|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Информационные хранилища (Data Warehouse).
Информационное хранилище (Data Warehouse) – это самообучающаяся ИИС, которая позволяет извлекать знания из баз данных и создавать специально-организованные базы знаний. В отличие от интеллектуальной базы данных информационное хранилище представляет собой хранилище извлеченной значимой информации из оперативной базы данных, которое предназначено для оперативного анализа данных (реализации OLAP - технологии). Извлечение знаний из баз данных осуществляется регулярно, например, ежедневно. Типичными задачами оперативного ситуационного анализа являются: • Определение профиля потребителей конкретного товара; • Предсказание изменений ситуации на рынке; • Анализ зависимостей признаков ситуаций (корреляционный анализ). Для извлечения значимой информации из баз данных используются специальные методы (Data Mining или Knowledge Discovery), основанные или на применении многомерных статистических таблиц, или индуктивных методов построения деревьев решений, или нейронных сетей. Формулирование запроса осуществляется в результате применения интеллектуального интерфейса, позволяющего в диалоге гибко определять значимые признаки анализа. Применение информационных хранилищ на практике все в большей степени демонстрирует необходимость интеграции интеллектуальных и традиционных информационных технологий, комбинированное использование различных методов представления и вывода знаний, усложнение архитектуры информационных систем. Адаптивные системы
Общие сведения Адаптивная информационная система - это ИИС, которая изменяет свою структуру в соответствии с изменением модели проблемной области. Ядром адаптивной ИС является постоянно развиваемая модель проблемной области (предприятия), поддерживаемая в специальной базе знаний - репозитории, на основе которого осуществляется генерация или конфигурация программного обеспечения. Таким образом, проектирование и адаптация ИС сводится, прежде всего, к построению модели проблемной области и ее своевременной корректировке. При проектировании информационной системы обычно используются два подхода: оригинальное или типовое проектирование. Первый подход предполагает разработку информационной системы “с чистого листа” в соответствии с требованиями объекта, второй подход – адаптацию типовых разработок к особенностям объекта. Первый подход, как правило, реализуется на основе применения систем автоматизированного проектирования ИС или CASE-технологий, например, таких как, Designer 2000 (Oracle), SilverRun (SilverRun Technology), Natural LightStorm (Software AG) и др. Второй подход – на основе применения систем компонентного проектирования ИС, например, таких как R/3 (SAP), BAAN IV (Baan Corp), Prodis (Software AG), Галактика (Новый Атлант) и др. Репозиторий - хранилище метазнаний о структуре фактуального и операционного знания или модели проблемной области. Case-технология- технология, позволяющая генерировать информационную систему на основе модели проблемной области, хранимой в репозитории. Компонентная технология - технология, позволяющая конфигурировать информационную систему из готовых типовых компонентов на основе модели проблемной области, хранимой в репозитории. Отличие подходов заключается в следующем: при использовании CASE-технологии на основе репозитория при возникновении изменения выполняется каждый раз генерация (пересоздание) программного обеспечения, а при использовании компонентной технологии - конфигурация программ и только в редких случаях их переработка с помощью CASE - средств, например, использования языков четвертого поколения (4GL). В обобщенном виде конфигурация адаптивных информационных систем на основе компонентной технологии представлена на рис 2.4.
Рис. 2.4
Нейронные сети Иску́ сственные нейро́ нные се́ ти (ИНС) — математические модели, а также их программные или аппаратные реализации, построенные по принципу организации и функционирования биологических нейронных сетей — сетей нервных клеток живого организма. Это понятие возникло при изучении процессов, протекающих в мозге, и при попытке смоделировать эти процессы. Первой такой попыткой были нейронные сети Маккалока и Питтса [1]. Впоследствии, после разработки алгоритмов обучения, получаемые модели стали использовать в практических целях: в задачах прогнозирования, для распознавания образов, в задачах управления и др. ИНС представляют собой систему соединённых и взаимодействующих между собой простых процессоров (искусственных нейронов). Такие процессоры обычно довольно просты, особенно в сравнении с процессорами, используемыми в персональных компьютерах. Каждый процессор подобной сети имеет дело только с сигналами, которые он периодически получает, и сигналами, которые он периодически посылает другим процессорам. И тем не менее, будучи соединёнными в достаточно большую сеть с управляемым взаимодействием, такие локально простые процессоры вместе способны выполнять довольно сложные задачи. С точки зрения машинного обучения, нейронная сеть представляет собой частный случай методов распознавания образов, дискриминантного анализа, методов кластеризации и т. п. С математической точки зрения, обучение нейронных сетей — это многопараметрическая задача нелинейной оптимизации. С точки зрения кибернетики, нейронная сеть используется в задачах адаптивного управления и как алгоритмы для робототехники. С точки зрения развития вычислительной техники и программирования, нейронная сеть — способ решения проблемы эффективного параллелизма[2]. А с точки зрения искусственного интеллекта, ИНС является основой философского течения коннективизма и основным направлением в структурном подходе по изучению возможности построения (моделирования) естественного интеллекта с помощью компьютерных алгоритмов.
