|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Инициализация массивов указателей
Напишем функцию month_name(n), которая возвращает указатель на строку символов, содержащий название n-го месяца. Эта функция идеальна для демонстрации использования статического массива. Функция month_name имеет в своем личном распоряжении массив строк, на одну из которых она и возвращает указатель. Ниже покажем, как инициализируется этот массив имен. Синтаксис задания начальных значений аналогичен синтаксису предыдущих инициализаций: /* month_name: возвращает имя n-го месяца */char *month_name(int n){ static char *name[] = { " Неверный месяц", " Январь", " Февраль", " Март", " Апрель", " Май", " Июнь", " Июль", " Август", " Сентябрь", " Октябрь", " Ноябрь", " Декабрь" }; return (n < 1 || n > 12)? name[0]: name[n]; }Объявление name массивом указателей на символы такое же, как и объявление lineptr в программе сортировки. Инициализатором служит список строк, каждой из которых соответствует определенное место в массиве. Символы i-й строки где-то размещены, и указатель на них запоминается в name[i]. Так как размер массива name не специфицирован, компилятор вычислит его по количеству заданных начальных значений. Указатели против многомерных массивов Начинающие программировать на Си иногда не понимают, в чем разница между двумерным массивом и массивом указателей вроде name из приведенного примера. Для двух следующих определений: int a[10][20]; int *b[10];записи a[3][4] и b[3][4] будут синтаксически правильным обращением к некоторому значению типа int. Однако только a является истинно двумерным массивом: для двухсот элементов типа int будет выделена память, а вычисление смещения элемента a[строка][столбец] от начала массива будет вестись по формуле 20 * строка + столбец, учитывающей его прямоугольную природу. Для b же определено только 10 указателей, причем без инициализации. Инициализация должна задаваться явно -либо статически, либо в программе. Предположим, что каждый элемент b указывает на двадцатиэлементный массив, в результате где-то будут выделены пространство, в котором разместятся 200 значений типа int, и еще 10 ячеек для указателей. Важное преимущество массива указателей в том, что строки такого массива могут иметь разные длины. Таким образом, каждый элемент массива b не обязательно указывает на двадцатиэлементный вектор; один может указывать на два элемента, другой - на пятьдесят, а некоторые и вовсе могут ни на что не указывать. Наши рассуждения здесь касались целых значений, однако чаще массивы указателей используются для работы со строками символов, различающимися по длине, как это было в функции month_name. Сравните определение массива указателей и соответствующий ему рисунок: char *name[] = {" Неправильный месяц", " Янв", " Февр", " Март" };
с объявлением и рисунком для двумерного массива: char aname[][15] = {" Неправ. месяц", " Янв", " Февр", " Март" };
Упражнение 5.9. Перепишите программы day_of_year и month_day, используя вместо индексов указатели. Аргументы командной строки В операционной среде, обеспечивающей поддержку Си, имеется возможность передать аргументы или параметры запускаемой программе с помощью командной строки. В момент вызова main получает два аргумента. В первом, обычно называемом argc (сокращение от argument count), стоит количество аргументов, задаваемых в командной строке. Второй, argv (от argument vector), является указателем на массив символьных строк, содержащих сами аргументы. Для работы с этими строками обычно используются указатели нескольких уровней. Простейший пример - программа echo (" эхо" ), которая печатает аргументы своей командной строки в одной строчке, отделяя их друг от друга пробелами. Так, команда echo Здравствуй, мир!Напечатает Здравствуй, мир!По соглашению argv[0] есть имя вызываемой программы, так что значение argc никогда не бывает меньше 1. Если argc равен 1, то в командной строке после имени программы никаких аргументов нет. В нашем примере argc равен 3, и соответственно argv[0], argv[1] и argv[2] суть строки " echo" , " Здравствуй, " и " мир! ". Первый необязательный аргумент - это argv[1], последний - argv[argc-1]. Кроме того, стандарт требует, чтобы argv[argc] всегда был пустым указателем.
