
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Классическое и статистическое определение вероятности. Геометрическая вероятность.Стр 1 из 5Следующая ⇒
Классическое и статистическое определение вероятности. Геометрическая вероятность. Основным понятием теории вероятностей является понятие случайного события. Случайным событием называется событие, которое при осуществлении некоторых условий может произойти или не произойти. Например, попадание в некоторый объект или промах при стрельбе по этому объекту из данного орудия является случайным событием.
Событие называется достоверным, если в результате испытания оно обязательно происходит. Невозможным называется событие, которое в результате испытания произойти не может.
Случайные события называются несовместными в данном испытании, если никакие два из них не могут появиться вместе.
Случайные события образуют полную группу, если при каждом испытании может появиться любое из них и не может появиться какое-либо иное событие, несовместное с ними.
Рассмотрим полную группу равновозможных несовместных случайных событий. Такие события будем называть исходами. Исход называется благоприятствующим появлению события А, если появление этого события влечет за собой появление события А.
Вероятностью события A называют отношение числа m благоприятствующих этому событию исходов к общему числу n всех равновозможных несовместных элементарных исходов, образующих полную группу
Геометрическая вероятность — один из способов задания вероятности; пусть Ω — ограниченное множество евклидова пространства, имеющее объем λ (Ω ) (соответственно длину или площадь в одномерной или двумерной ситуации), пусть ω — точка, взятая случайным образом из Ω, пусть вероятность, что точка будет взята из подмножества
Теоремы сложения и умножения вероятностей Теоремы сложения и умножения вероятностей
Суммой двух событий А и В называется событие С, состоящее в появлении хотя бы одного из событий А или В.
Теорема сложения вероятностей
Вероятность суммы двух несовместимых событий равна сумме вероятностей этих событий:
Р (А + В) = Р (А) + Р (В).
В случае, когда события А и В совместны, вер-ть их суммы выражается формулой
Р (А +В) = Р (А) + Р (В) – Р (АВ),
где АВ – произведение событий А и В.
Два события называются зависимыми, если вероятность одного из них зависит от наступления или не наступления другого. в случае зависимых событий вводится понятие условной вероятности события.
Условной вероятностью Р(А/В) события А называется вероятность события А, вычисленная при условии, что событие В произошло. Аналогично через Р(В/А) обозначается условная вероятность события В при условии, что событие А наступило.
Произведением двух событий А и В называется событие С, состоящее в совместном появлении события А и события В. Теорема умножения вероятностей
Вероятность произведения двух событий равна вер-ти одного из них, умноженной на условную вероятность другого при наличии первого:
Р (АВ) = Р(А) · Р(В/А), или Р (АВ) = Р(В) · Р(А/В).
Следствие. Вероятность совместного наступления двух независимых событий А и В равна произведению вероятностей этих событий:
Р (АВ) = Р(А) · Р(В).
Следствие. При производимых n одинаковых независимых испытаниях, в каждом из которых события А появляется с вероятностью р, вероятность появления события А хотя бы один раз равна 1 - (1 - р)n
Вероятность появления хотя бы одного события. Пример. Формула Бейеса. Вероятность сделать хотя бы одну ошибку на странице тетради составляет р=0, 1. В тетради 7 написанных страниц. Какова вероятность Р, что в тетради есть хотя бы одна ошибка? Решение: Вероятность наступления события А, состоящего из событий А1, А2, …, Аn, независимых в совокупности, равна разности между единицей и произведением вероятностей противоположных событий Ǡ 1, Ǡ 2, ... Ǡ n. P(A) = 1 - q1q2…qn
Вероятность противоположного события q = 1 - p. В частности, если все события имеют одинаковую вероятность равную р, то вероятность появления хотя бы одного из этих событий равна: Р(А) = 1 – qn = 1 – (1 – p)n = 1 – ( 1 – 0, 1 )7 = 0, 522 Ответ: 0, 522 Формула Бейеса. Предположим, что производится некоторый опыт, причем об условиях его проведения можно высказать n единственно возможных и несовместных гипотез
6.Формула Бернулли. Примеры. Формула Бернулли — формула в теории вероятностей, позволяющая находить вероятность появления события A при независимых испытаниях. Формула Бернулли позволяет избавиться от большого числа вычислений — сложения и умножения вероятностей — при достаточно большом количестве испытаний. Названа в честь выдающегося швейцарского математика Якоба Бернулли, выведшего формулу. Формулировка Теорема: Если Вероятность p наступления события Α в каждом испытании постоянна, то вероятность Доказательство Так как в результате Локальная и интегральная теоремы Лапласа. Примеры. Локальная и интегральная теоремы Лапласа
Локальная теорема Лапласа. Вероятность того, что в n независимых испытаниях, в каждом из которых вероятность появления события равна р(0 < р < 1), событие наступит ровно k раз (безразлично, в какой последовательности), приближенно равна (тем точнее, чем больше n)
Интегральная теорема Лапласа. Вероятность того, что в n независимых испытаниях, в каждом из которых вероятность появления события равна р (0 < р < 1), событие наступит не менее k1 раз и не более k2 раз, приближенно равна
P(k1; k2)=Φ (x'') - Φ (x')
Здесь
Пример. Найти вероятность того, что событие А насту пит ровно 70 раз в 243 испытаниях, если вероятность появления этого события в каждом испытании равна 0, 25.
