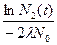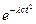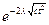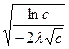|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Глава 2.1. Лингвистическое время: глоттохронология, лексикостатистика
I. Языковая дивергенция.— II. Роль базисной лексики в датировке языковой дивергенции.— III. Метод Сводеша.— IV. Соотношение между постулатами глоттохронологии и реально наблюдаемой языковой историей.— V. Модификация основной формулы глоттохронологии.— VI. Глоттохронология германских языков.— VII. Этимостатистика. I. Концепция генеалогического древа предполагает, что родственные языки развиваются из общего языка-предка. Исходя только из структуры дерева, мы можем дать лишь относительную хронологию языковой дивергенции: так, мы можем сказать, что праславянский язык существовал позже прабалтославянского, а последний — позже праиндоевропейского, но не можем сказать, когда существовал каждый из них. Интересно задаться вопросом: существует ли способ измерения абсолютной временн{о/}й глубины языковой дивергенции, иными словами, способ определения времени распада праязыка? В случаях, когда нам хорошо известна история соответствующей языковой семьи, ответ прост: глубина дивергенции соответствует реально засвидетельствованному времени раздельного существования отдельных языков. Так, в случае с романскими языками мы можем с уверенностью утверждать, что время распада общероманского праязыка (т. е. народной латыни) приблизительно совпадает со временем падения Западной Римской Империи: именно с этого момента диалекты народной латыни, на которых говорили в разных концах этого политического объединения, постепенно начинают превращаться в отдельные языки. Однако в подавляющем большинстве случаев момент распада праязыка исторически не засвидетельствован. Можно ли по чисто лингвистическим данным определить календарное время дивергенции двух языков, то есть время существования их общего праязыка? На этот вопрос можно ответить положительно только в том случае, если какие-либо из изменений происходят с более или менее постоянной скоростью: тогда по количеству произошедших изменений можно судить о времени, отделяющем язык от праязыка или два родственных языка друг от друга. Изменения эти должны происходить в одной подсистеме языка, поскольку инновации в разных подсистемах могут быть несопоставимы между собой: например, едва ли можно определить, для чего нужно больше времени — для двух передвижений согласных или для возникновения сингармонизма, для падения редуцированных или для развития эргативности. II. Но какие из многочисленных языковых изменений могут иметь постоянную скорость? Рассмотрим возможные типы языковых инноваций: 1) изменения в фонетике; 2) изменения в грамматике (в грамматической семантике и синтаксисе); 3) изменения плана содержания слов (т. е. семантические изменения); 4) замена грамматических морфем; 5) лексические замены. Опираться на фонетические и грамматические изменения сложно из-за их несопоставимости, семантические изменения в настоящее время слишком слабо изучены. Кроме того, известны случаи очень быстрого изменения как фонологических, так и морфологических систем (особенно при активных языковых контактах, см. Гл. 1.4), а также наоборот — чрезвычайного фонологического и морфологического консерватизма, сохранения исходных систем на протяжении очень долгих периодов времени (особенно в случае изолированного существования языка — например, в островных или горных условиях). В то же время изменения в лексике наиболее пригодны для строгих датировок, так как допускают применение статистических методов. В наиболее простых случаях датировки, полученные при помощи подсчета базисной лексики, хорошо коррелируют с датировками, полученными путем анализа других элементов языка. Для случаев же более сложных желательно пользоваться некоторым единым критерием — с тем, чтобы получать сопоставимые результаты. Выше (см. Гл. 1.1) мы писали, что основным критерием близости языков — хотя и с многочисленными оговорками — может служить именно лексическая близость. Чтобы сохранялось взаимопонимание между различными поколениями носителей, необходимо, чтобы лексических замен было не слишком много: фонетические и морфологические изменения, как мы видели, мало препятствуют коммуникации, но очень большой процент лексических различий несомненно приведет к утрате взаимопонимания, скажем, между дедами и внуками. При этом меньше всего