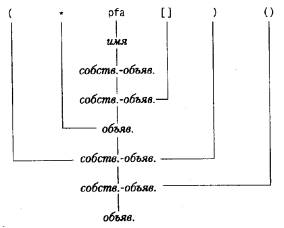
Первая версия программы echo трактует argv как массив символьных указателей. #include < stdio.h> /* эхо аргументов командной строки: версия 1 */main(int argc, char *argv[]){ int i; for (i = 1; i < argc; i++) printf(" %s%s", argv[i], (i < argc-1)? " " : " " ); printf(" \n" ); return 0; }Так как argv - это указатель на массив указателей, мы можем работать с ним как с указателем, а не как с индексируемым массивом. Следующая программа основана на приращении argv, он приращивается так, что его значение в каждый отдельный момент указывает на очередной указатель на char; перебор указателей заканчивается, когда исчерпан argc. Аргумент argv - указатель на начало массива строк аргументов. Использование в ++argv префиксного оператора ++ приведет к тому, что первым будет напечатан argv[1], а не argv[0]. Каждое очередное приращение указателя дает нам следующий аргумент, на который указывает *argv. В это же время значение argc уменьшается на 1, и, когда оно станет нулем, все аргументы будут напечатаны. Инструкцию printf можно было бы написать и так: printf((argc > 1)? " %s " : " %s", *++argv);Как видим, формат в printf тоже может быть выражением. В качестве второго примера возьмем программу поиска образца, рассмотренную в параграфе 4.1, и несколько усовершенствуем ее. Если вы помните, образец для поиска мы " вмонтировали" глубоко в программу, а это, очевидно, не лучшее решение. Построим нашу программу по аналогии с grep из UNIXa, т. е. так, чтобы образец для поиска задавался первым аргументом в командной строке. #include < stdio.h> #include < string.h> #define MAXLINE 1000 int getline(char *line, int max); /* find: печать строк с образцом, заданным 1-м аргументом */main(int argc, char *argv[]){ char line[MAXLINE]; int found == 0; if (argc! = 2) printf(" Используйте в find образец\n" ); else while (getline(line, MAXLINE) > 0) if (strstr(line, argv[1]) > = NULL) { printf (" %s", line); found++; } return found; }Стандартная функция strstr(s, t) возвращает указатель на первую встретившуюся строку t в строке s или NULL, если таковой в s не встретилось. Функция объявлена в заголовочном файле < string.h>. Эту модель можно развивать и дальше, чтобы проиллюстрировать другие конструкции с указателями. Предположим, что мы вводим еще два необязательных аргумента. Один из них предписывает печатать все строки, кроме тех, в которых встречается образец; второй - перед каждой выводимой строкой печатать ее порядковый номер. По общему соглашению для Си-программ в системе UNIX знак минус перед аргументом вводит необязательный признак или параметр. Так, если -x служит признаком слова " кроме", которое изменяет задание на противоположное, а -n указывает на потребность в нумерации строк, то команда find -x -n образецнапечатает все строки, в которых не найден указанный образец, и, кроме того, перед каждой строкой укажет ее номер. Необязательные аргументы разрешается располагать в любом порядке, при этом лучше, чтобы остальная часть программы не зависела от числа представленных аргументов. Кроме того, пользователю было бы удобно, если бы он мог комбинировать необязательные аргументы, например так: find -nx образецА теперь запишем нашу программу. #include < stdio.h> #include < string.h> #define MAXLINE 1000 int getline(char *line, int max); /* find: печать строк образцами из 1-го аргумента */main(int argc, char *argv[]){ char line[MAXLINE]; long lineno = 0; int c, except = 0, number = 0, found = 0; while (--argc > 0 & & (*++argv)[0] == '-') while (c = *++argv[0]) switch (c) { case 'x': except = 1; break; case 'n': number = 1; break; default: printf(" find: неверный параметр %c\n", c); argc = 0; found = -1; break; } if (argc! = 1) printf(" Используйте: find -x -n образец\n" ); else while (getline(line, MAXLINE) > 0) { lineno++; if ((strstr(line, *argv)! = NULL)! = except) { if (number) printf(" %ld: ", lineno); printf(" %s", line); found++; } } return found; }Перед получением очередного аргумента argc уменьшается на 1, а argv " перемещается" на следующий аргумент. После завершения цикла при отсутствии ошибок argc содержит количество еще не обработанных аргументов, a argv указывает на первый из них. Таким образом, argc должен быть равен 1, a *argv указывать на образец. Заметим, что *++argv является указателем на аргумент- строку, a (*++argv)[0] - его первым символом, на который можно сослаться и другим способом: **++argv;Поскольку оператор индексирования [] имеет более высокий приоритет, чем * и ++, круглые скобки здесь обязательны, без них