
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
О ПРЕДМЕТЕ, ИСТОРИИ, ОСНОВНЫХ ПОНЯТИЯХ И ИДЕЯХ ТЕОРИИ ВЕРОЯТНОСТЕЙ, КАК ОСНОВЕ СТАТИСТИЧЕСКОЙ ДИНАМИКИ СИСТЕМ УПРАВЛЕНИЯ (СУ)Стр 1 из 20Следующая ⇒
О ПРЕДМЕТЕ, ИСТОРИИ, ОСНОВНЫХ ПОНЯТИЯХ И ИДЕЯХ ТЕОРИИ ВЕРОЯТНОСТЕЙ, КАК ОСНОВЕ СТАТИСТИЧЕСКОЙ ДИНАМИКИ СИСТЕМ УПРАВЛЕНИЯ (СУ) Пример 3. Число разделений генеральной совокупности на части. Обобщением формулы (1.2.4) является формула для полиномиального коэффициента. Пусть целые числа
Это равенство получается итеративным использованием равенства (1.2.4):
Простейшие задачи для выборок без возвращений можно решать так. Например, найдём вероятность того, что Пример 3. Выборка с возвращениями. Можно рассмотреть другую схему выборки – с возвращением (объектов). Число таких выборок
с вероятностью по классической схеме
Пример 4. Урновая схема. Рассмотрим следующую «урновую» задачу: пусть в урне n шаров, из них
Если просуммировать по всевозможным величинам чёрных шаров
образует так называемое гипергеометрическое распределение. Пример 5. Размещение шаров по ящикам. Пусть имеется k шаров которые надо разместить по n ящикам. Возможны три варианта размещений: 1) разные, т.е. различимые шары, 2) неразличимые шары, 3) неразличимые шары и ящики. Первый случай был рассмотрен выше, и число вариантов при этом по формуле (1.2.6) было равно Во втором случае неразличимых шаров результат полностью описывается числами заполнений каждого ящика:
В этом случае два размещения различимы только тогда, когда соответствующие наборы разные. В этом случае число различимых размещений (т.е. число решений уравнения (1.2.10)) равно
А число различимых размещений, когда ни один ящик не остаётся пустым
Покажем это, обозначив шары звёздочками, а n ящиков в виде промежутков, разделённых n +1 чертой. Тогда на двух концах стоят 2 черты, а остальные n-1 черта и k звёздочек расположены в произвольном порядке. Таким образом, надо выбрать k мест из n+ k-1 мест, а это и равно В третьем случае неразличимых ящиков вычисления сложнее. Сначала надо взять конкретное распределение количества шаров по ящикам, а затем к данному распределению применить формулу (1.2.6) (к шарам). Далее посчитать число вариантов таких распределений ещё раз, применив формулу (1.2.6) (теперь к ящикам) и умножить эти оба числа. После чего просуммировать полученные произведения по всем возможным вариантам распределений. Так, в случае трёх шаров и трёх ящиков будет: 1) 27, 2) 10, 3) 3 вариантов распределения. С помощью полученных формул (1.2.1) – (1.2.12) можно решать большое число прикладных задач, в том числе, которые будут приведены ниже. В том числе, схема размещения шаров по ящикам появляется в следующих прикладных задачах: распределение несчастных случаев, выборочные обследования, эксперименты с облучением, распределение генов, случайные цифры, химические реакции. Пример 6. Исходы бросаний неразличимых костей. Имеется Пример 7. Число частных производных. Частные производные порядка k от n переменных не зависят от порядка дифференцирования, а зависят только от количества дифференцирований по каждой переменной. Таким образом, каждая переменная играет роль ящика, и в этом случае существует Пример 8. Распределения частиц в квантовой механики. Рассмотрим распределение k частиц в атоме по n энергетическим уровням, которые играют роль ящиков. Пусть имеются n фиксированных целых чисел удовлетворяющих формуле (1.2.10): В случае Бозе-Эйнштейна рассматриваются только различимые размещения, и каждому из них приписывается согласно формуле (1.2.12) вероятность Пример 6. Схема Бернулли. Рассмотрим крайне важную, фундаментальную схему Бернулли. Пусть из генеральной совокупности, состоящей из двух элементов {0, 1} производится выборка с возвращением объёма r – эквивалентно игре в орёл (Герб, Г)-решка (Р). Обозначим это множество выборок
случаев наличия ровно k единиц в выборке. Легко доказать биномиальное равенство В ней вероятность появления 1 на фиксированном месте выборке (например, на месте s) равна p – вероятность успеха. Аналогично вероятность появления 1 на k фиксированных местах равна Важным является случай ограниченного числа бросаний n, что достаточно легко позволяет определить вероятностное пространство с числом элементов Аналогично могут быть найдена вероятность событий «выпало не менее k гербов (или решёток)». Пример 8. Выборочное обследование. Пусть требуется вычислить число курящих в группе из в 100 человек, которое может быть равно от 0 до 100. Это и есть пространство элементарных событий, состоящее из 101 точки x= 0, 1, 2,…, 100. Примером составного события является следующее: «большинство людей в данной выборке – курящие», т.е. одним из событий, x= 51, 52,…, 100. Пример 9. Бросание кубика. Эквивалентно размещению по ящикам – роль ящиков играют грани. Таким образом, при бросании r раз общее число возможных исходов равно Пример 10. Составление слова. Английское слово из 10 букв представляет выборку из генеральной совокупности в 26 букв. Повторения разрешаются, т.е. выборка с возвращением и число вариантов равно Пример 11. Случайно выбранные цифры. Пусть генеральная совокупность состоит из десяти цифр: 0,1,…, 9. Каждая последовательность из 5 цифр является выборкой с возвращениями объёма k=5 и мы считаем, что она согласно классической схеме выборки имеет вероятность Пример 12. Распределение шаров по ящикам. Если n шаров случайно размещаются по n ящикам, то вероятность того, что каждый ящик занят, равна Пример 13. Дни рождения. Дни рождения k человек образует выборку из совокупности всех 365 (как правило) дней в году. Вероятность, что все k дней рождения различны, определяется выборками этих k дней без возвращения по формуле (1.2.7)
