
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Определение необходимого числа наблюдений
В зависимости от степени охвата объекта исследования принято различать сплошное (генеральное) и не сплошное (выборочное) статистическое наблюдение. Но при использовании выборочного метода необходимо учитывать, что выборочная совокупность должна быть репрезентативной, т.е. представительной. Иначе говоря, результаты, полученные на части единиц наблюдения, должны соответствовать данным всей (генеральной) выборке (совокупности). Мерой репрезентативности является разность между средними (или относительными) величинами в выборочной и генеральной совокупности. Для упрощения определения необходимого числа наблюдений при проведении комплексных медико-социальных исследований, в зависимости от желаемой точности и уверенности в результатах исследования, пользуются уже рассчитанным необходимым числом наблюдений по таблице К. А. Отдельной (где К – коэффициент точности, уровень которого выбирает сам исследователь – от 0, 5 до 0, 1; t – стандартное отклонение признака от средней арифметической; р – степень уверенности в заданной неточности результата исследования): Таблица 8. Необходимый объем выборки
Как видно из таблицы 8, необходимый объем выборки для получения устойчивых результатов с достаточной степенью уверенности и точности составляет 400 (к=0, 1; р=0, 95). Для получения устойчивого результата при минимальной точности и достоверности, необходимое число единиц наблюдения составляет 16 (к=0, 5; р=0, 95). Основные ошибки статистического анализа (четвертый этап исследования). Число ошибок статистического анализа можно объединить в три группы: 1. Ошибки методики – к ним относятся арифметические ошибки; недостаточное число наблюдений, что ведет к получению недостоверных результатов; неправильное определение единицы наблюдения; использование слишком сложных таблиц, содержащих много признаков; недостаточность обработки данных (отсутствие расчета относительных величин, не составлены динамические ряды, не рассчитаны коэффициенты корреляции); неправильность группировки, что может привести к неоднородности групп. 2. Неправильная оценка показателей – это смешение экстенсивных и интенсивных показателей (вывод о большей или меньшей частоте каких-либо явлений, процессов можно делать только на основании интенсивных показателей); составление вывода на искусственно отобранных группах; оценка темпа роста без учета исходного уровня; представление слишком общих сведений, без проведения детального анализа материала; не использование метода стандартизации при анализе показателей, характеризующих статистические совокупности, имеющие разный состав по каким-то признакам (полу, возрасту, нозологии заболеваний); 3. Третья группа ошибок – это логические ошибки формального анализа. К ним, в основном, относятся следующие ошибки: вывод, сделанный на основе простого сравнения цифр без учета качественной характеристики явления; отсутствие установления достоверной связи между последовательными событиями (“post hoc, non propter hoc” – после этого, не значит, что вследствие этого), так, если у больного страдающего гипертонической болезнью, случилось обострение, наступил криз, после ссоры с соседями по квартире, то это не является, что криз обусловлен только вследствие ссоры, т.к. больной страдал еще и гипертонической болезнью; недостаточность изучения всесторонних связей данного явления (статистические связи между причиной и следствием, временные, пространственные и прочие не однозначны. Они вероятны в той или иной степени). Таким образом, статистический анализ – это не только анализ цифр и явлений, но в значительной мере искусство специалиста, умение выделить из ряда последовательных событий ведущие, установить достоверную связь между ними, наметить пути воздействия.
Контрольные вопросы.