выражение трактовалось бы так же, как *++(argv[0]). Именно такое выражение мы применим во внутреннем цикле, где просматриваются символы конкретного аргумента. Во внутреннем цикле выражение *++argv[0] приращивает указатель argv[0]. Потребность в более сложных выражениях для указателей возникает не так уж часто. Но если такое случится, то разбивая процесс вычисления указателя на два или три шага, вы облегчите восприятие этого выражения. Упражнение 5.10. Напишите программу expr, интерпретирующую обратную польскую запись выражения, задаваемого командной строкой, в которой каждый оператор и операнд представлены отдельным аргументом. Например, expr 2 3 4 + *вычисляется так же, как выражение 2*(3+4). Упражнение 5.11. Усовершенствуйте программы entab и detab (см. упражнения 1.20 и 1.21) таким образом, чтобы через аргументы можно было задавать список " стопов" табуляции. Упражнение 5.12. Расширьте возможности entab и detab таким образом, чтобы при обращении вида entab -m +n" стопы" табуляции начинались с m-й позиции и выполнялись через каждые n позиций. Разработайте удобный для пользователя вариант поведения программы по умолчанию (когда нет никаких аргументов). Упражнение 5.13. Напишите программу tail, печатающую n последних введенных строк. По умолчанию значение n равно 10, но при желании n можно задать с помощью аргумента. Обращение вида tail -nпечатает n последних строк. Программа должна вести себя осмысленно при любых входных данных и любом значении n. Напишите программу так, чтобы наилучшим образом использовать память; запоминание строк организуйте, как в программе сортировки, описанной в параграфе 5.6, а не на основе двумерного массива с фиксированным размером строки. Указатели на функции В Си сама функция не является переменной, но можно определить указатель на функцию и работать с ним, как с обычной переменной: присваивать, размещать в массиве, передавать в качестве параметра функции, возвращать как результат из функции и т. д. Для иллюстрации этих возможностей воспользуемся программой сортировки, которая уже встречалась в настоящей главе. Изменим ее так, чтобы при задании необязательного аргумента -n вводимые строки упорядочивались по их числовому значению, а не в лексикографическом порядке. Сортировка, как правило, распадается на три части: на сравнение, определяющее упорядоченность пары объектов; перестановку, меняющую местами пару объектов, и сортирующий алгоритм, который осуществляет сравнения и перестановки до тех пор, пока все объекты не будут упорядочены. Алгоритм сортировки не зависит от операций сравнения и перестановки, так что передавая ему в качестве параметров различные функции сравнения и перестановки, его можно настроить на различные критерии сортировки. Лексикографическое сравнение двух строк выполняется функцией strcmp (мы уже использовали эту функцию в ранее рассмотренной программе сортировки); нам также потребуется программа numcmp, сравнивающая две строки как числовые значения и возвращающая результат сравнения в том же виде, в каком его выдает strcmp. Эти функции объявляются перед main, а указатель на одну из них передается функции qsort. Чтобы сосредоточиться на главном, мы упростили себе задачу, отказавшись от анализа возможных ошибок при задании аргументов. #include < stdio.h> #include < string.h> #define MAXLINES 5000 /* максимальное число строк */char *lineptr[MAXLINES]; /* указатели на строки текста */ int readlines(char *lineptr[], int nlines); void writelines(char *lineptr[], int nlines); void qsort(void *lineptr[], int left, int right, int (*comp)(void *, void *)); int numcmp(char *, char *); /* сортировка строк */main(int argc, char *argv[]){ int nlines; /* количество прочитанных строк */ int numeric = 0; /* 1, если сорт. по числ. знач. */ if (argc > 1 & & strcmp(argv[1], " -n" ) == 0) numeric = 1; if ((nlines = readlines(lineptr, MAXLINES)) > = 0) { qsort((void **) lineptr, 0, nlines-1, (int (*)(void*, void*))(numeric? numcmp: strcmp)); writelines(lineptr, nlines); return 0; } else { printf(" Bведено слишком много строк\n" ); return 1; }}В обращениях к функциям qsort, strcmp и numcmp их имена трактуются как адреса этих функций, поэтому оператор & перед ними не нужен, как он не был нужен и перед именем массива. Мы написали qsort так, чтобы она могла обрабатывать данные любого типа, а не только строки символов. Как видно из прототипа, функция qsort в качестве своих аргументов ожидает массив указателей, два целых значения и функцию с двумя аргументами-указателями. В качестве аргументов-указателей заданы указатели