Что для k =10 даёт 0.877 (точное значение 0.883). Можно ещё использовать логарифмы для относительно больших k:
Пример 14. Бридж и покер. В колоде для этих игр находится 52 карты по 13 одинаковых карт каждой масти. В бридже имеется 4 игрока, каждому из которых сдаётся по 13 карт. В покере количество игроков разумно не ограничено и каждому игроку сдаётся по 5 карт. Таким образом, у каждого из 4-х игроков при игре в бридж имеется Пример 15. Сенаторы от штатов. Каждый из 50 штатов представлен 2-мя сенаторами. Рассмотрим комитет из 50 сенаторов. Общее число вариантов выбора равно Найдём ещё вероятность того, что представлены все штаты. На каждом из 50 шагов выбора из каждого штата имеется 2 варианта выбора (одного из 2-х сенаторов). Таким образом, общее число вариантов равно Формирующие фильтры Во многих случаях построения систем управления необходимо уметь создавать случайные процессы с заданными статистическими характеристиками. Например, многие задачи и вычисления существенно упрощаются, если в качестве входного сигнала брать белый шум. Тогда возможным способом обобщения используемого метода является построение «формирующего фильтра», т.е. такого преобразования, которое преобразует белый шум в произвольный или требуемый случайный процесс. Формально такое построение осуществляется в рамках корреляционной теории и требует построения из белого шума случайного процесса с заданной корреляционной функцией Рассмотрим более простой, но и содержательный случай стационарного процесса и спектральных плотностей, и будем исходить из формулы преобразования спектральных плотностей при прохождении через линейную стационарную систему (1.5.3)
Рассмотрим белый шум и дробно-рациональную спектральную плотность. Поскольку для спектральной плотности коэффициенты полиномов в числителе и знаменателе будут вещественными, то все комплексные корни распадаются на пары с одинаковыми вещественными частями и мнимыми частями с противоположными знаками (симметричными относительно вещественной оси). Тогда имеет место разложение (факторизация):
Здесь Следовательно
И, окончательно, можно взять
Пример 3.5.1. Сформируем случайный процесс со спектральной плотностью Разложим спектральную плотность на комплексно-сопряженные множители
Тогда для единичного белого шума передаточная функция формирующего фильтра имеет вид
Фильтры Колмогорова-Винера Исторический обзор Фильтр Винера относится к задаче фильтрации, т.е. к наилучшему извлечению информации об изучаемом процессе. Первые работы по фильтрации можно отнести к временам Г. Галилея, А. Лежандра, К. Гаусса. В 1975 г. Гаусс разработал метод наименьших квадратов и применил его к расчёту движения астероида Церера, открытого в 1801 году, а затем скрывшегося в облаках и лучах Солнца. В 1821 г. Гауссом же была разработана рекуррентная версия метода наименьших квадратов, позволившая не производить полного перевычисления при поступлении новых данных. В связи с интенсивным развитием радиолокационной техники впервые Колмогоров в 1939 г. для дискретного случая, а затем и Винер в 1949 г. (в 1941 г. в закрытых материалах) для непрерывных стационарных случайных процессов решили задачу фильтрации – выделение полезного сигнала на фоне шума. Они основывались на преобразовании Фурье. Винер показал эквивалентность задачи решению интегрального уравнения Винера-Хопфа. Винер также придумал оригинальный метод решения интегрального уравнения, который основан на разложении спектральной плотности процесса в произведение двух зеркально симметричных сомножителей (факторизация). Это соответствует построению частотной характеристики системы, порождающей исходный процесс из белого шума с известными статистическими характеристиками на входе – задача формирующего фильтра, Боде, Шеннон, 1950 г. В 1952 г. Р. Бутон обобщил интегральное уравнение Винера-Хопфа на нестационарный случай: процессов и фильтров, но не дал метода его решения, который был дан В.С. Пугачёвым в 1959 г. Несколько позже Р. Бьюси показал, что импульсная переходная характеристика такого фильтра может быть выписана с помощью дифференциальных уравнений и для нестационарных процессов. Аналогичные результаты для дискретного времени получил И. Стратонович в 1958 г. В 1960 г. Р. Л. Стратонович и Р. Калман обобщили винеровскую фильтрацию на нестационарные гауссовские случайные процессы на конечном интервале времени. Работа Калмана нашла широкое применение в инженерной практике, ввиду её изложения на инженерном языке. Дополнения к фильтру Винера Классификация задач фильтрации: - линейная-нелинейная (как динамическая система, так и сам фильтр); - стационарная-нестационарная; - представление фильтра ядром интегрального оператора (импульсной передаточной функцией (ИПФ)), передаточной функцией (частотной), алгоритмом на основе системы обыкновенных дифференциальных уравнений в пространстве состояний. Мы рассматриваем только линейную задачу фильтрации (линейная система, линейный фильтр). Фильтр Колмогорова-Винера даёт решение в случае стационарных эргодических процессов в виде частотной передаточной функции или ИПФ. Фильтр Калмана-Бьюси – в виде алгоритма на основе системы обыкновенных дифференциальных уравнений в пространстве состояний. Фильтр Винера был обобщён в следующих направлениях: векторный случай (спектральные матрицы), метод неопределённых коэффициентов для нестационарного случая. Существуют решения, в том числе для нелинейных систем и нелинейных фильтров в виде уравнений Вольтерра, функциональных рядов, спектральных матриц.
