|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
ОДНА ГОЛОВА ХОРОШО, А ДВЕ ЛУЧШЕ?
Групповые оценки в основном точнее индивидуальных, но это не всегда так. Групповая точность зависит от нескольких факторов, в том числе от природы и сложности задачи, от компетентности членов группы, способа общения и т.п. Рейд Хейсти в 1986 году опубликовал обзор, в котором рассматривались многие факторы, влияющие на групповую оценку, и сравнивались группы и индивидуумы по трем различным типам: (1) оценке количества и величины, например, количества бобов в стакане; (2) оценке в ответе на головоломки, вроде задачки о лошади; (3) оценке в ответах на вопросы из области общего знания, например, абсент — это ликер или минерал? В отношении количественных суждений Хейсти заключил, что группы обычно несколько более точны, чем индивидуумы (для читателей, знакомых со статистикой, Хейсти сообщает, что разница равнялась одной восьмой единицы стандартного отклонения). Более современные исследования Джанет Снайзек и Бекки Хенри (1989, 1990) показали, что в некоторых случаях эта разница может быть больше, чем оценивал ее Хейсти. Используя меру, известную как «стандартизированное отклонение», Снайзек и Хенри обнаружили, что группы из трех человек были на 23—32% точнее, чем индивидуумы, т.е. в 2—3 раза больше, чем установил Хейсти. В том, что касалось головоломок и других вопросов, связанных с логикой, Хейсти обнаружил, что группы обычно превосходили индивидуумов общим развитием, но что самый умный представитель группы в одиночку работал лучше, чем вся группа в целом. Точно так же Хейсти обнаружил, что группы обычно превосходят среднего индивидуума в ответах на вопросы, связанные с общим знанием, но что лучший член группы не уступал или превосходил группу в целом. Подобные результаты рассмотрела Гейл Хилл в 1982 году в своей статье «Group versus Individual Performance: Are N+ 1 Heads Better Than One? », представляющей собой обзор исследований индивидуальных и групповых показателей за 50 лет. Несмотря на то что она уделяла больше внимания поведению, а не оценке и принятию решений, одна из частей ее работы посвящена творчеству и решению проблем. Хилл обнаружила, что группы зачастую превосходили средних индивидуумов, но группы нередко уступали наилучшему индивидууму, находящемуся в статистическом коллективе (невзаимодействующей группе того же размера). В отношении простых вопросов увеличение группы означало всего лишь, что она вероятнее будет включать в себя хотя бы одного человека, способного решить задачу. Для решения сложных вопросов командная работа имеет неоспоримое преимущество: члены группы могут поделиться мнением и исправить ошибки друг друга. Хилл также обратила внимание и на брэйнсторминг (мозговой штурм). В частности, она сравнивала количество идей, выработанных группой, с количеством идей, предложенных той же численностью людей, которые сначала «штурмовали» по- отдельности и позднее сложили свои идеи вместе. Хилл обнаружила, что брэйнсторминг был более успешным, когда идеи вырабатывались независимо, а потом комбинировались, нежели когда они выдвигались при групповом обсуждении. Она сделала вывод, что превосходство группы проявляется из- за того, что больше людей занято решением проблемы, а не из- за самого взаимодействия. В практическом смысле это означает, что лучший способ выработать решение трудной проблемы состоит в следующем: несколько людей независимо работают над этим, а затем делятся своими идеями. ДОСТОИНСТВА ДИКТАТУРЫ Несмотря на то что группа выносит более верные оценки, чем индивидуум, точность зависит и от того, каким образом члены группы комбинируют свои ответы (Дейвис, 1973). Исследование, иллюстрирующее это замечание, было опубликовано Джанет Снайзек в 1989 году. Снайзек сопоставила пять типов методик принятия решений, применяемых группами: (1) «консенсус», когда в лобовом, открытом обсуждении выбирается оценка, принимаемая всеми