|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Структуры со ссылками на себя
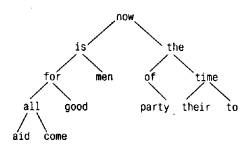
Предположим, что мы хотим решить более общую задачу - написать программу, подсчитывающую частоту встречаемости для любых слов входного потока. Так как список слов заранее не известен, мы не можем предварительно упорядочить его и применить бинарный поиск. Было бы неразумно пользоваться и линейным поиском каждого полученного слова, чтобы определять, встречалось оно ранее или нет - в этом случае программа работала бы слишком медленно. (Более точная оценка: время работы такой программы пропорционально квадрату количества слов.) Как можно организовать данные, чтобы эффективно справиться со списком произвольных слов? Один из способов - постоянно поддерживать упорядоченность уже полученных слов, помещая каждое новое слово в такое место, чтобы не нарушалась имеющаяся упорядоченность. Делать это передвижкой слов в линейном массиве не следует, - хотя бы потому, что указанная процедура тоже слишком долгая. Вместо этого мы воспользуемся структурой данных, называемой бинарным деревом. В дереве на каждое отдельное слово предусмотрен " узел", который содержит: - указатель на текст слова; - счетчик числа встречаемости; - указатель на левый сыновний узел; - указатель на правый сыновний узел.У каждого узла может быть один или два сына, или узел вообще может не иметь сыновей. Узлы в дереве располагаются так, что по отношению к любому узлу левое поддерево содержит только те слова, которые лексикографически меньше, чем слово данного узла, а правое - слова, которые больше него. Вот как выглядит дерево, построенное для фразы " now is the time for all good men to come to the aid of their party" (" настало время всем добрым людям помочь своей партии" ), по завершении процесса, в котором для каждого нового слова в него добавлялся новый узел:
Чтобы определить, помещено ли уже в дерево вновь поступившее слово, начинают с корня, сравнивая это слово со словом из корневого узла. Если они совпали, то ответ на вопрос — положительный. Если новое слово меньше слова из дерева, то поиск продолжается в левом поддереве, если больше, то — в правом. Если же в выбранном направлении поддерева не оказалось, то этого слова в дереве нет, а пустующая позиция, говорящая об отсутствии поддерева, как раз и есть то место, куда нужно " подвесить" узел с новым словом. Описанный процесс по сути рекурсивен, так как поиск в любом узле использует результат поиска в одном из своих сыновних узлов. В соответствии с этим для добавления узла и печати дерева здесь наиболее естественно применить рекурсивные функции. Вернемся к описанию узла, которое удобно представить в виде структуры с четырьмя компонентами: struct tnode { /* узел дерева */ char *word; /* указатель на текст */ int count; /* число вхождений */ struct tnode *left; /* левый сын */ struct tnode *right; /* правый сын */};Приведенное рекурсивное определение узла может показаться рискованным, но оно правильное. Структура не может включать саму себя, но ведь struct tnode *left;объявляет left как указатель на tnode, а не сам tnode. Иногда возникает потребность во взаимоссылающихся структурах: двух структурах, ссылающихся друг на друга. Прием, позволяющий справиться с этой задачей, демонстрируется следующим фрагментом: Вся программа удивительно мала - правда, она использует вспомогательные программы вроде getword, уже написанные нами. Главная программа читает слова с помощью getword и вставляет их в дерево посредством addtree. #include < stdio.h> #include < ctype.h> #include < string.h> #define MAXWORD 100 struct tnode *addtree(struct tnode *, char *); void treeprint(struct tnode *); int getword(char *, int); /* подсчет частоты встречаемости слов */main(){ struct tnode *root; char word[MAXWORD]; root = NULL; while (getword (word, MAXWORD)! = EOF) if (isalpha(word[0])) root = addtree(root, word); treeprint(root); return 0; }Функция addtree рекурсивна. Первое слово функция main помещает на верхний уровень дерева (корень дерева). Каждое вновь поступившее слово сравнивается со словом узла и " погружается" или в левое, или в правое поддерево с помощью рекурсивного обращения к addtree. Через некоторое время