Критерии оптимальности. И для фильтра Винера и для фильтра Калмана мы используем критерий среднеквадратичной ошибки, который приводит к результатам, аналогичным случаю детерминированных систем. Также аналогично, можно рассмотреть вместо задачи оптимальной оценки случайного сигнала (процесса), задачу оптимального управления (я ранее выражал скепсис по этому поводу, но был неправ – в классических книгах существует такая постановка, и мы её далее рассмотрим). В фильтре Винера вся информации должна быть задана априорна. В случае фильтра Калмана – её можно получать по мере поступления. Это большой плюс. В задачах фильтрации (оценки параметров или выбора гипотез также, это уже нелинейная фильтрация) можно использовать также формулу Байеса и отвечающей ей критерий максимального правдоподобия. Общепринятая достаточно универсальная идеология фильтрации использует байесовский принцип. Ее применение позволяет, по крайней мере, теоретически, создавать как линейные, так и нелинейные алгоритмы фильтрации. Кроме того, этот принцип помогает выяснить, при каких условиях линейные процедуры фильтрации приводят к наивысшему качеству обработки и, следовательно, являются абсолютно оптимальными. Отметим, однако, с самого начала основные недостатки байесовской фильтрации. Первый является общим для байесовских методов вообще и заключается в очень высоких требованиях к объему и характеру данных, содержащихся в математических моделях сигналов и помех, удовлетворить которым на практике удается далеко не всегда. Полагаем, что на входе фильтра действует сигнал где куда входит распределение Задачей байесовского фильтра является вычисление распределения вероятностей Несмотря на сложность байесовских процедур для фильтрации даже одномерных сигналов, были получены блестящие решения проблемы, основанные на использовании Марковских моделей сигналов и помех.
О преобразовании Лапласа и Фурье в фильтре Винера. Фильтр Винера основан на преобразованиях Лапласа и Фурье. Прежде всего, напомним не очень строго определение преобразования Лапласа F ( p ) для функции f ( t ):
Область определения преобразования Лапласа ограничивается функциями: - - В технических приложениях первому условию равенства 0 сигнала при отрицательном времени соответствует тому, что вся информация о прошлом содержится в начальных условиях при t = 0. Второе условие требует принадлежности сигнала классу суммируемых функций. Оно будет заведомо выполняться, если
Такое минимальное Теорема 1 (об аналитичности преобразования Лапласа). Если Re p > Обратное преобразование Лапласа:
Оно даёт первоначальную функцию (которая здесь называется оригиналом), если В каких случаях оно существует и как его находить? Этот вопрос имеет важнейшее значение для фильтра Винера. Теорема 2 (о существовании обратного преобразования Лапласа для аналитических функций). Для аналитической при Re p > В том числе, если мы сделали преобразование Лапласа для соответствующей функции, то получили аналитическую функцию для Re p > Теорема 3 (разложения). Если F( p) аналитическая в
то
Теорема 4 (разложения). Если F( p) мероморфная (имеем особенности только в виде полюсов, в конечном количестве в ограниченной области), аналитическая в
то
Теорема 5 (разложения). При ограниченном числе полюсов – получается правильная дробно-рациональная функция
Для простых полюсов:
Устойчивая система. Для устойчивости системы с импульсной передаточной функцией (ИПФ) K ( t ) необходимо и достаточно:
В этом случае, для ограниченного входного сигнала будет т.е. будет существовать выходной сигнал:
Сделав преобразование Фурье над (ИПФ) K ( t ) получаем необходимое и достаточное условие в виде отрицательности вещественной части нулей частотной передаточной функции
Сделаем заключительное замечание, относящееся к строгой применимости полученной формулы: линейный фильтр является оптимальным для нормальных случайных процессов, иначе – решение принадлежит к классу нелинейных систем.
Теперь применяя эту лемму о факторизации к многочленам в числителе и знаменателе спектральной плотности
При этом если дисперсия
Согласно формуле (1.5.3) для установившейся реакции выходного сигнала
И дисперсия выходного процесса равна
В случае отсутствия кратных корней дисперсия равна сумме вычетов:
Заметим, что Таким образом, на полуокружности бесконечно большого радиуса, охватывающей левую полуплоскость, подынтегральное выражение убывает не медленней, чем
где во втором интеграле интегрирование ведётся по контуру, охватывающему левую полуплоскость. Значение такого интеграла равно сумме вычетов подынтегрального выражения во всех полюсах, лежащих внутри этого контура, что и приводит к равенству (**). Пример 3.3. ППП Далее надо ещё: 1) проекция в гильбертовом пространстве (синяя книга Леоденса), 2) векторное уравнение Винера-Хопфа и фильтр Винера (синяя книга Леоденса), 3) метод неопределённых коэффициентов (синяя книга Леоденса), 4) книги Первозванского, Леоденса, Венгерова, … ОСНОВНЫЕ ПОНЯТИЯ, РЕЗУЛЬТАТЫ И ПРИМЕРЫ К ЭКЗАМЕНУ 6.1. Основные примеры
Пример 1. (Пример 1.1 из Егупова) Типовые корреляционные функции и их плотности.