обобщенного типа void *. Любой указатель можно привести к типу void * и обратно без потери информации, поэтому мы можем обратиться к qsort, предварительно преобразовав аргументы в void *. Внутри функции сравнения ее аргументы будут приведены к нужному ей типу. На самом деле эти преобразования никакого влияния на представления аргументов не оказывают, они лишь обеспечивают согласованность типов для компилятора. /* qsort: сортирует v[left]...v[right] по возрастанию */void qsort(void *v[], int left, int right, int (*comp)(void *, void *)){ int i, last; void swap(void *v[], int, int); if (left > = right) /* ничего не делается, если */ return; /* в массиве менее двух элементов */ swap(v, left, (left + right)/2); last = left; for (i = left+1; i < = right; i++) if ((*comp)(v[i], v[left]) < 0) swap(v, ++last, i); swap(v, left, last); qsort(v, left, last-1, comp); qsort(v, last+1, right, comp); }Повнимательней приглядимся к объявлениям. Четвертый параметр функции qsort: int (*comp)(void *, void *)сообщает, что comp - это указатель на функцию, которая имеет два аргумента- указателя и выдает результат типа int. Использование comp в строке if ((*comp)(v[i], v[left]) < 0)согласуется с объявлением " comp - это указатель на функцию", и, следовательно, *comp - это функция, а (*comp)(v[i], v[left])- обращение к ней. Скобки здесь нужны, чтобы обеспечить правильную трактовку объявления; без них объявление int *comp(void *, void *) /* НЕВЕРНО */говорило бы, что comp - это функция, возвращающая указатель на int, а это совсем не то, что требуется. Мы уже рассматривали функцию strcmp, сравнивающую две строки. Ниже приведена функция numcmp, которая сравнивает две строки, рассматривая их как числа; предварительно они переводятся в числовые значения функцией atof. #include < stdlib.h> /* numcmp: сравнивает s1 и s2 как числа */ int numcmp(char *s1, char *s2){ double v1, v2; v1 = atof(s1); v2 = atof(s2); if (v1 < v2) return -1; else if (v1 > v2) return 1; else return 0; }Функция swap, меняющая местами два указателя, идентична той, что мы привели ранее в этой главе за исключением того, что объявления указателей заменены на void*. void swap(void *v[], int i, int j){ void *temp; temp = v[i]; v[i] = v[j]; v[j] = temp; }Программу сортировки можно дополнить и множеством других возможностей; реализовать некоторые из них предлагается в качестве упражнений. Упражнение 5.14. Модифицируйте программу сортировки, чтобы она реагировала на параметр -r, указывающий, что объекты нужно сортировать в обратном порядке, т. е. в порядке убывания. Обеспечьте, чтобы -r работал и вместе с -n. Упражнение 5.15. Введите в программу необязательный параметр -f, задание которого делало бы неразличимыми символы нижнего и верхнего регистров (например, a и A должны оказаться при сравнении равными). Упражнение 5.16. Предусмотрите в программе необязательный параметр -d, который заставит программу при сравнении учитывать только буквы, цифры и пробелы. Организуйте программу таким образом, чтобы этот параметр мог работать вместе с параметром -f. Упражнение 5.17. Реализуйте в программе возможность работы с полями: возможность сортировки по полям внутри строк. Для каждого поля предусмотрите свой набор параметров. Предметный указатель этой книги (Имеется в виду оригинал книги на английским языке. – Примеч. пер.) упорядочивался с параметрами: -df для терминов и -n для номеров страниц. Сложные объявления Иногда Си ругают за синтаксис объявлений, особенно тех, которые содержат в себе указатели на функции. Таким синтаксис получился в результате нашей попытки сделать похожими объявления объектов и их использование. В простых случаях этот синтаксис хорош, однако в сложных ситуациях он вызывает затруднения, поскольку объявления перенасыщены скобками и их невозможно читать слева направо. Проблему иллюстрирует различие следующих двух объявлений: int *f(); /* f: функция, возвращающая ук-ль на int */int (*pf)(); /* pf: ук-ль на ф-цию, возвращающую int */Приоритет префиксного оператора * ниже, чем приоритет (), поэтому во втором случае скобки необходимы. Хотя на практике по-настоящему сложные объявления встречаются редко, все же важно знать, как их понимать, а если потребуется, и как их конструировать. Укажем хороший способ: объявления можно синтезировать, двигаясь небольшими шагами с помощью typedef, этот способ рассмотрен в параграфе 6.7. В настоящем параграфе на примере двух программ, осуществляющих преобразования правильных Си-объявлений в соответствующие им словесные описания и обратно, мы демонстрируем иной способ конструирования