|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
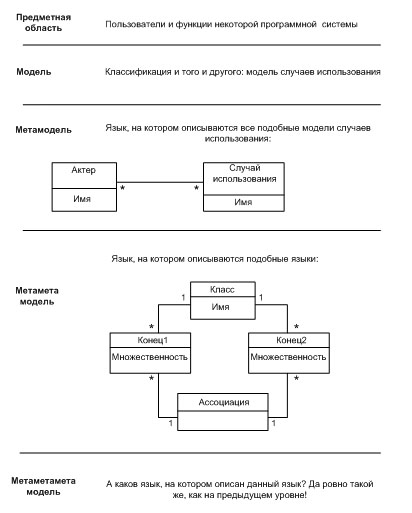
Предметная область, модель, метамодель, метаметамодель.
При визуальном моделировании программного обеспечения используются следующие уровни абстракции:
Для визуального моделирования в качестве предметной области (domain) обычно выступает:
Модель (model) - это упрощенное описание предметной области, созданное для удобства выполнения там действий, работы. Более простая модель дает возможность не рассматривать все бесконечное многообразие предметной области, а сосредоточиться лишь на некоторых ее свойствах. Например, для создания информационной системы автоматизации предприятия строится модель предприятия, которая фокусируется на бизнес-процессах, потоках данных, бизнес-ролях. В эту модель не входит следующая информация о предприятии: межличностные отношения сотрудников, детали планировки помещений офисов, расписание работы компании (начало работы, обеденный перерыв, выходные) и т. д. При визуальном моделировании ПО обычно строятся следующие модели.
Модели анализа должны " плавно" переходить в модели проектирования, и это является одним из главных принципов модельно-ориентированного подхода к разработке ПО. В индустриальном производстве создание той или иной модели - это не единичный прецедент. Например, люди, специализирующиеся на разработке информационных систем, создают много моделей разных компаний. Соответственно, у них возникает потребность в специальном языке, который существенно упростил бы разработку таких моделей. Этот язык должен содержать описание всех тех абстракций, которые обычно нужны при моделировании деятельности предприятий. Само множество этих моделей оказывается предметной областью для новой модели, которую поэтому естественно называть метамоделью (metamodel). В рамках одной области деятельности может быть востребовано много разных модельных языков, и тогда необходим общий способ по их разработке и спецификации. В этом случае оказывается востребованным язык описания языков (метамоделей) - метаметамодель (meta-metamodel). Предметной областью для этой новой модели являются соответствующие метамодели. Теоретически, приведенную выше цепочку метауровней можно продолжать бесконечно. Каждый следующий уровень будет служить моделью для предыдущего, а предыдущий уровень оказывается для него предметной областью, как показано на рис.2.6.
Переход на следующий метауровень целесообразен лишь тогда, когда на некотором уровне появляется много сходных объектов, нуждающихся в структурировании, а, значит, в метаописании. В какой-то момент будет достигнут предел по количеству объектов, требующих унификации и упорядочивания. На рис.2.7 приведен пример четырех метауровней с кратким обоснованием, почему пятый уровень и далее не нужны.
Есть и объективная предпосылка к тому, что пятый уровень оказывается вырожденным, безотносительно тому, какие средства используются для создания метаметамодели. Дело в том, что не существует большого множества средств для задания метамоделей визуальных языков. И поэтому не возникает задачи по структурированию и упорядочиванию таких способов путем разработки для них общей модели. То есть метаметаметамодель не требуется… Язык UML, являясь, очевидно, метамоделью, описан с помощью своего подмножества - диаграмм классов. Это подмножество стандартизовано OMG в качестве стандартной метаметамодели как универсальное средство описания различных метамоделей и названо MOF (Meta Object Facility). С его помощью описываются такие стандарты OMG, как Common Warehouse Metamodel (CWM), СORBA Component Model (CCM) и др. (OMG®, founded in 1989, is an international, open membership, not-for-profit computer industry consortium with more than 500 members worldwide, including government agencies, small and large IT users, vendors and research institutions. OMG is most known for its standards development work. OMG Task Forces develop enterprise integration standards for a wide range of technologies, including: Real-time, Embedded and Specialized Systems, Analysis and Design, Architecture-Driven Modernization and Middleware; and for more than two-dozen vertical industries, including: Business Modeling and Integration, C4I for Military and Crisis Response, Finance, Government, Healthcare, Regulatory Compliance, Life Sciences Research, Knowledge Management, Software Assurance, Manufacturing Technology, Robotics, Software-Based Communications and Space. Over time, OMG has evolved to meet the changing business needs of Information Technology by playing a strong role as a builder of practitioner-driven Communities of Practice focused on Green/Sustainability, Service Oriented Architecture, BPM, Cyber Security and Event Processing, while staying true to its standards development roots.)
