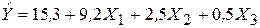|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
ГЛАВА 2. ПАРНЫЙ РЕГРЕССИОННЫЙ АНАЛИЗСтр 1 из 8Следующая ⇒
ГЛАВА 2. ПАРНЫЙ РЕГРЕССИОННЫЙ АНАЛИЗ
Функциональная, статистическая и корреляционная Зависимости экономических переменных
Любая экономическая политика заключается в регулировании определенных экономических показателей. Однако стратегия регулирования может быть весьма неэффективной и рискованной без достаточного знания того, как эти показатели связаны с другими переменными, часто имеющими ключевое значение для принимающего решение политика или предпринимателя. Кроме того, воздействие на многие экономические показатели не может осуществляться непосредственно. Например, нельзя непосредственно регулировать темп инфляции, но на него можно воздействовать средствами фискальной (бюджетно-налоговой) и монетарной (кредитно-денежной) политики. Поэтому, в частности, должна быть изучена зависимость между предложением денег и уровнем цен. В реальных экономических ситуациях даже устоявшиеся зависимости могут проявляться неоднозначно. Еще более сложной проблемой является анализ малоизученных и нестабильных зависимостей, построение моделей которых является основной задачей современной эконометрики. Разработка эффективных эконометрических моделей невозможна без проведения на всех этапах исследований качественного и количественного анализа с использованием реальных статистических данных. Основными инструментами таких исследований являются методы корреляционного и регрессионного анализа. Модели регрессионного анализа занимают центральное место в математическом аппарате эконометрики. В естественных науках обычно имеют дело со строгой (функциональной) зависимостью, при которой каждому значению одной переменной соответствует единственное значение другой. В экономике в большинстве случаев имеют место зависимости, когда каждому значению одной переменной соответствует определенное (условное) распределение другой. Такую зависимость называют статистической (вероятностной). В частности, статистическая зависимость может проявляться в том, что при изменении одной из величин изменяется среднее значение (условное математическое ожидание) другой. В этом случае статистическая зависимость называется корреляционной. Так, например, при рассмотрении взаимосвязи между двумя переменными Х и Y может быть представлена усредненная по Х схема зависимости, где условное математическое ожидание Мх(Y) изменяется в зависимости от Х = х. Односторонняя зависимость, выражаемая соотношением Мх(Y) = φ (x), (2.1) называется функцией регрессии или просто регрессией Y на Х. При этом зависимую переменную Y называют также функцией отклика, результативным признаком или результирующей переменной, а независимую переменную Х – регрессором, фактором-аргументом, факторным признаком. Соотношение (2.1), определяющее взаимосвязь между двумя переменными, представляет собой парную регрессию. Зависимость нескольких экономических переменных, выражаемую уравнением:
называют множественной (многомерной) регрессией. Термин «регрессия» (движение назад, возвращение в прежнее состояние) был введен Френсисом Галтоном в конце XIX в. при анализе зависимости между ростом родителей и ростом детей. Галтон установил, что рост детей у высоких родителей меньше, чем средний рост родителей. У низких родителей, наоборот, средний рост детей выше. И в том, и в другом случае средний рост детей стремится (возвращается) к среднему росту людей в данном регионе. Сущность такой зависимости отражается используемым термином. В настоящее время основными задачами регрессионного анализа являются установление формы зависимости между СВ, оценка функции регрессии, оценка неизвестных значений (прогноз значений) зависимой переменной.
Парная линейная регрессия
Под уравнением регрессии будем понимать функциональную зависимость между объясняющими переменными и условным математическим ожиданием (средним значением) зависимой переменной, которая строится с целью определения оценки этого среднего значения. Если функция регрессии линейна, то говорят о линейной регрессии, и общее теоретическое уравнение парной регрессии имеет вид: Мх(Y) = b0 + b1x. (2.3) Для отражения того факта, что реальные значения зависимой переменной Y не всегда совпадают с ее условными математическими ожиданиями, следует ввести в соотношение (2.3) случайное слагаемое (случайное отклонение) ε: Y = Mx(Y) + ε = b0 + b1 + ε, (2.4) которое по существу является СВ и указывает на вероятностный характер зависимости. Соотношение (2.4) представляет теоретическую линейную регрессионную модель (модель парной линейной регрессии) в общем виде. Тогда для каждого индивидуального значения (наблюдения) yi будем иметь:
Индивидуальные значения yi представлены в виде двух компонент – систематической, объясняемой уравнением регрессии b0 + b1xi, и случайной (необъясненной) – ε i. По реальным наблюдениям (по выборке ограниченного объема) мы сможем построить так называемое эмпирическое уравнение регрессии.
