
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
ГЕНЕРАЛЬНАЯ СОВОКУПНОСТЬ, ВЫБОРКА.Стр 1 из 7Следующая ⇒
ЛЕКЦИЯ № СТАТИСТИКА Математическая статистика разрабатывает математический аппарат прикладной статистики, т.е. находит и с помощью теории вероятностей обосновывает различные методы обработки и анализа результатов наблюдений. Одна из задач статистики - сделать имеющуюся информацию более сжатой, систематизированной, четкой, наглядной. Здесь помощь оказывают как математические приемы, так и диаграммы, таблицы, графики. ГЕНЕРАЛЬНАЯ СОВОКУПНОСТЬ, ВЫБОРКА. Пусть требуется изучить совокупность однотипных объектов (людей, деталей, машин, заболеваний и пр.) относительно некоторого признака, количественного или качественного. Скажем, если объекты - это детали, то количественным признаком может быть контролируемый размер детали, а качественным - ее стандартность. В обоих случаях с деталью признак можем рассматривать как случайную величину X: в первом случае - непрерывную, во втором - как дискретную (условившись, что нестандартность детали означает (Х=0), а стандартность (Х=1)). Все интересующее нас множество объектов (а также совокупность значений признака, присущего объектам) принято называть генеральной совокупностью. В статистике применяют два основных подхода: метод сплошных наблюдений (описательная статистика) и выборочный метод. Метод сплошных наблюдений предполагает измерение всех элементов генеральной совокупности. Выборочный метод основан на том, что из всей обследуемой совокупности, называемой генеральной, случайно отбирают часть элементов. Эту выбранную совокупность элементов называют выборкой и задают в виде х1, хг...., хn, где n - число выбранных элементов (объем выборки), x1 - значение исследуемого признака у первого элемента, х2 - значение признака у второго элемента и т.д. Как видим, отличие метода сплошных наблюдений от выборочного метода в том, что при первом методе принимаются во внимание все имеющиеся в наличии элементы (объекты, единицы) совокупности, а при втором - выводы о свойствах всей генеральной совокупности делаются на основе анализа взятой из нее случайным образом части -выборки. Это существенно экономит время, силы и средства. В ряде случаев генеральную совокупность большого объема мыслят как бесконечную, понимая под ней не только массу уже имеющихся элементов, но и совокупность тех, какие появятся в будущем. Эта абстракция упрощает вычисления и позволяет сделать прогноз на будущее. Случайный выбор элемента рассматривается как независимое наблюдение над случайной величиной X, распределенной так, как распределен признак в генеральной совокупности. Те значения х1, х2...., хn, какие признак X принял в n наблюдениях, называются реализациями cл.величины X. Они образуют конкретную выборку (х1, х2,..., хn), на основании которой исследователь строит выводы о генеральной совокупности. Выборочный метод широко применяется как в технике, так и в общественных и коммерческих исследованиях. В США, например, в большинстве крупных городов существуют коммерческие агентства, которые по заказам планируют и проводят выборочные исследования. В промышленности, торговле и обслуживании пользуются выборочным методом, чтобы повысить результативность работы предприятий. Опросы общественного мнения, финансовый контроль, контроль качества продукции - также сфера приложения этого метода. Выборка называется представительной (репрезентативной), если она достаточно хорошо представляет вероятностные свойства генеральной совокупности. Репрезентативность выборки обычно достигается случайностью выбора, когда каждому элементу обеспечивается равная со всеми остальными элементами вероятность попасть в выборку. УПРАЖНЕНИЯ. Доказать тождество
2. Доказать, что: а) при увеличении каждого элемента Xi выборки на 10 выборочное среднее х увеличится на 10, a S2 не изменится. б) при увеличении каждого элемента х1 выборки в 10 раз х среднее также возрастет в 10 раз, а дисперсия S2 в 100 раз. В теории вероятностей употребляются характеристикизаконараспределения:
Деление на среднеквадратическое в соответствующей степени делает эти характеристики безразмерными. Асимметрия равна нулю для симметричных распределений, она больше нуля, если " хвост" распределения тянется вправо. У нормального распределения асимметрия и эксцесс нулевые. Если эксцесс больше нуля, это, как правило, означает, что график плотности в окрестности моды имеет более острую и более высокую вершину, чем нормальная кривая. Для более плосковершинных, чем нормальное, распределений эксцесс отрицателен. По выборке мы находим приближенные значения асимметрии и эксцесса, строим оценки: асимметрия выборки = m3/ S3 (4) эксцесс выборки = m4/ s4 - 3 (5) Когда наблюдения проводятся над системой (Х, У) двух случайных величин, то выборка состоит уже из пар чисел - значений Х и У: ( x1., yi), (х2, y2 ),.... (хn, yn ). Поxiмы можем построить рассмотренные статистические моменты для X, по уi - для У. Связь между X и У, точнее, меру близости этой связи к линейной, выражает коэффициент корреляции:
Заменой средних μ x μ y на выборочные средние и дисперсий
Эту формулу легко преобразовать к виду:
Как иρ x y , выборочный коэффициент корреляции rxy заключен между -1 и +1. Если rxy =±1, то точки (х1, у1 ) лежат строго на прямой, т.е. имеет место строгая линейная зависимость. Пример 10. Испытана рессорная сталь на прочность прикручении и изгибе. Х - прочность при кручении, У - прочность приизгибе; (x1, y1 ) - прочность при кручении и изгибе i-ro образца стали. Вычислить выборочный коэффициент корреляции rxy по выборке объема n=12, заданной в двух столбцах таблицы 3. Таблица 3 Вычисление гxy
∆ x обозначает разность Сумма чисел в столбцах ∆ x и ∆ y теоретически должна всегда равняться нулю. В столбце ∆ x сумма оказалась равной -1 (а не 0), потому что вместо точного значения х=87.9 было использовано округленное значение 88. Выборочные дисперсии:
Выборочный коэффициенткорреляции:
Как видим, в среднем прочность на кручение почти вдвое больше, чем при изгибе. Близость коэффициента корреляции к 1 говорит о практически линейной связи между Х и У. Статистические моменты вычисляются по случайной выборке и потому являются сл. величинами. Поэтому следует различать две вещи: 1) статистический момент как cл. величину и 2) конкретное значение этого момента, наблюденное по конкретной выборке. Для определенности рассмотрим выборочное среднее. Его следовало бы обозначить среднее X, когда выборочное среднее есть cл. величина, и обозначить среднее х, когда мы говорим о реализации х, т.е. о среднем арифметическом значении элементов конкретной выборки. Точно так же и выборку, строго говоря, следует понимать в двух смыслах: 1) как систему (Х1, X2, ..., Хn) n независимых одинаково распределенных cл. величин, у каждой из которых закон распределения тот же, что у cл. величины X, над которой проводятся наблюдения, и 2) как конкретную выборку x1, x2,... xn, где x1 реализация cл. величины Х1, ....xn -реализация величины Хn. Выясним, какому закону подчиняется выборочное среднее Х=Хn, если наблюдения проводятся над нормальной cл. величиной Как сумма нормальных величин X1+Х2+...+Хn,
числитель величины
Таким образом Интуитивно ясно, что если взять ряд выборок (из n элементов каждая), то средние этих выборок должны вести себя куда более стабильно, чем исходная сл. величина X: меньше отклоняться μ и меньше " прыгать" от одной выборки к другой. Формула (8) это подтверждает: у величины среднее X тот же центр μ распределения, но дисперсия в n раз меньше: б2x- = б2/n. Пример. Каким следует взять объем выборки п, чтобы выборочное среднее подчинялось закону N(μ, 0.1), если Х ~ N(μ, 5)? 0.1 = DX = б2x-= 5/n, n=5/0.1=50. По поводу формулы (8) надо добавить следующее. Соотношения MX = MX и DX = DX/n выведены без учета требования нормальности. Если число наблюдений n велико, то каким бы ни было распределение у X, в силу центральной предельной теоремы выборочное среднее Хn подчиняется закону, близкому к нормальному; тем более близкому, чем больше n и чем ближе к нормальному закон распределения величины X. Так что формула (8) приближенно верна всегда. С ростом объема n выборки плотность вероятности для среднее Хn концентрируется около центра μ и имеет нормальный вид, высота графика плотности пропорциональна n1/2 ВЫБОРОЧНЫЕ РАСПРЕДЕЛЕНИЯ Эмпирическая функция распределения. По вариационному ряду или выборке легко построить эмпирическую функцию распределения F*(x) - оценку истинной функции распределения F(x) = P(X< x).