членами группы; (2) «диалектическая» методика, в которой члены группы обсуждают факторы, которые могут повлиять на их оценку; (3) «диктатура», когда обсуждение заканчивается выбором субъекта, чья оценка и станет оценкой группы; (4) метод Дельфи, когда члены группы не встречаются лицом к лицу, а вместо этого представляют ответы анонимно в серии «раундов», пока не будет достигнут консенсус или принято среднее решение (приятное качество этой методики состоит в том, что члены группы застрахованы от того, что кто- то один может монополизировать дискуссию и незаметно влиять на остальных); (5) «коллективная» методика, предотвращающая все интриги среди членов группы, поскольку просто усредняет индивидуальные оценки для получения оценки коллективной (в исследовании Снайзек коллективная методика устанавливала базовую линию точности, поскольку не зависела от социальных факторов). Каждая группа состояла из пяти студентов, и каждая использовала все пять методик. Группы начинали с использования коллективной методики, после чего использовали прочие в переменном порядке. Задачей студентов было оценить, насколько большую выручку получит принадлежащий колледжу магазин в следующем месяце за одежду, журналы, открытки, сувениры, косметику и лекарства. Снайзек определяла точность оценок относительно реальной выручки в «абсолютном проценте отклонения». Она обнаружила, что каждая из четырех первых методик (консенсус, диалектика, диктатура и дельфийская) достигала более точных результатов, чем простое усреднение (коллективная методика), но наибольшие успехи принесла диктатура, при которой процент ошибки был в среднем в три раза меньше. Интересно, однако, что в каждом случае применения «диктатуры» диктатор группы изменял свое конечное мнение в направлении коллективного среднего, тем самым увеличивая величину ошибки. Другими словами, группы были способны выбирать диктаторов, дававших точные ответы, но диктатор тут же становился демократом и, таким образом, снижал общую точность ответов. Конечно, открытия, сделанные Снайзек, специфичны, относятся только к группам определенного размера (пять человек), определенной категории (студенты) и к определенной задаче (определение доходов магазина). Было бы глупо считать, что метод диктатуры работает лучше во всех ситуациях. Тем не менее эксперимент Снайзек показал, что точность решения, принятого группой, зависит и от того, каким образом оно выработано. Ее результаты продемонстрировали, что в некоторых случаях экспертное решение, принятое группой, оказывается лучше, чем статистическое усреднение оценок, предложенных не совещавшимися людьми. Итак, по крайней мере, в конкретной ситуации результат зависит не только от того, лучше ли две головы, чем одна, но и от того, как эти головы соединены. Заключение Поскольку результаты, продемонстрированные группами, определяются столькими факторами, трудно делать какие- то обобщения (Тиндейл, 1989). По этой же причине трудно объединить отдельные результаты исследований групп. Кроется ли расхождение в разнице тем? В размерах группы? В правилах принятия решений? В самой интерпретации результатов? Это опять- таки результат того, что групповой оценке и решениям не уделялось столько внимания, сколько индивидуальным, несмотря на наличие комитетов, комиссий, судов, штабов и других групп, предназначенных для выработки решений. Более того, граница между исследованиями групп и индивидуумов не проводилась, поскольку группы, видите ли, тоже состоят из индивидуумов. Например, исследование групповой ошибки атрибуции — это, фактически, исследование того, как индивидуумы оценивают группы. Точно так же сдвиги к выбору могут изучаться и путем сравнения групповых решений с индивидуальными, и как сравнение индивидуальных решений до и после групповой дискуссии. Только в первом случае это действительно групповое решение. Однако исследования групповой оценки и принятия решений позволяют сделать