
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Методы выявления мешающих параметров
В практике обработки результатов измерений очень часто возникает ситуация, когда имеется не безосновательное подозрение, что они могут не совсем в нужной мере удовлетворять таким основополагающим требованиям, как достаточная степень случайности, однородности и независимости. При этом под степенью случайности будем понимать степень присутствия в ряде измерений закономерной составляющей. Чаще всего эта закономерная составляющая сводится к линейному виду, который принято называть трендом (постоянно действующим влечением). Степень однородности, для практики, целесообразно сводить к наличию грубых измерений, значимому изменению от значения к значению в ряде оценки сдвига (математического ожидания) и масштаба (меры рассеивания). Степень независимости в ряде принято характеризовать величиной автокорреляции, которая показывает тесноту связи между измерениями и которая должна быть непременно учтена, если имеет величину больше допустимой. Так как часто о законе распределения ряда измерений достоверно мало известно, используют подход как на основе параметрических алгоритмов анализа (о законе распределения достаточно известно и он достаточно нормален), так и на основе непараметрических (о законе распределения достоверно практически ничего не известно). Сравнивая результаты исследований по этим двум направлениям можно получить намного более достоверные выводы. В геодезии традиционно принято из перечисленных выше групп основных характеристик выделять только грубые (из однородности) и систематические погрешности (из случайности, тренда), которые иногда называют мешающие параметры. В последнее время положение начинает изменяться в сторону рассмотрения всего комплекса характеристик, что позволяет более полно учитывать их влияния и повысить эффективность и точность (иногда значительно) обработки результатов измерений.
2.1. Исследование ряда измерений на степень случайности (тренд)
Очевидно, что исследование на случайность – первый шаг при обработке, так как отсутствие случайности измерений в должной мере не позволяет эффективно использовать для получения оценок аппарат математической статистики. В подавляющем большинстве случаев практики мера случайности сводится к определению меры закономерности в ряде измерений. Тогда, если эта мера не велика, ряд можно считать достаточно случайным и проводить дальнейшие исследования или оценивание на основе математической статистики. В геодезии и других науках о Земле, если не оговаривается отдельно, в подавляющем большинстве случаев пытаются выявить в ряде измерений значимость линейной закономерности (постоянного линейного влечения, или тренда). Вспомним, что в геодезии выявление закономерной составляющей носит название исследование на значимость систематического влияния в результатах измерений. Мы рассмотрим два наиболее мощных алгоритма выявления линейного тренда (и таким образом степени случайности ряда измерений) на основе параметрического и непараметрического подходов. Из параметрических алгоритмов взят метод на основе анализа коэффициентов линейной регрессии (статистически лучшей линейной модели данных). Из непараметрических – метод на основе инверсий. Параметрический алгоритм на основе анализа коэффициентов линейной регрессии предполагает, что результаты измерений достаточно хорошо подчиняются нормальному закону распределения. Это предположение позволяет использовать аппарат статистической проверки гипотез в его традиционном, классическом виде для выявления значимости линейного тренда и таким образом, значимости не случайной составляющей в исследуемом ряде измерений. Для реализации алгоритма предполагаем, что результаты измерений, обязательно представленные по порядку их получения, линейно зависят от времени, или от номера в ряде. Рассмотрим случай зависимости от номера в ряде. Тогда, чтобы выявить общую тенденцию увеличения (уменьшения) значений результатов измерений Xi в зависимости от номера i (т. е. дрейф результатов, или тренд), нужно провести аппроксимацию (приближение, моделирование) ряда измерений функцией вида