Решение. По условию, n=243; k = 70; р =0, 25; q= 0, 75. Так как n=243 - достаточно большое число, воспользуемся локальной теоремой Лапласа:
Найдем значение х
P(243)(70) = 1/6, 75*0, 1561 =0, 0231. Числовые характеристики дискретных величин. Примеры Числовые характеристики дискретных случайных величин
Закон распределения полностью характеризует случайную величину. Однако, когда невозможно найти закон распределения, или этого не требуется, можно ограничиться нахождением значений, называемых числовыми характеристиками случайной величины. Эти величины определяют некоторое среднее значение, вокруг которого группируются значения случайной величины, и степень их разбросанности вокруг этого среднего значения.
Определение. Математическим ожиданием дискретной случайной величины называется сумма произведений всех возможных значений случайной величины на их вероятности.
Математическое ожидание существует, если ряд, стоящий в правой части равенства, сходится абсолютно.
С точки зрения вероятности можно сказать, что математическое ожидание приближенно равно среднему арифметическому наблюдаемых значений случайной величины.
Теоретические моменты. Примеры. Идея этого метода заключается в приравнивании теоретических и эмпирических моментов. Поэтому мы начнем с обсуждения этих понятий.
Пусть
Для того, чтобы найти оценки неизвестных параметров по методу моментов следует:
явно вычислить теоретические моменты
решить систему (35) относительно переменных
12.Неравенство Чебышева. Закон больших чисел. Нера́ венство Чебышева, известное также как неравенство Биенэме — Чебышева, это распространённое неравенство из теории меры и теории вероятностей. Оно было первый раз получено Биенэме (фран.) в 1853 году, и позже также Чебышевым. Неравенство, использующееся в теории меры, является более общим, в теории вероятностей используется его следствие. Неравенство Чебышева в теории меры
Неравенство Чебышева в теории меры описывает взаимосвязь интеграла Лебега и меры. Аналог этого неравенства в теории вероятностей — неравенство Маркова. Неравенство Чебышева также используется для доказательства вложения пространства Формулировки Пусть
Тогда справедливо неравенство: В более общем виде: Если
Неравенство Чебышева в теории вероятностей
Неравенство Чебышева в теории вероятностей утверждает, что случайная величина в основном принимает значения, близкие к своему среднему. Говоря более точно, оно даёт оценку вероятности, что случайная величина примет значение, далёкое от своего среднего. Неравенство Чебышева является следствием неравенства Маркова.
Формулировки
Пусть случайная величина
Закон больших чисел
Основными понятиями теории вероятностей являются понятия случайного события и случайной величины. При этом предсказать заранее результат испытания, в котором может появиться или не появиться то или иное событие или какое-либо определенное значение случайной величины, невозможно, так как исход испытания зависит от многих случайных причин, не поддающихся учету.
Однако при неоднократном повторении испытаний наблюдаются закономерности, свойственные массовым случайным явлениям. Эти закономерности обладают свойством устойчивости. Суть этого свойства состоит в том, что конкретные особенности каждого отдельного случайного явления почти не сказываются на среднем результате большой массы подобных явлений, а характеристики случайных событий и случайных величин, наблюдаемых в испытаниях, при неограниченном увеличении числа испытаний становятся практически не случайными.