замен, по-видимому, должно быть в базисной лексике, т. е. в основном словарном составе языка, составляющем его ядро. Кроме того, базисная лексика, в отличие от прочих компонентов языка (т. е. " манеры выражаться" и культурной лексики), мало меняется в ходе языковых контактов, поэтому подсчеты, основанные на ней, позволяют вычислить именно время самостоятельного существования языка, а не степень его вовлеченности в контакты с другими языками. III. На предположении о постоянной скорости изменений в базисной лексике построил свою теорию глоттохронологии, иногда называемой также лексикостатистикой, американский ученый Морис Сводеш. Эта теория базируется на следующих пяти постулатах (в работах самого М. Сводеша, см. [НВЛ 1960], они не сформулированы, поэтому мы приводим их по книге [Арапов, Херц 1974, 21-22, 25]): " 1. В словаре каждого языка можно выделить специальный фрагмент, который мы будем называть дальше основной, или стабильной частью. 2. Можно указать список значений, которые в любом языке обязательно выражаются словами из основной части... Будем говорить, что эти слова образуют основной список (ОС). Через N{0} обозначим число слов в ОС. 3. Доля p слов из ОС, которые сохранятся (не будут заменены другими словами) на протяжении интервала времени {Dд} t... постоянна (то есть зависит только от величины выбранного промежутка, но не от того, как он выбран или какие слова какого языка рассматриваются). 4. Все слова, составляющие ОС, имеют одинаковые шансы сохраниться (соответственно, не сохраниться, " распасться" ) на протяжении этого интервала времени. 5. Вероятность для слова из ОС праязыка сохраниться в ОС одного языка-потомка не зависит от его вероятности сохраниться в аналогичном списке другого языка-потомка." Из совокупности приведенных постулатов выводится основная математическая зависимость глоттохронологии:
N(t)= N{0}e-{l}t
где время, прошедшее от начала момента развития до некоторого последующего момента обозначается как t (и измеряется в тысячелетиях); N{0} есть исходный ОС; {l} есть " скорость выпадения" слов из N{0}; и N(t) есть доля слов исходного ОС, сохранившихся к моменту t. Зная коэффициент {l} и долю слов, сохранившихся в данном языке из списка ОС, мы можем вычислить длину прошедшего промежутка времени:
t= Доля слов из ОС, сохранившихся в двух языках, будет составлять соответственно:
N{2}(t)=
а время, разделяющее их, будет вычисляться как:
t=
IV. Несмотря на простоту и элегантность данного математического аппарата, уже давно было замечено, что он не очень хорошо работает. Так, К. Бергсланд и Х. Фогт [Bergsland, Vogt 1962], рассматривая материал скандинавских языков, показали, что скорость распадения лексики в исландском языке за последнюю тысячу лет равнялась всего {=~} 0, 04, а в литературном норвежском (риксмоле) — {=~} 0, 2 (и это при том, что М. Сводеш в качестве константы {l} предлагал величину 0, 14! ). Соответственно, получались вполне нелепые результаты: для исландского языка около 100-150 лет, а для риксмола — около 1400 лет развития — при том, что оба языка возникли из одного источника и развивались независимо в течение около 1000 лет. В большинстве случаев применение теории Сводеша давало явно " умоложенные" даты по сравнению с теми, которые можно было предположить на основании реальной истории языков. Все это заставило большинство исследователей поставить под сомнение всю глоттохронологическую методику. Несмотря на это, глоттохронология продолжает существовать. Дело в том, что есть непреложный эмпирический факт, с которым приходится считаться: чем ближе друг к другу языки, тем больше между ними совпадений в области базисной лексики. Так, все индоевропейские языки (из разных подгрупп: немецкий и русский, хинди и польский, болгарский и румынский) имеют между собой около 30% совпадений; все балто-славянские языки (литовский и русский, латышский и чешский) имеют между собой примерно 45-50% совпадений; все славянские языки (русский и польский, чешский и болгарский), а также все германские языки (немецкий и шведский, голландский и исландский) имеют между собой примерно 75-85% совпадений. Налицо, таким образом, явная корреляция между степенью родства и количеством совпадений в базисной лексике. Глоттохронологию, по-видимому, нельзя сбрасывать со счетов, хотя нужен пересмотр некоторых ее постулатов. V. Здесь следует отметить четыре момента: 1) В случае активных контактов между языками возникают многочисленные заимствования, в том числе и в базисной