1. Каково назначение статистики как науки? Что ее отличает от медицинской статистики? 2. Какие наблюдения называются сплошными и какие - несплошными? 3. Что такое: монографическое описание; метод основного массива; выборочное исследование? 4. В каких случаях используются статистические методы исследования в здравоохранении? 5. Какова характерная черта статистики как общественной науки? 6. Являются ли причинные взаимосвязи в обществе единичными или они многообразны? В чём проявляется их многообразие? 7. Зачем нужно изучать статистику в медицинских ВУЗах; нужна ли она врачу или только научным сотрудникам? 8. Чем обуславливается успех в медико-статистическом исследовании? 9. Перечислите последовательность (этапы) в организации методики статистического исследования. 10. Что включает в себя подготовительный (организационный) этап статистического исследования? 11. Что понимается под объектом медико-социального исследования? 12. Что такое единица наблюдения? 13. Что относится к количественным признакам явления? 14. Что относится к качественным признакам явления? 15. Из каких подэтапов состоит третий этап медико-социального исследования? Дайте краткую характеристику каждого подэтапа. 16. Какие основные типы графических изображений используются в медико-социальных исследованиях? 17. Какие вы знаете варианты практического использования результатов медико-социального исследования? 18. Какие разделы включаются в программу любого исследования? 19. Из каких источников можно получить информацию о состоянии здоровья исследуемого контингента населения? 20. Какими методами можно получить сведения об условиях и образе жизни населения? 21. Что такое репрезентативность? 22. Каков должен быть объем выборки для получения устойчивых результатов с достаточной степенью уверенности и точности? 23. Какие основные ошибки могут наблюдаться при анализе медико-статистического исследования? 24. Приведите пример статистической совокупности и ее структурных единиц. 25. Ниже приведены цифры, полученные из разного типа таблиц: 1) 150 мужчин в возрасте 20 лет, больных гипертонией I стадии; 2) 500 мужчин, больных гипертонией I стадии; 3) 1000 больных гипертонией I стадии. Студенты параллельной с вами группы утверждают, что цифра 150 в пункте 1 могла быть получена из комбинационной таблицы, цифра 500 в пункте 2 – из групповой, а цифра 1000 в пункте 3 – из простой. Согласны ли вы с вашими коллегами? Дайте обоснование.
Глава 16. Статистические методы исследования
На третьем этапе статистического исследования, т.е. при обработке данных, производится вычисление различных показателей, коэффициентов, величин и т.д. для чего должны быть использованы адекватные статистические методы. Основные величины, которыми пользуется статистика – это абсолютные и относительные величины. Абсолютные величины получаются в результате группировки и табличной сводки материалов наблюдения. Эти величины используются очень широко, т.к. они характеризуют собой размеры изучаемых явлений и процессов: например, численность населения в мире, в конкретной стране, в городе, районе и т.д.; число медицинского персонала и лечебно-профилактического учреждения (ЛПУ); количество больничных коек и прочее. В то же время, при рассмотрении абсолютных величин чаще всего можно сделать только некоторые предварительные выводы и для дальнейшего анализа, когда нужны сравнения – где больше, меньше, чаще, реже, выше, ниже, возникает необходимость в преобразовании этих величин в производные величины: относительные и средние. К относительным величинам относятся: экстенсивный показатель, интенсивный показатель, показатель соотношения, показатель наглядности, показатели динамического ряда. Причем, показатели и коэффициенты этих величин отличаются друг от друга тем, что они выражаются в процентах (%), промилле (‰), продецимилле (%00), просантимилле (%000), которые получаются из соотношения двух сравниваемых чисел, умноженных на 100 (тогда это проценты), на 1000 (промилле), на 10000 (продецимилле), на 100000 (просантимилле) и т.д. Какими и когда пользоваться относительными показателями (на что умножить) – решает сам исследователь. Нужно только учитывать что, чем реже встречается изучаемое явление, тем больше числовое основание следует избрать с тем, чтобы показатель был удобен в использовании, выражался целой величиной. В здравоохранении принято структуру какого-либо явления выражать в процентах; показатели рождаемости и смертности – в промилле; заболеваемость – в продецимилле или в просантимилле. Коэффициенты (в отличие от показателей соотношения), - это простое соотношение тех или других величин, которые ни на что не умножаются. С целью сравнительного анализа статистических данных, когда нам надо охарактеризовать структуру явления, показать долю признака или распределение признаков в данной совокупности, применяется экстенсивный показатель. Он, как правило, выражается в процентах (%) и рассчитывается по формуле:
Этот показатель характеризует первое свойство статистической совокупности – распределение признака, заключающееся в том, что единица статистической совокупности распределяется не одинаково по характеру учетного признака и образует определенную внутреннюю структуру. Числитель получают как сумму единиц с одинаковым признаком, а знаменатель – как сумму всех единиц. Например, в городе К. отмечено всего 1600 случаев инфекционных заболеваний, из которых 320 случаев кори. Какую долю занимают заболевания корью среди инфекционных заболеваний?