доля точек выборки слева от т. х. Так, График Слева от точки х.( 1) Теорема Гливенко Советским математиком Гливенко была доказана теорема: При числе испытаний, стремящихся к бесконечности эмпирическая функция распределения равномерно сходится к теоретической функции распределения. Пример 12. Построить график {0.17, 1.53, 0.99, 2.04, 0.56, 1.73, 0.95, 1.25, 0.75, 1.82}, n=10. Упорядочим выборку: {0.17, 0.56, 0.75, 0.95, 0.99, 1.25, 1.53, 1.73, 1.82, 2.04}, и нанесем точки х( 1), х(2), ..., х(10) на ось х. Высота каждой ступеньки графика равна 1/n = 0.1 и число x n=10. Эмпирическая функция Сравним функции
С ростом объема n выборки функция при большом n - При большом числе наблюдений над непрерывной cл. величиной X прибегают к группировке данных: ось х разбивают на 10-15 интервалов Длины интервалов не обязательно одинаковы. По сгруппированным данным выборочное распределение выражают разными графиками, в первую очередь это: 1) кумулятивная кривая распределения (или график накопленной частоты) - аппроксимация эмпирической функции распределения 2) гистограмма; 3) полигон частот. Строятся они так. Кумулятивная кривая. Взяв на оси ох точку Построенные точки плоскости соединим последовательно прямолинейными отрезками. В точках Гистограмма. На каждом интервале Ij оси абсцисс строим прямоугольник с высотой hj = mj/(nIj), обеспечивающей площадь прямоугольника, равную частоте mj/n (здесь lj= Полигон. В середине каждого интервала Ij разбиения строим ординату, равную mj/n - частоте попадания наблюдений в этот интервал. Соединяем полученные точки прямолинейными отрезками. Другой вариант полигона получим, соединяя отрезками середины верхних сторон прямоугольников, образующих гистограмму. Гистограмма и полигон являются эмпирическими аналогами плотности вероятности. Если n увеличивать, а длины lj интервалов уменьшать, то гистограмма и полигон неограниченно приближаются к кривой плотности вероятности cл. величины. Пример 13. Построить три указанные кривые по сгруппированным данным, представленным в таблице 4 частот, n=200. Таблица Сгруппированные данные
На рисунках 5, 6 представлены три выборочные распределения. В частности, на рис.5 в точке х=115 высота кумулятивной кривой W(х) равна 0.035+0.055+0.075=0.165, в точке х=140 W(х)=0.95, а W(150) = 1.
Высота гистограммы в точке х=117 (рис.6) равна m4/nl = 0.120/5 = 0.024. МЕТОД МОМЕНТОВ Если параметр распределения сам является моментом, как МХ или DХ, то за его оценку в этом методе берут соответствующий статистический момент (например, Например, если Пример. Найти формулу для оценки методом моментов срединного отклонения Е нормального распределения. Срединное отклонение Заменяя дисперсию в формуле на S2 - статистический центральный момент второго порядка, получим оценку срединного отклонения:
Пример. Пусть неизвестный параметр - математическое ожидание. Тогда в нормальном распределении
Эта характеристика является состоятельной (закон больших чисел). Пример. Смещенная выборочная характеристика. Пусть в нормальном распределении следует оценить дисперсию. Положим в качестве выборочной характеристики случайную величину
= = = т.к. Доказать, что выборочная характеристика
является несмещенной для дисперсии
= ИНТЕРВАЛЬНОЕ ОЦЕНИВАНИЕ Мы видели, что точечная оценка параметра есть случайная величина, имеющая некоторый разброс возле истинного значения параметра, а потому мы допускаем какую-то ошибку, приравнивая истинное значение параметра численному значению оценки. Здесь же мы рассмотрим вопрос получения интервальных оценок, т.е. возможность построения некоторого интервала, содержащего (накрывающего) истинное значение параметра с заданной вероятностью. Эту вероятность β называют по-разному: доверительной вероятностью, коэффициентом доверия или гарантией, а построенный интервал - доверительным. Доверительный интервал для параметра θ, соответствующий доверительной вероятности β, обозначим Iβ (θ ) - это интервал для θ, построенный по случайной выборке (и потому случайный) и накрывающий истинное значение θ (постоянное и обычно неизвестное нам) с заданной вероятностью β, т.е.