Xi = a × i + b. (23)
Здесь i – номер измерения по порядку (переставлять результаты измерения нельзя ни в коем случае); а – характеристика наклона линии относительно горизонтали; b – начальный уровень процесса, т.е. то, что смоделированная линия отсекает по вертикальной оси координат. Сущность метода можно свести к следующему. Не сложно показать, что если в уравнении (23) коэффициент а = 0, то b будет равен среднему арифметическому из ряда измерений. И тогда процесс, описываемый рядом измерений, будет случайным и случайно флуктуирующим вокруг постоянного уровня, равного среднему арифметическому. Таким образом, коэффициент а кроме того что характеризует меру наклона модельной линии, ещё является характеристикой значимости линейного систематического влияния (линейного тренда, или влечения, а также степени случайности ряда). Теперь задачу анализа на степень случайности по методу значимости коэффициентов регрессии (модели) можно свести к следующим трем шагам: 1. Провести аппроксимацию результатов измерений в зависимости от номера прямой линией решим по методу наименьших квадратов – получение линии регрессии. Чтобы модель была наилучшей, пожелаем найти такие коэффициенты регрессии а и b, чтобы суммарное отклонение реальных измерений от смоделированных было наименьшим. Обычно используют сумму квадратов отклонений. Такая функция носит название целевой, минимум которой и требуется отыскать. Для этого составляем целевую функцию Ф вида
Ф = [((Xi)мод. – Xi)2] = [(a × i + b – Xi)2] = [v2] (24)
и находим её минимум, решая следующую систему нормальных уравнений
[i2] × a + [i] × b = [x× i] [i] × a + n × b = [x]. (25)
В матричном виде система имеет вид N ∙ k = B, где
а решение системы может быть получено через обращение матрицы N в виде k = N-1× B = Q× B, или, или любым другим способом. Возможно решение задачи аппроксимации целевой функции (24) на основе обычной вычислительной схемы МНК: матрица плана А, матрица нормальных уравнений N, и т.д. 2. Получив коэффициенты регрессии а и b на основе статистической проверки гипотез проверяем степень отличия а от 0, а b от среднего арифметического. Так как коэффициент регрессии b является средним только для парной регрессии вида (23), то обычно проверяют только степень отличия коэффициента а от 0. Для этого можно использовать приближенное правило: величина считается практически равной нулю, если по абсолютной величине не превосходит тройной погрешности её определения – |a| £ 3× σ a (правило " трёх сигм", или правило Райта). При более точном подходе, необходимо вычислить практическое значение t-статистики Стьюдента
и сравнить её с теоретическим значением t (получаемым из статистических таблиц, или в какой-либо программе, например Matlab) по доверительной вероятности p и числу степеней свободы (п – 2). Здесь 2 – число определяемых параметров в линейной модели (23). Если tвыч. < t, то с вероятностью р величина а не отличается от нуля и значимого тренда – односторонне действующего систематического влияния в результатах измерений нет, а ряд достаточно случаен и пригоден для дальнейших вычислений. Чтобы получить погрешность σ а определения коэффициента а, необходимо иметь погрешность модели σ 0 и матрицу кофакторов модели (матрицу обратных весов N-1= Q). Погрешность модели определяется по известной формуле Бесселя
где k – число параметров в модели, для нашего случая равное 2, v как и выше разность между модельной и реальной величиной измерения (см. (24)). Тогда погрешность коэффициента а вычисляется как
--------------------------- * Дополнительно. Если систематическое влияние значимо, и известно, что в начале измерения были свободны от него (для Х1), возможно провести коррекцию результатов i-ого измерения как