Пример 2. Белый шум. Белым шумом называется стационарный СП с постоянной спектральной плотностью:
Тогда
Тогда в установившемся режиме
Для нестационарного белого шума вида
получаем нестационарную дисперсию:
Пример 3. (Пример 1.2 из Егупова) Преобразование сигнала линейной системой. Пусть имеется стационарный сигнал с Характеристическое уравнение и корень:
Найдём дисперсию в неустановившемся режиме:
Раскроем модуль и вычислим внутренний интеграл:
Тогда внутренний интеграл распадается на два
Подставим это выражение во внешний интеграл:
В установившемся режиме, т.е. при
Пример 4. Преобразования простейшей линейной системой простейшего сигнала с помощью передаточной функции и спектральной плотности. Пусть:
Сначала найдём спектральную плотность входного сигнала:
Теперь найдём дисперсию выходного сигнала:
Пример 5. Формирующий фильтр. Сформируем случайный процесс со спектральной плотностью Разложим спектральную плотность на комплексно-сопряженные множители
Тогда для единичного белого шума передаточная функция формирующего фильтра имеет вид
Пример 6. (Пример 1.7 из Егупова) Определение ошибки. Пусть имеется полезный сигнал m( t) и помеха n( t) со спектральными плотностями
Задачи из Егупова: Пример 3.1, Пример 3.3, Пример 3.4, Пример 3.5, Пример 3.6, Пример 3.7. Пример 7. (Пример 3.7 из Егупова). Фильтр Калмана при цветном шуме. Ф
Основные понятия и результаты Теория вероятности. Функция распределения, плотность распределения, случайная величина, математическое ожидание, дисперсия, центральные и начальные моменты, формула для вычисления дисперсии (1.7, Егупов). Нормальный (гауссовский) закон распределения, формула плотности распределения и его основные свойства. Нелинейные системы. Особенность прохождения через нелинейный элемент (рисунки 2.1 – 2.3 из Егупова). Метод статистической линеаризации: рассматриваемые схемы (рисунок 2.8), суть метода – замена коэффициентами, критерии статистической эквивалентности. Формулы для 1-го критерия: (2.30) – (2.36). Формулы для 2-го критерия: (2.41), (2.43), (2.44). Как они получаются. Формулы (2.47) – (2.49) для случая нормальных процессов. Как можно получить коэффициенты статистической линеаризации в этом случае. В чём заключается метод Монте-Карло (статистических испытаний).
Фильтр Винера. В чём состоит задача фильтрации. Параметрическая оптимизация: формулы (3.1) – (3.2), формулы (3.3) – (3.5) для ошибки и её оптимизации. Форма оптимального фильтра Винера в виде импульсной переходной функции (ИПФ). Среднеквадратичный критерий оптимальности (3.12). Уравнение Винера-Хопфа (3.24), как выводится. Постановка задачи Винера-Колмогорова и уравнение Винера-Хопфа для стационарного случая. Идеальное, физически нереализуемое решение: (3.28) + две формулы ниже. Способ получить физически реализуемое решение – формула (3.29). Свойства функций Проекционный метод решения векторного (матрично-векторного) уравнения Винера-Хопфа. Частотные уравнения (3.45), (3.46), (3.50) и как они выводятся. Решения задачи в виде формулы (3.51) и формулы над ней.
Фильтр Калмана. Постановка задачи и структура оптимального фильтра (3.4.1.3, лекции). Уравнение Винера-Хопфа (3.4.1.6) – исходная точка. Шаги вывода алгоритма Калмана (стр. 97-98, лекции). Представление фильтра уравнением в пространстве состояний (3.4.2.1) и условия (3.4.2.2) – (3.4.2.5) (лекции). Уравнение оптимального фильтра (3.4.2.21) и общая схема его получения (с чего начинаем) и примерно что далее делаем. Формула (3.4.3.8) оптимальной матричной функции коэффициентов фильтра и как она получается (с чего начинается вывод и последовательность действий). Дисперсионное уравнение (3.4.4.8) и вся Теорема 1. Как выводится (с чего начинается вывод и последовательность действий). Краткий алгоритм построения фильтра на стр. 112. Теорема 3.2 из Егупова (формулы (3.128) – (3.131), из Егупова). Обобщённый фильтр: формулировка и как выводится, отличие от стандартного фильтра Калмана (п. 3.3.6 из Егупова). Случай цветного шума: формулировка и как выводится, отличие от стандартного фильтра Калмана (п. 3.3.7 из Егупова). Оптимальный наблюдатель в системах управления: формулировка и как выводится, отличие от стандартного фильтра Калмана (п. 3.3.8 из Егупова).