объявлений. Словесное описание читается слева направо. Первая программа, dcl, - более сложная. Она преобразует Си-объявления в словесные описания так, как показано в следующих примерах: char **argv argv: указ. на указ. на charint (*daytab)[13] daytab: указ. на массив[13] из intint (*daytab)[13] daytab: массив[13] из указ. на intvoid *comp() comp: функц. возвр. указ. на voidvoid (*comp)() comp: указ. на функц. возвр. voidchar (*(*x())[])() x: функц. возвр. указ. на массив[] из указ. на функц. возвр. charchar(*(*x[3])())[5] x: массив[3] из указ. на функц. возвр. указ. на массив[5] из charФункция dcl в своей работе использует грамматику, специфицирующую объявитель. Эта грамматика строго изложена в параграфе 8.5 приложения A, а в упрощенном виде записывается так: объявитель: необязательные * собственно-объявительсобственно-объявитель: имя (объявитель) собственно-объявитель() собственно-объявитель [необязательный размер]Говоря простым языком, объявитель есть собственно-объявитель, перед которым может стоять * (т. е. одна или несколько звездочек), где собственно- объявитель есть имя, или объявитель в скобках, или собственно-объявитель с последующей парой скобок, или собственно-объявитель с последующей парой квадратных скобок, внутри которых может быть помещен размер. Эту грамматику можно использовать для грамматического разбора объявлений. Рассмотрим, например, такой объявитель: (*pfa[])()Имя pfa будет классифицировано как имя и, следовательно, как собственно- объявитель. Затем pfa[] будет распознано как собственно-объявитель, а *pfa[] - как объявитель и, следовательно, (*pfa[]) есть собственно-объявитель. Далее, (*pfa[])() есть собственно-объявитель и, таким образом, объявитель. Этот грамматический разбор можно проиллюстрировать деревом разбора, приведенным на следующей странице (где собственно-объявитель обозначен более коротко, а именно собств.-объяв.). Сердцевиной программы обработки объявителя является пара функций dcl и dirdcl, осуществляющих грамматический разбор объявления согласно приведенной грамматике. Поскольку грамматика определена рекурсивно, эти функции обращаются друг к другу рекурсивно, по мере распознавания отдельных частей объявления. Метод, примененный в обсуждаемой программе для грамматического разбора, называется рекурсивным спуском.
Приведенные программы служат только иллюстративным целям и не вполне надежны. Что касается dcl, то ее возможности существенно ограничены. Она может работать только с простыми типами вроде char и int и не справляется с типами аргументов в функциях и с квалификаторами вроде const. Лишние пробелы для нее опасны. Она не предпринимает никаких мер по выходу из ошибочной ситуации, и поэтому неправильные описания также ей противопоказаны. Устранение этих недостатков мы оставляем для упражнений. Ниже приведены глобальные переменные и главная программа main. #include < stdio.h> #include < string.h> #include < ctype.h> #define MAXTOKEN 100 enum {NAME, PARENS, BRACKETS}; void dcl(void); void dirdcl(void); int gettoken(void); int tokentype; /* тип последней лексемы */char token[MAXTOKEN]; /* текст последней лексемы */ char name[MAXTOKEN]; /* имя */char datatype[MAXTOKEN]; /* тип = char, int и т.д. */char out[1000]; /* выдаваемый текст */ main() /* преобразование объявления в словесное описание */{ while (gettoken()! = EOF) { /* 1-я лексема в строке */ strcpy(datatype, token); /* это тип данных */ out[0] = '\0'; dcl(); /* разбор остальной части строки */ if (tokentype! = '\n') printf(" синтаксическая ошибка\n" ); printf(" %s: %s %s\n", name, out, datatype); } return 0; }Функция gettoken пропускает пробелы и табуляции и затем получает следующую лексему из ввода: " лексема" (token) - это имя, или пара круглых скобок, или пара квадратных скобок (быть может, с помещенным в них числом), или любой другой единичный символ. int gettoken(void) /* возвращает следующую лексему */{ int с, getch(void); void ungetch(int); char *p = token; while ((c = getch()) == ' ' || с = '\t'); if (c == '(') { if ((c = getch())== ')' { strcpy(token, " ()" ); return tokentype = PARENS; } else { ungetch(c); return tokentype = '('; } } else if (c == '['){ for (*p++ = c; (*p++ = getch())! = ']'; ); *p = '\0'; return tokentype = BRACKETS; } else if (isalpha(c)) { for (*p++ = c; isalnum(c = getch()); ) *p++ = c; *p = '\0'; ungetch(c); return tokentype = NAME; } else return tokentype = c; }Функции getch и ungetch были рассмотрены в главе 4. Обратное преобразование реализуется легче, особенно если не придавать значения тому, что будут генерироваться