* Дополнительно. Для проверки гипотезы случайности ряда измерений (и все что из этого следует) в непараметрическом случае используем критерий инверсий. Критерий тренда и случайности на основе инверсий также производит проверки гипотез о случайности расположения полученных выборочных данных, т. е. отсутствия взаимосвязи между значениями реализаций наблюдаемой случайной величины и их номерами в выборочной последовательности. Также как и выше величины измерений используются только в порядке их появления. Сущность метода в следующем. Если в выборке значений х1, х2, …, хп, обязательно записанных в порядке их появления, за некоторым значением х i следует меньшее по величине (т.е. х i > х j, где i + 1 ≤ j ≤ п), то имеет место одна инверсия ki. Общее число инверсий I = [k] в выборке является статистикой критерия случайности исследуемого ряда измерений. Обусловлено это следующими соображениями. Если ряд только возрастающий, или только убывающий, то мы имеем закономерность (порядок) и о случайности говорить не приходится. Здесь число инверсий или максимальное, или 0. Но где-то в середине между ними имеем достаточную случайность, которую и следует фиксировать. Для этого надо построить закон распределения для инверсий, найти его основные характеристики и на основе их проверить гипотезу о количестве инверсий. При п ≥ 20 статистика критерия инверсий I достаточно хорошо для прикладных целей распределена нормально со средним М(I) и дисперсией D(I), где
При
гипотеза случайности не отклоняется с вероятностью р. Здесь u(1+p)/2 – квантиль нормального распределения (критическое, или теоретическое значение критерия) для доверительной вероятности р. При необходимости (достаточно редко для практики) точные критические значения статистики I можно получить из статистических таблиц (см. например [3], стр. 536). Критерий имеет асимптотическую эффективность ----------------------------
Другие, достаточно простые и нередко используемые критерии выявления разного рода систематических влияний в результатах измерений при условии, что закон распределения неизвестен, это критерий серий и критерий восходящих и нисходящих серий.
2.1.1. Пример исследования ряда на степень случайности (тренд)
Для примера используем исходные данные таблица 1. Проведем проверку степени случайности на основе параметрического критерия коэффициентов регрессии. Первым, рекомендуемым шагом при проверке, является графическое представление результатов измерений hi в зависимости от их номера i в ряде. Такое представление (см. рис. 1) часто может многое сказать сразу, до вычислений, о поведении ряда.
Рис.1 График зависимости значения измерения от номера в ряде
На следующем этапе проведем аппроксимацию результатов измерений в зависимости от номера измерения в ряде на основе метода наименьших квадратов (МНК). Простейшая и универсальная последовательность приближения данных по МНК следующая. Строим матрицу плана А, состоящую из чисел при коэффициентах а и b в модели регрессии
Теперь, для составления системы нормальных уравнений N ∙ k = B, позволяющих определить коэффициенты модели (см. (25) и далее) вычисляем матрицу
Теперь искомое уравнение регрессии (уравнение модели в зависимости от номера измерения i) будет
Замечаем визуально, что коэффициент модели а = 0.0000586 достаточно близок к нулю, а коэффициент b = 4.5983 к среднему арифметическому 4.5989. Чтобы проверить значимость отличия коэффициента модели а = 0.0000586 от нуля математически, необходимо получить величину погрешности определения этого коэффициента и использовать процедуру проверки гипотез (см. (28), (27), (26)). Для получения погрешности модели (27) вычисляем значения отклонений vi =(hi)мод – hi, вычислив предварительно по модели выше для каждого из 20 номеров i величины (hi)мод. Тогда в матричном виде имеем
Величина [v2] = vTv = 0.00029894, а погрешность модели из (27)
Здесь k = 2 – число определяемых коэффициентов в модели (a и b).
Заметим, что число цифр после запятой в промежуточных записях не менее трех, т.к. исходные данные мы имеем до мм. Целесообразно иметь одну запасную цифру, т.е. промежуточная запись результатов в нашем случае до 4 цифр после запятой.