Величина β влияет на величину интервала Iβ (θ ): чем больше β, тем шире интервал. Принято брать β равным 0, 95 или 0, 99. Если, приняв β =0, 99, мы по выборкам будем строить доверительные интервалы, то в среднем 1 на 100 интервалов не будет содержать истинное значение θ параметра, т.е. будет лежать в стороне от. θ (какой именно один из ста мы, конечно, не знаем, поскольку θ не известно). Чтобы понять метод построения доверительных интервалов в простейших задачах, рассмотрим некоторые из них.
Пример 21. По выборке с n=16 для нормальной величины с известной дисперсией σ 2=64 найдено х=200. Построить доверительный интервал для генерального среднего (иначе говоря, для математического ожидания) μ, приняв β =0, 95. Решение. I β (μ )= I0.95(μ )=200 Делая вывод, что с гарантией β =0, 95 истинное среднее принадлежат интервалу (196, 204), мы понимаем, что возможна ошибка. Из 100 доверительных интервалов I0. 95 (μ ) в среднем 5 не содержат μ. Пример 22. Каким в условиях предыдущего примера 21 следует взять n, чтобы вдвое сузить доверительный интервал? Чтобы иметь 2δ =4, надо взять На практике часто пользуются односторонними доверительными интервалами. Так, если полезны или не страшны высокие значения μ, но не.приятны низкие, как в случае с прочностью или надежностью, то резонно строить односторонний интервал. Для этого следует максимально поднять его верхнюю границу. Если мы построим, как в примере 21, двусторонний доверительный интервал для заданного β, а затем максимально расширим его за счет одной из границ, то получим односторонний интервал с большей гарантией β ' = β + (1-β ) / 2 = (1+β )/2, например, если β = 0, 90, то β = 0, 90 + 0, 10/2 = 0, 95. Например, будем считать, что речь идет о прочности изделия и поднимем верхнюю границу интервала до Практическим недостатком формулы (15)_является то, что она выведена в предположении, что дисперсия Пример 23. Положим, в некотором большом городе в результате выборочного обследования жилищных условий жителей получена следующая таблица данных (пример из работы [6]). Таблица 8 Исходные данные к примеру
Естественно допустить, что сл. величина X - общая (полезная) площадь (в м2), приходящаяся на одного человека подчиняется нормальному закону. Среднее μ и дисперсия σ 2 не известны. Для μ требуется построить 95%-ный доверительный интервал. Чтобы по группированным данным найти выборочные средние и дисперсию, составим следующую таблицу выкладок (табл.9). Таблица 9 Вычисления X и 5 по сгруппированным данным
В этой вспомогательной таблице по формуле (2) подсчитаны первый и второй начальные статистические моменты а1 и а2
Хотя дисперсия σ 2 здесь неизвестна, из-за большого объема выборки можно практически применить формулу (15), положив в ней σ = Тогда δ =k0.95σ / Доверительный интервал для генерального среднего при β =0, 95 равен I0.95 (μ ) = Следовательно, среднее значение площади на одного человека в данном городе с гарантией 0.95 лежит в промежутке (18.54; 19.46).
