
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Машинное представление вещественных чисел. Мантисса и порядок.
В памяти компьютера вещественные числа представлены в форме с плавающей точкой, в двоичной системе счисления. Десятичное число D в этой форме записи имеет вид D=+- m*10n, где m и n – соответственно мантисса числа и его порядок. Например, число 357.5 можно записать в виде: 3575*10-1, 0.3575*103. Последняя запись – нормализованная форма числа с плавающей точкой. Обычная же запись числа в виде 357.5 называется формой записи с фиксированной точкой. Такое представление чисел в компьютерах используется только на этапах их ввода или вывода, в то время как хранение и обработка вещественных чисел осуществляется именно в форме с плавающей точкой. Машинная точность Конечное количество разрядов мантиссы приводит к тому, что при вычислениях с помощью компьютера неизбежны погрешности округления. Так, например, если при 6 десятичных разрядах к числу 0.214724 прибавить число, меньшее по модулю половины последнего разряда (т.е. меньшее по модулю 0.0000005), в результате получится то же самое число 0.214724. Величина ошибки округления определяется количеством разрядов мантиссы. При округлении по дополнению (которое, как правило, и реализуется в компьютерах) максимальная относительная погрешность округления равна Верные цифры. Пусть а - точное значение,
Абсолютной погрешностью приближенного значения называется величина Значащими цифрами числа Значащую цифру числа
Часть 1 №2 Кодирование информации. Эффективность кодирования. Для определения количества информации был найден способ представить любой ее тип (символьный, текстовый, графический) в едином виде, что позволило все типы информации преобразовать к единому стандартному виду. Таким видом стала так называемая двоичная форма представления информации. информация в ЭВМ кодируется в следующих случаях: 1. шифрование (скрытие секретной информации, перевод из одного алфавита в другой) 2. сжатие (уменьшение объёма, использование более коротких комбинаций для наиболее часто повторяющихся комбинаций) 3. защита от помех (при передачи возможно искажение информации при этом используются так называемые биты чётности) Эффективность кодирования измеряется избыточностью. Повысить эффективность кодирования можно, строя код не для символа, а для блоков из n символов, причем частота блока рассчитывается как произведение частот символов, входящих в блок. Энтропия. Избыточность. Энтропия(H)-мера неопределенности случайного объекта с конечным множеством состояний Аi с соответствующими им вероятностями р i Величину Н называют средним количеством информации на знак, информацией на знак или энтропией источника сообщений. Н=∑ р i * log(1/ р i ) Избыточность(Е)-это мера бесполезно совершаемых альтернативных выборов. Разность L-H называют избыточностью кода. Также избыточность можно выразить в процентах, при этом относительная избыточность будет равна 100%*(L-H)/L. Оптимальное кодирование. Этот вид кодирования используется для уменьшения объемов информации на носителе. Код называется оптимальным, если его избыточность равна нулю.Для кодирования символов исходного алфавита используют двоичные коды переменной длины: чем больше частота символа, тем короче его код. Эффективность кода определяется средним числом двоичных разрядов для кодирования одного символа – lср по формуле
При эффективном кодировании существует предел сжатия, ниже которого не «спускается» ни один метод эффективного кодирования - иначе будет потеряна информация. Этот параметр определяется предельным значением двоичных разрядов возможного эффективного кода – lпр:
Как видно из формулы, этим пределом сжатия является энтропия. Существуют два классических метода эффективного кодирования: метод Шеннона-Фано и метод Хаффмена. Входными данными для обоих методов является заданное множество исходных символов для кодирования с их частотами; результат - эффективные коды. Алгоритм составления эффективного кода методом Шеннона-Фано: 1) Составить список букв алфавита (исходное множество букв) в порядке убывания значений соответствующих им вероятностей. 2) Разбить этот список на два подсписка (подмножества букв) таким образом, чтобы значения вероятностей того, что наугад взятая из рассматриваемого текста буква окажется в первом или во втором из этих подмножеств, были бы по возможности близки. 3) Приписать произвольному одному из этих подмножеств (подсписков) символ " 0", а другому - " 1". 4) Рассматривая каждое из этих подмножеств (подсписков) как исходное, применительно к каждому из них осуществить операции, указанные в пунктах (2) и (3). 5) Этот процесс продолжать до тех пор, пока в каждом из очередных подмножеств не окажется по одной букве. 