
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Построение прямых линий регрессии по выборочным данным
Две случайные величины могут быть связаны либо функциональной зависимостью, либо быть независимыми, либо связаны зависимостью другого рода, называемой статистической (иначе стохастической). Как правило, функциональная зависимость реализуется редко, так как одна или две случайные величины подвержены действию многих случайных факторов. Случайные величины независимы, если закон распределения одной из них не зависит от того, какие значения принимает другая случайная величина. Статистической называется такая зависимость, при которой изменение одной из них влечет за собой изменение распределения другой. В частности, если при изменении одной из величин изменяется среднее значение другой, статистическую зависимость называют корреляционной. Приведем примеры статистической зависимости. Примеры. Рост X школьников и их возраст Y; месячная зарплата рабочих предприятия X и их месячный расход на бензин Y; тоннаж X, перевезенный за определенный период времени товарными поездами по железной дороге и Y – автотранспортом; количество удобрений X, внесенных на 1 га и урожай Y с этого участка. О влиянии курения на рак легких. Статистические данные указывают, что процент заболевания раком легких среди тех, кто выкуривает много сигарет в день, гораздо выше, чем среди тех, кто курит мало или не курит вообще. Это указывает на связь, но не на причину заболевания. Не может ли совершенно другая причина вызывать как интенсивное курение, так и рак легких без какой-либо причинно-следственной связи между ними? Могут существовать, например, генетические особенности, которые делают человека более восприимчивым к раку легких и в то же время служат причиной вспыльчивого характера, а поэтому склонности к курению для успокоения нервов? Р. Фишер, известный как генетик не меньше, чем как статистик, рассуждал практически также. Роль табака как фактора, вызывающего рак легких, была установлена точно лишь тогда, когда из него выделили канцерогены-вещества, тесно связанные со смолой, содержащейся в табаке; было также доказано, что они легче поглощаются организмом из сигарет, чем из сигар или трубочного табака. Таким образом, биохимические исследования подтверждают предполагаемую статистическую связь между курением и раком легких. Пусть изучается система количественных признаков В первом случае (несгруппированных данных) в результате n независимых опытов получены n пар чисел: Таблица 7.4.1
Во втором случае (случай сгруппированных данных) мы имеем дело с корреляционной таблицей. В ней перечислены значения случайных величин Х и У, а также их частоты Если количество значений X и Y велико или эти величины распределены непрерывно, то производится группировка их значений по интервалам. В этом случае Таблица 7.4.2
Корреляционная таблица содержит всю информацию, полученную в результате выборки наблюдаемых величин X и Y объемом n. Условным средним Условным средним С помощью корреляционной табл. 7.4.2 для каждого значения Таблица 7.4.3
На основании табл. 7.4.3 можно определить условное среднее
Если подобным образом определить условные средние значения Y Таблица 7.4.4
Таблицу 7.4.4 можно рассматривать как зависимость условного среднего значения Y от величины X, т.е. корреляционную зависимость. Если построить точки ( Действительно, если указанные точки расположены приближенно вдоль прямой линии (рис. 7.4.1), естественно высказать предположение о существовании линейной корреляционной зависимости между изучаемыми величинами. Если же точки расположены приближенно вдоль параболы (рис. 7.4.2) – о квадратичной корреляционной зависимости.