где Ŷ -оценка условного математического ожидания Мх(Y),
где отклонение (остаток) ei представляет собой оценку теоретического случайного отклонения ε i. Линейная регрессионная модель является наиболее распространенным и удобным для анализа видом зависимости между экономическими переменными. Простейшее парное уравнение позволяет достаточно наглядно (часто с помощью графической интерпретации) рассмотреть основные приемы регрессионного анализа. Кроме того, парная регрессия может служить начальной точкой эконометрического моделирования. Например, это может быть линейная зависимость спроса на некоторый товар или услугу от цены или зависимость частного потребления от располагаемого дохода (модель Дж. Кейнса) и т. д. Метод наименьших квадратов
Рассмотрим задачу аппроксимации набора наблюдений xi, yi (i = 1, 2, …, n) линейной функцией регрессии. Основной этап решения этой задачи состоит в определении по конкретной выборке пар значений (xi, yi) таких оценок
Рис. 2.1.
Мерой качества найденных оценок параметров могут служить определенные композиции отклонений еi. В качестве меры соответствия линии регрессии (модели) наблюдаемым значениям удобно рассматривать сумму квадратов отклонений Метод определения оценок параметров линейной регрессионной модели (коэффициентов регрессии), заключающийся в минимизации суммы квадратов отклонений выборочных данных yi от модельных (регрессионных) значений В случае парной линейной регрессии при использовании МНК минимизируется следующая функция двух параметров:
На основании необходимого условия существования минимума функции двух переменных (2.8) приравниваем к нулю ее частные производные по неизвестным параметрам
Раскрыв скобки и перегруппировав слагаемые, получим систему двух линейных уравнений для определения
Разделив оба уравнения (2.10) на n и решая систему, найдем
где соответствующие средние находятся по формулам:
Нетрудно заметить, что решение для
где Covв(x, y) – выборочная ковариация, а Dв(x) - выборочная дисперсия объясняющей переменной (фактора-аргумента) Х. Тогда, преобразуя (2.12), получим:
где rxy - выборочный коэффициент корреляции; Оценка Резюмируя проведенные рассуждения, можно сделать следующие выводы: 1. Оценки параметров модели по МНК являются функциями от объема выборки n, что позволяет достаточно легко их рассчитывать. 2. Оценки по МНК являются точечными оценками теоретических коэффициентов регрессии. 3. Из формулы для определения параметра 4. Из первой формулы соотношения (2.9) следует, что сумма отклонений Для иллюстрации МНК рассмотрим следующий пример. Пример 2.1. Приведены статистические данные недельного дохода (Х) и недельного потребления (Y) в у.е. для домашних хозяйств (см. таблицу).
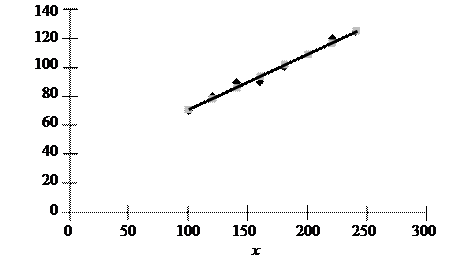
Необходимо построить парную (однофакторную) регрессионную модель зависимости потребления от располагаемого дохода. Для наглядности и предварительного анализа нанесем точки xi, yi (n = 8) на координатную плоскость и получим так называемое корреляционное поле или диаграмму рассеяния (рис. 2.2).
Рис. 2.2.
По характеру расположения точек на корреляционном поле можно предположить, что зависимость между Y и Х является линейной:
Для построения уравнения парной линейной регрессии по МНК составим вспомогательную табл. 2.1. Тогда, согласно МНК, имеем:
Для нахождения оценок параметров модели необходимы данные первых четырех столбцов таблицы. Остальные данные будут необходимы для последующего анализа качества построенной модели.