следующие заключения: v Многие личностные виды эвристики и смещений проявляются и в групповой оценке. v Групповая дискуссия часто усиливает первоначальные склонности (тенденции). v Группы обычно добиваются лучших результатов, чем индивидуумы, особенно если лидер добивается, чтобы свое мнение высказали все члены группы. v Лучший член группы в одиночку может добиться большего (что может иногда сыграть на пользу «диктатуры»). v Мозговой штурм эффективнее, если члены группы генерируют идеи независимо. Каждое из этих заключений обосновано достаточным числом экспериментов, но поскольку на группы влияет слишком много факторов, их можно воспринимать как общие советы. Несмотря на то что люди часто объединяются для принятия решений, сотрудничество — не всегда гарантия успеха. Раздел VI. Типичные ловушки Этот раздел посвящен трем распространенным проблемам, окружающим принимающего решения человека. Глава 19 посвящена излишней самонадеянности, глава 20 — обсуждению предсказаний, которые сбываются сами собой, а глава 21 рассказывает о специфических затруднениях, известных как «поведенческие ловушки». Каждая глава содержит практические советы и подсказки, как избежать этих проблем. Глава 19. Самоуверенность Авария случается раз в 10 000 лет Виталий Скиларов, министр энергетики Украины, за два месяца до Чернобыльской трагедии
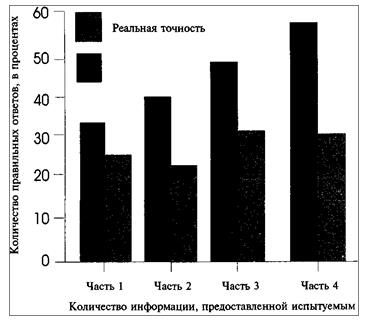
Ни одна из проблем оценки и принятия решений не таит в себе такой угрозы, как излишняя самоуверенность. Как отмечал Ирвинг Джанис в 1982 году в работе, посвященной групповому мышлению, американская самоуверенность позволила японцам уничтожить Pearl Harbor во время второй мировой войны. Самоуверенность сыграла также роль в гибельном решении о запуске космического корабля Челленджер. До того как челнок выполнил свою двадцать пятую миссию, НАСА официально оценило риск как одна катастрофа на 100 000 запусков (Фейнман, 1988, февраль), что означало, что если запускать корабль каждый день в течение 300 лет, то взорвется он всего один раз. Случай Джозефа Кидда Действительно ли НАСА было слишком уверено в успехе или ему просто было необходимо продемонстрировать уверенность? Поскольку реальную уверенность в такой ситуации измерить трудно, наиболее точную оценку должен дать тщательно контролируемый эксперимент. Одним из первых и наиболее известных исследований такого рода стал опыт, результаты которого были опубликованы Стюартом Оскампом в 1965 году. Оскамп попросил 8 клинических психологов, 18 аспирантов- психологов и 6 студентов последних курсов психологических факультетов прочитать исследование случая «Джозефа Кидда», 29- летнего человека, у которого были проблемы (комплексы неполноценности) в подростковом возрасте. Эксперимент был разбит на четыре стадии. Часть 1 представляла Кидда как прошедшего воинскую службу и работающего бизнес- ассистентом в студии садово- паркового дизайна. (270: ) Часть 2 была посвящена детству Кидда (до 12 лет). Часть 3 отражала его школьные и студенческие годы. Часть 4 — армейскую службу и последующую жизнь. Респонденты четыре раза отвечали после прочтения каждой части на один и тот же набор вопросов. Эти вопросы были построены на основе фактического материала исследования, но требовали от респондентов формирования клинической оценки, основанной на общем впечатлении о личности Кидда. В вопросах всегда предлагалось выбрать одну из пяти альтернатив ответа, и после каждого ответа респонденты оценивали свою уверенность в его правильности в границах от 20% (нет особой уверенности) до 100% (абсолютная уверенность). Несколько удивительно, что особой разницы в ответах профессиональных психологов, аспирантов и студентов не было, так что Оскамп подводил итоги по всем трем группам респондентов вместе. Он обнаружил, что уверенность росла вместе с количеством информации, полученной респондентами, но точность — нет. Прочитав первую часть, респонденты ответили верно на 