это слово обязательно либо совпадет с каким-нибудь из имеющихся в дереве слов (в этом случае к счетчику будет добавлена 1), либо программа встретит пустую позицию, что послужит сигналом для создания нового узла и добавления его к дереву. Создание нового узла сопровождается тем, что addtree возвращает на него указатель, который вставляется в узел родителя. struct tnode *talloc(void); char *strdup(char *); /* addtree: добавляет узел со словом w в р или ниже него */struct tnode *addtree(struct tnode *p, char *w){ int cond; if (р == NULL) { /* слово встречается впервые */ p = talloc(); /* создается новый узел */ p-> word = strdup(w); p-> count = 1; p-> left = p-> right = NULL; } else if ((cond = strcmp(w, p-> word)) == 0) p-> count++; /* это слово уже встречалось */ else if (cond < 0) /* меньше корня левого поддерева */ p-> left = addtree(p-> left, w); else /* больше корня правого поддерева */ p-> right = addtree(p-> right, w); return p; }Память для нового узла запрашивается с помощью программы talloc, которая возвращает указатель на свободное пространство, достаточное для хранения одного узла дерева, а копирование нового слова в отдельное место памяти осуществляется с помощью strdup. (Мы рассмотрим эти программы чуть позже.) В тот (и только в тот) момент, когда к дереву подвешивается новый узел, происходит инициализация счетчика и обнуление указателей на сыновей. Мы опустили (что неразумно) контроль ошибок, который должен выполняться при получении значений от strdup и talloc. Функция treeprint печатает дерево в лексикографическом порядке: для каждого узла она печатает его левое поддерево (все слова, которые меньше слова данного узла), затем само слово и, наконец, правое поддерево (слова, которые больше слова данного узла). /* treeprint: упорядоченная печать дерева р */void treeprint(struct tnode *p){ if (p! = NULL) { treeprint (p-> left); printf(" %4d %s\n", p-> count, p-> word); treeprint(p-> right); }}Если вы не уверены, что досконально разобрались в том, как работает рекурсия, " проиграйте" действия treeprint на дереве, приведенном выше. Практическое замечание: если дерево " несбалансировано" (что бывает, когда слова поступают не в случайном порядке), то время работы программы может сильно возрасти. Худший вариант, когда слова уже упорядочены; в этом случае затраты на вычисления будут такими же, как при линейном поиске. Существуют обобщения бинарного дерева, которые не страдают этим недостатком, но здесь мы их не описываем. Прежде чем завершить обсуждение этого примера, сделаем краткое отступление от темы и поговорим о механизме запроса памяти. Очевидно, хотелось бы иметь всего лишь одну функцию, выделяющую память, даже если эта память предназначается для разного рода объектов. Но если одна и та же функция обеспечивает память, скажем) и для указателей на char, и для указателей на struct tnode, то возникают два вопроса. Первый: как справиться с требованием большинства машин, в которых объекты определенного типа должны быть выровнены (например, int часто должны размещаться, начиная с четных адресов)? И второе: как объявить функцию-распределитель памяти, которая вынуждена в качестве результата возвращать указатели разных типов? Вообще говоря, требования, касающиеся выравнивания, можно легко выполнить за счет некоторого перерасхода памяти. Однако для этого возвращаемый указатель должен быть таким, чтобы удовлетворялись любые ограничения, связанные с выравниванием. Функция alloc, описанная в главе 5, не гарантирует нам любое конкретное выравнивание, поэтому мы будем пользоваться стандартной библиотечной функцией malloc, которая это делает. В главе 8 мы покажем один из способов ее реализации. Вопрос об объявлении типа таких функций, как malloc, является камнем преткновения в любом языке с жесткой проверкой типов. В Си вопрос решается естественным образом: malloc объявляется как функция, которая возвращает указатель на void. Полученный указатель затем явно приводится к желаемому типу (Замечание о приведении типа величины, возвращаемой функцией malloc, нужно переписать. Пример коpректен и работает, но совет является спорным в контексте стандартов ANSI/ISO 1988-1989 г. На самом деле это не обязательно (при условии что приведение