Пусть производится большая серия однотипных опытов. Исход каждого отдельного опыта является случайным, неопределенным. Однако, несмотря на это, средний результат всей серии опытов утрачивает случайный характер, становится закономерным.
Для практики очень важно знание условий, при выполнении которых совокупное действие очень многих случайных причин приводит к результату, почти не зависящему от случая, так как позволяет предвидеть ход явлений. Эти условия и указываются в теоремах, носящих общее название закона больших чисел.
Под законом больших чисел не следует понимать какой-то один общий закон, связанный с большими числами. Закон больших чисел - это обобщенное название нескольких теорем, из которых следует, что при неограниченном увеличении числа испытаний средние величины стремятся к некоторым постоянным.
К ним относятся теоремы Чебышева и Бернулли. Теорема Чебышева является наиболее общим законом больших чисел, теорема Бернулли - простейшим.
В основе доказательства теорем, объединенных термином " закон больших чисел", лежит неравенство Чебышева, по которому устанавливается вероятность отклонения Математическая формулировка Нужно определить максимум линейной целевой функции (линейной формы) Геометрический способ решения задач линейного программирования для двух переменных. Пример. Областью решения линейного неравенства с двумя переменными
Областью решений системы неравенств является пересечение конечного числа полуплоскостей, описываемых каждым отдельным неравенством. Это пересечение представляет собой многоугольную область G. Она может быть как ограниченной, так и неограниченной и даже пустой (если система неравенств противоречива).
Область решений G обладает важным свойством выпуклости. Область называется выпуклой, если произвольные две ее точки можно соединить отрезком, целиком принадлежащим данной области. На рис. 2 показаны выпуклая область G1 и невыпуклая область G2. В области G1 две ее произвольные точки А1 и В1 можно соединить отрезком, все точки которого принадлежат области G1. В области G2 можно выбрать такие две ее точки А2 и В2, что не все точки отрезка А2В2 принадлежат области G2.
Опорной прямой называется прямая, которая имеет с областью по крайней мере одну общую точку, при этом вся область расположена по одну сторону от этой прямой. На рис. 2 показаны две опорные прямые l1 и l2, т. е. в данном случае прямые проходят соответственно через вершину многоугольника и через одну из его сторон.
Аналогично можно дать геометрическую интерпретацию системы неравенств с тремя переменными. В этом случае каждое неравенство описывает полупространство, а вся система - пересечение полупространств, т. е. многогранник, который также обладает свойством выпуклости. Здесь опорная плоскость проходит через вершину, ребро или грань многогранной области.
Основываясь на введенных понятиях, рассмотрим геометрический метод решения задачи линейного программирования. Пусть заданы линейная целевая функция f = c0 + c1x1 + c2x2 двух независимых переменных, а также некоторая совместная система линейных неравенств, описывающих область решений G. Требуется среди допустимых решений
Положим функцию f равной некоторому постоянному значению С: f = c0 + c1x1 + c2x2 = C. Это значение достигается в точках прямой, удовлетворяющих уравнению
Предположим, что прямая, записанная в виде (9), при параллельном переносе в положительном направлении вектора n первый раз встретится с областью допустимых решений G в некоторой ее вершине, при этом значение целевой функции равно С1, и прямая становится опорной. Тогда значение С1 будет минимальным, поскольку дальнейшее движение прямой в том же направлении приведет к увеличению значения f.
Таким образом, оптимизация линейной целевой функции на многоугольнике допустимых решений происходит в точках пересечения этого многоугольника с опорными прямыми, соответствующими данной целевой функции. При этом пересечение может быть в одной точке (в вершине многоугольника) либо в бесконечном множестве точек (на ребре многоугольника).
Алгоритм симплекс-метода для решения общей задачи линейного программирования. Таблица. Алгоритмы решения
Наиболее известным и широко применяемым на практике для решения общей задачи линейного программирования (ЛП) является симплекс-метод. Несмотря на то, что симплекс-метод является достаточно эффективным алгоритмом, показавшим хорошие результаты при решении прикладных задач ЛП, он является алгоритмом с экспоненциальной сложностью. Причина этого состоит в комбинаторном характере симплекс-метода, последовательно перебирающего вершины многогранника допустимых решений при поиске оптимального решения.
