
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Экономико-статистическое моделирование и прогнозирование средствами MS Excel
Теоретическая поддержка
Наиболее широкое распространение при построении прогнозов развития в практике коммерческой деятельности получили экономико-статистические модели, которые описывают зависимость исследуемого экономического показателя от одного или нескольких факторов, оказывающих на него существенное влияние. MS Excel предлагает широкий диапазон средств для изучения экономической информации. Множество встроенных статистических функций (СРЗНАЧ, МЕДИАНА, МОДА и др.) используют для проведения несложного анализа данных. Если возможностей встроенных функций недостаточно, то обращаются к инструменту Описательная статистика, имеющийся в пакете «Статистический анализ» MS Excel. Выходной диапазон инструмента Описательная статистика содержит следующие статистические характеристики для каждой переменной из входного диапазона: среднее, стандартная ошибка, медиана, мода, стандартное отклонение, дисперсия и др. Корреляционный анализ – это раздел математической статистики, посвященный изучению взаимосвязей между случайными величинами. Основной целью корреляционного анализа является установление характера влияния факторной переменной на исследуемый показатель и определение тесноты их связи с тем, чтобы с достаточной степенью надежности строить модель развития исследуемого показателя. С технической точки зрения проведение корреляционного анализа сводится к расчету коэффициентов парной корреляции, значения которых помогут судить о характере и тесноте связи между исследуемым показателем и каждой отобранной факторной переменной. Коэффициент парной корреляции используется в качестве меры, характеризующей степень линейной связи двух переменных. Значение коэффициента корреляции лежит в интервале от -1 (в случае строгой линейной отрицательной связи) до +1 (в случае строгой линейной положительной связи). Соответственно, положительное значение коэффициента корреляции свидетельствует о прямой связи между исследуемым и факторным показателем, а отрицательное — об обратной. Чем ближе значение коэффициента корреляции к 1, тем теснее связь. Качественно оценить тесноту связи позволяет специальная шкала значений коэффициентов корреляции, разработанная профессором Колумбийского университета США Чеддоком (таблица 3.1).
Таблица 3.1 - Шкала значений коэффициентов корреляции
Для количественной оценки взаимосвязи двух наборов данных можно обратиться к статистической функции КОРРЕЛ, вызывая ее в диалоговом окне Мастера функций. Однако чаще всего в экономических расчетах приходится иметь дело сразу с несколькими (более двух) наборами данных, взаимосвязи которых требуется изучить. В этом случае рассчитывают коэффициент множественной корреляции, который принимает значения от 0 до 1, но несет в себе более универсальный смысл: чем ближе его значение к 1, тем в большей степени учтены факторы, влияющие на зависимую переменную, тем более точной выглядит построенная на основе отобранных факторов модель. В таких случаях обращаются к инструменту Корреляция, содержащемуся в пакете «Статистический анализ» Excel. Для этого используют команду Анализ данных из меню Сервис. В открывшемся окне Инструменты анализа вызывают инструмент Корреляция. Регрессионный анализ имеет своей целью вывод, определение (идентификацию) уравнения регрессии, включая статистическую оценку его параметров. В основе любой регрессионной модели лежит уравнение (или система уравнений) регрессии, которое показывает, каким будет в среднем изменение зависимой переменной у, если независимые переменные х примут конкретные значения. Это обстоятельство позволяет применять модель регрессии не только для анализа, но и для прогнозирования. Методика построения и виды моделей тренда. Если имеется некоторая совокупность данных, характеризующих динамику исследуемого показателя, то всегда можно попытаться найти на графике наилучшую линию, которая будет «ближайшей» к точкам наблюдений в рамках всей их совокупности. Чтобы составить прогноз развития исследуемого показателя, используя линии тренда Excel, сначала необходимо с помощью Мастера диаграмм построить диаграмму его динамики на основе базовых данных. Когда диаграмма построена, открывается контекстное меню, в котором содержится команда «Добавить линию тренда». После ее выбора Excel выведет окно диалога Линии тренда, содержащее две основные вкладки: Тип и Параметры. Прогнозирование с применением функции экспоненциального сглаживания. Для составления прогнозов методом