лишние скобки. Программа undcl превращает фразу вроде " x есть функция, возвращающая указатель на массив указателей на функции, возвращающие char", которую мы будем представлять в виде х () * [] * () charв объявление char (*(*х())[])()Такой сокращенный входной синтаксис позволяет повторно пользоваться функцией gettoken. Функция undcl использует те же самые внешние переменные, что и dcl. /* undcl: преобразует словесное описание в объявление */main(){ int type; char temp[MAXTOKEN]; while (gettoken()! = EOF) { strcpy(out, token); while ((type = gettoken())! = '\n') if (type == PARENS || type == BRACKETS) strcat(out, token); else if (type == '*' ) { sprintf(temp, " (*%s)", out); strcpy(out, temp); } else if (type == NAME) { sprintf(temp, " %s %s", token, out); strcpy(out, temp); } else printf( " неверный элемент %s в фразе\n", token); printf(" %s\n", out); } return 0; }Упражнение 5.18. Видоизмените dcl таким образом, чтобы она обрабатывала ошибки во входной информации. Упражнение 5.19. Модифицируйте undcl так, чтобы она не генерировала лишних скобок. Упражнение 5.20. Расширьте возможности dcl, чтобы dcl обрабатывала объявления с типами аргументов функции, квалификаторами вроде const и т. п. Глава 6. Структуры 6.1 Основные сведения о структурах Структура - это одна или несколько переменных (возможно, различных типов), которые для удобства работы с ними сгруппированы под одним именем. (В некоторых языках, в частности в Паскале, структуры называются записями.) Структуры помогают в организации сложных данных (особенно в больших программах), поскольку позволяют группу связанных между собой переменных трактовать не как множество отдельных элементов, а как единое целое. Традиционный пример структуры - строка платежной ведомости. Она содержит такие сведения о служащем, как его полное имя, адрес, номер карточки социального страхования, зарплата и т. д. Некоторые из этих характеристик сами могут быть структурами: например, полное имя состоит из нескольких компонент (фамилии, имени и отчества); аналогично адрес, и даже зарплата. Другой пример (более типичный для Си) - из области графики: точка есть пара координат, прямоугольник есть пара точек и т. д. Главные изменения, внесенные стандартом ANSI в отношении структур, - это введение для них операции присваивания. Структуры могут копироваться, над ними могут выполняться операции присваивания, их можно передавать функциям в качестве аргументов, а функции могут возвращать их в качестве результатов. В большинстве компиляторов уже давно реализованы эти возможности, но теперь они точно оговорены стандартом. Для автоматических структур и массивов теперь также допускается инициализация.
Указанные две компоненты можно поместить в структуру, объявленную, например, следующим образом: struct point { int x; int y; };Объявление структуры начинается с ключевого слова struct и содержит список объявлений, заключенный в фигурные скобки. За словом struct может следовать имя, называемое тегом структуры (от английского слова tag — ярлык, этикетка. — Примеч. пер.), point в нашем случае. Тег дает название структуре данного вида и далее может служить кратким обозначением той части объявления, которая заключена в фигурные скобки. Перечисленные в структуре переменные называются элементами (members - В некоторых изданиях, в том числе во 2-м издании на русским языке этой книги structure members переводится как члены структуры. - Примеч. ред). Имена элементов и тегов без каких-либо коллизий могут совпадать с именами обычных переменных (т. е. не элементов), так как они всегда различимы по контексту. Более того, одни и те же имена элементов могут встречаться в разных структурах, хотя, если следовать хорошему стилю программирования, лучше одинаковые имена давать только близким по смыслу объектам. Объявление структуры определяет тип. За правой фигурной скобкой, закрывающей список элементов, могут следовать переменные точно так же, как они могут быть указаны после названия любого базового типа. Таким образом, выражение struct {...} x, y, z;с точки зрения синтаксиса аналогично выражению int х, у, z;в том смысле, что и то и другое объявляет x, y и z переменными указанного типа; и то и другое приведет к выделению памяти соответствующего размера. Объявление структуры, не содержащей списка переменных, не резервирует памяти; оно просто описывает шаблон, или образец структуры. Однако если структура имеет тег, то этим тегом далее можно пользоваться при определении структурных объектов. Например, с помощью заданного выше описания структуры point строка struct point pt;определяет структурную переменную pt типа struct point. Структурную переменную при ее определении можно инициализировать, формируя список инициализаторов ее элементов в виде константных выражений: struct point maxpt = {320, 200};Инициализировать автоматические структуры можно также присваиванием или обращением к функции, возвращающей структуру соответствующего типа. Доступ к отдельному элементу структуры осуществляется посредством конструкции вида: имя-структуры.