Рис. 7.4.1 Рис. 7.4.2 Аналогично, с помощью корреляционной табл. 7.4.2 для каждого значения Таблица 7.4.5
Условное среднее
Вычисляя условные средние Таблица 7.4.6
Построив в прямоугольной системе координат точки Рассмотрим случай, когда есть основания предполагать наличие линейной корреляционной зависимости между величинами X и Y (в генеральной совокупности их значений), т.е. когда линейные уравнения регрессии имеют вид В этих случаях для описания корреляционных зависимостей между величинами X и Y по результатам выборочных наблюдений вводят выборочные уравнения линейной регрессии Y на X и X на Y: где
1. Нахождение параметров выборочных уравнений прямой линии регрессии по несгруппированным данным
Пусть в результате n независимых опытов получены n пар значений системы ( Так как различные значения X и соответствующие им значения Подберем параметры Исследуя функцию
Выполняя в последних уравнениях элементарные преобразования и применяя безындексную форму (вместо Решив эту систему, получим:
Аналогично можно найти выборочные уравнения прямой линии регрессии X на Y:
Формулы для параметров
2. Нахождение параметров выборочных уравнений прямой линии регрессии по сгруппированным данным
Пусть теперь статистические данные сгруппированы и заданы в виде корреляционной табл. 7.5.2. Перепишем систему уравнений (7.4.6) так, чтобы она отражала данные корреляционной таблицы. Для этого учтем следующие тождества:
В результате вместо системы (7.4.6) получим систему уравнений:
Решив эту систему, найдем параметры
Однако иногда уравнение регрессии (7.4.11) удобно записать в другой форме, вводя выборочный коэффициент корреляции. Найдя Если ввести соотношение
является выборочным коэффициентом корреляции, уравнение (7.4.13) может быть представлено в следующем виде:
Оно называется выборочным уравнением регрессии Y на X. Аналогично находится выборочное уравнение линейной регрессии X на Y: Задача 7.5.1. Методами корреляционного анализа исследовать зависимость между урожайностью пшеницы и картофеля на соседних участках на основании статистических данных (США). Построить выборочное уравнение линейной регрессии.
Решение: Составим вспомогательную таблицу
Выборочное уравнение линейной регрессии Y на X имеет вид
коэффициенты которого Используя вспомогательную таблицу, получим
Таким образом, уравнение линейной регрессии Y на X имеет вид
Аналогично уравнение линейной регрессии X на Y имеет вид
где коэффициенты
Таким образом, уравнение линейной регрессии X на Y имеет вид
7.5. Нахождение оценки для коэффициента корреляции Пусть над системой случайных величин (X, Y) произведено в одинаковых условиях n независимых опытов. Результаты опытов:
являются независимыми системами случайных величин, математические ожидания, дисперсии и корреляционные моменты которых одинаковы, т.е.
Требуется на основании статистических данных (7.5.1) найти оценки этих числовых характеристик системы. Для математических ожиданий и дисперсий компонент системы
Так как корреляционный момент равен
причем в силу равноточности измерений
После преобразования выражений, стоящих под знаком суммы, получим несмещенную, состоятельную оценку для корреляционного момента
Выборочный коэффициент корреляции определяется по формуле Вместо формул (7.5.4) и (7.5.5) для выборочного коэффициента корреляции полезно иметь расчетные формулы, использующие статистические данные (7.5.1). Имеем
Таким образом, для выборочного коэффициента корреляции имеем следующую формулу: Если использовать вместо “исправленных” выборочных дисперсий Если использовать сгруппированные статистические данные, несложно получить вместо (7.5.7) для выборочного коэффициента корреляции следующую расчетную формулу: Выборочный коэффициент корреляции Задача 7.5.1. Используя данные задачи 7.4.1, найти выборочный коэффициент корреляции. Решение. По полученным данным вспомогательной таблицы решения задачи 7.4.1, найдем сначала выборочные средние
Используя формулу (7.5.7), имеем |
Последнее изменение этой страницы: 2019-05-08; Просмотров: 255; Нарушение авторского права страницы
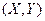 . В результате опытов выборочные данные могут быть несгруппированными и сгруппированными.
. В результате опытов выборочные данные могут быть несгруппированными и сгруппированными.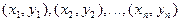 , которые могут быть представлены в виде таблицы:
, которые могут быть представлены в виде таблицы: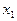
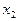
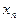
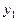
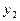
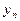
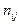 , равные числу появлений в выборке пары (
, равные числу появлений в выборке пары (  )(табл. 7.4.2).
)(табл. 7.4.2).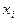 и
и 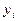 представляют собой середины соответствующих интервалов:
представляют собой середины соответствующих интервалов: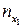
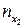
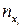
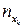
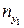
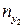
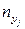
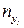
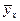 называют среднее арифметическое наблюдавшихся значений Y, соответствующих X = x.
называют среднее арифметическое наблюдавшихся значений Y, соответствующих X = x.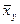 называют среднее арифметическое наблюдавшихся значений X, соответствующих Y= y.