экспоненциального сглаживания в Excel предусмотрен инструмент Экспоненциальное сглаживание. Активизировать инструмент Экспоненциальное сглаживание можно из меню Сервис после загрузки надстройки Пакет анализа посредством команды Анализ данных. Инструмент Экспоненциальное сглаживание целесообразно применять для составления прогнозов только на период, непосредственно следующий за интервалом базовых наблюдений. Вычисление скользящего среднего средствами Excel. Инструмент Скользящее среднее можно вызвать в диалоговом окне команды Анализ данных из меню Сервис. Как правило, прогноз с применением скользящего среднего составляется на период, непосредственно следующий за интервалом наблюдения. Составление линейных прогнозов средствами Excel Функция рабочего листа ЛИНЕЙН помогает определить характер линейной связи между результатами наблюдений и временем их фиксации и дать ей математическое описание, наилучшим образом аппроксимирующее исходные данные. Функция ТЕНДЕНЦИЯ рассчитывает прогнозные значения исследуемого показателя в соответствии с линейным трендом. Функция ПРЕДСКАЗ аналогична функции ТЕНДЕНЦИЯ за исключением того, что она определяет лишь одну точку на линии тренда и не может рассчитать массив, который формирует эту линию. Поэтому ее удобно использовать для оперативного вычисления единичных прогнозов. Использование возможностей Excel при построении нелинейных прогнозов Функция ЛГРФПРИБЛ работает подобно функции ЛИНЕЙН. Различия между ними состоят лишь в том, что ЛИНЕЙН определяет параметры прямой линии, наилучшим образом аппроксимирующей исходные данные, а функция ЛГРФПРИБЛ — экспоненциальной кривой. В то время как функция ЛГРФПРИБЛ рассчитывает параметры уравнения экспоненциальной кривой роста, которая аппроксимирует наилучшим образом множество базовых данных, функция РОСТ определяет точки, лежащие на этой кривой. Вызвать функции ЛИНЕЙН, ТЕНДЕНЦИЯ, ПРЕДСКАЗ, ЛГРФПРИБЛ и РОСТ можно в диалоговом окне Мастера функций (категория «Статистические»), расположенном на панели инструментов Стандартная. Задание 1. Использование инструмента Описательная статистика В рамках оценки конкурентоспособности гастронома исследовать центральную тенденцию и изменчивость уровня рентабельности двадцати продовольственных магазинов (гастрономов) области на основе следующих собранных по ним за отчетный период данных (таблица 3.2).
Таблица 3.2 - Данные об уровне рентабельности по магазинам (гастрономам) области за отчетный период
Выполнение: Порядок обработки ряда данных с помощью инструмента Описательная статистика установлен в диалоговом окне Описательная статистика, которое можно вызвать из меню Сервис через команду Анализ данных. Открывшееся окно диалога предлагает пользователю определиться с набором следующих параметров (рисунок 3.1): 1) Входной диапазон (интервал) — предполагает ввод ссылки на ячейки рабочего листа, которые содержат анализируемые данные. Тогда входной диапазон объединяет ячейки В1: В21; 2) Группирование — требует установления переключателя в положение «По столбцам» или «По строкам» в зависимости от расположения данных во входном диапазоне. Поскольку данные об уровне рентабельности расположены в таблице 3.2 в виде столбца, то переключатель следует установить в положение «По столбцам»; 3) Метки в первой строке/Метки в первом столбце — позволяет определить название каждого столбца (или строки) выходной таблицы. Переключатель устанавливается в положение «Метки в первой строке», если первая строка во входном диапазоне содержит названия столбцов. Когда в первом столбце входного диапазона находятся названия строк, переключатель устанавливается в положение «Метки в первом столбце». Если входной диапазон не содержит меток, то необходимые заголовки в выходном диапазоне создаются на основе программы автоматически. Учитывая, что в таблице 3.2 первая строка содержит названия столбцов, переключатель следует установить в положение «Метки в первой строке»; 4) Уровень надежности — используется, если в выходную таблицу необходимо включить строку для уровня надежности. Тогда в соответствующее поле диалогового окна вводится требуемое значение. В экономических расчетах, как правило, значения уровня надежности задают в размере 95 или 99 %. Например, значение 95 % вычисляет уровень надежности среднего со значимостью 0, 05; 5) К-й наибольший — применяется, если в выходную таблицу необходимо включить строку для k-го наибольшего значения входного диапазона данных. В соответствующем окне вводится число k. Если k равно 1, эта строка будет содержать максимум из набора данных. Например, при оценке конкурентоспособности нашего гастронома (пусть в таблице 3.2 он имеет порядковый номер 7) для нас важно проследить, попал ли уровень его рентабельности в первую тройку наиболее высокорентабельных предприятий, а также, каков диапазон изменения уровня рентабельности у трех самых высокорентабельных магазинов. Тогда для k-го наибольшего в диалоговом окне надо ввести цифру 3 (т.