Первый полиномиальный алгоритм, метод эллипсоидов, был предложен в 1979 году советским математиком Л. Хачияном, разрешив таким образом проблему, долгое время остававшуюся нерешённой. Метод эллипсоидов имеет совершенно другую, некомбинаторную, природу, нежели симплекс-метод. Однако в вычислительном плане этот метод оказался неперспективным. Тем не менее, сам факт полиномиальной сложности задач привёл к созданию целого класса эффективных алгоритмов ЛП — методов внутренней точки, первым из которых был алгоритм Н. Кармаркара, предложенный в 1984 году. Алгоритмы этого типа используют непрерывную трактовку задачи ЛП, когда вместо перебора вершин многогранника решений задачи ЛП осуществляется поиск вдоль траекторий в пространстве переменных задачи, не проходящих через вершины многогранника. Метод внутренних точек, который, в отличие от симплекс-метода, обходит точки из внутренней части области допустимых значений, использует методы логарифмических барьерных функций нелинейного программирования, разработанные в 1960-х годах Фиако (Fiacco) и МакКормиком (McCormick).
24.Особые случаи в симплекс-методе: вырожденное решение, бесконечное множество решений, отсутствие решения. Примеры. Использование метода искусственного базиса для решения общей задачи линейного программирования. Пример. Метод искусственного базиса.
Метод искусственного базиса используется для нахождения допустимого базисного решения задачи линейного программирования, когда в условии присутствуют ограничения типа равенств. Рассмотрим задачу:
max{F(x)=∑ cixi|∑ ajixi=bj, j=1, m; xi≥ 0}.
В ограничения и в функцию цели вводят так называемые «искусственные переменные» Rj следующим образом:
∑ ajix+Rj=bj, j=1, m; F(x)=∑ cixi-M∑ Rj
При введении искусственных переменных в методе искусственного базиса в функцию цели им приписывается достаточно большой коэффициент M, который имеет смысл штрафа за введение искусственных переменных. В случае минимизации искусственные переменные прибавляются к функции цели с коэффициентом M. Введение искусственных переменных допустимо в том случае, если в процессе решения задачи они последовательно обращаются в нуль.
Симплекс-таблица, которая составляется в процессе решения, используя метод искусственного базиса, называется расширенной. Она отличается от обычной тем, что содержит две строки для функции цели: одна – для составляющей F = ∑ cixi, , а другая – для составляющей M ∑ Rj Рассмотрим процедуру решения задачи на конкретном примере.
Пример 1. Найти максимум функции F(x) = -x1 + 2x2 - x3 при ограничениях:
2x1+3x2+x3=3,
x1+3x3=2,
x1≥ 0, x2≥ 0, x3≥ 0.
Применим метод искусственного базиса. Введем искусственные переменные в ограничения задачи
2x1 + 3x2 + x3 + R1 = 3;
x1 + 3x3 + R2 = 2;
Функция цели F(x)-M ∑ Rj= -x1 + 2x2 - x3 - M(R1+R2).
Выразим сумму R1 + R2 из системы ограничений: R1 + R2 = 5 - 3x1 - 3x2 - 4x3, тогда F(x) = -x1 + 2x2 - x3 - M(5 - 3x1 - 3x2 - 4x3). При составлении первой симплекс-таблицы (табл. 1) будем полагать, что исходные переменные x1, x2, x3 являются небазисными, а введенные искусственные переменные – базисными. В задачах максимизации знак коэффициентов при небазисных переменных в F- и M-строках изменяется на противоположный. Знак постоянной величины в M-строке не изменяется. Оптимизация проводится сначала по M-строке. Выбор ведущих столбца и строки, все симплексные преобразования при испльзовании метода искусственного базиса осуществляются как в обычном симплекс-методе.
x1=0; x2=7/9; Fmax=8/9.
