
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Косвенная регистровая адресация
Рисунок 2.26 – Косвенная регистровая адресация
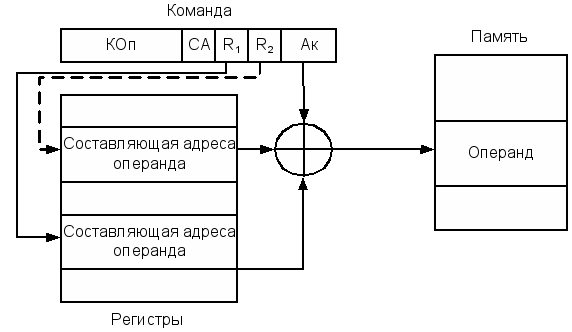
Адресация со смещением
Адресация со смещениемпредполагает, что адресная часть команды включает в себя как минимум одно поле (Ак). В нем содержится константа, смысл которой в разных вариантах адресации со смешением может меняться. Константа может представлять собой некий базовым адрес, к которому добавляется хранящееся в регистре смещение. Допустим и прямо противоположный подход: базовый адрес находится в регистре процессора, а в поле Ак указывается смещение относительно этого адреса. В некоторых процессорах для реализации определенных вариантов адресации со смешением предусмотрены специальные регистры, например базовый или индексный. Использование таких регистров предполагается по умолчанию, поэтому адресная часть команды содержит только поле Ак. Если же составляющая адреса может располагаться в произвольном регистре общего назначения, то для указания конкретного регистра в команду включается дополнительное поле R (при составлении адреса более чем из двух составляющих в команде будет несколько таких полей). Еще одно поле Я может появиться в командах, где смещение перед вычислением исполнительного адреса умножается на масштабный коэффициент. Такой коэффициент заносится в один из РОН, на который и указывает это дополнительное поле. В наиболее общем случае адресация со смещением подразумевает наличие двух адресных полей: Ак и R. Общая схема адресации со смещением представлена на рисунке 2.26. Рисунок 2.26 –Адресация со смещением Ниже рассматриваются основные способы адресации со смещением, каждый из которых, впрочем, имеет собственное название.
Базовая регистровая адресация
Более типичен случаи, когда в роли базового регистра выступает один из регистров общего назначения, тогда его номер явно указывается в подполе Rкоманды. Базовую регистровую адресацию обычно используют для доступа к элементам массива, положение которого в памяти в процессе вычислений может меняться. В базовый регистр заносится начальный адрес массива, а адрес элемента массива указывается в подполе АСкоманды в виде смещения относительно печатного адреса массива. Достоинство данного способа адресации в том, что смещение имеет меньшую длину, чем полный адрес, и это позволяет сократить длину адресного поля команды. Короткое смешение расширяется до полной длины исполнительного адреса путем добавления слева битов, совпадающих со значением знакового разряда смешения.
Индексная адресация
Индексная адресация предоставляет удобный механизм для организации итеративных вычислении. Пусть, например, имеется массив чисел, расположенных и памяти последовательно, начиная с адреса N и мы хотим увеличить на единицу все элементы данного массива. Для этого требуется извлечь каждое число из памяти, прибавить к нему 1 и вернуть обратно, а последовательность исполнительных адресов будет следующей: N, N+1, N+2,..., вплоть до последней ячейки, занимаемой рассматриваемым массивом. Значение Nберется из подполя АС команды, а и выбранный регистр, насыпаемый индексным регистром, сначала заносится 0. После каждой операции содержимое индексного регистра увеличивается на 1. Taк как это довольно типичныйслучаи, и большинстве ЭВМ увеличение или уменьшение содержимого индексного регистра до или после обращения к нему осуществляется автоматически как часть машинного цикла. Такой прием называется автоиндексированием. Если для индексном адресации используются специально выделенные регистры, автоиндексирование может производиться неявно и автоматически. При задействовании для хранения индексов регистров общего назначения необходимость операции автоиндексировання должна указываться в команде специальным битом. Автоиндексирование с увеличением содержимого индексного регистра носит название автоинкрементной адресации и может быть описано следующим образом: Аналогично реализуется автоиндексирование с уменьшением содержимого индексного регистра. Оно носит название автодекрементной адресации. Здесь также возможны два варианта, отличающиеся последовательностью выполнения операции уменьшения содержимого индексного регистра и вычисления исполнительного адреса; постдекрементное автоиндексирование и предекрементное автоиндексирование Интересным и весьма полезным является еще один вариант индексной адресации — индексная адресация с масштабированием и смещением: содержимое индексного регистра умножается на масштабный коэффициент и суммируется с АС. Масштабным коэффициент может принимать значения 1, 2, 4 или 8. для чего в адресной части команды выделяется дополнительное поле. Описанный способ адресации реализован, например, в микропроцессорах фирмы Intel. Следует особо отметить, что система команд многих ЭВМ предоставляет возможность различным образом сочетать базовую и индексную адресации в качестве дополнительных способов адресации.