е. k = 3). Это значит, что в выходной таблице, кроме максимального значения уровня рентабельности, будет отражен третий за ним по убывающей размер уровня рентабельности из всей исследуемой совокупности данных; 6) К-й наименьший — применяется, если в выходную таблицу необходимо включить строку для k-го наименьшего значения входного диапазона данных. В соответствующем окне вводится число k. Если k равно 1, эта строка будет содержать минимум из набора данных. Например, для нас важно убедиться, что уровень рентабельности исследуемого гастронома не относится к пяти самым низким показателям. Тогда в диалоговом окне для k-го наименьшего вводится цифра 5. Это значит, что в выходной таблице, кроме минимального значения уровня рентабельности, будет отражен пятый за ним по возрастающей размер уровня рентабельности; 7) Выходной диапазон — предполагает введение ссылки на левую верхнюю ячейку выходного диапазона. Инструмент Описательная статистика выводит два столбца сведений для каждого набора данных. Левый столбец содержит наименования рассчитанных статистических величин, а правый — их значения. В нашем случае выходная таблица статистических характеристик должна быть расположена, например, на том же рабочем листе, что и входная, на одном с ней уровне, но правее. Тогда можно задать следующий выходной диапазон — D1; 8) Новый лист — применяют, чтобы открыть новый лист в книге и вставить результаты анализа, начиная с ячейки А1. При необходимости в поле диалогового окна, расположенном напротив соответствующего положения переключателя, вводится имя нового листа; 9) Новая книга — используется, когда необходимо открыть новую книгу и вставить результаты анализа в ячейку А1 на первом листе этой книги; 10) Итоговая статистика — требует установления флажка, который означает, что в выходном диапазоне необходимо получить полный список статистических характеристик: Среднее, Стандартная ошибка (среднего), Медиана, Мода, Стандартное отклонение, Дисперсия выборки, Эксцесс, Асимметричность, Интервал, Минимум, Максимум, Сумма, Счет, Наибольшее (k-e), Наименьшее (k-e), Уровень надежности.
Рисунок 3.1 - Окно диалога Описательная статистика
Проведение всех вышеобозначенных действий с данными таблицы 3.2 позволяет получить следующую итоговую таблицу обобщенных статистических характеристик уровня рентабельности исследуемых торговых предприятий (таблица 3.3).
Таблица 3.3 - Статистическая оценка данных об уровне рентабельности по магазинам (гастрономам) области за отчетный год
Продолжение таблицы 3.3
Вывод: Приведенные в таблице 3.3 данные позволяют оперативно проследить, что уровень рентабельности по двадцати исследуемым предприятиям за анализируемый период сложился в среднем 0, 94+0, 46 % и колебался в пределах 0, 02-1, 67 %. С известной долей условности можно предположить, что приблизительно 68 % магазинов имели уровень рентабельности между 0, 48% (0, 94 - 0, 46) и 1, 4% (0, 94 + 0, 46). Стандартное отклонение (± 0, 456) свидетельствует о достаточно сильном разбросе размеров уровня рентабельности предприятий относительно его среднего значения, т.е. отобранные магазины далеко не в равной степени могут рассматриваться в качестве конкурентов нашего предприятия. Исследуемый гастроном № 7, имея уровень рентабельности 1, 23 %, не относится к тройке самых высокорентабельных предприятий (1, 43-1, 67 %), но, судя по медиане, принадлежит к той половине предприятий, которая обладает большей рентабельностью. Чаще всего в выборке присутствует уровень рентабельности 1, 22 % (что тоже ниже показателя нашего гастронома), а отрицательное значение коэффициента асимметрии свидетельствует о более высокой плотности распределения значений уровня рентабельности, больших величины 1, 22 % (левосторонней асимметрии). Следовательно, по показателю рентабельности у гастронома № 7 гораздо меньше реальных конкурентов, чем общее количество членов выборки. При этом рассчитанные коэффициенты асимметрии и эксцесса указывают на неоднородность исследуемого массива данных и необходимость пересмотра его состава. В этой связи для проведения углубленного анализа реальных конкурентов магазина № 7 по избранному признаку целесообразно пересмотреть и урезать выборку.