Решение:
Ответ: в городе К. корь среди всех инфекционных заболеваний составила 20%, следовательно, другие инфекции составили 80%. Если нам нужно охарактеризовать частоту явления, выяснить, где оно чаще, — применяется интенсивный показатель. Этот показатель указывает на уровень (распространенность) явления во взаимосвязанной с ним среде. К типичным интенсивным показателям относятся показатели рождаемости, смертности, заболеваемости в тех или иных группах людей в определенное время. Рассчитывается интенсивный показатель по формуле: числитель – явление; знаменатель – среда, породившая данное явление (своя среда) и результат умножается на 100 (%), 1000 (%0) или 10000 (%00):
среда
Например: в городе К. отмечено 320 случаев кори среди детей в возрасте от 0 до 4 лет, численность которых составляет 8000 человек. Какой уровень заболеваемости корью детей данной возрастной группы? Решение:
Ответ: в городе К. уровень заболеваемости корью детей в возрасте 0-4 лет составил 40%o. Этот показатель характеризует распространенность кори среди детей данной возрастной группы. Следует иметь в виду, что интенсивные и экстенсивные показатели могут совпадать в том случае, когда вся среда продуцирует данное явление. Например: при анализе заболеваемости за истекший год мы принимаем за 100% общее число зарегистрированных заболеваний и определяем, какой процент из них составляет каждая нозология в отдельности. Сопоставимы ли эти показатели в разные годы? Вполне, при условии примерной одинаковой численности и возрастно-полового состава населения данной территории. При условии же необходимости определения частоты признаков в какой-то другой среде, мы должны вычислять показатель соотношения , который характеризует отношение двух самостоятельных совокупностей, выраженный в %, ‰, %00. Вычисляется показатель соотношения по формуле: числитель-совокупность А (явление), знаменатель-совокупность В (другая среда), с последующим умножением на 100, 1000 или 10000: Совокупность А (явление)
Совокупность В (другая среда)
Например: в городе К, где численность детей в возрасте 0-14 лет составляет 20000 человек, число врачей-педиатров детских поликлиник – 40. сколько штатных должностей врачей-педиатров приходится на 10000 детей в возрасте 0-14 лет? Решение:
Число штатных должностей врачей-педиатров 40 х 10000
численность детей 20000 в возрасте 0-14 лет
Ответ: на каждые 10000 детей в возрасте 0-14 лет в городе К приходится 20 должностей врачей-педиатров Типичными показателями соотношения являются: обеспеченность населения врачами, средними медработниками, койками (в расчёте на 10000 человек). При анализе статистических данных, иногда выгодно бывает показать отношение какого-то признака к другому, принятому за 100. Этот показатель называется показателем наглядности и рассчитывается по формуле: числитель - явление, знаменатель – другое явление, принятое за 100%, умножить на 100: Явление
Другое (однородное) явление, принятое за 100%
Если не умножать на 100, то мы будем иметь коэффициент наглядности. Например, каждый пятый житель Земли – китаец:
6 млрд. человек, проживающих на Земле
1 млрд. 200 млн. человек населения Китая
В показатели наглядности можно преобразовать абсолютные величины, интенсивные показатели, средние величины, представленные как в статике, так и в динамике. Для анализа изменения явления во времени (динамика явления) в статистике используются динамические ряды. Динамическим рядом называется совокупность однородных статистических величин, показывающих изменение какого-либо явления на протяжении определенного промежутка времени. Динамические ряды могут состоять из абсолютных и относительных чисел, средних величин. Величины, составляющие динамический ряд, называются уровнями ряда. Если числа, из которых составляют уровни ряда – абсолютные числа, то такой динамический ряд называется простым. Когда же уровнями ряда выступают средние и относительные величины, то такой динамический ряд называется сложным или произвольным. Простые динамические ряды бывают моментные и интервальные. Моментный динамический ряд состоит из величин, характеризующих явление на какой-то определенный момент (дату). Например, каждый уровень может характеризовать численность населения, численность врачей и прочее на конец какого-то года (табл.9 ). Таблица 9 Моментный (простой) динамический ряд коечного фонда в городе К. с 1996 по 2001 год (на конец каждого года).