лексике. Следует, однако, представлять себе, что замена исконного слова на исконное же имеет несколько иной механизм, чем замена исконного слова на заимствование. Замены первого типа происходят постепенно, вне зависимости от культурно-исторического контекста, и только для них можно предполагать некоторую постоянную скорость. Замены второго типа могут происходить в течение краткого времени (при активизации культурных контактов) и, таким образом, как бы нарушают естественный ход развития лексики. Неучет различия этих двух типов замен может привести к серьезным искажениям результатов глоттохронологии. Заметим, что подавляющее большинство " неудачных" результатов глоттохронологических подсчетов, приводивших к искаженным классификациям и неверным датировкам, обусловлено именно неразличением этих двух типов лексических замен. Так, упомянутый выше случай с исландским языком и риксмолом легко объясняется, если учесть, что в исландском вовсе нет заимствований (в силу его изолированного существования), в то время как стословный список риксмола включает в себя 11 датских, 3 шведских и 2 немецких заимствования. Число исконных замен в исландском и норвежском, таким образом, оказывается вполне сопоставимо — однако их не 14%, как это должно было бы быть по Сводешу, а около 5% за последнюю тысячу лет. Аналогичную цифру мы получаем и для других языков, чья история зафиксирована на протяжении нашей эры (японского, китайского, романских и др.). 2) Вероятность для слова из любого списка базисной лексики сохраниться в одном из языков-потомков становится зависимой от того, сохранилось ли оно в другом языке-потомке, при наличии между этими языками-потомками интенсивных контактов (в ту эпоху, когда они были заметно родственными): в активно взаимодействующих заметно родственных языках имеется тенденция к сохранению и/или выпадению из базисной лексики одних и тех же слов (при этом далеко не всегда можно говорить о заимствовании); иногда такие контакты могут вызывать " подскок" доли совпадений даже на 5-6%. Подобную картину мы наблюдаем, например, для белорусского и западнославянских языков, немецкого и скандинавских и пр. В то же время наличие в языке культивируемой литературной нормы на скорость замены базисной лексики, по-видимому, не влияет: в таких случаях разговорный язык просто отходит от нормы и изменяется сам по себе — такова ситуация во французском, чешском, персидском и многих других языках. Существенно, однако, что, как показывают многочисленные эксперименты, средняя (по списку) вероятность выпадения слов одинакова для любых языков. 3) Третий постулат глоттохронологии, по-видимому, не вполне верен: доля p слов из ОС, которые сохранятся (не будут заменены другими словами) на протяжении интервала времени {Dд} t не постоянна, но меняется с течением времени. Чем дольше слово " прожило" в языке, тем больше шанс, что оно вскоре выпадет (известны примеры широкого распространения слова в древних языках при почти полной его утрате в современных). Коэффициент {l}, таким образом, должен зависеть от времени t. Как показывают исследования языков с достаточной длинной письменной историей, скорость распада основного списка равна примерно 0, 05 лишь на протяжении последней тысячи — полутора тысяч лет. Если же рассмотреть развитие какого-либо языка в течение, например, 2, 5 тысячелетий, то скорость его развития окажется равной {=~} 0, 1 (см. [Старостин С. 1989b, 10-13]). 4) С другой стороны, вызывает сомнения и четвертый постулат: все слова, составляющие ОС, имеют одинаковые шансы сохраниться на протяжении интервала времени t. На самом деле среди слов, составляющих ОС, есть более устойчивые слова, сохраняющиеся буквально на протяжении тысяч лет, а есть гораздо менее устойчивая лексика: так, шансов на выпадение из списка у слов `маленький' или `кожа' в целом значительно больше, чем у слов `я', `ты' или `ухо'. Коэффициент сохраняемости индивидуального слова может варьировать в зависимости от культурного и лингвистического окружения (так, слова `облако' и `хвост' весьма устойчивы в тюркских языках и нестабильны в германских). В силу этих причин наблюдается следующая зависимость: по мере выпадения слов из списка скорость выпадения слов из него — коэффициент {l} — уменьшается, поскольку начинают происходить повторные замены среди менее устойчивой части списка. Таким образом, коэффициент {l} должен зависеть еще и от доли сохранившихся слов N(t). Эти соображения приводят нас к переформулировке основной зависимости глоттохронологии в следующем виде (обозначим для простоты N(t) как c, а N{0} примем за единицу, поскольку мы имеем дело именно со стословным списком):