Таблица 2.1
Таким образом, построенная модель парной регрессии (уравнение регрессии) имеет вид:
По этому уравнению рассчитаем модельные значения Графически задачу парной линейной регрессии можно представить следующим образом. В «облаке» точек xi, yi плоскости XY следует провести прямую так, чтобы совокупность всех отклонений В нашем примере параметр модели
ЛИНЕЙНОЙ РЕГРЕССИИ
Основные понятия и уравнения множественной регрессии
На любой экономический показатель чаще всего оказывает влияние не один, а несколько совокупно действующих факторов. Например, объем реализации (Y) для предприятий оптовой торговли может определяться уровнем цен (Х1), числом видов товаров (Х2), размером торговой площади (Х3) и товарных запасов (Х4). В целом объем спроса на какой-либо товар определяется не только его ценой (Х1), но и ценой на конкурирующие товары (Х2), располагаемым доходом потребителей (Х3), а также некоторыми другими факторами. В этих случаях возникает необходимость рассмотрения моделей множественной регрессии. Естественным обобщением парной (однофакторной) линейной регрессионной модели является модель множественной линейной регрессии, теоретическое уравнение которой имеет вид:
где Х1, Х2, …, Хm – набор независимых переменных (факторов-аргументов); b0, b1, …, bm – набор (m + 1) параметров модели, подлежащих определению; ε – случайное отклонение (ошибка); Y – зависимая (объясняемая) переменная. Для индивидуального i-го наблюдения (i = 1, 2, …, n) имеем:
или
Здесь bj называется j-м теоретическим коэффициентом регрессии (частичным коэффициентом регрессии). Аналогично случаю парной регрессии, истинные значения параметров (коэффициентов) bj по выборочным данным получить невозможно. Поэтому для определения статистической взаимосвязи переменных Y и Х1, Х2, …, Хm оценивается эмпирическое уравнение множественной регрессионной модели
в котором Оцененное уравнение (3.4) в первую очередь должно описывать общий тренд (направление, тенденцию) изменения зависимой переменной Y. При этом необходимо иметь возможность рассчитать отклонения от этого тренда. Для решения задачи определения оценок параметров множественной линейной регрессии по выборке объема n необходимо выполнение неравенства n ³ m + 1 (m – число регрессоров). В данном случае число v = n - m - 1 будет называться числом степеней свободы. Отсюда для парной регрессии имеем v = n - 2. Нетрудно заметить, что если число степеней свободы невелико, то и статистическая надежность оцениваемой формулы невысока. На практике принято считать, что достаточная надежность обеспечивается в том случае, когда число наблюдений по крайней мере в три раза превосходит число оцениваемых параметров k = m + 1. Самым распространенным методом оценки параметров уравнения множественной линейной регрессионной модели является метод наименьших квадратов (МНК). Напомним (см. раздел 2.4.1), что надежность оценок и статистических выводов, полученных с использованием МНК, обеспечивается при выполнении предпосылок Гаусса-Маркова. В случае множественной линейной регрессии к предпосылкам 1–4 необходимо добавить еще одну (пятую) – отсутствие мультиколлинеарности, что означает отсутствие линейной зависимости между объясняющими переменными в функциональной или статистической форме. Более подробно мультиколлинеарность объясняющих переменных будет рассмотрена в разделе (3.4). Модель, удовлетворяющая предпосылкам МНК, называется классической нормальной моделью множественной регрессии. На практике часто бывает необходимо оценить силу влияния на зависимую переменную различных объясняющих (факторных) переменных. В этом случае используют стандартизованные коэффициенты регрессии Стандартизированный коэффициент регрессии определяется по формуле:
где S(xj) и S(y) – выборочные средние квадратичные отклонения (стандарты) соответствующей объясняющей и зависимой переменных. Средний коэффициент эластичности
показывает, на сколько процентов (от средней) изменится в среднем зависимая переменная Y при увеличении только j-й объясняющей переменной на 1 %. Для модели с двумя объясняющими (факторными) переменными
Множественной регрессии
Для проверки общего качества уравнения регрессии обычно используется коэффициент детерминации R2, который характеризует долю дисперсии зависимой переменной Y, объясняемую регрессионной моделью, и определяется по формуле:
Свойства коэффициента R2 подробно рассмотрены в разделе 2.4. Для множественной регрессии коэффициент детерминации (или множественный коэффициент детерминации) является неубывающей функцией числа объясняющих переменных, т. е. добавление новой объясняющей переменной (фактора-аргумента Х) в модель никогда не уменьшает значение R2. Действительно, каждая новая объясняющая переменная может лишь дополнить информацию, объясняющую поведение зависимой переменной. В целом это уменьшает неопределенность в поведении исследуемой величины Y. Однако увеличение R2 при добавлении новых переменных далеко не всегда приводит к улучшению качества регрессионной модели, так как эти переменные могут не оказывать существенного влияния на результативный признак. Поэтому, наряду с коэффициентом R2, для анализа используется скорректированный коэффициент детерминации
или с учетом (3.27)
Можно заметить, что знаменатель в (3.29) является несмещенной оценкой общей дисперсии зависимой переменной Y, а числитель – несмещенной оценкой остаточной дисперсии (дисперсии случайных отклонений). Скорректированный коэффициент детерминации устраняет (корректирует) неоправданный эффект, связанный с ростом R2 при увеличении числа объясняющих переменных. Из (3.28) следует, что В компьютерных пакетах приводятся данные как по R2, так и по В общем случае качество модели считается удовлетворительным, если R2 > 0, 5. Однако не следует рассматривать коэффициент детерминации как абсолютный показатель качества модели. Можно привести ряд примеров, когда неправильно специфицированные модели имели сравнительно высокие коэффициенты детерминации. Поэтому коэффициент детерминации в современной эконометрике следует рассматривать лишь как один из показателей, который необходим для анализа строящейся модели. Анализ общей (совокупной) статистической значимости уравнения множественной регрессии осуществляется на основе проверки основной гипотезы об одновременном равенстве нулю всех коэффициентов при объясняющих переменных: Н0: b1 = b2 = … = bm = 0. Если данная гипотеза не отклоняется, то естественно считать уравнение модели статистически незначимым, т. е. не выражающим существенную линейную связь между Y и Х1, Х2, …, Хm. Напомним (см. раздел 2.4.3), что общая дисперсия зависимой переменной Dn(y) может быть представлена в виде суммы двух составляющих:
где Исходя из этого проводится дисперсионный анализ для проверки гипотезы Н0 (F-тест). Строится проверочная F-статистика:
где Если рассчитан коэффициент детерминации R2, то критерий значимости уравнения регрессии (3.30) может быть представлен в следующем виде:
Критерий (3.31) обычно используется на практике для тестирования гипотезы о статистической значимости коэффициента детерминации (Н0: R2 = 0; Н1: R2 > 0) которая эквивалентна гипотезе об общей статистической значимости уравнения множественной регрессии. Отметим, что в отличие от парной регрессии, где t-тест и F-тест равносильны, в случае множественной регрессии коэффициент R2 приобретает самостоятельную значимость. Пример 3.2. Оценим статистическую значимость построенной модели. Пусть при оценке регрессии с тремя объясняющими переменными (
Мультиколлинеарность
Весьма нежелательным эффектом, который может проявляться при построении моделей множественной регрессии, является мультиколлинеарность – линейная взаимосвязь двух или нескольких объясняющих переменных. Различают функциональную и корреляционную формы мультиколлинеарности. При функциональной форме мультиколлинеарности по крайней мере два регрессора связаны между собой линейной функциональной зависимостью. В этом случае определитель матрицы ХТХ равен нулю в силу присутствия линейно зависимых вектор-столбцов (нарушается предпосылка 5 МНК), что приводит к невозможности решения соответствующий системы уравнений и получения оценок параметров регрессионной модели. Однако в эконометрических исследованиях мультиколлинеарность чаще всего проявляется в более сложной корреляционной форме, когда между хотя бы двумя объясняющими переменными существует тесная корреляционная связь. Ниже рассмотрены некоторые способы обнаружения, а также уменьшения и устранения мультиколлинеарности. Один из таких способов заключается в исследовании матрицы ХТХ. Если ее определитель близок к нулю, то это может свидетельствовать о наличии мультиколлинеарности. В этом случае наблюдаются значительные стандартные ошибки коэффициентов регрессии и их статистическая незначимость по t-критерию, хотя в целом регрессионная модель может оказаться значимой по F-тесту. Другой подход состоит в анализе матрицы парных коэффициентов корреляции между объясняющими переменными (факторами). Если бы факторы не коррелировали между собой, то корреляционная матрица R была бы единичной матрицей, поскольку все недиагональные элементы (хi ¹ xj) равны нулю. Определитель такой матрицы равен единице. Например, для модели, включающей три объясняющих переменных