называют среднее арифметическое наблюдавшихся значений X, соответствующих Y= y.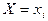 можно построить условное эмпирическое распределение случайной величины Y. В табл. 7.4.3 перечислены все значения случайной величины Y, а также соответствующие частоты:
можно построить условное эмпирическое распределение случайной величины Y. В табл. 7.4.3 перечислены все значения случайной величины Y, а также соответствующие частоты: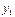
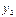
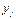
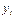
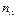
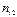
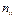
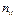
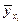 :
: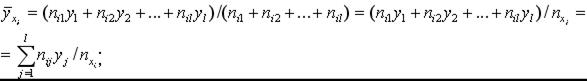
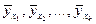 , то можно составить таблицу, в первой строке которой перечислены все встречающиеся в выборке значения величины X, а во второй - соответствующие условные средние значения величины Y (Табл. 7.4.4).
, то можно составить таблицу, в первой строке которой перечислены все встречающиеся в выборке значения величины X, а во второй - соответствующие условные средние значения величины Y (Табл. 7.4.4).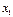
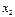
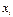
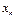
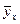

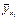
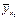

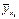
 ) в прямоугольной системе координат, то характер расположения этих точек, построенных по выборочной статистической совокупности, может привести к предположению о форме корреляционной зависимости Y от X.
) в прямоугольной системе координат, то характер расположения этих точек, построенных по выборочной статистической совокупности, может привести к предположению о форме корреляционной зависимости Y от X.
 можно составить таблицу эмпирического распределение величины X.
можно составить таблицу эмпирического распределение величины X.
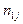
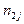
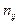

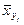 можно вычислить по формуле:
можно вычислить по формуле: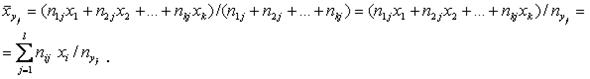
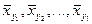 , составим таблицу, отражающую экспериментальную зависимость условного среднего значения
, составим таблицу, отражающую экспериментальную зависимость условного среднего значения 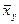 от Y.
от Y.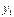
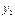
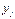
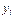
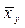
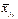
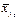
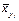
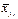
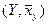 , по характеру их расположения можно высказать предположение о форме корреляционной зависимости величины X от Y.
, по характеру их расположения можно высказать предположение о форме корреляционной зависимости величины X от Y.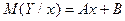 , (7.4.1)
, (7.4.1)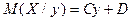 . (7.4.2)
. (7.4.2)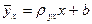 , (7.4.3)
, (7.4.3)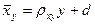 , (7.4.4)
, (7.4.4)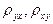 – выборочные коэффициенты линейной регрессии, имеющие смысл выборочных оценок коэффициентов A и C в формулах (7.4.1) и (7.4.2). При этом
– выборочные коэффициенты линейной регрессии, имеющие смысл выборочных оценок коэффициентов A и C в формулах (7.4.1) и (7.4.2). При этом 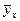 ,
, 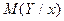 и
и 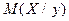 , а параметры
, а параметры 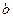 и
и 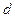 – оценками
– оценками 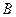 и
и 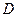 .
.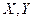 ):
): 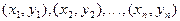 , которые могут быть заданы табл. 7.5.1. По этим статистическим данным найдем сначала параметры (коэффициенты) уравнения (7.4.3) регрессии Y на X:
, которые могут быть заданы табл. 7.5.1. По этим статистическим данным найдем сначала параметры (коэффициенты) уравнения (7.4.3) регрессии Y на X: 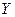 наблюдались по одному разу, то группировать данные нет необходимости; также нет надобности использовать понятие условной средней, поэтому уравнение (7.4.3) можно записать
наблюдались по одному разу, то группировать данные нет необходимости; также нет надобности использовать понятие условной средней, поэтому уравнение (7.4.3) можно записать . (7.4.5)
. (7.4.5)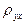 и
и 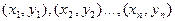 , построенные по данным наблюдениям на плоскости
, построенные по данным наблюдениям на плоскости 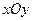 , лежали как можно ближе к прямой (7.4.5). Разность
, лежали как можно ближе к прямой (7.4.5). Разность 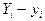 является отклонением ординаты
является отклонением ординаты 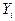 , вычисленной с помощью уравнения (7.4.5) при
, вычисленной с помощью уравнения (7.4.5) при 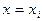 от наблюдаемой ординаты, соответствующей значению
от наблюдаемой ординаты, соответствующей значению 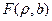 (вместо
(вместо 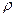 ):
): 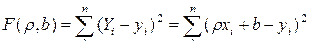 .