Уровни моментного ряда не могут дробиться Интервальный динамический ряд состоит из величин, характеризующих явление за определенный промежуток времени (интервал). Интервальный динамический ряд можно разделить на более дробные периоды или, напротив, укрупнить интервалы. Каждый уровень такого ряда может характеризовать смертность, рождаемость, заболеваемость, среднегодовую занятость койки за год (квартал, месяц) – размер интервала выбирается самим исследователем в зависимости от степени изменчивости явления (табл.10). Таблица 10. Интервальный динамический ряд сезонного колебания случаев острого тонзиллита в городе К. в течение года.
Как видно из таблицы, динамика изучаемого явления (число заболеваний острым тонзиллитом) представлена не в виде непрерывно меняющегося в одном направлении явления, а скачкообразными изменениями то увеличиваясь, то уменьшаясь. После укрупнения интервалов по кварталам года выявляется определенная закономерность – наибольшее число заболеваний приходится на летне-осенний период. Таким образом, укрупнение интервалов в нашем примере дало возможность произвести выравнивание уровней динамического ряда, которое ярче, определеннее выявило закономерность сезонных колебаний заболеваний острым тонзиллитом в городе К. Кроме укрупнения интервала, с целью выравнивания динамического ряда, пользуются расчетом скользящей средней и вычислением наименьших квадратов крайних средних скользящих по формуле Урбаха. Скользящая средняя вычисляется как средняя величина из данного уровня и двух соседних с ним (табл.11) Таблица 11 Показатель скользящей средней.
Расчет скользящей средней:
Для 1995 года
Для 1996 года
Для 2000 года
Однако этот метод исключает из анализа средние величины первого и последнего уровня. Поэтому для более точного определения тенденции изучаемого явления можно рассчитать скользящие средние крайних уровней методом наименьших квадратов по формуле Урбаха:
В нашем примере (табл.11):
Для 1994 года Для 2001 года
Как видим, метод наименьших квадратов позволяет рассчитать точки прохождения такой прямой линии, от которой имеющаяся эмпирическая находится на расстоянии наименьших квадратов от других возможных линий. Динамический ряд в случае применения данного метода должен иметь не менее пяти хронологических дат, количество их должно быть нечетным, а интервалы между ними – одинаковыми. Анализ динамических рядов проводится по комплексу следующих показателей: 1. Абсолютный прирост (или убыль) определяется как разность чисел данного уровня и предыдущего; 2. Темп прироста (убыли) – процентное отношение абсолютного прироста к предыдущему уровню и умножить на 100; 3. Темп роста в процентах – это отношение данного уровня к предыдущему и умножить на 100; 4. Абсолютное значение одного процента прироста (убыли) – это отношение абсолютного прироста (убыли) к темпу прироста (убыли).
Например: дана динамика числа лиц, охваченных профилактическими прививками с 1997 по 2000 год (табл.12). Рассчитать показатели динамического ряда и провести их анализ. Таблица 12
Решение: 1. Абсолютный прирост: Для 1998 года = 450 – 150 = +300; Для 1999 года = 700 – 450 = +250 и т.д. 2. Темп прироста:
Для 1998 года Для 1999 года 3. Темп роста в процентах:
Для 1998 года
Для 1999 года 4. Абсолютное значение одного процента прироста:
Для 1998 года
Для 1999 года
Вывод: данные анализа динамического ряда показывают, что отмечается увеличение охвата профилактическими прививками населения при значительном уменьшении темпа прироста (с +200% до +57%) и темпа роста (с +300% до +157, 1%), с наименьшим значением в 1999 году (темп роста составил +155, 5%). Результаты многих исследований, представленные в количественном выражении, часто многочисленны и малодоступны для их общего обозрения. В силу этого характер распределения изучаемых явлений лучше выявляется при анализе вариационных рядов или рядов распределения. Вариационный ряд – это ряд числовых измерений определённого признака, отличающихся друг от друга по своей величине, расположенных в ранговом порядке – по порядку, от меньшего к большему или наоборот. Вариационный ряд состоит из вариант (v) и соответствующих им частот (p). Вариантой (v) называют каждое числовое значение изучаемого признака. Частота (p) – абсолютная численность отдельных вариант в совокупности, указывающая, сколько раз встречается данная варианта в вариационном ряду. Общее число случаев наблюдений, из которых состоит вариационный ряд, обозначается буквой h. Если h включает в себя не более 30 наблюдений, то все значения признака располагают в нарастающем или убывающем порядке (от максимальной варианты до минимальной или наоборот) и указывают частоту каждой варианты. При большом числе наблюдений (более 30) вариационный ряд должен быть сгруппирован. Построение сгруппированного ряда учитывает разность между максимальным и минимальным значениями вариант и складывается из нескольких этапов: 1. Определение количества групп; 2. Определение интервала между группами; 3. Определение начала, середины и конца группы; 4. Распределение данных наблюдений по группам; 5. Графическое изображение вариационного ряда.