6) Каждой букве приписать двоичный код, состоящий из последовательности нулей и единиц, встречающихся на пути из исходного множества букв ко множеству, состоящему из одной этой буквы. Алгоритм составления эффективного кода методом Хаффмена: 1) Составить список букв алфавита (исходное множество букв) в порядке убывания значений соответствующих им вероятностей. 2) Объединим два наименее вероятных символа алфавита источника в один символ, вероятность которого равна сумме соответствующих вероятностей. 2*) Таким образом, нужно построить код для источника, у которого число символов уменьшилось на 1. Повторяя этот процесс несколько раз, приходим к более простой задаче кодирования источника, алфавит которого состоит из символов 0 и 1. 3) Возвращаясь на один шаг назад, имеем, что один из символов нужно разбить на два символа; это можно сделать, обавив к соответствующему кодовому слову символ 0 для одного из символов и символ 1 - для другого. 3*) Возвращаясь еще на один шаг назад, нужно таким же образом разбить один из трех имеющихся симво- лов на два символа, и так далее. 4) В результате около каждого исходного символа получим его двоичный код
Префиксные коды. Префиксные коды - это коды однозначность декодирования которых достигается без помощи каких-либо разделительных символов. Обладают свойством: ни одна более короткая кодовая комбинация не является началом любой другой более длинной комбинации Первая теорема Шеннона Теорема о кодировании без шума: для n-кратного расширения достаточно высокой кратности средняя длина кодового слова L может быть сколь угодно близкой к энтропии источника. Аналого-цифровое преобразование . Для преобразования любого аналогового сигнала (звука, изображения) в цифровую форму необходимо выполнить три основные операции: дискретизацию, квантование и кодирование. Первый этап формирования цифрового сигнала – дискретизация. Дискретизируют сигнал в соответствующий момент времени, а затем удерживают полученное значение отсчета до момента формирования следующего отсчета. Отсчет сигнала используют для получения его цифрового представления. Причина удерживания величины отсчета может быть не совсем очевидна. «Период удерживания» дает время аналого-цифровому преобразователю (АЦП) выполнить его преобразование. Очевидно, что чем меньше интервал дискретизации и, соответственно, выше частота дискретизации, тем меньше различия между исходным сигналом и его дискретизированной копией. Квантование — это отображение вещественных чисел в некоторое счётное множество чисел, а именно в множество всех кратных некоторого числа Δ , называемого шагом квантования (или просто квантом). Отображение устроено так, что всякий из наших равных по длине интервалов чисел отображается в то кратное Δ , которое лежит в этом интервале. Физические соображения снова позволяют нам предполагать, что значения функции, представляющие собой значения некоторой физической величины, не могут быть как угодно велики, а ограничены сверху и снизу. Поэтому квантование переводит значения функции в конечное множество чисел, которое можно понимать как набор знаков. Таким образом, дискретизация, за которой следует квантование, даёт последовательность знаков - произвольное сообщение превращается в дискретное, представляемое словом над некоторым набором знаков. Отдельные знаки этого набора - кратные шага квантования - в свою очередь можно двоично закодировать. В технике этот метод известен под названием импульсно-кодовой модуляции Существует несколько вариантов основной формы ИКМ: • Дельта-Модуляция (ДМ); • Дифференциальная ИКМ (ДИКМ); • Адаптивная Дифференциальная ИКМ (АДИКМ) Цифровое кодирование - квантованный сигнал, в отличие от исходного аналогового, может принимать только конечное число значений. Это позволяет представить его в пределах каждого интервала дискретизации числом, равным порядковому номеру уровня квантования. В свою очередь это число можно выразить комбинацией некоторых знаков или символов. Совокупность знаков (символов) и система правил, при помощи которых данные представляются в виде набора символов, называют кодом. Конечная последовательность кодовых символов называется кодовым словом. Квантованный сигнал можно преобразовать в последовательность кодовых слов. Эта операция и называется кодированием. |
Последнее изменение этой страницы: 2017-03-14; Просмотров: 118; Нарушение авторского права страницы
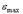 и называется машинной точностью.
и называется машинной точностью. - приближенное значение некоторой величины.
- приближенное значение некоторой величины.
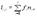 где k – число символов исходного алфавита; ns – число двоичных разрядов для кодирования символа s; fs – частота символа s; причем
где k – число символов исходного алфавита; ns – число двоичных разрядов для кодирования символа s; fs – частота символа s; причем
 где n – мощность кодируемого алфавита, fi – частота i-го символа кодируемого алфавита.
где n – мощность кодируемого алфавита, fi – частота i-го символа кодируемого алфавита.