Кое-что про фильтр Калмана Целью работы является изучение методов фильтрации Калмана-Бьюси случайных векторных процессов. Рассматривается ситуация, когда коэффициенты фильтра не зависят от времени. Пусть Пусть Оценка где Имеют место следующие утверждения: Теорема 1. Пусть Теорема 2. Пусть а ее ошибка Пусть Справедлива следующая теорема: Теорема (о нормальной корреляции). Для гауссовского вектора задаются следующими формулами: где Пусть При этом последовательность Согласно теореме 1, Задача фильтрации состоит в отыскании этих величин для произвольных последовательностей с параметрами Теорема Калмана-Бьюси. Пусть Рассмотрим примеры на применение фильтра Калмана-Бьюси. Пример 1. Рассматриваются две стационарные некоррелированные случайные последовательности где Последовательность Пример 2. Рассмотрена проблема определения отказа работы реактивных двигателей стабилизации системы управления космического аппарата. Данная проблема приводит к невыполнению целевой задачи и отказу типа "неотключение" двигателя, что является причиной больших потерь рабочего тела и раскрутки космического аппарата до недопустимых угловых скоростей. Построен алгоритм идентификации отказов двигателей стабилизации в дискретном времени с помощью фильтра Калмана-Бьюси, имеющий вид: где Работа алгоритма основана на анализе величины оцениваемого в фильтре Калмана-Бьюси возмущающего момента. Если математическое ожидание оценки возмущающего момента, вычисленного на некоторой временной базе, где управление равно нулю, превосходит допустимый порог, то принимается решение об отказе двигателей стабилизации. ЛИТЕРАТУРА 1. Методы классической и современной теории автоматического управления // Т.2, «Статистическая динамика и идентификация систем автоматического управления» // Под ред. К.А. Пупкова, Н.Д. Егупова. – М:, Изд-во МГТУ им. Н.Э. Баумана. 2004. 638 с.Крамер 2. Колмогоров А.Н. Основные понятия теории вероятностей. – М.:, Главная ред. физ.-мат. литературы изд-ва «Наука», 1974, 120 стр. 3. Г. Секей. Парадоксы теории вероятности и математической статистики. 4. Феллер. Теория вероятностей, т.1. 5. Колмогоров А.Н. Интегрирование и экстраполирование стационарных случайных последовательностей // Изв. АН СССР, сер. мат. т.5, № 1, 1941. 6. Wiener N. Extrapolation, interpolation and smoothing of stationary time series. // New York: John Wiley. 1949. № 7. 7. Kalman R.E., Busy R.S. New results in linear filtering and prediction theory.// J. Basis Engineering. (ASME Transactions) v.83, D, 1961. № 1. pp. 95- 108. 8. Аоки М. Оптимизация стохастических систем. М.: Наука, 1971. 9. Брайсон А.Е., Хо-Ю-Ши. Прикладная теория оптимального управления. -М.: Мир, 1972.-544 с. 10. Дейч A.M., Методы идентификации динамических объектов. М.: «Энергия», 1979. 240 с. 11. Медич Дж. Статистически оптимальные оценки и управление. . М.: Энергия, 1973.-440 с. 12. Райбман Н.С., Что такое идентификация. М.: Наука, 1970. 13. Сейдж Э., Мелса Дж. Идентификация систем управления М.: Наука, 1974.-340 с. 14. Цыпкин Я.З. Основа информационной теории идентификации М.: «Наука», 1984. -320 с. 15. Эйкхофф П. Основы идентификации систем управления М.: Мир, 1975.-685 с
О ПРЕДМЕТЕ, ИСТОРИИ, ОСНОВНЫХ ПОНЯТИЯХ И ИДЕЯХ ТЕОРИИ ВЕРОЯТНОСТЕЙ, КАК ОСНОВЕ СТАТИСТИЧЕСКОЙ ДИНАМИКИ СИСТЕМ УПРАВЛЕНИЯ (СУ) |
Последнее изменение этой страницы: 2019-03-22; Просмотров: 238; Нарушение авторского права страницы
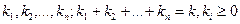 – тогда число способов разбиения генеральной совокупности из k элементов на n упорядоченных множества, содержащих
– тогда число способов разбиения генеральной совокупности из k элементов на n упорядоченных множества, содержащих  элементов каждая, равно
элементов каждая, равно (1.2.5)
(1.2.5)
 . Поскольку оставшиеся k–2 места могут быть заняты любыми из n–2 элементов генеральной совокупности, то число таких выборок равно
. Поскольку оставшиеся k–2 места могут быть заняты любыми из n–2 элементов генеральной совокупности, то число таких выборок равно  . Таким образом, искомая вероятность равна
. Таким образом, искомая вероятность равна  .
. (1.2.6)
(1.2.6) . Найдём для такой схемы вероятность того, что все элементы будут разными. Выборок с различными элементами будет столько же, сколько в выборках без возвращений:
. Найдём для такой схемы вероятность того, что все элементы будут разными. Выборок с различными элементами будет столько же, сколько в выборках без возвращений:  . Поэтому искомая вероятность равна
. Поэтому искомая вероятность равна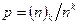 . (1.2.7)
. (1.2.7) чёрных и
чёрных и  белых. Какова вероятность, что в выборке будет ровно
белых. Какова вероятность, что в выборке будет ровно  чёрных шаров при общем числе выбранных k шаров? Выше показано, что различающихся составом выборок
чёрных шаров при общем числе выбранных k шаров? Выше показано, что различающихся составом выборок  . Чёрных
. Чёрных  шаров из
шаров из  способами, аналогично остальные
способами, аналогично остальные  белых шаров из всех
белых шаров из всех 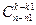 способами. Очевидно, что любой набор чёрных шаров может сочетаться с любым набором белых шаров, поэтому число всех выборок объёма k различающихся составом и содержащих ровно
способами. Очевидно, что любой набор чёрных шаров может сочетаться с любым набором белых шаров, поэтому число всех выборок объёма k различающихся составом и содержащих ровно 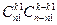 . (1.2.8)
. (1.2.8) . Искомая вероятность же равна
. Искомая вероятность же равна 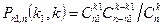 . Заметим, что набор чисел
. Заметим, что набор чисел (1.2.9)
(1.2.9) , (1.2.10)
, (1.2.10)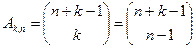 . (1.2.11)
. (1.2.11) . (1.2.12)
. (1.2.12) . Условие, что нет пустых ящиков означает, что нет рядом стоящих черт. Таким образом, между k звёздочками должно быть k-1 промежутков, заполненных чертами, т.е. имеем
. Условие, что нет пустых ящиков означает, что нет рядом стоящих черт. Таким образом, между k звёздочками должно быть k-1 промежутков, заполненных чертами, т.е. имеем  вариантов.