элементОператор доступа к элементу структуры. соединяет имя структуры и имя элемента. Чтобы напечатать, например, координаты точки pt, годится следующее обращение к printf: printf(" %d, %d", pt.x, pt.y);Другой пример: чтобы вычислить расстояние от начала координат (0, 0) до pt, можно написать double dist, sqrt(double); dist = sqrt((double)pt.x * pt.x + (double)pt.y * pt.y);Структуры могут быть вложены друг в друга. Одно из возможных представлений прямоугольника - это пара точек на углах одной из его диагоналей:  struct rect { struct point pt1; struct point pt2; }; struct rect { struct point pt1; struct point pt2; }; Структура rect содержит две структуры point. Если мы объявим screen как struct rect screen;то screen.pt1.xобращается к координате x точки pt1 из screen. Структуры и функции Единственно возможные операции над структурами - это их копирование, присваивание, взятие адреса с помощью & и осуществление доступа к ее элементам. Копирование и присваивание также включают в себя передачу функциям аргументов и возврат ими значений. Структуры нельзя сравнивать. Инициализировать структуру можно списком константных значений ее элементов; автоматическую структуру также можно инициализировать присваиванием. Чтобы лучше познакомиться со структурами, напишем несколько функций, манипулирующих точками и прямоугольниками. Возникает вопрос: а как передавать функциям названные объекты? Существует по крайней мере три подхода: передавать компоненты по отдельности, передавать всю структуру целиком и передавать указатель на структуру. Каждый подход имеет свои плюсы и минусы. Первая функция, makepoint, получает два целых значения и возвращает структуру point. /* makepoint: формирует точку по компонентам x и y */struct point makepoint(int х, int у){ struct point temp; temp.x = х; temp.у = у; return temp; }Заметим: никакого конфликта между именем аргумента и именем элемента структуры не возникает; более того, сходство подчеркивает родство обозначаемых им объектов. Теперь с помощью makepoint можно выполнять динамическую инициализацию любой структуры или формировать структурные аргументы для той или иной функции: struct rect screen; struct point middle; struct point makepoint(int, int); screen.pt1 = makepoint(0, 0); screen.pt2 = makepoint(XMAX, YMAX); middle = makepoint((screen.pt1.x + screen.pt2.x)/2, (screen.pt1.y + screen.pt2.y)/2);Следующий шаг состоит в определении ряда функций, реализующих различные операции над точками. В качестве примера рассмотрим следующую функцию: /* addpoint: сложение двух точек */struct point addpoint(struct point p1, struct point p2){ p1.x += p2.x; p1.y += p2.y; return p1; }Здесь оба аргумента и возвращаемое значение - структуры. Мы увеличиваем компоненты прямо в р1 и не используем для этого временной переменной, чтобы подчеркнуть, что структурные параметры передаются по значению так же, как и любые другие. В качестве другого примера приведем функцию ptinrect, которая проверяет: находится ли точка внутри прямоугольника, относительно которого мы принимаем соглашение, что в него входят его левая и нижняя стороны, но не входят верхняя и правая. /* ptinrect: возвращает 1, если p в r, и 0 в противном случае */int ptinrect(struct point р, struct rect r){ return p.x > = r.pt1.x & & p.x < r.pt2.x & & p.y > = r.pt1.y & & p.y < r.pt2.y; }Здесь предполагается, что прямоугольник представлен в стандартном виде, т.е. координаты точки pt1 меньше соответствующих координат точки pt2. Следующая функция гарантирует получение прямоугольника в каноническом виде. #define min(a, b) ((a) < (b)? (a): (b))#define max(a, b) ((a) > (b)? (a): (b)) /* canonrect: канонизация координат прямоугольника */struct rect canonrect(struct rect r){ struct rect temp; temp.pt1.x = min(r.pt1.x, r.pt2.x); temp.ptl.y = min(r.pt1.y, r.pt2.