Задание 2. Проведение корреляционного анализа Провести корреляционный анализ товарооборота на основе информации, подготовленной с помощью электронных таблиц Excel (таблица 3.4). Для проведения корреляционного анализа объема товарооборота (исследуемый показатель) могут быть отобраны следующие факторы: - товарооборачиваемость в днях; - удельный вес торговой площади в общей площади предприятия; - удельный вес торгово-оперативных работников в их общей численности; - удельный вес товаров с высоким (в рамках установленного действующим законодательством предельного уровня) уровнем торговых надбавок.
Таблица 3.4 - Исходные данные для проведения корреляционного анализа
Выполнение: Для количественной оценки взаимосвязи объема данных обращаются к инструменту Корреляция, содержащемуся в пакете «Статистический анализ» Excel. Для этого используют команду Анализ данных из меню Сервис. В открывшемся окне Инструменты анализа вызывают инструмент Корреляция, диалоговое окно которого предлагает пользователю определить следующие параметры (рисунок 3.2): 1) Входной диапазон (интервал) — предполагает ввод ссылки на ячейки рабочего листа, которые содержат анализируемые данные. Для данных таблицы 3.4 входной диапазон имеет вид - B2: F18; 2) Группирование — требует установления переключателя в положение «По столбцам» или «По строкам» в зависимости от расположения данных во входном диапазоне. Поскольку анализируемые наборы данных расположены в таблице 3.4 в виде столбцов, то переключатель следует установить в положение «По столбцам»; 3) Метки в первой строке/Метки в первом столбце — позволяет определить название каждого столбца (или строки) выходной таблицы. Переключатель устанавливается в положение «Метки в первой строке», если первая строка во входном диапазоне содержит названия столбцов. Когда в первом столбце входного диапазона находятся названия строк, переключатель устанавливается в положение «Метки в первом столбце». Если входной диапазон не содержит меток, то необходимые заголовки в выходном диапазоне создаются на основе программы автоматически. Учитывая, что в таблице 3.4 первая строка содержит названия столбцов, переключатель следует установить в положение «Метки в первой строке»; 4) Выходной диапазон — предполагает введение ссылки на левую верхнюю ячейку выходного диапазона. Например, если необходимо, чтобы выходная таблица располагалась на том же рабочем листе, что и входная, и непосредственно под ней, то можно задать выходной диапазон ячейкой А21; 5) Новый лист — применяют, чтобы открыть новый лист в книге и вставить результаты анализа, начиная с ячейки А1. При необходимости в поле диалогового окна, расположенном напротив соответствующего положения переключателя, вводится имя нового листа; 6) Новая книга — используется, когда необходимо открыть новую книгу и вставить результаты анализа в ячейку А1 на первом листе этой книги.