Если же, наоборот, между факторами-аргументами существует полная линейная зависимость и все коэффициенты корреляции равны 1 (|rij| = 1), то определитель матрицы межфакторной корреляции равен нулю
Таким образом, чем ближе к нулю определитель матрицы межфакторной корреляции, тем сильнее мультиколлинеарность объясняющих переменных и ненадежнее оценки множественной регрессии, полученные с использованием МНК. Если в модели больше двух объясняющих переменных, то для обнаружения мультиколлинеарности полезно находить частные коэффициенты корреляции, поскольку парные коэффициенты корреляции определяют силу линейной зависимости между двумя факторами без учета влияния на них других объясняющих переменных. Например, между двумя экономическими переменными может наблюдаться высокий положительный коэффициент корреляции совсем не потому, что одна из них стимулирует изменение другой, а вследствие того, что обе эти переменные изменяются в одном направлении под влиянием других факторов, присутствующих в модели. Поэтому возникает необходимость оценки действительной тесноты (силы) линейной связи между двумя факторами, очищенной от влияния других переменных. Параметр, определяющий степень корреляции между двумя факторами Хi и Xj при исключении влияния остальных переменных называется частным коэффициентом корреляции. Например, в случае модели с тремя объясняющими переменными Х1, Х2, Х3 частный коэффициент корреляции между Х1 и Х2 рассчитывается по формуле:
Частный коэффициент корреляции может существенно отличаться от «обычного» парного коэффициента корреляции r12. Пусть, например, r12 = 0, 5; r13 = 0, 5; r23 = -0, 5. Тогда частный коэффициент корреляции r12.3 = 1 (3.34), т. е. при относительно невысоком коэффициенте корреляции r12 частный коэффициент корреляции указывает на высокую зависимость (коллинеарность) между переменными Хi и Xj. Таким образом, для обоснованного вывода о корреляции между объясняющими переменными множественной регрессии необходимо рассчитывать частные коэффициенты корреляции. Частный коэффициент корреляции rij.1, 2, …, m, как и парный коэффициент rij, может принимать значения от -1 до 1. Присутствие в модели пар переменных, имеющих высокие коэффициенты частной корреляции (обычно больше 0, 8), свидетельствует о наличии мультиколлинеарности. Для устранения или уменьшения мультиколлинеарности используется ряд методов, простейшим из которых является исключение из модели одной или нескольких коррелированных переменных. Обычно решение об исключении какой-либо переменной принимается на основании экономических соображений. Следует заметить, что при удалении из анализа объясняющей переменной можно допустить ошибку спецификации. Например, при изучении спроса на некоторый товар в качестве объясняющих переменных целесообразно использовать цену данного товара и цены товаров-заменителей, которые зачастую коррелируют друг с другом. Исключив из модели цены заменителей, мы, вероятнее всего, допустим ошибку спецификации. Вследствие этого можно получить смещенные оценки и сделать ненадежные выводы. Иногда для уменьшения мультиколлинеарности достаточно (если это возможно) увеличить объем выборки. Например, при использовании ежегодных показателей можно перейти к поквартальным данным. Увеличение количества данных сокращает дисперсии коэффициентов регрессионной модели и тем самым увеличивает их статистическую значимость. В ряде случаев минимизировать либо вообще устранить мультиколлинеарность можно с помощью преобразования переменных, в результате которого осуществляется переход к новым переменным, представляющим собой линейные или относительные комбинации исходных. Например, построенная регрессионная модель имеет вид:
причем Х1 и Х2 – коррелированные переменные. В этом случае целесообразно оценивать регрессионные уравнения относительных величин:
(3.36)
Следует ожидать, что в моделях, построенных аналогично (3.36), эффект мультиколлинеарности не будет проявляться. Существуют также другие, более теоретически разработанные способы обнаружения и подавления мультиколлинеарности, описание которых выходит за рамки данной книги. Следует заметить, что если основная задача, решаемая с помощью эконометрической модели, – прогнозирование поведения реального экономического объекта, то при общем удовлетворительном качестве модели проявление мультиколлинеарности не является слишком серьезной проблемой, требующей приложения больших усилий по ее выявлению и устранению, т. к. в данном случае наличие мультиколлинеарности не будет существенно сказываться на прогнозных качествах модели. Таким образом, вопрос о том – следует ли серьезно заниматься проблемой мультиколлинеарности или «смириться» с ее проявлением – решается исходя из целей и задач эконометрического анализа.