Нейронные сети не программируются в привычном смысле этого слова, они обучаются. Возможность обучения — одно из главных преимуществ нейронных сетей перед традиционными алгоритмами. Технически обучение заключается в нахождении коэффициентов связей между нейронами. В процессе обучения нейронная сеть способна выявлять сложные зависимости между входными данными и выходными, а также выполнять обобщение. Это значит, что в случае успешного обучения сеть сможет вернуть верный результат на основании данных, которые отсутствовали в обучающей выборке, а также неполных и/или «зашумленных», частично искаженных данных. Этапы решения задач 1.Сбор данных для обучения; 2.Подготовка и нормализация данных; 3.Выбор топологии сети; 4.Экспериментальный подбор характеристик сети; 5.Экспериментальный подбор параметров обучения; 6.Собственно обучение; 7.Проверка адекватности обучения; 8.Корректировка параметров, окончательное обучение.
1.Сбор данных для обучения Выбор данных для обучения сети и их обработка является самым сложным этапом решения задачи. Набор данных для обучения должен удовлетворять нескольким критериям: Репрезентативность — данные должны иллюстрировать истинное положение вещей в предметной области; Непротиворечивость — противоречивые данные в обучающей выборке приведут к плохому качеству обучения сети. 2.Выбор топологии сети Выбирать тип сети следует исходя из постановки задачи и имеющихся данных для обучения. 3. После выбора общей структуры нужно экспериментально подобрать параметры сети. Для сетей, подобных перцептрону, это будет число слоев, число блоков в скрытых слоях (для сетей Ворда), наличие или отсутствие обходных соединений, передаточные функции нейронов. При выборе количества слоев и нейронов в них следует исходить из того, что способности сети к обобщению тем выше, чем больше суммарное число связей между нейронами. С другой стороны, число связей ограничено сверху количеством записей в обучающих данных. 4. Экспериментальный подбор параметров обучения После выбора конкретной топологии, необходимо выбрать параметры обучения нейронной сети. Этот этап особенно важен для сетей, обучающихся с учителем. От правильного выбора параметров зависит не только то, насколько быстро ответы сети будут сходиться к правильным ответам. Например, выбор низкой скорости обучения увеличит время схождения, однако иногда позволяет избежать паралича сети. 5. Собственно обучение сети В процессе обучения сеть в определенном порядке просматривает обучающую выборку. Порядок просмотра может быть последовательным, случайным и т. д. Некоторые сети, обучающиеся без учителя, например, сети Хопфилда просматривают выборку только один раз. Другие, например, сети Кохонена, а также сети, обучающиеся с учителем, просматривают выборку множество раз, при этом один полный проход по выборке называется эпохой обучения. При обучении с учителем набор исходных данных делят на две части — собственно обучающую выборку и тестовые данные; принцип разделения может быть произвольным. Обучающие данные подаются сети для обучения, а проверочные используются для расчета ошибки сети (проверочные данные никогда для обучения сети не применяются). Таким образом, если на проверочных данных ошибка уменьшается, то сеть действительно выполняет обобщение. Если ошибка на обучающих данных продолжает уменьшаться, а ошибка на тестовых данных увеличивается, значит, сеть перестала выполнять обобщение и просто «запоминает» обучающие данные. 6. Проверка адекватности обучения Даже в случае успешного, на первый взгляд, обучения сеть не всегда обучается именно тому, чего от неё хотел создатель.[2] Вывод В алгоритме обучения ничего не говорится о том, насколько будет продолжительным во времени процесс обучения сети. В некоторых ситуациях бывает очень трудно определить выполнено ли условие разделимости для обучающего множества. Так же в некоторых примерах простой перебор всех возможных весов может оказаться лучше. Эти проблемы являются важной областью современных исследований.