Множество моделей ПО Выше уже говорилось, что модели ПО обычно бывают или моделями анализа, или моделями проектирования. На самом деле моделей оказывается значительно больше, правда, не все они визуализируются. Посмотрим, почему их оказывается много. Прежде всего, модели в проекте " множатся" из-за разных видов деятельности процесса разработки ПО (рис.2.8). При анализе на ПО смотрят как на то, что реализует определенную бизнес-функциональность, нужную заказчику. При этом несущественными оказываются принципы и детали реализации. При проектировании, наоборот, на первое место выходят принципы реализации ПО. А при тестировании детали реализации снова неважны - на ПО смотрят как на черный ящик, реализующий (не важно каким способом) некоторый набор пользовательской функциональности. При развертке у заказчика на ПО смотрят как на набор файлов, хранилищ данных и т. д.
Далее, в разработку/использование ПО вовлечено большое количество очень разных специалистов: программисты, инженеры, тестеры, технические писатели, менеджеры, заказчик, пользователи, продавцы-маркетологи и т. д. (рис.2.9). Для всех этих специалистов нужна разная информация о программной системе. Представьте, что произойдет, если, например, продавцу или заказчику-непрограммисту в ответ на просьбу получше ознакомиться с ПО вы дадите почитать программные коды…
Большое количество конфликтов и трудностей в проектах возникает просто из-за того, что одни специалисты не могут понять других. Например, частой является ситуация, когда инженерам по аппаратуре трудно понять программистов, которые создают ПО, взаимодействующее с этой аппаратурой. Программисты объясняют алгоритмы работы своих программ в терминах процедур, переменных, классов и т. д. И наоборот, инженеры " заваливают" программистов деталями реализации и функционирования своих устройств. Другой пример - очень часто технические писатели, создающие пользовательскую документацию для ПО, плохо разбираются в том программном обеспечении, которое они описывают. И документация получается никуда не годной, для галочки. Еще пример: менеджеры (особенно высокопоставленные, в больших проектах) часто не понимают реальных проблем проекта и склонны " расхлебывать" то, что уже произошло, а не реагировать на первые признаки неурядиц. Подобные проблемы легче разрешаются, если в проекте существуют или могут быть созданы по требованию разные модели, предназначенные для различных специалистов, на которых в доступной форме и без лишних деталей представлена нужная информация. Итак, разные виды деятельности при разработке ПО и разные категории специалистов, задействованные в программном проекте, - все это приводит к созданию и использованию различных моделей, выполненных с разных точек зрения. Точка зрения моделирования (viewpoint) - это определенный взгляд на систему, который осуществляется для выполнения какой-то определенной задачи кем-либо из участников проекта. Далее будут рассматриваться только визуальные модели ПО, хотя многое из сказанного ниже справедливо также и для произвольных моделей. На первый взгляд, введенное выше определение очевидно и ничего нового не привносит. Например, при создании различных инженерных объектов активно используется эта же концепция - принципиальная схема, монтажная схема, генеральный план, различные проекции и " разрезы" деталей, зданий и пр. Все это является моделями создаваемой системы, выполненными с разных точек зрения. Однако в обычных инженерных областях есть стандартные, зафиксированные точки зрения на систему, и им соответствуют стандартные же модели. Например, электрик при создании электропроекта жилого дома не изобретает различные виды чертежей и описаний, а руководствуется существующими нормативами (в России это свод документов, называемый ПУЭ - Правила Устройства Электроустановок). То же самое касается и проектировщиков зданий, конструкторов автомобилей, самолетов и т. д. В случае с визуальным моделированием ПО таких стандартизированных видов моделей, к сожалению, не существует. Есть, конечно же, типы диаграмм в UML, но какие из них и когда использовать, какую часть системы с их помощью " прорисовывать" - решать самим разработчикам. Более того, само разбиение UML на разные типы диаграмм условно - диаграммы можно смешивать. Забегая вперед, заметим, что, например, диаграммы объектов UML предназначены для моделирования фрагментов системы, и сразу появляется вопрос - каких именно фрагментов? Решать приходится разработчикам, использующим эти диаграммы. Далее, существует очень много разных стратегий по созданию диаграмм случаев использования (use case diagrams): одни авторы считают, что нужно создавать не много случаев использования, (даже для крупных систем), другие предпочитают строить огромные " полотна", одни считают, что не нужно подробно изображать окружение