void* к ALMOSTANYTYPE* выполняется автоматически) и возможно даже опасно, если malloc или ее заместитель не может быть объявлен как функция, возвращающая void*. Явное приведение типа может скрыть случайную ошибку. В другие времена (до появления стандарта ANSI) приведение считалось обязательным, что также справедливо и для C++. — Примеч. авт.). Описания malloc и связанных с ней функций находятся в стандартном заголовочном файле < stdlib.h>. Таким образом, функцию talloc можно записать так: #include < stdlib.h> /* talloc: создает tnode */struct tnode *talloc(void){ return (struct tnode *) malloc(sizeof(struct tnode)); }Функция strdup просто копирует строку, указанную в аргументе, в место, полученное с помощью malloc: char *strdup(char *s) /* делает дубликат s */{ char *p; p = (char *) malloc(strlen(s)+1); /* +1 для '\0' */ if (p! = NULL) strcpy(p, s); return p; }Функция malloc возвращает NULL, если свободного пространства нет; strdup возвращает это же значение, оставляя заботу о выходе из ошибочной ситуации вызывающей программе. Память, полученную с помощью malloc, можно освободить для повторного использования, обратившись к функции free (см. главы 7 и 8). Упражнение 6.2. Напишите программу, которая читает текст Си-программы и печатает в алфавитном порядке все группы имен переменных, в которых совпадают первые 6 символов, но последующие в чем-то различаются. Не обрабатывайте внутренности закавыченных строк и комментариев. Число 6 сделайте параметром, задаваемым в командной строке. Упражнение 6.3. Напишите программу печати таблицы " перекрестных ссылок", которая будет печатать все слова документа и указывать для каждого из них номера строк, где оно встретилось. Программа должна игнорировать " шумовые" слова, такие как " и", " или" и пр. Упражнение 6.4. Напишите программу, которая печатает весь набор различных слов, образующих входной поток, в порядке возрастания частоты их встречаемости. Перед каждым словом должно быть указано число вхождений. Просмотр таблиц В этом параграфе, чтобы проиллюстрировать новые аспекты применения структур, мы напишем ядро пакета программ, осуществляющих вставку элементов в таблицы и их поиск внутри таблиц. Этот пакет - типичный набор программ, с помощью которых работают с таблицами имен в любом макропроцессоре или компиляторе. Рассмотрим, например, инструкцию #define. Когда встречается строка вида #define IN 1имя IN и замещающий его текст 1 должны запоминаться в таблице. Если затем имя IN встретится в инструкции, например в state = IN;это должно быть заменено на 1. Существуют две программы, манипулирующие с именами и замещающими их текстами. Это install(s, t), которая записывает имя s и замещающий его текст t в таблицу, где s и t - строки, и lookup(s), осуществляющая поиск s в таблице и возвращающая указатель на место, где имя s было найдено, или NULL, если s в таблице не оказалось. Алгоритм основан на хэш-поиске: поступающее имя свертывается в неотрицательное число (хэш-код), которое затем используется в качестве индекса в массиве указателей. Каждый элемент этого массива является указателем на начало связанного списка блоков, описывающих имена с данным хэш-кодом. Если элемент массива равен NULL, это значит, что имен с соответствующим хэш-кодом нет
Блок в списке - это структура, содержащая указатели на имя, на замещающий текст и на следующий блок в списке; значение NULL в указателе на следующий блок означает конец списка. struct nlist { /* элемент таблицы */ struct nlist *next; /* указатель на следующий элемент */ char *name; /* определенное имя */ char *defn; /* замещающий текст */};А вот как записывается определение массива указателей: #define HASHSIZE 101static struct nlist *hashtab[HASHSIZE]; /* таблица указателей */Функция хэширования, используемая в lookup и install, суммирует коды символов в строке и в качестве результата выдаст остаток от деления полученной суммы на размер массива указателей. Это не самая лучшая функция хэширования, но достаточно лаконичная и эффективная. /* hash: получает хэш-код для строки s */unsigned hash(char *s){ unsigned hashval; for (hashval = 0; *s! = '\0'; s++) hashval = *s + 31 * hashval; return hashval % HASHSIZE; }Беззнаковая арифметика гарантирует, что