вариантов. различимых исходов бросания k неразличимых игральных костей.
различимых исходов бросания k неразличимых игральных костей. различных частных производных порядка k. Например, функция трёх переменных имеет 15 производных четвёртого порядка и 21 производную пятого порядка.
различных частных производных порядка k. Например, функция трёх переменных имеет 15 производных четвёртого порядка и 21 производную пятого порядка. . Число возможных размещений k шаров по n ящикам, при которых в каждом ящике содержится соответственно
. Число возможных размещений k шаров по n ящикам, при которых в каждом ящике содержится соответственно  шаров, согласно формуле (1.2.5) равно
шаров, согласно формуле (1.2.5) равно 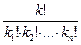 , а вероятность такого заполнения для
, а вероятность такого заполнения для  равновероятных размещений
равновероятных размещений  . Такое размещение, используемое в статистической физике, где вместо уровней энергии используются малые области, ячейки, фазового пространства, и названное распределением (или статистикой) Максвелла-Больцмана считалось интуитивно очевидным. Однако в квантовой механике распределение Максвелла-Больцмана неприменимо ни к каким частицам, а имеют место два других: Бозе-Эйнштейна и Ферми-Дирака. Здравый смысл говорит в пользу первой схемы (различимых шаров и ящиков), однако эксперименты показали, что возможны только случаи Бозе-Эйнштейна (фотоны, атомные ядра, атомы с чётным числом элементарных частиц), Ферми-Дирака (электроны, нейтроны, протоны).
. Такое размещение, используемое в статистической физике, где вместо уровней энергии используются малые области, ячейки, фазового пространства, и названное распределением (или статистикой) Максвелла-Больцмана считалось интуитивно очевидным. Однако в квантовой механике распределение Максвелла-Больцмана неприменимо ни к каким частицам, а имеют место два других: Бозе-Эйнштейна и Ферми-Дирака. Здравый смысл говорит в пользу первой схемы (различимых шаров и ящиков), однако эксперименты показали, что возможны только случаи Бозе-Эйнштейна (фотоны, атомные ядра, атомы с чётным числом элементарных частиц), Ферми-Дирака (электроны, нейтроны, протоны). . Статистика Ферми-Дирака основана на следующих предположениях: 1) в одной ячейке может находиться не более одной частицы, 2) все различимые размещения, удовлетворяющие п. 1) имеют одинаковую вероятность. Для первого условия необходимо
. Статистика Ферми-Дирака основана на следующих предположениях: 1) в одной ячейке может находиться не более одной частицы, 2) все различимые размещения, удовлетворяющие п. 1) имеют одинаковую вероятность. Для первого условия необходимо  , и размещение полностью описывается указанием какие ячейки содержат частицу, что можно сделать
, и размещение полностью описывается указанием какие ячейки содержат частицу, что можно сделать  . Выбор статистики для конкретной частицы определяется только на основе эксперимента, а не с помощью априорных рассуждений.
. Выбор статистики для конкретной частицы определяется только на основе эксперимента, а не с помощью априорных рассуждений. . Определим функцию вероятности на этом множестве (вероятностном пространстве) для случая ровно k гербов
. Определим функцию вероятности на этом множестве (вероятностном пространстве) для случая ровно k гербов  , тогда существует
, тогда существует (1.2.14)
(1.2.14)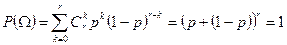 – т.е. P – вероятность. Соответствующее распределение называется биномиальным, схема – схемой Бернулли, и испытания обладают свойством независимости.
– т.е. P – вероятность. Соответствующее распределение называется биномиальным, схема – схемой Бернулли, и испытания обладают свойством независимости. .
. и элементарными событиями являются последовательности из {Р,Г}, эквивалентно, из {0,1} длиной n:
и элементарными событиями являются последовательности из {Р,Г}, эквивалентно, из {0,1} длиной n:  . Тогда составное событие, что выпало не менее 2-х гербов, состоит из всех тех последовательностей (элементарных событий), в которых 0 (Р) встречается не более 2-х раз. Нетрудно их подсчитать: 0 встречается 0 раз только в последовательности из всех единиц {1, 1, …, 1} – 1 вариант; 1 раз в n последовательностях только на месте n, т.е. – n вариантов; 2 раза в
. Тогда составное событие, что выпало не менее 2-х гербов, состоит из всех тех последовательностей (элементарных событий), в которых 0 (Р) встречается не более 2-х раз. Нетрудно их подсчитать: 0 встречается 0 раз только в последовательности из всех единиц {1, 1, …, 1} – 1 вариант; 1 раз в n последовательностях только на месте n, т.е. – n вариантов; 2 раза в 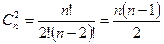 последовательностях, образуемых выбором 2-х элементов из n элементов –
последовательностях, образуемых выбором 2-х элементов из n элементов –  вариантов. Итоговое число искомых последовательностей образуется суммой всех трёх возможностей:
вариантов. Итоговое число искомых последовательностей образуется суммой всех трёх возможностей:  , а вероятность равна
, а вероятность равна  .
. , а число исходов без выпадения 1 ни разу равно
, а число исходов без выпадения 1 ни разу равно 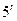 . Следовательно, вероятность такого события равна
. Следовательно, вероятность такого события равна  . Вероятность же появления 1 равна
. Вероятность же появления 1 равна  – не очень велика.
– не очень велика. . Если для каждого слова в типографии имеются 1000 литер, и надо физически выбрать из литер 10 штук без повторений, то слово может быть набрано
. Если для каждого слова в типографии имеются 1000 литер, и надо физически выбрать из литер 10 штук без повторений, то слово может быть набрано  различными способами – что намного больше.
