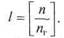|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Связанное распределение памяти
Связанное представление линейного списка называется связанным списком. При связанном распределении памяти для построения структуры необходимо задать отношения следования и предшествования с помощью специальных средств — указателей (адресов, хранимых в записях). Отличие данного способа адресации от последовательного распределения памяти состоит в том, что значение адресной функции получают не путем вычисления адреса следующего элемента, а путем просмотра хранящихся указателей. Такой метод распределения памяти позволяет расширить либо сократить логическую структуру без перемещения самих данных в памяти ЭВМ, однако при этом требуется больше памяти для хранения структуры по сравнению с последовательным распределением. Каждый узел структуры содержит указатель на следующий узел списка, т. е. адрес следующего узла. Понятно, что список не нужно хранить в последовательных элементах памяти — можно ис- 215
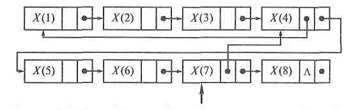
Рис. 16.5. Однонаправленный список: а —- общий вид; б — вид после удаления узла 4 и добавления узлов 2о и 5 пользовать любой свободный участок. Структура линейного списка, представленная с помощью связанного распределения, называется также цепной структурой или цепью. Рассмотрим несколько типов связанных списков. На рис. 16.5 показан простейший однонаправленный список и его скорректированный вариант (буквой «Л» здесь и далее принято обозначать конец списка): На рис. 16.6 показан двунаправленный список, элементы которого содержат два указателя: на следующий и предыдущий узлы. Первый и последний элементы содержат знак «конец списка».
Введем следующие обозначения: Soc(X(i)) — указатель, хранящийся в Mi), т.е. адрес узла X(i + 1); Тор(Х) — базовый адрес. Тогда можно записать адресные функции для указанных списков: 1) для однонаправленного линейного списка:
2) двунаправленного линейного списка: • в прямом направлении (естественно, совпадает с предыдущим); • обратном направлении:
Для ускорения доступа к требуемому элементу структуры данных используют два способа: 1) организацию связанного линейного списка с пропусками 2) построение специального линейного списка-индекса (рис. 16.8). информации за счет организации «пропуска» некоторых узлов. Первый метод предусматривает начало поиска с предпоследнего узла, второй — с первого узла линейного списка (который и называется индексом).
Каким же образом следует разбивать исходную структуру на группы узлов, которые «пропускаются» при поиске? Определим 217
оптимальный размер группы узлов пг из условия минимизации времени поиска произвольного узла списка. Если в исходном списке п узлов, число групп / можно определить, взяв целую часть от дроби:
При равновероятном нахождении узла в любой из групп при доступе к узлу необходимо просмотреть в среднем 1/2 групп, а в каждой группе — и,./2 узлов. Результаты минимизации общего среднего количества просмотров А (при понятном допущении о непрерывности пт):
Таким образом, для минимизации времени поиска произвольного узла в списке из п элементов необходимо организовать примерно л/и групп (такая же оценка справедлива для размера индекса во втором методе). В данном примере узлов в структуре было восемь, следовательно, групп пропусков узлов (элементов в индексе) нужно (примерно) три. Для связанных линейных списков в ряде случаев целесообразно создать специальный узел списка — голову списка — и хранить его в специальной фиксированной ячейке памяти (по адресу базы Ь). В голове списка обычно хранят служебную информацию: идентификатор списка, число узлов и т.п. Важной разновидностью представления в памяти линейного списка является циклический список, который называют также коль- 218
Рис. 16.9. Кольцевой однонаправленный список цевой структурой или кольцом. На рис. 16.9 показан простейший однонаправленный кольцевой список. Отметим, что для такого списка справедлива формула Soc(X(n)) = Ъ. Существуют и другие кольцевые структуры: двунаправленный циклический список; однонаправленный циклический список с указанием на голову списка и т. п. Все они предусматривают дополнительные траты памяти (на содержание указателей) для ускорения поиска данных. Как уже отмечалось, современные ЭВМ это позволяют. Особо выделим еще два варианта использования памяти: стек (магазин) и очередь, нашедших весьма широкое применение. Например, с помощью стека удобно организовывать работу календаря событий при имитационном моделировании, а с помощью очереди — работу системы массового обслуживания с дисциплиной обслуживания FCFS (англ. first соте — first service — «первым пришел — первым обслужен»). Стек {магазин) (от англ. stack — стог, кипа, груда и др.) — это структура данных, в которую можно добавить и из которой можно удалить элемент данных, причем доступен лишь последний добавленный элемент (можно либо получить его значение, либо удалить из стека). Название «магазин» хорошо иллюстрируется аналогией с магазином с патронами, в который всегда можно добавить (сверху) очередной и изъять последний патрон. Очередь (от англ. queue — очередь, коса, хвост и др.) —- это структура данных, в которую можно добавить элемент в конец очереди или изъять элемент, стоящий в очереди первым (полная аналогия с очередью в обыденном понимании этого слова). |
Последнее изменение этой страницы: 2019-05-08; Просмотров: 349; Нарушение авторского права страницы