Генетический алгоритм
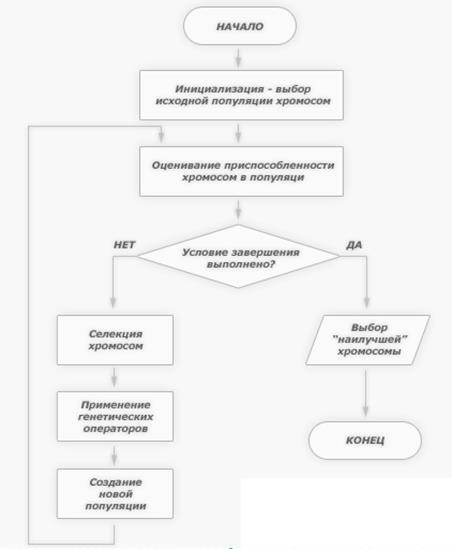
Генети́ ческий алгори́ тм (англ. genetic algorithm) — это эвристический алгоритм поиска, используемый для решения задач оптимизации и моделирования путём случайного подбора, комбинирования и вариации искомых параметров с использованием механизмов, напоминающих биологическую эволюцию. Является разновидностью эволюционных вычислений. Отличительной особенностью генетического алгоритма является акцент на использование оператора «скрещивания», который производит операцию рекомбинации решений-кандидатов, роль которой аналогична роли скрещивания в живой природе. Описание алгоритма Схема работы генетического алгоритма Задача формализуется таким образом, чтобы её решение могло быть закодировано в виде вектора («генотипа») генов, где каждый ген может быть битом, числом или неким другим объектом. В классических реализациях ГА предполагается, что генотип имеет фиксированную длину. Однако существуют вариации ГА, свободные от этого ограничения.
Некоторым, обычно случайным, образом создаётся множество генотипов начальной популяции. Они оцениваются с использованием «функции приспособленности», в результате чего с каждым генотипом ассоциируется определённое значение («приспособленность»), которое определяет насколько хорошо фенотип им описываемый решает поставленную задачу. Из полученного множества решений («поколения») с учётом значения «приспособленности» выбираются решения (обычно лучшие особи имеют большую вероятность быть выбранными), к которым применяются «генетические операторы» (в большинстве случаев «скрещивание» — crossover и «мутация» — mutation), результатом чего является получение новых решений. Для них также вычисляется значение приспособленности, и затем производится отбор («селекция») лучших решений в следующее поколение.[3]
Этот набор действий повторяется итеративно, так моделируется «эволюционный процесс», продолжающийся несколько жизненных циклов (поколений), пока не будет выполнен критерий остановки алгоритма. Таким критерием может быть: нахождение глобального, либо субоптимального решения; исчерпание числа поколений, отпущенных на эволюцию; исчерпание времени, отпущенного на эволюцию. Генетические алгоритмы служат, главным образом, для поиска решений в многомерных пространствах поиска. Таким образом, можно выделить следующие этапы генетического алгоритма: Задать целевую функцию (приспособленности) для особей популяции Создать начальную популяцию(Начало цикла) Размножение (скрещивание) Мутирование Вычислить значение целевой функции для всех особей Формирование нового поколения (селекция) Если выполняются условия останова, то (конец цикла), иначе (начало цикла). Создание начальной популяции Перед первым шагом нужно случайным образом создать начальную популяцию; даже если она окажется совершенно неконкурентоспособной, генетический алгоритм все равно достаточно быстро переведет ее в жизнеспособную популяцию. Таким образом, на первом шаге можно особенно не стараться сделать слишком уж приспособленных особей, достаточно, чтобы они соответствовали формату особей популяции, и на них можно было подсчитать функцию приспособленности (Fitness). Итогом первого шага является популяция H, состоящая из N особей. Размножение (Скрещивание) Размножение в генетических алгоритмах обычно половое — чтобы произвести потомка, нужны несколько родителей, обычно два. Размножение в разных алгоритмах определяется по-разному — оно, конечно, зависит от представления данных. Главное требование к размножению — чтобы потомок или потомки имели возможность унаследовать черты обоих родителей, «смешав» их каким-либо способом. Почему особи для размножения обычно выбираются из всей популяции H, а не из выживших на первом шаге элементов H0 (хотя последний вариант тоже имеет право на существование)? Дело в том, что главный бич многих генетических алгоритмов — недостаток разнообразия (diversity) в особях. Достаточно быстро выделяется один-единственный генотип, который представляет собой локальный максимум, а затем все элементы популяции проигрывают ему отбор, и вся популяция «забивается» копиями этой особи. Есть разные способы борьбы с таким нежелательным эффектом; один из них — выбор для