Вопросы и упражнения для самопроверки
1. Как определяется модель множественной линейной регрессии? 2. Опишите алгоритм определения коэффициентов множественной линейной регрессии (параметров модели) по МНК в матричной форме. 3. Как определяется статистическая значимость коэффициентов регрессии? 4. В чем суть скорректированного коэффициента детерминации и его отличие от обычного R2? 5. Как используется F-статистика во множественном регрессионном анализе? 6. Вычислите величину стандартной ошибки регрессионной модели со свободным членом и без него, если 7. На основе n = 30 наблюдений оценена модель с тремя объясняющими переменными. Получены следующие результаты:
Стандартные ошибки (2, 5) (1, 6) (2, 8) (0, 07) t-значения ( ) ( ) ( ) ( ) Проведите необходимые расчеты и занесите данные в скобки. Сделайте выводы о существенности коэффициентов регрессии на уровне значимости a =0, 05. 8. Имеются данные о ставках месячных доходов по трем акциям за шестимесячный период:
Популярное: |
Последнее изменение этой страницы: 2016-06-05; Просмотров: 2890; Нарушение авторского права страницы
 , (2.2)
, (2.2)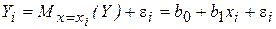 . (2.5)
. (2.5)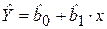 , (2.6)
, (2.6)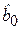 и
и 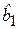 - оценки неизвестных теоретических параметров модели b0 и b1, называемые эмпирическими коэффициентами регрессии. Следовательно, для конкретных значений yi в случае эмпирической парной модели справедливо следующее соотношение:
- оценки неизвестных теоретических параметров модели b0 и b1, называемые эмпирическими коэффициентами регрессии. Следовательно, для конкретных значений yi в случае эмпирической парной модели справедливо следующее соотношение:  , (2.7)
, (2.7)

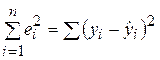 , что дает возможность построить достаточно развитую статистическую теорию.
, что дает возможность построить достаточно развитую статистическую теорию.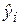 , называется методом наименьших квадратов (МНК).
, называется методом наименьших квадратов (МНК). . (2.8)
. (2.8)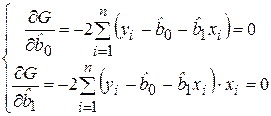 . (2.9)
. (2.9) . (2.10)
. (2.10)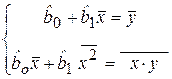
 , (2.11)
, (2.11)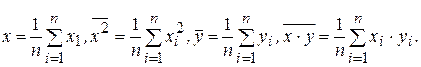
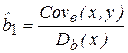 , (2.12)
, (2.12)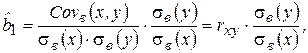 (2.13)
(2.13)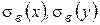 – выборочные средние квадратические отклонения. Таким образом, зная коэффициент корреляции, можно легко найти коэффициент парной регрессии
– выборочные средние квадратические отклонения. Таким образом, зная коэффициент корреляции, можно легко найти коэффициент парной регрессии 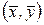 ; т. е.
; т. е.  .
.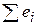 , а также среднее значение
, а также среднее значение 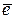 равны нулю.
равны нулю.
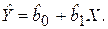
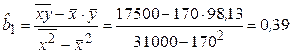 – оценка коэффициента регрессии;
– оценка коэффициента регрессии; 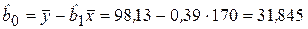 – оценка свободного члена.
– оценка свободного члена.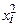
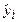
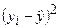
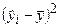

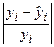
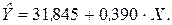
 отвечала условию МНК (2.8).
отвечала условию МНК (2.8). (3.1)
(3.1)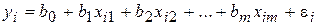 (3.2)
(3.2)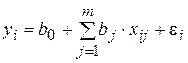 . (3.3)
. (3.3)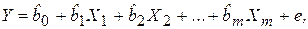 (3.4)
(3.4)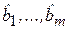 – оценки соответствующих теоретических коэффициентов регрессии; е – оценка случайного отклонения ε.
– оценки соответствующих теоретических коэффициентов регрессии; е – оценка случайного отклонения ε.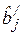 и средние коэффициенты эластичности
и средние коэффициенты эластичности  .