хэш-код будет неотрицательным. Хэширование порождает стартовый индекс для массива hashtab; если соответствующая строка в таблице есть, она может быть обнаружена только в списке блоков, на начало которого указывает элемент массива hashtab с этим индексом. Поиск осуществляется с помощью lookup. Если lookup находит элемент с заданной строкой, то возвращает указатель на нее, если не находит, то возвращает NULL. /* lookup: ищет s */struct nlist *lookup(char *s){ struct nlist *np; for (np = hashtab[hash(s)]; np! = NULL; np = np-> next) if (strcmp(s, np-> name) == 0) return np; /* нашли */ return NULL; /* не нашли */}В for-цикле функции lookup для просмотра списка используется стандартная конструкция for (ptr = head; ptr! = NULL; ptr = ptr-> next)...Функция install обращается к lookup, чтобы определить, имеется ли уже вставляемое имя. Если это так, то старое определение будет заменено новым. В противном случае будет образован новый элемент. Если запрос памяти для нового элемента не может быть удовлетворен, функция install выдает NULL. struct nlist *lookup(char *); char *strdup(char *); /* install: заносит имя и текст (name, defn) в таблицу */struct nlist *install(char *name, char *defn){ struct nlist *np; unsigned hashval; if ((np = lookup(name)) == NULL) { /* не найден */ np = (struct nlist *) malloc(sizeof(*np)); if (np == NULL || (np-> name = strdup(name)) == NULL) return NULL; hashval = hash(name); np-> next = hashtab[hashval]; hashtab[hashval] = np; } else /* уже имеется */ free((void *) np-> defn); /* освобождаем прежний defn */ if ((np-> defn = strdup(defn)) == NULL) return NULL; return np; }Упражнение 6.5. Напишите функцию undef, удаляющую имя и определение из таблицы, организация которой поддерживается функциями lookup и install. Упражнение 6.6. Реализуйте простую версию #define-npoцeccopa (без аргументов), которая использовала бы программы этого параграфа и годилась бы для Си-программ. Вам могут помочь программы getch и ungetch. Средство typedef Язык Си предоставляет средство, называемое typedef, которое позволяет давать типам данных новые имена. Например, объявление typedef int Length;делает имя Length синонимом int. С этого момента тип Length можно применять в объявлениях, в операторе приведения и т. д. точно так же, как тип int: Length len, maxlen; Length *lengths[];Аналогично объявление typedef char *String;делает String синонимом char *, т. e. указателем на char, и правомерным будет, например, следующее его использование: String р, lineptr[MAXLINES], alloc(int); int strcmp(String, String); p = (String) malloc(100);Заметим, что объявляемый в typedef тип стоит на месте имени переменной в обычном объявлении, а не сразу за словом typedef. С точки зрения синтаксиса слово typedef напоминает класс памяти - extern, static и т. д. Имена типов записаны с заглавных букв для того, чтобы они выделялись. Для демонстрации более сложных примеров применения typedef воспользуемся этим средством при задании узлов деревьев, с которыми мы уже встречались в данной главе. typedef struct tnode *Treeptr; typedef struct tnode { /* узел дерева: */ char *word; /* указатель на текст */ int count; /* число вхождений */ Treeptr left; /* левый сын */ Treeptr right; /* правый сын */} Treenode;В результате создаются два новых названия типов: Treenode (структура) и Treeptr (указатель на структуру). Теперь программу talloc можно записать в следующем виде: Treeptr talloc(void){ return (Treeptr) malloc(sizeof(Treenode)); }Следует подчеркнуть, что объявление typedef не создает объявления нового типа, оно лишь сообщает новое имя уже существующему типу. Никакого нового смысла эти новые имена не несут, они объявляют переменные в точности с теми же свойствами, как если бы те были объявлены напрямую без переименования типа. Фактически typedef аналогичен #define с тем лишь отличием, что при интерпретации компилятором он может справиться с такой текстовой подстановкой, которая не может быть обработана препроцессором. Например typedef int (*PFI)(char *, char *);создает тип PFI - " указатель на функцию (двух аргументов типа char *), возвращающую int", который, например, в программе сортировки, описанной в главе 5, можно использовать в таком контексте: PFI