у); temp.pt2.x = max(r.pt1.x, r.pt2.x); temp.pt2.y = max(r.pt1.y, r.pt2.y); return temp; }Если функции передается большая структура, то, чем копировать ее целиком, эффективнее передать указатель на нее. Указатели на структуры ничем не отличаются от указателей на обычные переменные. Объявление struct point *pp;сообщает, что pp - это указатель на структуру типа struct point. Если pp указывает на структуру point, то *pp - это сама структура, а (*pp).x и (*pp).y - ее элементы. Используя указатель pp, мы могли бы написать struct point origin, *pp; pp = & origin; printf(" origin: (%d, %d)\n", (*pp).x, (*pp).y);Скобки в (*pp).x необходимы, поскольку приоритет оператора. выше, чем приоритет *. Выражение *pp.x будет проинтерпретировано как *(pp.x), что неверно, поскольку pp.x не является указателем. Указатели на структуры используются весьма часто, поэтому для доступа к ее элементам была придумана еще одна, более короткая форма записи. Если p — указатель на структуру, то р-> элемент-структурыесть ее отдельный элемент. (Оператор -> состоит из знака -, за которым сразу следует знак >.) Поэтому printf можно переписать в виде printf(" origin: (%d, %d)\n", pp-> х, pp-> y);Операторы. и -> выполняются слева направо. Таким образом, при наличии объявления struct rect r, *rp = & r;следующие четыре выражения будут эквивалентны: r.pt1.xrp-> pt1.x(r.pt1).x(rp-> pt1).xОператоры доступа к элементам структуры. и -> вместе с операторами вызова функции () и индексации массива [] занимают самое высокое положение в иерархии приоритетов и выполняются раньше любых других операторов. Например, если задано объявление struct { int len; char *str; } *p;то ++p-> lenувеличит на 1 значение элемента структуры len, а не указатель p, поскольку в этом выражении как бы неявно присутствуют скобки: ++(p-> len). Чтобы изменить порядок выполнения операций, нужны явные скобки. Так, в (++р)-> len, прежде чем взять значение len, программа прирастит указатель p. В (р++)-> len указатель p увеличится после того, как будет взято значение len (в последнем случае скобки не обязательны). По тем же правилам *p-> str обозначает содержимое объекта, на который указывает str; *p-> str++ прирастит указатель str после получения значения объекта, на который он указывал (как и в выражении *s++), (*p-> str)++ увеличит значение объекта, на который указывает str; *p++-> str увеличит p после получения того, на что указывает str. Массивы структур Рассмотрим программу, определяющую число вхождений каждого ключевого слова в текст Си-программы. Нам нужно уметь хранить ключевые слова в виде массива строк и счетчики ключевых слов в виде массива целых. Один из возможных вариантов - это иметь два параллельных массива: char *keyword[NKEYS]; int keycount[NKEYS];Однако именно тот факт, что они параллельны, подсказывает нам другую организацию хранения - через массив структур. Каждое ключевое слово можно описать парой характеристик char *word; int count;Такие пары составляют массив. Объявление struct key { char *word; int count; } keytab[NKEYS];объявляет структуру типа key и определяет массив keytab, каждый элемент которого является структурой этого типа и которому где-то будет выделена память. Это же можно записать и по-другому: struct key { char *word; int count; }; struct key keytab[NKEYS];Так как keytab содержит постоянный набор имен, его легче всего сделать внешним массивом и инициализировать один раз в момент определения. Инициализация структур аналогична ранее демонстрировавшимся инициализациям - за определением следует список инициализаторов, заключенный в фигурные скобки: struct key { char *word; int count; } keytab[] = { " auto", 0, " break", 0, " case", 0, " char", 0, " const", 0, " continue", 0, " default", 0, /*...*/ " unsigned", 0, " void", 0, " volatile", 0, " while", 0};Инициализаторы задаются парами, чтобы соответствовать конфигурации структуры. Строго говоря, пару инициализаторов для каждой отдельной структуры следовало бы заключить в фигурные скобки, как, например, в { " auto", 0 }, { " break", 0 }, { " case", 0 }, ...Однако когда инициализаторы - простые константы или строки символов и все они имеются в наличии, во внутренних скобках нет необходимости. Число элементов массива keytab будет вычислено по количеству инициализаторов, поскольку они представлены полностью, а внутри квадратных скобок " []" ничего не задано. Программа подсчета ключевых слов начинается с определения keytab. Программа main читает ввод, многократно обращаясь к функции getword и получая на каждом ее вызове очередное слово. Каждое слово ищется в keytab. Для этого используется функция бинарного поиска, которую мы написали в главе 3. Список ключевых слов должен быть упорядочен в алфавитном порядке. |
Последнее изменение этой страницы: 2017-03-14; Просмотров: 567; Нарушение авторского права страницы