Блочная адресация
11. Законы Амдала и Густафсона. DOP (Degree Of Parallelism) Степень параллелизма программы – D(t) – число процессоров, участвующих в исполнении рограммы в момент времени t DOP зависит от алгоритма программы, эффективности компиляции и доступных ресурсов при исполнении График D(t) – профиль параллелизма программы
T(n) – время исполнения программы на n процессорах
T(n)< T(1), если параллельная версия алгоритма эффективна T(n)> T(1), если накладные расходы (издержки) реализации параллельной версии алгоритма чрезмерно велики
Speedup Ускорение за счёт параллельного выполнения S(n) = T(1) / T(n)
Efficiency Эффективность системы из n процессоров E(n) = S(n) / n
Случай S(n)=n – линейное ускорение – масштабируемость (Scalability) алгоритма (возможность ускорения вычислений пропорционально числу процессоров)
Случай S(n)> n – суперлинейное ускорение (например, из-за большего коэффициента кеш-попаданий)
Закон Амдала Gene Amdahl (1967) f – доля последовательной части программы 1-f – доля распараллеливаемой части программы
Практические ограничения ускорения
Джин Амдал сформулировал закон в 1967 году, обнаружив простое по существу, но непреодолимое по содержанию ограничение на рост производительности при распараллеливании вычислений: «В случае, когда задача разделяется на несколько частей, суммарное время ее выполнения на параллельной системе не может быть меньше времени выполнения самого длинного фрагмента». Если разделяемая часть кода f может быть равномерно формально распределена по n процессорам, то закономерность может быть записана, как представлено на рис. 1.
Закон определяет теоретически возможную верхнюю границу, но на практике дело обстоит еще хуже – часть ресурсов каждого процессора уходит на обеспечение коллаборативной работы, а шины обладают конечной пропускной способностью.
Закон Густафсона Единственная известная гипотеза о возможности преодоления описанных ограничений была высказана в 1988 году Джоном Густафсоном, но она не распространяется на подмножество фиксированных задач. На основании полученного опыта Густафсон пришел к выводу, что при построении более мощных систем пользователи стремятся не сократить время работы текущей версии задачи, а перейти к новой версии, обеспечивающей более высокое качество решения:
S(P)= P – l(P – 1), где P – число процессоров, S – ускорение, l – часть кода, не поддающаяся распараллеливанию.
Закон масштабируемого ускорения (Scaled Speedup):
Допустим, некоторую конструкцию можно рассчитать методом конечных элементов, и в таком случае, чем меньшим берется размер элемента, тем выше будет точность. Сегодня идеи Густафсона, связанные с совершенствованием методов коммуникации между узлами, реализуются в компании Massively Parallel Technologies (MPT), где, кстати, работает и сам Амдал. Допустимо сказать, что эти методы позволяют преодолеть ограничения закона, названного его именем, но только косвенно.
Принцип замены простых задач более сложными, предложенный Густафсоном, скорее экзотика, чем повседневная практика, поэтому в массовых приложениях, на которые рассчитываются многоядерные процессоры, действует закон Амдала.
Популярное:
|
Последнее изменение этой страницы: 2016-03-25; Просмотров: 3245; Нарушение авторского права страницы

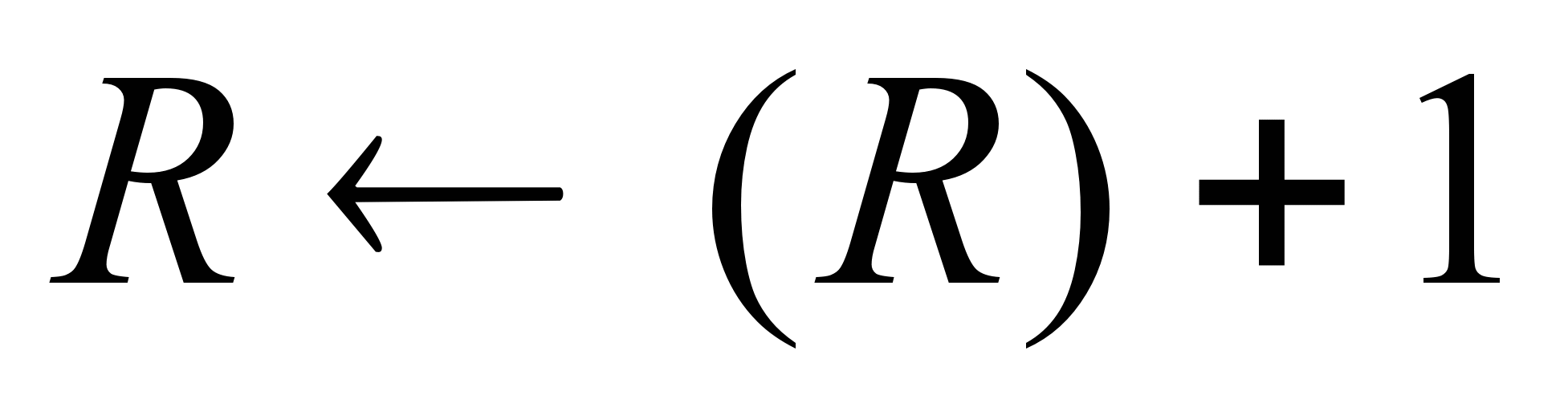 или
или 