strcmp, numcmp;Помимо просто эстетических соображений, для применения typedef существуют две важные причины. Первая - параметризация программы, связанная с проблемой переносимости. Если с помощью typedef объявить типы данных, которые, возможно, являются машинно-зависимыми, то при переносе программы на другую машину потребуется внести изменения только в определения typedef. Одна из распространенных ситуаций - использование typedef-имен для варьирования целыми величинами. Для каждой конкретной машины это предполагает соответствующие установки short, int или long, которые делаются аналогично установкам стандартных типов, например size_t и ptrdiff_t. Вторая причина, побуждающая к применению typedef, - желание сделать более ясным текст программы. Тип, названный Тreeptr (от английских слов tree - дерево и pointer - указатель), более понятен, чем тот же тип, записанный как указатель на некоторую сложную структуру. Объединения Объединение - это переменная, которая может содержать (в разные моменты времени) объекты различных типов и размеров. Все требования относительно размеров и выравнивания выполняет компилятор. Объединения позволяют хранить разнородные данные в одной и той же области памяти без включения в программу машинно-зависимой информации. Эти средства аналогичны вариантным записям в Паскале. Примером использования объединений мог бы послужить сам компилятор, заведующий таблицей символов, если предположить, что константа может иметь тип int, float или являться указателем на символ и иметь тип char *. Значение каждой конкретной константы должно храниться в переменной соответствующего этой константе типа. Работать с таблицей символов всегда удобнее, если значения занимают одинаковую по объёму память и запоминаются в одном и том же месте независимо от своего типа. Цель введения в программу объединения - иметь переменную, которая бы на законных основаниях хранила в себе значения нескольких типов. Синтаксис объединений аналогичен синтаксису структур. Приведем пример объединения. union u_tag { int ival; float fval; char *sval; } u;Переменная u будет достаточно большой, чтобы в ней поместилась любая переменная из указанных трех типов: точный ее размер зависит от реализации. Значение одного из этих трех типов может быть присвоено переменной u и далее использовано в выражениях, если это правомерно, т. е. если тип взятого ею значения совпадает с типом последнего присвоенного ей значения. Выполнение этого требования в каждый текущий момент - целиком на совести программиста. В том случае, если нечто запомнено как значение одного типа, а извлекается как значение другого типа, результат зависит от реализации. Синтаксис доступа к элементам объединения следующий: имя-объединения.элементили указатель-на-объединение-> элементт. е. в точности такой, как в структурах. Если для хранения типа текущего значения u использовать, скажем, переменную utype, то можно написать такой фрагмент программы: if (utype == INT) printf(" %d\n", u.ival); else if (utype === FLOAT) printf(" %f\n", u.fval); else if (utype == STRING) printf(" %s\n", u.sval); else printf (" неверный тип %d в utype\n", utype);Объединения могут входить в структуры и массивы, и наоборот. Запись доступа к элементу объединения, находящегося в структуре (как и структуры, находящейся в объединении), такая же, как и для вложенных структур. Например, в массиве структур struct { char *name; int flags; int utype; union { int ival; float fval; char *sval; } u; } symtab[NSYM];к ival обращаются следующим образом: symtab[i].u.ivalа к первому символу строки sval можно обратиться любым из следующих двух способов: *symtab[i].u.svalsymtab[i].u.sval[0]Фактически объединение - это структура, все элементы которой имеют нулевое смещение относительно ее базового адреса и размер которой позволяет поместиться в ней самому большому ее элементу, а выравнивание этой структуры удовлетворяет всем типам объединения. Операции, применимые к структурам, годятся и для объединений, т. е. законны присваивание объединения и копирование его как единого целого, взятие адреса от объединения и доступ к отдельным его элементам. Инициализировать объединение можно только значением, имеющим тип его первого элемента; таким