.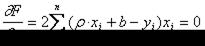 ,
,  .
. пишем
пишем  ), получим систему двух линейных уравнений относительно
), получим систему двух линейных уравнений относительно 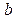 :
: . (7.4.6)
. (7.4.6) ,
, 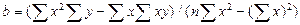 . (7.4.7).
. (7.4.7).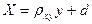 . (7.4.8)
. (7.4.8)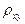 и
и 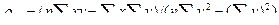 ,
,  (7.4.9)
(7.4.9)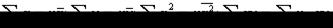 .
.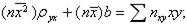
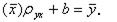 (7.4.10)
(7.4.10)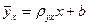 , (7.4.11)
, (7.4.11)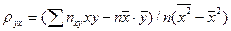 ,
, 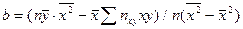 . (7.4.12)
. (7.4.12)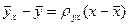 . (7.4.13)
. (7.4.13)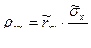 , где
, где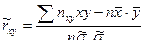 , (7.4.14)
, (7.4.14)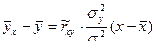 . (7.4.15)
. (7.4.15)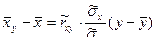 . (7.4.16)
. (7.4.16)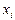
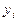
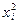
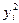
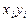
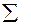
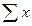 = 194,7
= 194,7
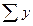 = 59,7
= 59,7
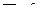 = 4974,01
= 4974,01
 = 456,51
= 456,51
 = 1501,21
= 1501,21
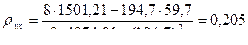 ,
, 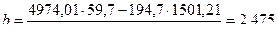 .
.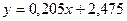 .
.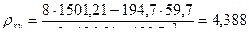 ,
, 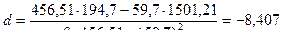 .
. .
. (7.5.1)
(7.5.1) .
.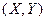 имеем известные формулы для их оценок:
имеем известные формулы для их оценок: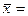
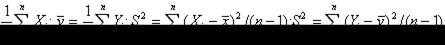 . (7.5.2)
. (7.5.2)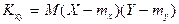 , будем искать оценку для него
, будем искать оценку для него 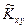 в виде
в виде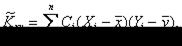 (7.5.3)
(7.5.3)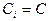 . Неизвестный коэффициент
. Неизвестный коэффициент 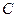 определяется из условия несмещенности оценки (7.5.3):
определяется из условия несмещенности оценки (7.5.3):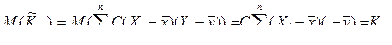 .
.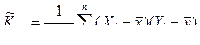 (7.5.4)
(7.5.4)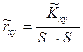 . (7.5.5)
. (7.5.5)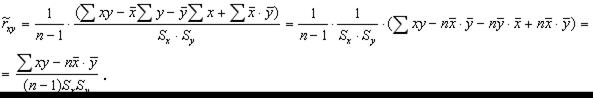
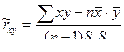 . (7.5.6)
. (7.5.6)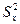 и
и  выборочные дисперсии
выборочные дисперсии  и
и 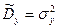 , то с использованием формулы их связи
, то с использованием формулы их связи 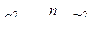 вместо формулы (7.5.6) получим:
вместо формулы (7.5.6) получим: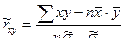 . (7.5.7)
. (7.5.7)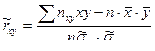 . (7.5.8)
. (7.5.8)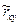 является оценкой коэффициента корреляции
является оценкой коэффициента корреляции 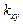 .
.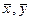 , а также выборочные дисперсии
, а также выборочные дисперсии 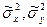 :
: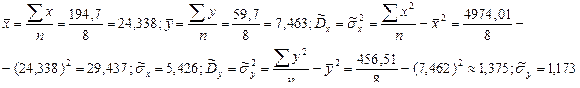 .
.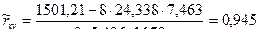 .
.