c=
Для двух языков будем иметь:
c=
Соответственно, время разделения двух языков будет вычисляться как:
t=
Эта формула, очевидно, является аппроксимацией сложной математической зависимости, учитывающей индивидуальные вероятности выпадения каждого отдельного слова в ОС; она, однако, довольно хорошо работает на всем известном нам языковом материале при принятии {l} = 0, 05. VI. Рассмотрим стословные списки нескольких германских языков:
Таблица 2.1.1
В приведенной таблице все корни пронумерованы в соответствии с их этимологиями. Выбирается по возможности основное слово для данного значения в данном языке; однако разрешается учитывать и близкие синонимы, если они имеются и оба являются употребительными (случаи типа little и small для значения `маленький' в английском и т. п.). Особо нужно оговорить заимствованную лексику: заимствованные слова помечены в таблице отрицательными номерами (при этом их этимологические связи не отмечаются), и они не учитываются при подсчете совпадений, то есть, например, пара нем. wir — англ. we засчитывается как совпадение, пара нем. Vogel — англ. bird — как несовпадение, а пара нем. Haut — англ. skin вовсе не учитывается, то есть основной список в данном случае как бы уменьшается на единицу (точно так же мы поступаем и в тех случаях, когда соответствующее слово в языке просто неизвестно — к сожалению, довольно частая ситуация со списками малоизученных и древних языков). Особенно сложна ситуация с отделением заимствованной лексики от исконной в английском языке, поэтому оговорим специально, что разметка английского списка произведена в соответствии со словарем [Skeat 1968]. В качестве представителя " норвежского" языка выбран диалект гьестал, поскольку оба литературных норвежских языка - букмол и нюнорск - изобилуют заимствованиями, причем для многих слов отнесение их к числу исконных или заимствованных спорно.
Подсчет этимологических совпадений (отметим еще раз, что " этимологическими совпадениями" считаются слова, имеющие один и тот же корень, морфологические различия не учитываются) дает нам следующий результат:
Таблица 2.1.2
В этой таблице верхний треугольник содержит доли совпадений между каждой парой языков, а нижний — вычисленные по этим долям времена расхождения (в тысячелетиях). Так, между английским и немецким 82% совпадений, что соответствует глубине дивергенции приблизительно в 1500 лет. Минимальный процент совпадений здесь — 74% между исландским и немецким, что соответствует времени дивергенции примерно 1800-1900 лет. Легко убедиться, что приведенные доли совпадений и датировки в целом вполне соотносятся с обычными представлениями о глубине германской семьи языков и ее классификации (ниже, см. Гл. 2.2, мы еще поговорим о классификационном аспекте лексикостатистики). Необходимо особо оговорить то, как при данной глоттохронологической методике следует обращаться с материалом древних языков. Используемый метод исходит из того, что скорость распада основного списка фактически не является постоянной величиной, а зависит от времени, отделяющего язык от праязыка. Следовательно, один и тот же процент совпадений, полученный для двух пар родственных языков, из которых одну пару составляют два современных языка, а вторую – два древних, зафиксированных, скажем, в V веке н. э., будет соответствовать различным периодам дивергенции. Чтобы вычислить соответствующую датировку, необходимо использовать метод табличной коррекции (см. Табл. 2.1.3; c — доля сохранившейся лексики в одном языке, c{2} — доля сохранившейся лексики в двух языках, t — время в тысячелетиях):
Таблица 2.1.3
и т. д.
Предположим, что мы сравниваем списки двух языков, один из которых (A) засвидетельствован в V в. н. э., а другой (B) — в XII, и получаем 80% совпадений. Поскольку язык A отделен от нашего времени периодом в 1, 5 тысяч лет, а язык B — периодом в 0, 8 тысяч лет, их современные потомки имели бы 0, 8*0, 9*0, 97 = 0, 7, то есть 70% совпадений, что соответствует дивергенции приблизительно в 1900 лет. После этих предварительных замечаний рассмотрим данные древних германских языков — древнеанглийского, древневерхненемецкого, древнеисландского и готского.
Таблица 2.1.4 Популярное: |
Последнее изменение этой страницы: 2016-06-05; Просмотров: 753; Нарушение авторского права страницы
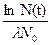
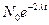 ,
,