Если при устранении M-строки решение не является оптимальным, то процедура оптимизации продолжается и выполняется обычным симплекс-методом. Рассмотрим пример, в котором присутствуют ограничения всех типов: ≤, =, ≥
Двойственные симметричные задачи линейного программирования. Пример. Определение двойственной задачи
Каждой задаче линейного программирования можно определенным образом сопоставить некоторую другую задачу (линейного программирования), называемую двойственной или сопряженной по отношению к исходной или прямой задаче. Дадим определение двойственной задачи по отношению к общей задаче линейного программирования, состоящей, как мы уже знаем, в нахождении максимального значения функции
1. Целевая функция исходной задачи (32) – (34) задается на максимум, а целевая функция двойственной (35) – (37) – на минимум. 2. Матрица
3. Число переменных в двойственной задаче (35) – (37) равно числу ограничений в системе (33) исходной задачи (32) – (34), а число ограничений в системе (36) двойственной задачи – числу переменных в исходной задаче.
4. Коэффициентами при неизвестных в целевой функции (35) двойственной задачи (35) – (37) являются свободные члены в системе (33) исходной задачи (32) – (34), а правыми частями в соотношениях системы (36) двойственной задачи – коэффициенты при неизвестных в целевой функции (32) исходной задачи.
5. Если переменная xj исходной задачи (32) – (34) может принимать только лишь положительные значения, то j–е условие в системе (36) двойственной задачи (35) – (37) является неравенством вида “? ”. Если же переменная xj может принимать как положительные, так и отрицательные значения, то 1 – соотношение в системе (54) представляет собой уравнение. Аналогичные связи имеют место между ограничениями (33) исходной задачи (32) – (34) и переменными двойственной задачи (35) – (37). Если i – соотношение в системе (33) исходной задачи является неравенством, то i–я переменная двойственной задачи
Двойственные пары задач обычно подразделяют на симметричные и несимметричные. В симметричной паре двойственных задач ограничения (33) прямой задачи и соотношения (36) двойственной задачи являются неравенствами вида “
Связь между переменными прямой и двойственной задачи. Пример. 30.Экономическая интерпретация двойственных задач. Значение нулевых оценок в решении экономической задачи. Примеры. Исходная задача I имела конкретный экономический смысл: основные переменные хi обозначали количество произведенной продукции i-го вида, дополнительные переменные обозначали количество излишков соответствующего вида ресурсов, каждое из неравенств выражало собой расход определенного вида сырья в сравнении с запасом этого сырья. Целевая функция определяла прибыль при реализации всей продукции. Предположим теперь, что предприятие имеет возможность реализовывать сырье на сторону. Какую минимальную цену надо установить за единицу каждого вида сырья при условии, чтобы доход от реализации всех его запасов был не меньше дохода от реализации продукции, которая может быть выпущена из этого сырья.
Переменные у1, у2, у3 будут обозначать условную предполагаемую цену за ресурс 1, 2, 3 вида соответственно. Тогда доход от продажи видов сырья, расходуемых на производство одной единицы продукции I, равен: 5у1 + 1· у3. Т. к. цена продукции I типа равна 3 ед., то 5у1 + у3
Еще раз обратим внимание на то, что уi - это лишь условные, предполагаемые, а не реальные цены на сырье. Иначе читателю может показаться странным, что например, у1* = 0. Этот факт вовсе не означает, что реальная цена первого ресурса нулевая, ничего бесплатного в этом мире нет. Равенство нулю условной цены означает лишь, что этот ресурс не израсходован полностью, имеется в излишке, недефицитен. Действительно, посмотрим на первое неравенство в системе ограничений задачи I, в котором подсчитывается расход первого ресурса: 5х1* + 0, 4х2* + 2х3* + 0, 5х4* = 66 < 400. его избыток составляет х5 = 334 ед. при данном оптимальном плане производства. Этот ресурс имеется в избытке, и поэтому для производителя он недефицитен, его условная цена равна 0, его не надо закупать. Наоборот, ресурс 2 и 3 используются полностью, причем у3 = 4 а у2 = 1, т. е. сырье третьего вида более дефицитно, чем второго, его условная цена больше. Если производитель продукции имел бы возможность приобретать дополнительно сырье к уже имеющемуся, с целью получения максимального дохода от производства, то увеличив сырье второго вида на единицу, он бы получил дополнительно доход в у2 денежных единиц, с увеличением на единицу сырья третьего вида, значение целевой функции увеличилось бы еще на у3 единицы.