26% вопросов (несколько выше уровня случайного угадывания), а их уверенность составляла 33%. Эти результаты довольно близки. Когда же респонденты получили больше информации, разрыв между точностью и уверенностью вырос (см. рис. 19.1). Несмотря на то что с получением дополнительной информации точность ответов не увеличилась, чем больше респонденты читали, тем увереннее они становились. К тому времени, когда они заканчивали читать четвертую часть, более 90% субъектов Оскампа были более уверены в своих ответах. За годы, прошедшие со времени описания этого эксперимента, в ряде опытов было обнаружено, что люди имеют тенденцию быть слишком уверенными в своих оценках, особенно когда точное решение принять трудно. Например, Сара Лихтенштейн и Барух Фишхофф в 1977 году провели серию экспериментов, в которых наблюдали, что люди были уверены в своей правоте на 65—70%, хотя на самом деле были правы примерно наполовину. В первом опыте Лихтенштейн и Фишхофф просили людей оценить, какие из 12 детских рисунков присланы из Европы, а какие — из Азии, а также оценить вероятность того, что тот или иной ответ верен. Несмотря на то что только 53% ответов были верными (почти случайная вероятность: угадал—не угадал), средняя уверенность достигала 68%. (271: ) Предполагаемая точность
Рисунок 19.1 Стюарт Оскамп (1965) обнаружил, что когда испытуемые получают больше информации, разрыв между предполагаемой точностью их ответов (уверенностью в своей правоте) и реальной точностью растет. В другом эксперименте Лихтенштейн и Фишхофф давали людям отчеты о продажах из 12 магазинов и просили оценить, доходы каких магазинов за определенный период вырастут, каких — упадут. И опять, несмотря на то что точность ответов была только 47% (даже меньше, чем у ответов наугад), уверенность достигала 65%. Проведя еще несколько дополнительных опытов, Лихтенштейн и Фишхофф сделали следующие заключения о связи между точностью и уверенностью в двухальтернативных суждениях: · Самоуверенность является самой высокой, когда точность близка к уровню случайного угадывания. · Самоуверенность уменьшается, когда точность растет от 50 до 80%, а если точность превышает 80%, то люди (272: ) становятся недостаточно уверенными. Другими словами, разница между точностью и уверенностью наименьшая, если точность около 80%, и она возрастает, когда точность отклоняется от этого значения. · Несоответствие между точностью и уверенностью не зависит от умственного развития респондента. Несмотря на то что первые критики этой работы писали, что эти результаты во многом являются порождением вопросов, которые были неясными или бессмысленными, последующие исследования показали, что факты Лихтенштейн и Фишхоффа подтверждаются и при использовании более обыденных, знакомых респондентам тем. Например, в серии экспериментов, включавшей более 10000 отдельных оценок, Ли Росс и его коллеги обнаружили, что люди на 10- 15% переоценивали точность своих ответов, когда их просили предсказать свое поведение и поведение других людей (Даннинг, Гриффин, Милойкович и Росс, 1990; Валлон, Гриффин, Лин и Росс, 1990). Нельзя сказать, что люди всегда излишне самоуверенны. Давид Роунис и Фрэнк Йетс в 1987 году обнаружили, например, что самоуверенность частично зависит от того, как оценивать уверенность и какой тип оценки был сделан (суждения из области общего знания обычно выносятся с относительно высокой уверенностью). Существуют также некоторые основания считать, что игроки в бридж, профессиональные оценщики, работники метеорологической службы — все, кто получает регулярную обратную связь на свои оценки, — не склонны к излишней самоуверенности (Керен, 1987; Лихтенштейн, Фишхофф и Филлипс, 1982; Мерфи и Браун, 1984; Мерфи и Уинклер, 1984). Однако большая часть исследований свидетельствует о том, что переоценка присутствует всегда. |
Последнее изменение этой страницы: 2017-05-05; Просмотров: 305; Нарушение авторского права страницы