL ( S tructured Q uery L anguage). Понятно, что указанную возможность можно обеспечить лишь при наличии некоторого общего системонезависимого ядра, каковым и является SQL.)
13.Объекты базы данных. Таблицы, отчеты, страницы, макросы и модули. Запросы и формы. БД может содержать разные типы объектов. Каждая СУБД может реализовывать свои типы объектов. Таблицы – основные объекты любой БД, в которых хранятся все данные, имеющиеся в базе, и хранится сама структура базы (поля, их типы и свойства). Отчеты – предназначены для вывода данных, причем для вывода не на экран, а на печатающее устройство (принтер). В них приняты специальные меры для группирования выводимых данных и для вывода специальных элементов оформления, характерных для печатных документов (верхний и нижний колонтитулы, номера страниц, время создания отчета и другое). Страницы или страницы доступа к данным – специальные объекты БД, выполненные в коде HTML, размещаемые на web -странице и передаваемые клиенту вместе с ней. Сам по себе объект не является БД, посетитель может с ее помощью просматривать записи базы в полях страницы доступа. Т.о., страницы – интерфейс между клиентом, сервером и базой данных, размещенным на сервере. Макросы и модули – предназначены для автоматизации повторяющихся операций при работе с системой управления БД, так и для создания новых функций путем программирования. Макросы состоят из последовательности внутренних команд СУБД и являются одним из средств автоматизации работы с базой. Модули создаются средствами внешнего языка программирования. Это одно из средств, с помощью которых разработчик БД может заложить в нее нестандартные функциональные возможности, удовлетворить специфические требования заказчика, повысить быстродействие системы управления, уровень ее защищенности. • Запросы и формы. Запросы – служат для извлечения данных из таблиц и предоставления их пользователю в удобном виде. С их помощью выполняют отбор данных, их сортировку и фильтрацию. Можно выполнить преобразование данных по заданному алгоритму, создавать новые таблицы, выполнять автоматическое заполнение таблиц данными, импортированными из других источников, выполнять простейшие вычисления в таблицах и многое другое. Особенность запросов состоит в том, что они черпают данные из базовых таблиц и создают на их основе временную результирующую таблицу(моментальный снимок) – образ отобранных из базовых таблиц полей и записей. Работа с образом происходит быстрее и эффективнее, нежели с таблицами, хранящимися на жестком диске. Обновление БД тоже можно осуществить посредством запроса. В базовые таблицы все данные вносятся в порядке поступления, т.е. они не упорядочены. Но по соответствующему запросу можно получить отсортированные и отфильтрованные нужным образом данные. Формы – средства для ввода данных, предоставляющие пользователю необходимые для заполнения поля. В них можно разместить специальные элементы управления (счетчики, раскрывающиеся списки, переключатели, флажки и прочее) для автоматизации ввода. Пример, заполнение определенных полей бланка. При выводе данных с помощью форм можно применять специальные средства их оформления. 14.Язык SQL ( структурированный язык запросов ).История возникновения. Подмножества языка. Из истории SQL: Все реляционные СУБД поддерживают специальный язык SQL ( S tuctured Q uery L anguage), на котором записываются запросы. Фактически SQL состоит из двух языков — DML ( D ata M anipulation L anguage) и DDL ( D ata D eclaration L anguage). История языка SQL началась в 1974 г. Первый прототип языка назывался SEQUEL (название образовано от S tructured E nglish Que ry L anguage). Впоследствии переработанная версия SEQUEL получила название SQL. Первый стандарт языка был принят в 1987 г. SQL — декларативный язык. Это означает, что клиент лишь указывает, что именно ему требуется, а как это получить, решает сама СУБД. Необходимо сказать, что хотя SQL и задумывался как средство работы конечного пользователя, в конце концов он стал настолько сложным, что превратился в инструмент программиста. В SQL определены два подмножества языка: Популярное:
|
Последнее изменение этой страницы: 2016-03-17; Просмотров: 4359; Нарушение авторского права страницы