различными способами – что намного больше. . Вероятность того, что все пять последовательных случайных цифр различны будет согласно формуле (1.2.3) равна
. Вероятность того, что все пять последовательных случайных цифр различны будет согласно формуле (1.2.3) равна  .
. – это поразительно мало, например для n=7,
– это поразительно мало, например для n=7,  . Например, если в некотором городе происходит 7 аварий в неделю (7 дней), то почти наверняка будет день, когда аварий не будет (и следовательно будут дни с 2-мя или более авариями).
. Например, если в некотором городе происходит 7 аварий в неделю (7 дней), то почти наверняка будет день, когда аварий не будет (и следовательно будут дни с 2-мя или более авариями). .
.
 различных комбинаций и
различных комбинаций и  комбинаций у игрока в покер. В покере значения карт могут быть выбраны
комбинаций у игрока в покер. В покере значения карт могут быть выбраны 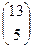 способами, и для каждого значения существует 4 масти. Таким образом, в покере вероятность одному игроку иметь все разные по значению карты равна
способами, и для каждого значения существует 4 масти. Таким образом, в покере вероятность одному игроку иметь все разные по значению карты равна  , а в бридже –
, а в бридже –  .
. . Вероятность того, что будет представлен каждый штат, будет дополнительной к вероятности противоположного события – т.е. данный штат не представлен, т.е. надо выбрать разными способами 50 сенаторов из 98 сенаторов не из данного штата:
. Вероятность того, что будет представлен каждый штат, будет дополнительной к вероятности противоположного события – т.е. данный штат не представлен, т.е. надо выбрать разными способами 50 сенаторов из 98 сенаторов не из данного штата:  . Следовательно, вероятность того, что данный штат не представлен равна
. Следовательно, вероятность того, что данный штат не представлен равна  .
. , и искомая вероятность равна
, и искомая вероятность равна 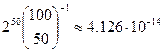 (используя формулу Стирлинга).
(используя формулу Стирлинга). или c заданной спектральной плотностью
или c заданной спектральной плотностью  .
. .
. . (1.6.1)
. (1.6.1) имеет все нули и полюсы в верхней полуплоскости, а
имеет все нули и полюсы в верхней полуплоскости, а  – в нижней. При этом выбор в качестве аргумента
– в нижней. При этом выбор в качестве аргумента  в формуле (1.6.1) приводит к соотношению
в формуле (1.6.1) приводит к соотношению  .
.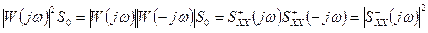 . (1.6.2)
. (1.6.2) . (1.6.3)
. (1.6.3) (и корреляционной функцией
(и корреляционной функцией  ).
). .
. .
.
 , (*)
, (*) и
и  - полезный сигнал и помеха, а
- полезный сигнал и помеха, а  - функция, описывающая их взаимодействие. При байесовском методе считается, что сигнал и помеха - случайные процессы (случайные двумерные поля) с известными законами распределения вероятностей. Пусть
- функция, описывающая их взаимодействие. При байесовском методе считается, что сигнал и помеха - случайные процессы (случайные двумерные поля) с известными законами распределения вероятностей. Пусть  - вектор, элементы которого - все
- вектор, элементы которого - все  отсчетов, образующих кадр изображения, а
отсчетов, образующих кадр изображения, а  -их совместное распределение. Примем для простоты, что помеха и сигнал независимы, а распределение вектора помехи
-их совместное распределение. Примем для простоты, что помеха и сигнал независимы, а распределение вектора помехи  равно
равно 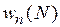 . Воспользовавшись формулой Байеса, запишем апостериорное распределение вероятностей (АРВ)
. Воспользовавшись формулой Байеса, запишем апостериорное распределение вероятностей (АРВ)  :
: , (**)
, (**) наблюдаемых данных и условное распределение
наблюдаемых данных и условное распределение 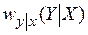 - называемое функцией правдоподобия. Смысл выражения (**) заключается в том, что оно дает возможность вычислить в устройстве обработки распределение вероятностей полезного сигнала, располагая входными данными
- называемое функцией правдоподобия. Смысл выражения (**) заключается в том, что оно дает возможность вычислить в устройстве обработки распределение вероятностей полезного сигнала, располагая входными данными  и опираясь на вероятностную модель как самого полезного сигнала, так и наблюдаемых данных. АРВ является аккумулятором всех доступных сведений о полезном сигнале, которые содержатся в
и опираясь на вероятностную модель как самого полезного сигнала, так и наблюдаемых данных. АРВ является аккумулятором всех доступных сведений о полезном сигнале, которые содержатся в  . (1)
. (1) ;
; .
. .
. называется показателем степени роста.
называется показателем степени роста. . (2)
. (2) .
. , т.е. имеет разложение (
, т.е. имеет разложение (  – функция Хевисайда)
– функция Хевисайда) ,
,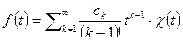 .
. , для каждого a
, для каждого a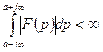 .
. .
. . И её можно разложить на простейшие дроби (с учётом кратности корней) и по таблице найти обратное преобразование Лапласа:
. И её можно разложить на простейшие дроби (с учётом кратности корней) и по таблице найти обратное преобразование Лапласа: .
. .
. .
. .
. .
. , получаем факторизацию спектральной плотности
, получаем факторизацию спектральной плотности .