Рисунок 3.2 - Окно диалога Корреляция
Проведение всех обозначенных действий с данными таблицы 3.4 позволяет получить матрицу значений парных коэффициентов корреляции, рассчитанных для всех возможных пар переменных без учета влияния других факторов (таблица 3.5). Поскольку коэффициент корреляции двух наборов данных не зависит от последовательности их обработки, то выходная область занимает только половину предназначенного для нее места. Ячейки выходного диапазона, имеющие совпадающие координаты строк и столбцов, содержат значение 1, так как каждая строка или столбец во входном диапазоне полностью коррелирует с самим собой. Таблица 3.5 - Матрица парных коэффициентов корреляции
Вывод: На основе приведенной матрицы можно содержательно оценить связь значений объема товарооборота с каждым из отобранных факторов и выбрать наиболее значимые из них для включения в модель. Так, полученные коэффициенты корреляции, характеризующие тесноту связи объема товарооборота с отобранными факторами (см. столбец В21: В26 таблицы 3.5), составляют соответственно: -0, 905 для фактора «оборачиваемость товаров»; 0, 750 для фактора «удельный вес торговой площади в общей»; 0, 509 для фактора «удельный вес товаров с высокими торговыми надбавками»; 0, 387 для фактора «удельный вес торгово-оперативного персонала в общей численности работников». Согласно шкале Чеддока (таблица 3.1), для данного торгового предприятия показатель объема товарооборота имеет весьма высокую тесноту связи с фактором «оборачиваемость товаров» и высокую — с фактором «удельный вес торговой площади в общей». Значение коэффициента корреляции, рассчитанное для товарооборота и фактора «удельный вес торгово-оперативного персонала», свидетельствует о слабо выраженной линейной связи между этими показателями. Знак «-» перед коэффициентом корреляции в ячейке В23 означает, что между объемом товарооборота и размером товарооборачиваемости в днях имеет место обратная связь, т.е. при росте количества дней одного оборота товарного запаса предприятия в днях (иными словами — замедлении товарооборачиваемости) объем его реализации при прочих равных условиях будет падать. С остальными факторами объем товарооборота находится в прямой зависимости. Задание 3. Прогнозирование развития показателей с помощью линии тренда Excel Составить прогноз товарооборота торгового предприятия на 17-й месяц (см. данные таблицы 3.6) с помощью команды Добавить линию тренда. Таблица 3.6 - Сведения о динамике товарооборота торгового предприятия
Выполнение: Чтобы составить прогноз развития исследуемого показателя, используя линии тренда Excel, сначала необходимо с помощью Мастера диаграмм построить диаграмму (График) его динамики на основе базовых данных (ячейки В3: В19 таблицы 3.6). Когда диаграмма построена, необходимо щелкнуть правой клавишей мыши на любой точке графика, чтобы открылось контекстное меню, в котором содержится команда Добавить линию тренда. После ее выбора Excel выведет окно диалога Линии тренда, содержащее две основные вкладки: Тип и Параметры. Вкладка Тип помогает пользователю выбрать тип линии тренда, которая будет аппроксимировать исходные данные. В диалоговом окне предлагается пять типов линий тренда. Для их построения Excel использует модели следующего вида: - линейную (у = mх + b); - полиномиальную (у = b + m1x + m2x2 +...+ m6х6); - логарифмическую (у = m · ln x + b); - экспоненциальную (у = m · еb· x); - степенную (у = m · хb). После задания типа линии тренда выделяют вкладку Параметры. Откроется ее окно диалога, в котором пользователь определяет следующие важные моменты: 1) количество прогнозируемых периодов и направление прогноза: вперед или назад; 2) когда выбрана линейная, полиномиальная или экспоненциальная кривая роста, то в поле Пересечение кривой с осью у в точке 0 задается ее у-пересечение: если данное поле обозначить флажком, то Excel будет искать лучшее уравнение кривой, которая на координатной плоскости обязательно должна пройти через начало координат; 3) через установку флажка в соответствующих полях окна диалога пользователь решает, отражать ли на выходной диаграмме уравнение, на основе которого была построена линия тренда, и размер квадрата коэффициента корреляции r2, характеризующий качество аппроксимации. C помощью команды Добавить линию тренда составим сразу пять различных вариантов прогноза товарооборота торгового предприятия на 17-й месяц и при этом по r2 оценить общее качество моделей, на основе которых они были получены. Используя возможности Excel по созданию в ячейках рабочего листа формул, с помощью приведенных на графиках уравнений кривых роста рассчитаем значения прогноза товарооборота на 17-й месяц (таблица 3.7).