Если перед производителем стоит вопрос, " выгодно ли производить какую-либо продукцию при условии, что затраты на единицу продукции составят 3, 1, 4 единиц 1, 2, 3-го видов сырья соответственно, а прибыль от реализации равна 23 единицам", то в силу экономического истолкования задачи ответить на этот вопрос несложно, поскольку затраты и условные цены ресурсов известны. Затраты равны 3, 1, 4, а цены у1* = 0, у2* = 1, у3* = 4. Значит, можно посчитать суммарную условную стоимость ресурсов, необходимых для производства этой новой продукции: 3 · 0 + 1 · 1 + 4 · 4 = 17 < 23. значит продукцию производить выгодно, т. к. прибыль от реализации превышает затраты на ресурсы, в противном случае ответ бы на этот вопрос был отрицательным. 31.Использование оптимального плана и симплекс-таблицы для определения интервалов чувствительности исходных данных. |
Последнее изменение этой страницы: 2017-03-14; Просмотров: 945; Нарушение авторского права страницы

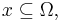 пропорциональна его объёму λ (x), тогда геометрическая вероятность подмножества определяется как отношение объёмов:
пропорциональна его объёму λ (x), тогда геометрическая вероятность подмножества определяется как отношение объёмов:  Геометрическое определение вероятности часто используется в методах Монте-Карло, например, для приближённого вычисления значений многократных определённых интегралов.
Геометрическое определение вероятности часто используется в методах Монте-Карло, например, для приближённого вычисления значений многократных определённых интегралов. , имеющих вероятности
, имеющих вероятности  Пусть в результате опыта может произойти или не произойти событие А, причем известно, что если опыт происходит при выполнении гипотезы
Пусть в результате опыта может произойти или не произойти событие А, причем известно, что если опыт происходит при выполнении гипотезы  то
то 
 Спрашивается, как изменятся вероятности гипотез, если стало известным, что событие А произошло? Иными словами, нас интересуют значения вероятностей
Спрашивается, как изменятся вероятности гипотез, если стало известным, что событие А произошло? Иными словами, нас интересуют значения вероятностей  На основании соотношений (4) и (5) имеем
На основании соотношений (4) и (5) имеем  откуда
откуда  Но по формуле полной вероятности
Но по формуле полной вероятности  Поэтому
Поэтому 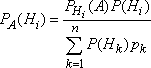 Формула (12) называется формулой Бейеса*.
Формула (12) называется формулой Бейеса*. того, что событие A наступит k раз в n независимых испытаниях, равна:
того, что событие A наступит k раз в n независимых испытаниях, равна:  где.
где.  .
. независимых испытаний, проведенных в одинаковых условиях, событие
независимых испытаний, проведенных в одинаковых условиях, событие  наступает с вероятностью
наступает с вероятностью 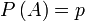 , следовательно противоположное ему событие с вероятностью
, следовательно противоположное ему событие с вероятностью  Обозначим
Обозначим  наступление события
наступление события  Так как условия проведения опытов одинаковые, то эти вероятности равны. Пусть в результате
Так как условия проведения опытов одинаковые, то эти вероятности равны. Пусть в результате  раз, тогда остальные
раз, тогда остальные  раз это событие не наступает. Событие
раз это событие не наступает. Событие 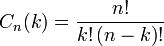 При этом вероятность каждой комбинации равна произведению вероятностей:
При этом вероятность каждой комбинации равна произведению вероятностей:  Применяя теорему сложения вероятностей несовместных событий, получим окончательную Формулу Бернулли:
Применяя теорему сложения вероятностей несовместных событий, получим окончательную Формулу Бернулли:  Для определения значений φ (x) можно воспользоваться специальной таблицей.
Для определения значений φ (x) можно воспользоваться специальной таблицей. -функция Лапласа
-функция Лапласа  Значения функции Лапласа находят по специальной таблице.
Значения функции Лапласа находят по специальной таблице. где х = (k—np)/ √ npq.