2. Доверительный интервал для математического ожидания μ в случае неизвестной дисперсии σ 2 нормальной величины. Этот интервал для заданной гарантии β строится по формуле
Коэффициент tβ, ν имеет тот же смысл для t – распределения с ν степенями свободы, что кβ для распределения N(0, 1), а именно:
Другими словами, сл. Величина tν попадает в интервал (-tβ, ν ; +tβ, ν ) с вероятностью β. Значения tβ, ν даны в табл.10 для β =0.95 и β =0.99. Таблица 10. Значения tβ, ν
Возвращаясь к примеру 23, видим, что в нем доверительный интервал был построен по формуле (16) с коэффициентом tβ, υ =k0..95=1.96, т. к. n=1000. Пример 24. Построить 99%-ный доверительный интервал для генерального среднего диаметра Д валика по " пробе" из 10 деталей, сработанных на токарном автомате, если отклонения х1 размеров этих валиков от номинального размера оказались следующими (в мк): 2, 1, -2, 3, 2, 4, -2, 5, 3, 4; n=10. Находим Строим доверительный интервал для среднего μ (отсчитываемого также от номинального размера) из условия
В таблице 10 для числа степеней свободы ν =10-1=9 1%-ный предел t0.99: 9 отсутствует, есть для ν =5 и для ν =10: t0.99: 5=4, 03; t0.99: 10=3, 17. Линейная интерполяция дает t0.99: 9= Таким образом, согласующиеся с нашими опытными данными, иными словами, " допустимые" (с гарантией 99%) значения параметра μ лежат в интервале (-0.55, 4.55). Если коэффициент Заметим, что если бы мы приняли число s=2.28 за значение параметра б и применим формулу, Пример 26. Пусть частота Принять β =0.95 Решение. а) б) В случае б) доверительный интервал крайне груб, поскольку требование npq > 10 не выполнено: npq ПРИМЕРЫ Рассмотрим сначала задачи проверки гипотез об интересующем нас параметре θ вида: 1) H0: θ =θ 0; H1: θ 2) H0: θ =θ 0; H1: θ < θ 0, 3) H0: θ =θ 0; H1: θ > θ 0. где θ 0 - заданное конкретное число. Такие гипотезы можно проверить посредствен построения доверительного интервала для θ. Для проверки гипотезы вида 1) мы строим с доверительной вероятностью β =1-α доверительный двусторонний интервал Iβ (θ ) для θ и проверяем, накрыл ли он число θ 0. Если θ 0 Є Iβ (θ ), то гипотеза Ho выдержала проверку, т.е. приемлема с уровнен значимости α. Если θ 0 При проверке гипотез вида 2) и 3) строится односторонний доверительный интервал, а именно, в случае 2) односторонний интервал Iβ (θ ) с нижней границей хH; а в случае 3) с верхней границей хB. Если этот интервал покрывает θ 0, гипотеза Н0 принимается, если не накрывает - отвергается. Пример 29. Допустим, при уровне значимости α =0, 05, проверяется гипотеза Но: μ =109 против альтернативной, Н1: μ Далее
Пример 30. При уровне значимости α =0, 05 проверить гипотезу Н0: μ =106, H1: μ > 106 по выборке предыдущего примера. Чтобы построить 95%-ый односторонний доверительный интервал для среднего, сначала строим 90%-ный двусторонний. В результате Двухсторонний доверительный 90%-й интервал найден: I0.90(μ )=100±6, 2=(93, 8; 106, 2). Опустив нижнюю границу интервала до - Итак, получен 95% -й односторонний доверительный интервал для математического ожидания μ с верхней границей 106, 2: I0.95(μ )=(- Число μ о=106 принадлежит этому интервалу, поэтому приемлема гипотеза Н0 о том, что математическое ожидание μ (оно жe истинное среднее μ, генеральное среднее) равно 106. Подчеркнем, что вывод о приемлемости основной гипотезы Н0, ее не противоречивости имеющимся данным не означают того, что доказана ее истинность. Так категорично утверждать нельзя. В последнем примере не противоречили бы тем же опытным данным гипотезы Н0: μ =100, или Н0: μ =105 и вообще бесконечное число промежуточных гипотез, из которых больше одной верной быть не может. Популярное: |
Последнее изменение этой страницы: 2016-03-17; Просмотров: 1344; Нарушение авторского права страницы




 на выборочные дисперсии
на выборочные дисперсии  получим оценку дляρ x y - выборочный коэффициент корреляции rxy:
получим оценку дляρ x y - выборочный коэффициент корреляции rxy:  (6)
(6)

 , а ∆ у обозначает
, а ∆ у обозначает  .