. , то
, то  – устойчивый многочлен, а
– устойчивый многочлен, а  – кроме корней в левой полуплоскости может иметь только корни на мнимой оси. А именно, из ограниченности дисперсии, следует отсутствие полюсов
– кроме корней в левой полуплоскости может иметь только корни на мнимой оси. А именно, из ограниченности дисперсии, следует отсутствие полюсов 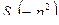 (т.е. корней
(т.е. корней  знаменателя) на мнимой оси.
знаменателя) на мнимой оси.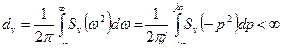 . (*)
. (*) .
. .
. . (**)
. (**) из-за устойчивости системы, а
из-за устойчивости системы, а  из-за ограниченности интеграла (*) для дисперсии.
из-за ограниченности интеграла (*) для дисперсии.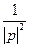 , а, следовательно,
, а, следовательно, ,
,

 .
.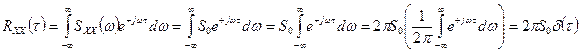 .
. .
. .
.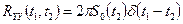 ,
, .
. , поступающий при t=0 на вход системы с передаточной функцией
, поступающий при t=0 на вход системы с передаточной функцией  . Найдём дисперсию.
. Найдём дисперсию.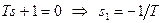 . Тогда
. Тогда  . Согласно определению корреляционной функции (в установившемся режиме):
. Согласно определению корреляционной функции (в установившемся режиме):

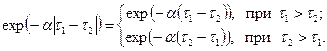
 :
:
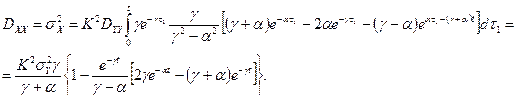
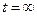 имеем:
имеем: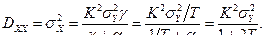
 ,
,  .
.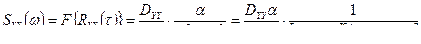 .
. .
. (и корреляционной функцией
(и корреляционной функцией 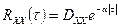 ).
). .
. .
. (и корреляционной функцией
(и корреляционной функцией  . Как решается уравнение (3.29) в частотной области. Факторизация, расщепление. Получение фильтра, т.е. последовательность всех формул (3.30) – (3.37).
. Как решается уравнение (3.29) в частотной области. Факторизация, расщепление. Получение фильтра, т.е. последовательность всех формул (3.30) – (3.37).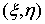 - пара случайных величин, из которых
- пара случайных величин, из которых  - наблюдаема, а
- наблюдаема, а  наблюдению не подлежит. Возникает вопрос: как по значениям наблюдений над
наблюдению не подлежит. Возникает вопрос: как по значениям наблюдений над  - борелевская функция. Случайная величина
- борелевская функция. Случайная величина 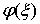 называется оценкой
называется оценкой  - среднеквадратической ошибкой этой оценки.
- среднеквадратической ошибкой этой оценки. называется оптимальной (в среднеквадратическом смысле), если
называется оптимальной (в среднеквадратическом смысле), если
 берется по классу всех борелевских функций
берется по классу всех борелевских функций 
 Тогда оптимальная оценка
Тогда оптимальная оценка  существует, и в качестве нее может быть взята функция
существует, и в качестве нее может быть взята функция
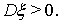 Тогда оптимальная оценка
Тогда оптимальная оценка 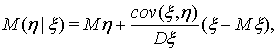

 - гауссовский вектор, где
- гауссовский вектор, где 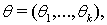

 оптимальная оценка
оптимальная оценка  вектора
вектора  по
по 


 - векторы-столбцы средних значений
- векторы-столбцы средних значений - матрицы ковариаций, и предполагается, что существует матрица
- матрицы ковариаций, и предполагается, что существует матрица 
 - частично наблюдаемая последовательность случайных векторов, таких что
- частично наблюдаемая последовательность случайных векторов, таких что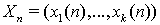

 управляется рекуррентными соотношениями
управляется рекуррентными соотношениями
 является оптимальной в среднеквадратическом смысле оценкой вектора
является оптимальной в среднеквадратическом смысле оценкой вектора  а
а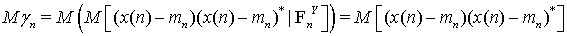 есть матрица ошибок оценивания.
есть матрица ошибок оценивания. управляемых уравнениями (1). Предположим, что условное распределение
управляемых уравнениями (1). Предположим, что условное распределение  является гауссовским,
является гауссовским,

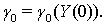 Тогда справедлива следующая теорема:
Тогда справедлива следующая теорема: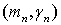 подчиняются следующим реккурентным уравнениям:
подчиняются следующим реккурентным уравнениям:

 и
и 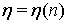 со средними значениями
со средними значениями  и спектральными плотностями
и спектральными плотностями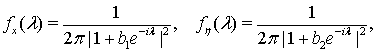

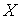 рассматривается как полезный сигнал, для которого находится оптимальная линейная оценка
рассматривается как полезный сигнал, для которого находится оптимальная линейная оценка  и среднеквадратическая ошибка
и среднеквадратическая ошибка 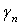 . Последовательность
. Последовательность  такая что
такая что 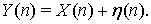




 - оценка вектора состояния,
- оценка вектора состояния,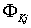 - переходная матрица для вектора состояния,
- переходная матрица для вектора состояния, - матрица измерений,
- матрица измерений,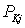 - ковариационная матрица ошибок фильтрации,
- ковариационная матрица ошибок фильтрации, - ковариационная матрица ошибок прогноза,
- ковариационная матрица ошибок прогноза, - матричный коэффициент усиления,
- матричный коэффициент усиления, - ковариационная матрица шумов измерения,
- ковариационная матрица шумов измерения,