системы на этих диаграммах (только тех актеров, которые непосредственно взаимодействуют с системой), другие, наоборот, считают это важным и т. п. Какой из этих способов избрать, или создать свой собственный, - опять-таки решать разработчикам конкретной системы. Один из классиков визуального моделирования, Грэди Буч, многократно подчеркивал в своих книгах, что его метод - это не поварская книга готовых рецептов. Создание полезных визуальных моделей является более сложным делом, чем создание чертежей и спецификаций в других инженерных областях. И правильно выбранная и ясно сформулированная точка зрения на систему, которая не " плывет" при моделировании, - это один из основных критериев того, что модель действительно принесет пользу. Важнейшими характеристиками точки зрения моделирования является цель (зачем создается модель) и целевая аудитория (то есть для кого она предназначается). Важным вопросом, на который нужно честно себе ответить в самом начале моделирования - это зачем вы используете UML. Это и есть определение цели моделирования. Потому что так создавать модели правильнее? И все проблемы (даже те, о которых ничего еще не известно) волшебным образом исчезнут, развеются? Очень часто, например, при создании модели случаев использования присутствует именно такая " цель" моделирования. А потом оказывается, что никакие проблемы не " вылечились", а наоборот, возникли новые (например, созданные нами диаграммы никто не понимает и не принимает). Да и сам аналитик чувствует, что диаграммы получились какие-то странные…. А может все происходить совсем не так. Например, аналитик действительно задался целью выявить требования к системе - не навязать свое собственное видение другим, а выяснить нужную информацию, смоделировать и изложить ее доступно. Для этого он и использует диаграммы случаев использования. Ему важно, чтобы будущие пользователи системы могли участвовать в этом процессе, диаграммы рисуются для них, они понятны и не избыточны. И эти же диаграммы структурируют и проясняют информацию для самого аналитика. Типична ситуация, когда UML используется, чтобы создавать модели ПО " вообще" - потому что так правильно, потому что люди недавно узнали, что такое UML и т.д. В этом случае какая-то точка зрения при моделировании все-таки есть, но она, как правило, не осознается авторами таких описаний. Цели моделирования расплывчаты и туманны, а люди, которым предназначены данные модели, вообще " потеряны". В результате такие диаграммы никому не нужны, а средства, затраченные на их создание, оказываются выброшенными на ветер. Важно понимать, что цель модели - это не какая-то гипотетическая задача типа " описания архитектуры, потому, что создавать модели правильно? ", а целевая аудитория - это не абстракция типа " люди, желающие познакомиться с ПО". И то и другое - что-то очень конкретное, реально существующее в проекте или рядом с ним. Ведь разработчики ПО не могут позволить себе за деньги заказчика создавать нечто на все века и для всех народов. И цель моделирования, и аудитория, которая будет работать с диаграммами, всегда существуют, важно лишь ясно понимать, какие они… Вот полезный практический прием для фокусировки на целевую аудиторию, для которой предназначена создаваемая вами модель. Можно выбрать одного представителя такой аудитории - конкретного и известного вам человека - и создавать диаграммы, понятные именно ему. При этом важно не обсуждать чрезмерно с ним ваши модели, поскольку это может создать дополнительный контекст, которого другие пользователи моделей будут лишены. Полезно представлять воображать себе этого человека при работе над моделями - его реакции, вопросы, недоумения и пр. И, исходя из этого, корректировать, исправлять созданное. И, конечно же, полезно проверить свои предположения, показав ему, что получилось. Кроме того, важно, чтобы точка зрения была " живая", а не выдумывалась аналитиком или бездумно копировалась из книжек и тренингов, посвященных UML. Незаметно для себя аналитик может придумать свой собственный проект, своих собственных пользователей системы, заказчика и т.д. Он может исподволь навязывать самому себе определенное восприятие реально существующих людей, задач, сильно искажая реальное положение дел. И именно в контексте этой воображаемой ситуации он будет создавать свои модели… Идеальный аналитик должен обладать гибкостью сознания, а также чуткостью и искренним стремлением к тому, чтобы сделать каждый конкретный проект, где он участвует, более гармоничным, более адекватным. И в любом случае иметь дело с реальной ситуацией, облегчая, распутывая и освобождая ее. Тут важно не путать:
и т.д. И вовремя пресекать свои собственные нежелательные " увлечения", не бояться порой непростых поисков нужных выразительных форм, акцентов и точек зрения на ситуацию.