.

 подчиняется нормальному закону. Найдем математическое ожидание и дисперсию величины «среднее X»
подчиняется нормальному закону. Найдем математическое ожидание и дисперсию величины «среднее X»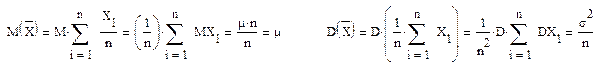
 (8)
(8)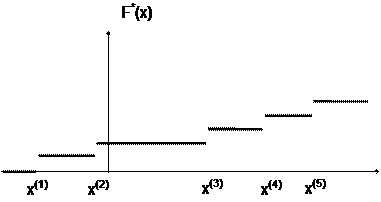
 = число точек выборки, лежащих левее т х на оси ох, или
= число точек выборки, лежащих левее т х на оси ох, или = 0.4 означает, что в выборке 40% чисел имеют значение меньшее трех.
= 0.4 означает, что в выборке 40% чисел имеют значение меньшее трех. дискретной cл. величины строится по ряду распределения вероятностей.
дискретной cл. величины строится по ряду распределения вероятностей. и F. F - неизвестная и неслучайная функция, интересующая исследователя. Функция F содержит всю информацию о соответствующей величине X, ее можно назвать истинной или теоретической функцией и по ней можно найти, в частности, МХ и DХ и другие моменты распределения.
и F. F - неизвестная и неслучайная функция, интересующая исследователя. Функция F содержит всю информацию о соответствующей величине X, ее можно назвать истинной или теоретической функцией и по ней можно найти, в частности, МХ и DХ и другие моменты распределения. , I2, ..., IК. Пусть
, I2, ..., IК. Пусть  - число наблюдений, попавших в интервал
- число наблюдений, попавших в интервал 
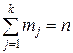 .
. - правый конец интервала
- правый конец интервала 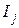 = 1, 2,..., к - отложим в ней по оси ординат накопленную частоту
= 1, 2,..., к - отложим в ней по оси ординат накопленную частоту 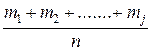 .
. , а между этими точками меняется линейно.
, а между этими точками меняется линейно. - длина интервала Ij). Вся площадь под графиком гистограммы равна 1. Другой вариант гистограммы получим, если высоту hj берем равной mj, а все длины lj одинаковы.
- длина интервала Ij). Вся площадь под графиком гистограммы равна 1. Другой вариант гистограммы получим, если высоту hj берем равной mj, а все длины lj одинаковы.

 или
или  ). Когда интересует характеристика θ распределения, отличная от начального или центрального момента, ее выражают как функцию одного или нескольких моментов и затем в качестве аргументов этой функции вместо теоретических моментов подставляют статистические.
). Когда интересует характеристика θ распределения, отличная от начального или центрального момента, ее выражают как функцию одного или нескольких моментов и затем в качестве аргументов этой функции вместо теоретических моментов подставляют статистические.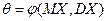 , то
, то 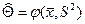 .
.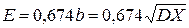 , поскольку для нормальной величины X ~ N(μ, б2) вероятность Р{μ - 0, 674б< Х< μ +0, 6746 } = 1/2.
, поскольку для нормальной величины X ~ N(μ, б2) вероятность Р{μ - 0, 674б< Х< μ +0, 6746 } = 1/2. .
.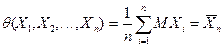
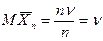


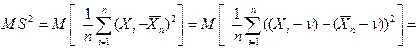

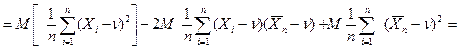
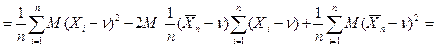
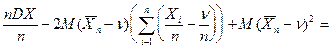
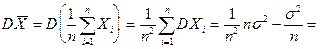
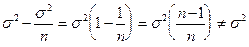 ,
, 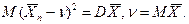
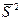 =
= 

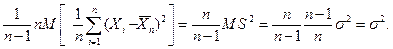
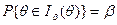 (13)
(13) -> Кβ σ /
-> Кβ σ /  = 4
= 4 4=(196; 204).