размножения не самых приспособленных, но вообще всех особей. Мутации К мутациям относится все то же самое, что и к размножению: есть некоторая доля мутантов m, являющаяся параметром генетического алгоритма, и на шаге мутаций нужно выбрать mN особей, а затем изменить их в соответствии с заранее определенными операциями мутации. Отбор На этапе отбора нужно из всей популяции выбрать определенную ее долю, которая останется «в живых» на этом этапе эволюции. Есть разные способы проводить отбор. Вероятность выживания особи h должна зависеть от значения функции приспособленности Fitness(h). Сама доля выживших s обычно является параметром генетического алгоритма, и ее просто задают заранее. По итогам отбора из N особей популяции H должны остаться sN особей, которые войдут в итоговую популяцию H'. Остальные особи погибают.[4] Вывод Генетические алгоритмы в разных формах применяются к решению многих научных и технических проблем. Генетические алгоритмы используются при создании других вычислительных структур, например, автоматов или сетей сортировки. В машинном обучении они используются при управлении роботами. Они также применяются при моделировании развития в разных предметных областях. Генетические алгоритмы являются эффективной процедурой поиска, которая конкурирует с другими процедурами. Эффективность генетических алгоритмов сильно зависит от таких деталей, как метод кодирования решений, операторов, настраивания параметров, отдельных критериев успеха. Байесовская сеть
Байесовская сеть (или Байесовская сеть доверия) — это вероятностная модель, представляющая собой множество переменных и их вероятностных зависимостей. Например, байесовская сеть может быть использована для вычисления вероятности того, чем болен пациент по наличию или отсутствию ряда симптомов, основываясь на данных о зависимости между симптомами и болезнями. Формально, байесовская сеть — это направленный ациклический граф, вершины которого представляют переменные, а ребра кодируют условные зависимости между переменными. Вершины могут представлять переменные любых типов, быть взвешенными параметрами, скрытыми переменными или гипотезами. Существуют эффективные методы, которые используются для вычислений и обучения байесовских сетей. Байесовские сети, которые моделируют последовательности переменных, называют динамическими байесовскими сетями. Байесовские сети, в которых могут присутствовать как дискретные переменные, так и непрерывные, называются гибридными байесовскими сетями. Предположим, что может быть две причины, по которым трава может стать мокрой (GRASS WET): сработала дождевальная установка, либо прошел дождь. Также предположим, что дождь влияет на работу дождевальной машины (во время дождя установка не включается). Тогда ситуация может быть смоделирована проиллюстрированной Байесовской сетью. Все три переменные могут принимать два возможных значения: T (правда — true) и F (ложь — false). Совместная вероятность функции: P(G, S, R) = P(G | S, R)P(S | R)P(R) где имена трех переменных означают G = Трава мокрая (Grass wet), S = Дождевальная установка (Sprinkler), и R = Дождь (Rain). Модель может ответить на такие вопросы как «Какова вероятность того, что прошел дождь, если трава мокрая? » используя формулу условной вероятности и суммируя переменные:
[4] Вывод В силу того, что Байесовская сеть — это полная модель для переменных и их отношений, она может быть использована для того, чтобы давать ответы на вероятностные вопросы. Например, сеть можно использовать чтобы получить новое знание о состоянии подмножества переменных наблюдая за другими переменными (переменные — свидетельства). Это процесс вычисления апостериорного распределения переменных по переменным-свидетельствам называют вероятностным выводом. Это следствие дает нам универсальную оценку для приложений, где нужно выбрать значения подмножества переменных, которое минимизирует функцию потерь, например вероятность ошибочного решения. Байесовская сеть может также считаться механизмом для автоматического построения расширения Теоремы Байеса для более сложных задач. Интеллектуальные САПР Популярное: |
Последнее изменение этой страницы: 2016-03-17; Просмотров: 2125; Нарушение авторского права страницы