1 этап: Определение количества групп в вариационном ряду. В связи с тем, что количество групп зависит от числа наблюдений, то чем больше число наблюдений, тем больше может быть групп. Учитывая это, число групп в сгруппированном вариационном ряду определяется по специальной таблице в зависимости от числа наблюдений (табл. 13): Таблица 13 Число групп в зависимости от числа наблюдений.
При большом колебании признака его максимальные величины могут не соответствовать размерам последней группы и будут вне ее. В этом случае необходимо увеличить число групп с тем, чтобы можно было включить эти крайние варианты.
2 этап: Определение величины интервала (i) между группами. Определяя величину интервала между группами, амплитуду вариационного ряда (разность между максимальным и минимальным значениями вариант) делят на число групп: Величина интервала
Полученный интервал округляется до целого числа.
3 этап: определение начала, середины и конца группы. Поскольку середина группы должна делиться на величину интервала, то за середину первой группы следует брать варианту, которая будет ближайшей к максимальному значению и без остатка разделится на величину интервала. Середины для каждой последующей группы находят путем вычитания величины интервала от середины каждой предыдущей группы:
Середина последующей группы = середина предыдущей группы – i (величина интервала)
После составления ряда из величин, принятых за середину группы, необходимо определить границы (начало и конец) этих групп. При этом границы групп не должны повторяться, в противном случае будет трудно распределить варианты по группам и построить вариационный ряд. Определяя начало группы, к ее середине прибавляется величина
4 этап: распределение случаев наблюдения по группам проводится соответственно размерам показателей в группе. Результаты записываются по группам, получая, таким образом, частоты (p) вариационного ряда.
5 этап: графическое изображение вариационного ряда делают статистические данные обозримыми, доступными для анализа и дальнейшего изучения. В графическом изображении ось абсцесс (х) служит для отображения градации (середины групп) изучаемого признака (рост, масса тела, уровень Hb в крови), а ось ординат (у) – для отображения числа случаев с данной величиной признака. Все пять этапов выполняются при составлении сгруппированных вариационных рядов. При составлении не сгруппированных вариационных рядов – выполняются 1, 2 и 5 этапы.