Погрешность определения коэффициента а из (28)
Для проверки значимости отличия коэффициента а от нуля, при погрешности его определения σ а: 1. Выдвигаем гипотезу, что с вероятностью р = 0.95 для нашего ряда, величину коэффициента а в модели можно принять практически равным нулю. 2. На основании (26) вычисляем практическое значение критерия
3. Получаем значение квантиля распределения Стьюдента (теоретическое значение критерия) t по вероятности р = 0.95 (модернизируя её как (1+0.95)/2=0.975 так как критерий двухсторонний) и количеству степеней свободы r = n – 2 (r = 18) используя систему Matlab:
tt=tinv(0.975, 18)
В результате имеем t = 2.10. 4. Сравнивая практическое значение критерия и теоретическое видим, что практика намного меньше теории
что говорит о том, что гипотеза о статистическом равенстве нулю величины коэффициента а в модели, можно принять с вероятностью р = 0.95. Это в свою очередь говорит о том что значимых линейных трендов в нашем ряде нет, а следовательно он достаточно случаен и мы свободно можем использовать весь статистический аппарат для дальнейших исследований. Для геодезистов выполнение критерия кроме всего прочего может трактоваться как отсутствие в ряде измерений значимого систематического влияния линейного (трендового) типа. Обычно для наглядности наносят линию регрессии на график зависимости значения элемента выборки от его номера (рис. 2).
Рис. 2. Рисунок ряда и его линейной модели
---------------------------- * Дополнительно. Для использования непараметричекого критерия инверсий проверки степени случайности ряда измерений необходимо подсчитать число инверсий ki в ряде по правилу: – берем ряд значений х1, х2, …, хп, обязательно записанных в порядке их появления; – для каждого значения х i, начиная с первого, считаем число элементов меньших х i, общее число которых и образует число инверсий ki для х i. Эту процедуру проделываем для всех п элементов ряда измерений, учитывая, что для последнего число инверсий равно нулю. Тогда для нашего ряда имеем
Общее число инверсий I = [k] = 86 будет статистикой критерия случайности исследуемого ряда измерений. Для практического значения критерия I * рассчитываем оценки математического ожидания М(I) и дисперсии D(I) числа инверсий I используя (30) и (31)
Тогда по формуле критерия (32) имеем для практического значения
Теоретическое значение критерия есть квантиль нормального распределения для вероятности р = 0.95 и равен u(1+p)/2 = 1.96. Так как |I *| < u(1+p)/2, то с вероятностью 0.95 можно принять гипотезу о случайности ряда исследуемых величин. -----------------------------
|
Последнее изменение этой страницы: 2019-03-29; Просмотров: 390; Нарушение авторского права страницы
 , (25а)
, (25а) (26)
(26) , (27)
, (27) . (28)
. (28) . (29)
. (29) , (30)
, (30) . (31)
. (31) (32)
(32)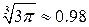 относительно критерия коэффициента регрессии. Следовательно, по эффективности он превосходит большинство непараметрических критериев для тренда.
относительно критерия коэффициента регрессии. Следовательно, по эффективности он превосходит большинство непараметрических критериев для тренда.
 и вектор свободных членов с, состоящий из 20 результатов измерений по порядку, необходимые для создания системы уравнений, позволяющих однозначно вычислить искомые коэффициенты модели. Так как при а имеем номера измерений от 1 до 20, а при b – единицы, очевидно что матрица А и вектор свободных членов с имеют вид
и вектор свободных членов с, состоящий из 20 результатов измерений по порядку, необходимые для создания системы уравнений, позволяющих однозначно вычислить искомые коэффициенты модели. Так как при а имеем номера измерений от 1 до 20, а при b – единицы, очевидно что матрица А и вектор свободных членов с имеют вид ,
, 
 и вектор свободных членов системы нормальных уравнений
и вектор свободных членов системы нормальных уравнений  . Элементы идентичны формулам (25) но намного проще и универсальнее с точки зрения вычислений. Тогда решение системы N ∙ k = B будет k = N-1× B = Q× B и в числах
. Элементы идентичны формулам (25) но намного проще и универсальнее с точки зрения вычислений. Тогда решение системы N ∙ k = B будет k = N-1× B = Q× B и в числах
 .
.
 м.
м. .
.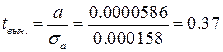 (более 2 знаков после запятой не нужно)
(более 2 знаков после запятой не нужно) ,
, 
 ,
,  .
. .
.