образом, упомянутую выше переменную u можно инициализировать лишь значением типа int. В главе 8 (на примере программы, заведующей выделением памяти) мы покажем, как, применяя объединение, можно добиться, чтобы расположение переменной было выровнено по соответствующей границе в памяти. Битовые поля При дефиците памяти может возникнуть необходимость запаковать несколько объектов в одно слово машины. Одна из обычных ситуаций, встречающаяся в задачах обработки таблиц символов для компиляторов, - это объединение групп однобитовых флажков. Форматы некоторых данных могут от нас вообще не зависеть и диктоваться, например, интерфейсами с аппаратурой внешних устройств: здесь также возникает потребность адресоваться к частям слова. Вообразим себе фрагмент компилятора, который заведует таблицей символов. Каждый идентификатор программы имеет некоторую связанную с ним информацию: например, представляет ли он собой ключевое слово и, если это переменная, к какому классу принадлежит: внешняя и/или статическая и т. д. Самый компактный способ кодирования такой информации - расположить однобитовые флажки в одном слове типа char или int. Один из распространенных приемов работы с битами основан на определении набора " масок", соответствующих позициям этих битов, как, например, в #define KEYWORD 01 /* ключевое слово */#define EXTERNAL 02 /* внешний */#define STATIC 04 /* статический */или в enum { KEYWORD = 01, EXTERNAL = 02, STATIC = 04 };Числа должны быть степенями двойки. Тогда доступ к битам становится делом " побитовых операций", описанных в главе 2 (сдвиг, маскирование, взятие дополнения). Некоторые виды записи выражений встречаются довольно часто. Так, flags |= EXTERNAL | STATIC;устанавливает 1 в соответствующих битах переменной flags, flags & = ~(EXTERNAL | STATIC);обнуляет их, a if ((flags & (EXTERNAL | STATIC)) == 0)...оценивает условие как истинное, если оба бита нулевые. Хотя научиться писать такого рода выражения не составляет труда, вместо побитовых логических операций можно пользоваться предоставляемым Си другим способом прямого определения и доступа к полям внутри слова. Битовое поле (или для краткости просто поле) - это некоторое множество битов, лежащих рядом внутри одной, зависящей от реализации единицы памяти, которую мы будем называть " словом". Синтаксис определения полей и доступа к ним базируется на синтаксисе структур. Например, строки #define, фигурировавшие выше при задании таблицы символов, можно заменить на определение трех полей: struct { unsigned int is_keyword: 1; unsigned int is_extern: 1; unsigned int is_static: 1; } flags;Эта запись определяет переменную flags, которая содержит три однобитовых поля. Число, следующее за двоеточием, задает ширину поля. Поля объявлены как unsigned int, чтобы они воспринимались как беззнаковые величины. На отдельные поля ссылаются так же, как и на элементы обычных структур: flags.is_keyword, flags.is_extern и т.д. Поля " ведут себя" как малые целые и могут участвовать в арифметических выражениях точно так же, как и другие целые. Таким образом, предыдущие примеры можно написать более естественно: flags.is_extern = flags.is_static = 1;устанавливает 1 в соответствующие биты; flags.is_extern = flags.is_static = 0;их обнуляет, а if (flags.is_extern == 0 & & flags.is_ststic == 0)...проверяет их. Почти все технические детали, касающиеся полей, в частности, возможность поля перейти границу слова, зависят от реализации. Поля могут не иметь имени; с помощью безымянного поля (задаваемого только двоеточием и шириной) организуется пропуск нужного количества разрядов. Особая ширина, равная нулю, используется, когда требуется выйти на границу следующего слова. На одних машинах поля размещаются слева направо, на других - справа налево. Это значит, что при всей полезности работы с ними, если формат данных, с которыми мы имеем дело, дан нам свыше, то необходимо самым тщательным образом исследовать порядок расположения полей; программы, зависящие от такого рода вещей, не переносимы. Поля можно определять только с типом int, а для того чтобы обеспечить переносимость, надо явно указывать signed или unsigned. Они не могут быть массивами и не имеют адресов, и, следовательно, оператор & к ним не применим.