Средние величины Каждая статистическая совокупность имеет особые групповые свойства, в частности средний уровень количественного признака, который измеряется средними величинами. Например, средний рост, средняя масса тела – при анализе физического развития группы населения; средняя длительность пребывания больного на койке; средняя продолжительность обследования больного – при анализе деятельности ЛПУ; средняя запыленность воздуха в цехе – при оценке загрязненности воздуха на предприятии и др. Таким образом, под средней величиной понимается число, выражающее общую меру исследуемого признака в совокупности. Средняя величина как бы выражает то общее, что характерно для признака в данной совокупности. В медицинской статистике используют три вида средних величин: среднюю арифметическую (М), моду (Мо), медиану (Ме). Мода (Мо) — соответствует величине признака, которая чаще других встречается в данной совокупности. Иначе говоря, за моду принимают варианту, которой соответствует наибольшее количество частот (p) вариационного ряда. Медиана (Ме) — величина признака, занимающая серединное положение в вариационном ряду. Она делит ряд на две равные части по числу наблюдений. Для определения медианы надо найти середину ряда. Так, принимают среднюю величину из двух центральных вариант, например, для ряда 2, 5, 6, 9, 11, 12, 15, 16 центральными вариантами будут 4-я и 5-я ( числовое значение 9 и 11). В этом случае медиана будет равна: Ме При нечетном числе наблюдений медианой будет серединная (центральная) варианта, которая определяется по формуле: Ме Например, при нечетном числе наблюдений (25 наблюдений), медианой будет серединная (центральная) варианта 13, так как в этом случае: Ме Это означает, что середина ряда приходится на тринадцатую варианту с начала ряда или тринадцатую варианту с конца ряда. Одной из возможных особенностей моды и медианы является то, что на их величины не оказывает влияние числовые значения крайних вариант. Например, если бы в вариационном ряду имелось максимальное нечетное абсолютное значение (предположим 65 кг), а минимальное абсолютное значение – четное (пусть будет 58 кг), то эти значения крайних вариант не отражаются ни на величине моды, ни на величине медианы. Следующая средняя величина, которая наиболее часто используется медицинской статистикой для характеристики среднего уровня признака, является средняя арифметическая величина (М). Средняя арифметическая величина бывает простой и взвешенной. Простая средняя арифметическая вычисляется из вариационного ряда, в котором каждая варианта встречается только один раз, т.е. для всех вариант р=1. Она определяется по формуле:
М – средняя арифметическая; n - значение вариационного ряда; n – общее число наблюдений.
Если в исследуемом вариационном ряду одна или несколько вариант повторяются, то вычисляется средняя арифметическая взвешенная (при р> 1). Расчет такой средней производится по формуле:
n – сумма частот (Sр).
Помимо рассмотренного метода прямого расчета средней арифметической взвешенной, существуют другие методы, в частности способ моментов, при котором несколько упрощены арифметические расчеты. Применяя этот способ, среднюю арифметическую рассчитывают по формуле:
А – условная средняя варианта, чаще других повторяющаяся в вариационном ряду; i – интервал между группами вариант; а – условное отклонение от условной средней (для этого из каждой варианты вычитаем условную среднюю: а=n-А); р – частота каждой варианты; n – число наблюдений. Например: необходимо произвести расчет средней арифметической по способу моментов длительности пребывания больных с язвенной болезнью в гастроэнтерологическом отделении больницы (табл.14), когда известно число дней лечения (n)и частота случаев (р), при i=1. Таблица 14
Расчет проводится в такой последовательности: 1. Среди вариант выбираем наиболее часто встречающуюся и находящуюся в центре вариационного ряда, которую принимаем за условную среднюю А (в нашем случае, это 32 дня лечения); 2. Определяем условное отклонение каждой варианты от условной средней (a1=27-32= -5; a2=28-32= -4 и т.д.); 3. Определяем произведение отклонений каждой варианты на ее частоту (а1× р1=-5× 2=-10; а2× р2=-4× 4=-16 и т.д.); 4. Определяем сумму всех отклонений, перемноженных на их частоты:
5. Определяем среднюю взвешенную по способу моментов:
Ответ: в рассматриваемом нами случае средняя длительность пребывания больных на лечении в гастроэнтерологическом отделении больницы составляет 31, 4 дня. Таким образом, средняя арифметическая одним числом характеризует совокупность, обобщая то, что свойственно всем ее вариантам, поэтому она имеет ту же размерность, что и каждая из вариант. Кроме того, средняя арифметическая величина обладает тремя свойствами: 1. Она занимает серединное положение в вариационном ряду: 2. Она является обобщающей величиной и за средней не видны случайные колебания, различия в индивидуальных данных. Средняя арифметическая вскрывает то типичное, что характерно для всей совокупности. В тоже время она абстрактна и поэтому не может правильно характеризовать совокупность из которой рассчитана; 3. Сумма отклонений всех вариант от средней равна нулю: Роль средних величин в медицине чрезвычайно велика. Их используют для характеристики явлений в целом; они необходимы для оценки отдельных величин, а также при сравнении отдельных величин со средними, когда получают ценные характеристики для каждой из них. В тоже время, использование средних величин требует строго соблюдения принципа однородности совокупности. Нарушение этого принципа ведет к искажению реальных процессов.