где х = (k—np)/ √ npq. По таблице п найдем ф(1, 37) =0, 1561. Искомая вероятность
По таблице п найдем ф(1, 37) =0, 1561. Искомая вероятность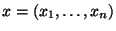 -- независимая выборка из распределения
-- независимая выборка из распределения  зависящего от неизвестного параметра
зависящего от неизвестного параметра  Теоретическим моментом
Теоретическим моментом 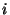 -го порядка называется функция
-го порядка называется функция 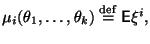 где
где  -- случайная величина с функцией распределения
-- случайная величина с функцией распределения  существуют, по крайней мере, для
существуют, по крайней мере, для  Эмпирическим моментом
Эмпирическим моментом 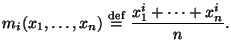 Отметим, что по своему определению эмпирические моменты являются функциями от выборки. Заметим, что
Отметим, что по своему определению эмпирические моменты являются функциями от выборки. Заметим, что  -- это хорошо нам известное выборочное среднее.
-- это хорошо нам известное выборочное среднее.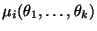
 , и составить следующую систему уравнений для неизвестных переменных
, и составить следующую систему уравнений для неизвестных переменных 
 В этой системе
В этой системе 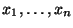 рассматриваются как фиксированные параметры.
рассматриваются как фиксированные параметры. Это и есть искомые оценки параметров по методу моментов.
Это и есть искомые оценки параметров по методу моментов. в слабое пространство
в слабое пространство  — пространство с мерой. Пусть также
— пространство с мерой. Пусть также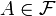
 — суммируемая на
— суммируемая на 

 — неотрицательная вещественная измеримая функция, неубывающая на области определения
— неотрицательная вещественная измеримая функция, неубывающая на области определения  то
то  В терминах пространства
В терминах пространства  Тогда
Тогда 
 определена на вероятностном пространстве
определена на вероятностном пространстве  , а её математическое ожидание
, а её математическое ожидание  и дисперсия
и дисперсия  конечны. Тогда
конечны. Тогда 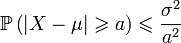 где
где  Если
Если  , где
, где  — стандартное отклонение и
— стандартное отклонение и  , то получаем
, то получаем 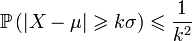 В частности, случайная величина с конечной дисперсией отклоняется от среднего больше, чем на
В частности, случайная величина с конечной дисперсией отклоняется от среднего больше, чем на  стандартных отклонения, с вероятностью меньше
стандартных отклонения, с вероятностью меньше 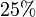 Она отклоняется от среднего на
Она отклоняется от среднего на  стандартных отклонения с вероятностью меньше
стандартных отклонения с вероятностью меньше  .
. от ее математического ожидания:
от ее математического ожидания: 
 при условиях
при условиях  Иногда на
Иногда на  также накладывается некоторый набор ограничений в виде равенств, но от них можно избавиться, последовательно выражая одну переменную через другие и подставляя её во всех остальных равенствах и неравенствах (а также в функции
также накладывается некоторый набор ограничений в виде равенств, но от них можно избавиться, последовательно выражая одну переменную через другие и подставляя её во всех остальных равенствах и неравенствах (а также в функции 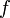 ). Такую задачу называют «основной» или «стандартной» в линейном программировании.
). Такую задачу называют «основной» или «стандартной» в линейном программировании. является полуплоскость. Для того, чтобы определить, какая из двух полуплоскостей соответствует этому неравенству, нужно привести его к виду
является полуплоскость. Для того, чтобы определить, какая из двух полуплоскостей соответствует этому неравенству, нужно привести его к виду  или
или 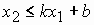 Тогда искомая полуплоскость в первом случае расположена выше прямой a0 + a1x1 + a2x2 = 0, а во втором - ниже нее. Если a2=0, то неравенство (8) имеет вид
Тогда искомая полуплоскость в первом случае расположена выше прямой a0 + a1x1 + a2x2 = 0, а во втором - ниже нее. Если a2=0, то неравенство (8) имеет вид  ; в этом случае получим либо
; в этом случае получим либо  - правую полуплоскость, либо
- правую полуплоскость, либо  - левую полуплоскость.
- левую полуплоскость. Рис. 2
Рис. 2 найти такое, при котором линейная целевая функция f принимает наименьшее значение.
найти такое, при котором линейная целевая функция f принимает наименьшее значение.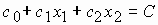 При параллельном переносе этой прямой в положительном направлении вектора нормали n(c1, c2) линейная функция f будет возрастать, а при ее переносе в противоположном направлении - убывать.