.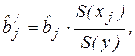 (3.5)
(3.5) (3.6)
(3.6) , после нахождения оценок
, после нахождения оценок 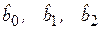 , уравнение определяет плоскость в трехмерном пространстве. В общем случае m независимых переменных геометрической интерпретацией модели является гиперплоскость в гиперпространстве.
, уравнение определяет плоскость в трехмерном пространстве. В общем случае m независимых переменных геометрической интерпретацией модели является гиперплоскость в гиперпространстве.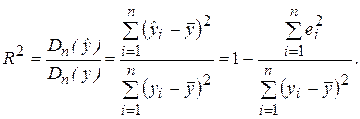 (3.27)
(3.27) , определяемый соотношением:
, определяемый соотношением:  (3.28)
(3.28) . (3.29)
. (3.29)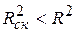 при m > 1 Можно показать, что
при m > 1 Можно показать, что 
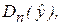 Dn(y) – соответственно, дисперсия? объясняемая уравнением множественной регрессии, и необъясняемая (остаточная) дисперсия, характеризующая влияние неучтенных факторов.
Dn(y) – соответственно, дисперсия? объясняемая уравнением множественной регрессии, и необъясняемая (остаточная) дисперсия, характеризующая влияние неучтенных факторов. (3.30)
(3.30) – объясняемая дисперсия (в уравнении множественной регрессии вместе со свободным членом оценивается k = m + 1 параметров);
– объясняемая дисперсия (в уравнении множественной регрессии вместе со свободным членом оценивается k = m + 1 параметров);  – остаточная дисперсия. При выполнении предпосылок МНК построенная статистика имеет распределение Фишера с числами степеней свободы v1 = m, v2 = n - m - 1. Поэтому гипотеза Н0 отклоняется, если при заданном уровне значимости a значение Fнабл, рассчитанное по формуле (3.30), больше, чем критическое значение Fкр = Fa; m; n - 1 - m (Fнабл > Fкр), и делается вывод о статистической значимости уравнения множественной регрессии. В противном случае (Fнабл > Fкр) нет оснований для отклонения Н0. Это означает, что объясняемая построенной моделью дисперсия соизмерима с дисперсией, вызванной неучтенными факторами, а следовательно, общее качество модели невысоко.
– остаточная дисперсия. При выполнении предпосылок МНК построенная статистика имеет распределение Фишера с числами степеней свободы v1 = m, v2 = n - m - 1. Поэтому гипотеза Н0 отклоняется, если при заданном уровне значимости a значение Fнабл, рассчитанное по формуле (3.30), больше, чем критическое значение Fкр = Fa; m; n - 1 - m (Fнабл > Fкр), и делается вывод о статистической значимости уравнения множественной регрессии. В противном случае (Fнабл > Fкр) нет оснований для отклонения Н0. Это означает, что объясняемая построенной моделью дисперсия соизмерима с дисперсией, вызванной неучтенными факторами, а следовательно, общее качество модели невысоко.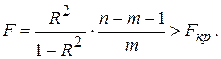 (3.31)
(3.31)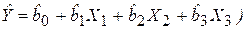 по 30 наблюдениям получено значение коэффициента детерминации R2 = 0, 7. Тогда, наблюдаемое значение F-статистики
по 30 наблюдениям получено значение коэффициента детерминации R2 = 0, 7. Тогда, наблюдаемое значение F-статистики  . По таблице критических точек распределения Фишера найдем F0, 05; 3; 26 = 2, 98 при заданном уровне значимости a = 0, 05. Поскольку Fнабл = 20, 2 > Fкр = 2, 98, то нулевая гипотеза отклоняется, т. е. отвергается предположение о незначимости линейной связи.
. По таблице критических точек распределения Фишера найдем F0, 05; 3; 26 = 2, 98 при заданном уровне значимости a = 0, 05. Поскольку Fнабл = 20, 2 > Fкр = 2, 98, то нулевая гипотеза отклоняется, т. е. отвергается предположение о незначимости линейной связи. , в этом случае имеем:
, в этом случае имеем:  . (3.32)
. (3.32)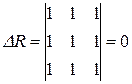 . (3.33)
. (3.33)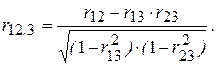 (3.34)
(3.34) (3.35)
(3.35)
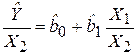 .
.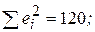 n = 30; m = 3.
n = 30; m = 3.