Контрольные вопросы. 1. Абсолютные величины; их получение, использование. 2. Относительные величины; их получение, использование; отличие от коэффициентов. 3. Экстенсивный показатель, что он характеризует собой? По какой формуле рассчитывается? 4. Интенсивный показатель, что он собой характеризует? По какой формуле рассчитывается? 5. Показатель соотношения, что он собой характеризует? По какой формуле рассчитывается? 6. Показатель наглядности, что он собой характеризует? По какой формуле рассчитывается? Какие величины и показатели можно преобразовывать в показатели наглядности? 7. Что такое динамические ряды? Какие динамические ряды являются простыми, а какие сложными? 8. В чем отличие между моментными и интервальными простыми динамическими рядами? 9. Что такое выравнивание уровней динамического ряда? Какими способами пользуются при выравнивании динамического ряда? 10. По каким показателям проводится анализ динамических рядов? 11. Что такое вариационный ряд? Из чего он состоит? Что такое варианта и частота вариационного ряда? 12. Как строится вариационный ряд при числе наблюдений не более 30 и при числе более 30 наблюдений? 13. Что включают в себя I и II этапы построения сгруппированного вариационного ряда? 14. Что включают в себя III и IV этапы? 15. С какой целью необходимо проведение V этапа построения сгруппированного вариационного ряда? При каких условиях проводятся все 5 этапов составления сгруппированных вариационных рядов и при каких условиях достаточно проведения только 3-х этапов (каких)? 16. Что понимается под средней величиной? Какие 3 вида средних величин наиболее часто используют в медицинской статистике? Как определяется мода и медиана? 17. Что такое средняя арифметическая величина? Как она подразделяется? Как вычисляется простая средняя арифметическая величина? 18. Как вычисляется средняя арифметическая взвешенная? Что такое способ моментов, чем он характеризуется и как высчитывается средняя арифметическая.? |
Последнее изменение этой страницы: 2017-04-12; Просмотров: 690; Нарушение авторского права страницы
 целое явление
целое явление
 ‰
‰ х 10000
х 10000
 х 10000 = = 20 %00
х 10000 = = 20 %00 х 100
х 100 ≈ 5
≈ 5

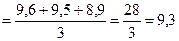



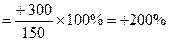
 и т.д.
и т.д.
 и т.д.
и т.д.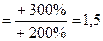 ;
; 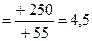 и т. д.
и т. д.
 ; вычитая же ее из середины, получаем конец группы. Границы должны быть составлены так, чтобы значения вариант не оказались между группами. Нежелательны также так называемые «открытые» группы, например «свыше 60» или «менее 20».
; вычитая же ее из середины, получаем конец группы. Границы должны быть составлены так, чтобы значения вариант не оказались между группами. Нежелательны также так называемые «открытые» группы, например «свыше 60» или «менее 20».


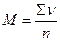 , где
, где , где
, где , где
, где ;
; 
 ;
;  . Это происходит потому, что средняя величина превышает размеры одних вариант и меньше размеров других вариант. Иначе говоря, истинное отклонение вариант от истинной средней
. Это происходит потому, что средняя величина превышает размеры одних вариант и меньше размеров других вариант. Иначе говоря, истинное отклонение вариант от истинной средней 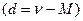 может быть положительной и отрицательной величиной, поэтому сумма (S) всех +d и –d равна нулю. Данное свойство средней используется при проверке правильности расчетов М. Если сумма отклонение вариант от средней равна нулю, то можно сделать вывод, что средняя вычислена правильно. На этом свойстве основан способ моментов для определения М.
может быть положительной и отрицательной величиной, поэтому сумма (S) всех +d и –d равна нулю. Данное свойство средней используется при проверке правильности расчетов М. Если сумма отклонение вариант от средней равна нулю, то можно сделать вывод, что средняя вычислена правильно. На этом свойстве основан способ моментов для определения М.