4=(196; 204).


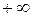 . Тогда для μ в примере 21 получим односторонний доверительный интервал (196, °°) с нижней границей 196 и доверительной вероятностью β '=0, 95+0, 05/2=0, 975.
. Тогда для μ в примере 21 получим односторонний доверительный интервал (196, °°) с нижней границей 196 и доверительной вероятностью β '=0, 95+0, 05/2=0, 975. = σ 2 (отсюда и
= σ 2 (отсюда и  .
.
 =7.16.
=7.16. =0.46.
=0.46. , где ν = n-1,
, где ν = n-1,  (16)
(16) .
.


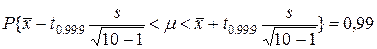 .
. Откуда
Откуда 
 получать не интерполяцией, а из более подробных таблиц, то найдем точнее
получать не интерполяцией, а из более подробных таблиц, то найдем точнее 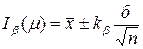 то " классические" 99%-ные доверительные границы были бы значительно уже. В самом деле, вместо
то " классические" 99%-ные доверительные границы были бы значительно уже. В самом деле, вместо 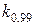 =2, 58 и получили δ =
=2, 58 и получили δ =  , т.е. оказалось бы
, т.е. оказалось бы  Этим мы значительно преувеличили бы действительную точность нашей оценки.
Этим мы значительно преувеличили бы действительную точность нашей оценки. безотказной работы при первых n испытаниях ракеты составила 0, 96. Построить доверительный интервал для вероятности р безотказной работы ракеты в двух случаях х: а) n=1000, б) n=100.
безотказной работы при первых n испытаниях ракеты составила 0, 96. Построить доверительный интервал для вероятности р безотказной работы ракеты в двух случаях х: а) n=1000, б) n=100.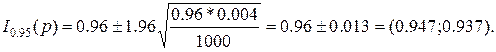
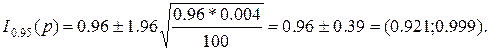
 и следует найти точный доверительный интервал для р, основанный на биноминальном распределении.
и следует найти точный доверительный интервал для р, основанный на биноминальном распределении. θ 0,
θ 0, 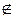 Iβ (θ ), т.е. интервал не накрыл θ 0, то гипотезу Н0 отбрасываем, принимая Н1.
Iβ (θ ), т.е. интервал не накрыл θ 0, то гипотезу Н0 отбрасываем, принимая Н1. .
.
 => гипотеза Н0 отклоняется. Вывод: генеральное среднее не равно по минимальному значению.
=> гипотеза Н0 отклоняется. Вывод: генеральное среднее не равно по минимальному значению. . Но коэффициента t0.90.ν ; нет в таблице 10. Зато в таблице 7 есть для сл.величины t30 квантиль уровня 0, 95, равный 1, 70. Значит, левее точки 1, 70 лежит 0, 95% площади распределения. А так как кривая t.-распределения симметричная, то 5% площади лежит не только правее точки 1, 70, но и левее точки -1, 70, а между -1, 70 и +1, 70 лежит 90% площади. Но t0.90.ν как раз обозначает такое число, что в интервале (-t0.90.ν ; +t0.90.ν ) заключено 90% площади, а остальная площадь поровну лежит слева и справа. Поэтому t0.90.30=1.70.
. Но коэффициента t0.90.ν ; нет в таблице 10. Зато в таблице 7 есть для сл.величины t30 квантиль уровня 0, 95, равный 1, 70. Значит, левее точки 1, 70 лежит 0, 95% площади распределения. А так как кривая t.-распределения симметричная, то 5% площади лежит не только правее точки 1, 70, но и левее точки -1, 70, а между -1, 70 и +1, 70 лежит 90% площади. Но t0.90.ν как раз обозначает такое число, что в интервале (-t0.90.ν ; +t0.90.ν ) заключено 90% площади, а остальная площадь поровну лежит слева и справа. Поэтому t0.90.30=1.70.
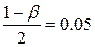 и приходим к β =0.95.
и приходим к β =0.95.