При параллельном переносе этой прямой в положительном направлении вектора нормали n(c1, c2) линейная функция f будет возрастать, а при ее переносе в противоположном направлении - убывать. Максимальный по абсолютному значению отрицательный коэффициент (-4) определяет ведущий столбец и переменную x3, которая перейдет в базис. Минимальное симплексное отношение (2/3) соответствует второй строке таблицы, следовательно, переменная R2 должна быть из базиса исключена. Ведущий элемент обведен контуром.
Максимальный по абсолютному значению отрицательный коэффициент (-4) определяет ведущий столбец и переменную x3, которая перейдет в базис. Минимальное симплексное отношение (2/3) соответствует второй строке таблицы, следовательно, переменная R2 должна быть из базиса исключена. Ведущий элемент обведен контуром.  В методе искусственного базиса искусственные переменные, исключенные из базиса, в него больше не возвращаются, поэтому столбцы элементов таких переменных опускаются. Табл. 2. сократилась на 1 столбец. Осуществляя пересчет этой таблицы, переходим к табл. 3., в которой строка M обнулилась, ее можно убрать. После исключения из базиса всех искусственных переменных получаем допустимое базисное решение исходной задачи, которое в рассматриваемом примере является оптимальным:
В методе искусственного базиса искусственные переменные, исключенные из базиса, в него больше не возвращаются, поэтому столбцы элементов таких переменных опускаются. Табл. 2. сократилась на 1 столбец. Осуществляя пересчет этой таблицы, переходим к табл. 3., в которой строка M обнулилась, ее можно убрать. После исключения из базиса всех искусственных переменных получаем допустимое базисное решение исходной задачи, которое в рассматриваемом примере является оптимальным:  при условиях
при условиях
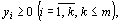 называется двойственной по отношению к задаче (32) – (34). Задачи (32) – (34) и (35) – (37) образуют пару задач, называемую в линейном программировании двойственной парой. Сравнивая две сформулированные задачи, видим, что двойственная задача составляется согласно следующим правилам:
называется двойственной по отношению к задаче (32) – (34). Задачи (32) – (34) и (35) – (37) образуют пару задач, называемую в линейном программировании двойственной парой. Сравнивая две сформулированные задачи, видим, что двойственная задача составляется согласно следующим правилам:  составленная из коэффициентов при неизвестных в системе ограничений (33) исходной задачи (32) – (34), и аналогичная матрица
составленная из коэффициентов при неизвестных в системе ограничений (33) исходной задачи (32) – (34), и аналогичная матрица  в двойственной задаче (35) – (37) получаются друг из друга транспонированием (т. е. заменой строк столбцами, а столбцов – строками).
в двойственной задаче (35) – (37) получаются друг из друга транспонированием (т. е. заменой строк столбцами, а столбцов – строками). . В противном случае переменная уj может принимать как положительные, так и отрицательные значения.
. В противном случае переменная уj может принимать как положительные, так и отрицательные значения. ”. Таким образом, переменные обеих задач могут принимать только лишь неотрицательные значения.
”. Таким образом, переменные обеих задач могут принимать только лишь неотрицательные значения. 3, в силу того, что интересы предприятия требуют, чтобы доход от продажи сырья был не меньше, чем от реализации продукции. Именно в силу такого экономического толкования система ограничений двойственной задачи принимает вид:
3, в силу того, что интересы предприятия требуют, чтобы доход от продажи сырья был не меньше, чем от реализации продукции. Именно в силу такого экономического толкования система ограничений двойственной задачи принимает вид:  А целевая функция G = 400y1 + 300y2 + 100y3 подсчитывает условную суммарную стоимость всего имеющегося сырья. Понятно, что в силу I теоремы двойственности F(x*) = G(y*) равенство означает, что максимальная прибыль от продажи всей готовой продукции совпадает с минимальной условной ценой ресурсов. Условные оптимальные цены уi показывают наименьшую стоимость ресурсов, при которой выгодно обращать эти ресурсы в продукцию, производить.
А целевая функция G = 400y1 + 300y2 + 100y3 подсчитывает условную суммарную стоимость всего имеющегося сырья. Понятно, что в силу I теоремы двойственности F(x*) = G(y*) равенство означает, что максимальная прибыль от продажи всей готовой продукции совпадает с минимальной условной ценой ресурсов. Условные оптимальные цены уi показывают наименьшую стоимость ресурсов, при которой выгодно обращать эти ресурсы в продукцию, производить.