Таблица 3.7 - Прогноз товарооборота на 17-й месяц
Вывод: Приведенные на рисунках 3.3–3.8 графики динамики товарооборота свидетельствуют, что наибольшая степень приближения линии тренда к базовым данным достигнута в случае полиномиальной кривой роста 3-й степени (см. рисунок 3.6, r2 = 0, 9519), наименьшая — в случае логарифмической кривой (см. рисунок 3.5, r2 = 0, 7779).
Задание 4. Прогнозирование с применением функции экспоненциального сглаживания Составить прогноз товарооборота торгового предприятия на основе данных таблицы 3.6 с помощью инструмента Экспоненциальное сглаживание. Выполнение: Активизировать инструмент Экспоненциальное сглаживание можно из меню Сервис после загрузки надстройки Пакет анализа посредством команды Анализ данных. Открывшееся окно диалога Экспоненциальное сглаживание предлагает пользователю определиться со следующими параметрами (рисунок 3.9): 1) Входной диапазон — требует ссылки на ячейки, содержащие данные об исследуемом показателе. Этот диапазон должен состоять из одного столбца или одной строки и содержать данные как минимум в четырех ячейках. В нашем примере параметр Входной диапазон включает ячейки В2: В19 (таблица 3.8); 2) Фактор затухания — это корректировочный фактор, минимизирующий нестабильность совокупности данных. Он может иметь значения в пределах от 0 до 1. По умолчанию пользователя Excel самостоятельно принимает значение фактора затухания равным 0, 3. В нашем примере для параметра Фактор затухания введем значение 0, 1; 3) Метки — требует установки флажка, если первая строка или первый столбец входного диапазона содержит заголовки (название столбца или строки). В нашем примере установим флажок для параметра Метки; 4) Выходной диапазон — предполагает ссылку на верхнюю ячейку выходного диапазона. В нашем примере установим верхнюю ячейку Выходного диапазона – С3; 5) Вывод графика — требует установки флажка, если пользователю, кроме значения прогноза, необходимо получить встроенную диаграмму динамики фактических и расчетных значений; 6) Стандартные погрешности — требует установки флажка, если пользователю для проведения оценки качества прогнозов необходимо включить в выходной диапазон столбец со стандартными погрешностями e(t).
Рисунок 3.9 - Окно диалога «Экспоненциальное сглаживание»
В результате работы инструмента Экспоненциальное сглаживание получаем следующие сглаженные показатели товарооборота (см. столбец С таблицы 3.8), в том числе прогноз на 17-й месяц — 35 908 ден. ед.
Таблица 3.8 - Расчет прогноза товарооборота с помощью инструмента Экспоненциальное сглаживание
|
Последнее изменение этой страницы: 2017-03-14; Просмотров: 840; Нарушение авторского права страницы


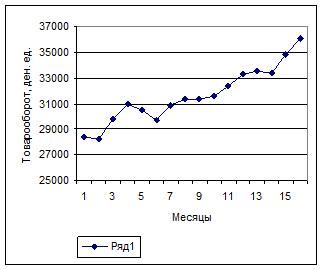 Рисунок 3.3 - График развития товарооборота торгового предприятия
Рисунок 3.3 - График развития товарооборота торгового предприятия
 Рисунок 3.4 - Оценка прогноза товарооборота торгового предприятия на основе линейной кривой роста
Рисунок 3.4 - Оценка прогноза товарооборота торгового предприятия на основе линейной кривой роста
 Рисунок 3.5 - Оценка прогноза товарооборота на основе логарифмической кривой роста
Рисунок 3.5 - Оценка прогноза товарооборота на основе логарифмической кривой роста
 Рисунок 3.6 - Оценка прогноза товарооборота на основе полиномиальной кривой роста (степень 3)
Рисунок 3.6 - Оценка прогноза товарооборота на основе полиномиальной кривой роста (степень 3)
 Рисунок 3.7 - Оценка прогноза товарооборота на основе степенной кривой роста
Рисунок 3.7 - Оценка прогноза товарооборота на основе степенной кривой роста
 Рисунок 3.8 - Оценка прогноза товарооборота на основе экспоненциальной кривой роста
Рисунок 3.8 - Оценка прогноза товарооборота на основе экспоненциальной кривой роста