Граф модели и диаграммы Визуальные модели создаются не с помощью карандаша и бумаги, а в специальных программных пакетах (например, CASE-пакетах). Это удобно, но, с другой стороны, усложняет структуру моделей и вводит новые правила работы с ними. Визуальные спецификации обычно разделяют на граф модели и диаграммы. Граф модели - это набор сущностей визуальной модели, их атрибутов и связей. Диаграмма - это внешнее представление модели: геометрические размеры сущностей, их координаты, цвета, шрифты надписей, толщина линий и пр. Графические редакторы позволяют менять эти и многие другие параметры, делая диаграмму максимально удобной для работы. При этом граф модели остается неизменным. Это разделение проходит красной нитью через средства визуального моделирования, отражаясь в строении визуальных языков, в интерфейсе и внутренней архитектуре программных инструментов и т. д. Рассмотрим пример.
Рис. 2.10. Пример двух разных, но " пересекающихся" по информации диаграмм
На рис.2.10а показана диаграмма классов, где приведена полная спецификация класса А - всех его атрибутов, операций, всех его предков в иерархии наследования, а также связей с другими классами. На рис.2.10б представлена диаграмма классов, где аналогично определяется класс E. Классы A и E связаны друг с другом ассоциацией, поэтому будут присутствовать на обеих диаграммах. Очевидно, что на этих диаграммах имеется общая информация. А теперь допустим, что изменилось имя класса E на рис.2.10б. Очевидно, что и на диаграмме с рис.2.10а это имя тоже должно измениться. Поскольку обе диаграммы представляют один и тот же граф модели, то при первом переименовании второе должно произойти автоматически. И это еще простой пример. А диаграммы могут принадлежать разным типам и все равно быть связанными по информации. Например, в дополнение к диаграммам класса с рис.2.10 можно создать диаграмму объектов, на которой будет присутствовать объект класса Е. При изменении имени класса Е диаграмма объектов должна также измениться, поскольку имя класса Е указано в имени объекта. Наконец, есть модельная информация, которая вовсе не отображается на диаграммах, но тем не менее нужна. Например, диаграммы могут образовывать иерархию - быть сгруппированы в пакеты, принадлежать отдельным модельным сущностям (например, набор диаграмм состояний и переходов может определять поведение одной компоненты). Для того, чтобы хранить всю информацию, которая связывает разные диаграммы в единое целое, и используется граф модели. Полная модель для диаграмм с рис.2.10 а и б представлен на рис.2.11. Однако далеко не каждую модель удается полностью изобразить на одной диаграмме.
Диаграммы помогают создавать граф модели, а также просматривать и изменять его. Граф модели является хранилищем модельной информации, причем хранилищем " умным". Что это значит? Граф модели не есть склад " диаграмм". В таком случае класс А на рис.2.10 а и тот же класс на рис.2.10 б были бы разными сущностями. Граф модели хранит общий граф всех сущностей и связей, фрагменты которого отображаются на диаграммах. Если диаграммы модели сопоставить с файлами исходных текстов некоторой программы, то граф модели - это проанализированный компилятором единый текст этой программы, представленный в виде графа синтаксического разбора. Подобный анализ происходит при компиляции программ в исполняемый код, а в случае визуальных моделей он происходит раньше - при сохранении диаграмм в CASE-средстве. Как правило, самым распространенным средством обзора графа модели является браузер модели. Такие браузеры есть в каждом CASE-пакете. Пример браузера модели для графа, представленного на рис.2.11, показан на рис.2.12. На этом рисунке показаны все классы этой визуальной модели, а также пакеты, в которые они входят. Но в этом браузере не показаны отношения наследования и ассоциации, поскольку их неудобно представлять в таком виде - в дереве.
Этот браузер - из пакета Microsoft Visio/ UML Addon. В современных CASE-пакетах граф модели хранится в репозитории - едином хранилище модельной информации. В прежних CASE-пакетах репозиторий реализовывался как база данных. С ее помощью решались все вопросы с хранением графа модели, а также с доступом к нему. Несомненным плюсом такого подхода является решение вопросов многопользовательского и сетевого доступа. Однако многопользовательский аспект не является в настоящее время ключевым, так как современные CASE-пакеты не являются средами разработки, как CASE-пакеты предыдущего поколения. Более важным оказываются вопросы быстродействия репозитория на больших моделях. Для решения этой задачи в современных CASE-пакетах часто применяются объектные базы в памяти, используются также специальные библиотеки для задания бизнес-объектов в памяти, например Eclipse/EMF. Долгосрочное хранение графа модели осуществляется в XML-формате.
Популярное:
|
Последнее изменение этой страницы: 2016-05-28; Просмотров: 918; Нарушение авторского права страницы