Глава 7. Ввод и вывод 7.1 Стандартный ввод-вывод Возможности для ввода и вывода не являются частью самого языка Си, поэтому мы подробно и не рассматривали их до сих пор. Между тем реальные программы взаимодействуют со своим окружением гораздо более сложным способом, чем те, которые были затронуты ранее. В этой главе мы опишем стандартную библиотеку, содержащую набор функций, обеспечивающих ввод-вывод, работу со строками, управление памятью, стандартные математические функции и разного рода сервисные Си-программы. Но особое внимание уделим вводу-выводу. Библиотечные функции ввода-вывода точно определяются стандартом ANSI, так что они совместимы на любых системах, где поддерживается Си. Программы, которые в своем взаимодействии с системным окружением не выходят за рамки возможностей стандартной библиотеки, можно без изменений переносить с одной машины на другую. Свойства библиотечных функций специфицированы в более чем дюжине заголовочных файлов; вам уже встречались некоторые из них, в том числе < stdio.h>, < string.h> и < ctype.h>. Мы не рассматриваем здесь всю библиотеку, так как нас больше интересует написание Си-программ, чем использование библиотечных функций. Стандартная библиотека подробно описана в приложении B. Стандартный ввод-вывод Как уже говорилось в главе 1, библиотечные функции реализуют простую модель текстового ввода-вывода. Текстовый поток состоит из последовательности строк; каждая строка заканчивается символом новой строки. Если система в чем-то не следует принятой модели, библиотека сделает так, чтобы казалось, что эта модель удовлетворяется полностью. Например, пара символов - возврат-каретки и перевод-строки - при вводе могла бы быть преобразована в один символ новой строки, а при выводе выполнялось бы обратное преобразование. Простейший механизм ввода - это чтение одного символа из стандартного ввода (обычно с клавиатуры) функцией getchar: int getchar(void)В качестве результата каждого своего вызова функция getchar возвращает следующий символ ввода или, если обнаружен конец файла, EOF. Именованная константа EOF (аббревиатура от end of file - конец файла) определена в < stdio.h>. Обычно значение EOF равно -1, но, чтобы не зависеть от конкретного значения этой константы, обращаться к ней следует по имени (EOF). Во многих системах клавиатуру можно заменить файлом, перенаправив ввод с помощью значка <. Так, если программа prog использует getchar, то командная строка prog < infileпредпишет программе prog читать символы из infile, а не с клавиатуры. Переключение ввода делается так, что сама программа prog не замечает подмены; в частности строка " < infile" не будет включена в аргументы командной строки argv. Переключение ввода будет также незаметным, если ввод исходит от другой программы и передается конвейерным образом. В некоторых системах командная строка otherprog | progприведет к тому, что запустится две программы, otherprog и prog, и стандартный выход otherprog поступит на стандартный вход prog. Функция int putchar(int)используется для вывода: putchar(c) отправляет символ c в стандартный вывод, под которым по умолчанию подразумевается экран. Функция putchar в качестве результата возвращает посланный символ или, в случае ошибки, EOF. То же и в отношении вывода: с помощью записи вида > имя-файла вывод можно перенаправить в файл. Например, если prog использует для вывода функцию putchar, то prog > outfileбудет направлять стандартный вывод не на экран, а в outfile. А командная строка prog | anotherprogсоединит стандартный вывод программы prog со стандартным вводом программы anotherprog. Вывод, осуществляемый функцией printf, также отправляется в стандартный выходной поток. Вызовы putchar и printf могут как угодно чередоваться, при этом вывод будет формироваться в той последовательности, в которой происходили вызовы этих функций. Любой исходный Си-файл, использующий хотя бы одну функцию библиотеки ввода-вывода, должен содержать в себе строку #include < stdio.h>причем она должна быть расположена до первого обращения к вводу-выводу. Если имя заголовочного файла заключено в угловые скобки < и >, это значит, что поиск заголовочного файла ведется в стандартном месте (например в системе UNIX это обычно директорий /usr/include). Многие программы читают только из одного входного потока и пишут только в один выходной поток. Для организации ввода-вывода таким программам вполне хватит функций getchar, putchar и printf, а для начального обучения уж точно достаточно ознакомления с этими функциями. В частности, перечисленных функций достаточно, когда требуется вывод одной программы соединить с вводом следующей. В качестве примера рассмотрим программу lower, переводящую свой ввод на нижний регистр: #include < stdio.h> #include < ctype.h> main() /* lower: переводит ввод на нижний регистр */{ int с; while ((с = getchar())! = EOF) putchar(tolower(c)); return 0; }Функция tolower определена в < ctype.h>. Она переводит буквы верхнего регистра в буквы нижнего регистра, а остальные символы возвращает без изменений. Как мы уже упоминали, " функции" вроде getchar и putchar из библиотеки < stdio.h> и функция tolower из библиотеки < ctype.h> часто реализуются в виде макросов, чтобы исключить накладные расходы от вызова функции на каждый отдельный символ. В параграфе 8.5 мы покажем, как это делается. Независимо от того, как на той или иной машине реализованы функции библиотеки < ctype.h>, использующие их программы могут ничего не знать о кодировке символов. Упражнение 7.1. Напишите программу, осуществляющую перевод ввода с верхнего регистра на нижний или с нижнего на верхний в зависимости от имени, по которому она вызывается и текст которого находится в arg[0]. Форматный вывод (printf) Функция printf переводит внутренние значения в текст. int printf(char *format, arg1, arg2, ...)В предыдущих главах мы использовали printf неформально. Здесь мы покажем наиболее типичные случаи применения этой функции: полное ее описание дано в приложении B. Функция printf преобразует, форматирует и печатает свои аргументы в стандартном выводе под управлением формата. Возвращает она количество напечатанных символов. Форматная строка содержит два вида объектов: обычные символы, которые напрямую копируются в выходной поток, и спецификации преобразования, каждая из которых вызывает преобразование и печать очередного аргумента printf. Любая спецификация преобразования начинается знаком % и заканчивается символом-спецификатором. Между % и символом-спецификатором могут быть расположены (в указанном ниже порядке) следующие элементы: · Знак минус, предписывающий выравнивать преобразованный аргумент по левому краю поля. · Число, специфицирующее минимальную ширину поля. Преобразованный аргумент будет занимать поле по крайней мере указанной ширины. При необходимости лишние позиции слева (или справа при левостороннем расположении) будут заполнены пробелами. · Точка, отделяющая ширину поля от величины, устанавливающей точность. · Число (точность), специфицирующее максимальное количество печатаемых символов в строке, или количество цифр после десятичной точки - для чисел с плавающей запятой, или минимальное количество цифр - для целого. · Буква h, если печатаемое целое должно рассматриваться как short, или l (латинская буква ell), если целое должно рассматриваться как long. Символы-спецификаторы перечислены в таблице 7.1. Если за % не помещен символ- спецификатор, поведение функции printf будет не определено. Ширину и точность можно специфицировать с помощью *; значение ширины (или точности) в этом случае берется из следующего аргумента (который должен быть типа int). Например, чтобы напечатать не более max символов из строки s, годится следующая запись: printf(" %.*s", max, s);Таблица 7.1 Основные преобразования printf
Большая часть форматных преобразований была продемонстрирована в предыдущих главах. Исключение составляет задание точности для строк. Далее приводится перечень спецификаций и показывается их влияние на печать строки " hello, world", состоящей из 12 символов. Поле специально обрамлено двоеточиями, чтобы была видна его протяженность. : %s: : hello, world:: %10s: hello, world:: %.10s: : hello, wor:: %-10s: : hello, world:: %.15s: : hello, world:: %-15s: : hello, world:: %15.10s: : hello, wor:: %-15.10s: : hello, wor:Предостережение: функция printf использует свой первый аргумент, чтобы определить, сколько еще ожидается аргументов и какого они будут типа. Вы не получите правильного результата, если аргументов будет не хватать или они будут принадлежать не тому типу. Вы должны также понимать разницу в следующих двух обращениях: printf(s); /* НЕВЕРНО, если в s есть % */ printf(" %s", s); /* ВЕРНО всегда */Функция sprintf выполняет те же преобразования, что и printf, но вывод запоминает в строке int sprintf(char *string, char *format, arg1, arg2, ...)Эта функция форматирует arg1, arg2 и т. д. в соответствии с информацией, заданной аргументом format, как мы описывали ранее, но результат помещает не в стандартный вывод, а в string. Заметим, что строка string должна быть достаточно большой, чтобы в ней поместился результат. Упражнение 7.2. Напишите программу, которая будет печатать разумным способом любой ввод. Как минимум она должна уметь печатать неграфические символы в восьмеричном или шестнадцатеричном виде (в форме, принятой на вашей машине), обрывая длинные текстовые строки. |
Последнее изменение этой страницы: 2017-03-14; Просмотров: 478; Нарушение авторского права страницы