
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Отдельные независимые переменные
Коэффициенты при отдельно взятой переменной X в функции регрессии измеряют частичное или чистое влияние, оказываемое этой переменной X на значение переменной Y. Если регрессия в целом признана значимой, то хотелось бы проверить и значимость каждой независимой переменной в отдельности. Проблема заключается в следующем: среди всех имеющихся переменных Если гипотеза Чтобы проверить значимость j-го слагаемого (j=0, 1,..., k), в функции регрессии, значение проверочной статистики t сравнивается с табличным значением t-распределения с n-k-1 степенями свободы. Для уровня значимости Если переменные X взаимосвязаны (мультиколлинеарны), коэффициенты уравнения регрессии и соответствующие значения t могут измениться (иногда существенно), если отдельное X будет удалено из функции регрессии. Например, переменная X, которая раньше была незначимой, может стать значимой. Значит, если имеется несколько малых (незначимых) значений t, следует удалить лишь одну независимую переменную (имеющую наименьшее значение t), а не все их вместе. Этот процесс останавливается тогда, когда все независимые переменные будут иметь большие (значимые) значения статистики t и сама регрессия также будет значимой.
Прогнозирование будущих значений зависимой переменной Прогноз будущего значения зависимой переменной Y для новых значений переменных Х можно получить с помощью найденной оценки функции регрессии. При доверительном уровне 1-
Стандартная ошибка прогноза имеет сложное выражение, в котором стандартная ошибка оценки
Фиктивные переменные Иногда требуется определить, как зависимая переменная связана с независимой, когда на ситуацию дополнительно влияет некоторый качественный фактор. Эта зависимость отображается в создании фиктивной переменной. Существует много способов связать классы качественной переменной с количественными величинами. Фиктивные, или индикаторные, переменные используются для определения взаимосвязи между качественными независимыми переменными и зависимой переменной.
Мультиколлинеарность Во многих случаях применения методов регрессии в качестве данных просто используются все доступные значения предварительно назначенных независимых переменных. В подобных ситуациях независимые переменные часто оказываются линейно зависимыми. Если линейная зависимость не точная, для оценки коэффициентов регрессии может по-прежнему применяться метод наименьших квадратов. Однако в этом случае полученные оценки часто характеризуются неустойчивостью (значения коэффициентов могут существенно изменяться даже при относительно небольших изменениях данных) и определенной избыточностью (рассчитанные величины, как правило, оказываются больше ожидаемых). В частности, отдельные коэффициенты могут иметь неверный знак, а значения t-статистики для отдельных слагаемых могут все оказаться незначимыми, в то время как F-тест демонстрирует значимость регрессии. К тому же вычисления по методу наименьших квадратов могут оказаться чувствительными к ошибкам округления. Линейная зависимость между двумя или более независимыми переменными называется мультиколлинеарностью. Степень мультиколлинеарности измеряется фактором роста дисперсии (VIF):
где Если j-я независимая переменная не связана с остальными X, то Для оценки эффекта одной, отдельно взятой независимой переменной при наличии в модели мультиколлинеарности существует несколько способов, ни один из которых не является универсальным для всех возможных случаев. 1 Создать новые переменные X, которые обозначим как
Все новые переменные будут иметь нулевое среднее значение и одно и то же выборочное среднеквадратическое отклонение. Вычисления коэффициентов регрессии для этих новых независимых переменных будут менее чувствительны к ошибкам округления при наличии мультиколлинеарности. 2 Найти и удалить из набора данных одну или более независимых переменных, являющихся избыточными. 3 Воспользоваться методом оценки, отличным от метода наименьших квадратов. 4 Представить зависимую переменную Y как линейную комбинацию некоррелирующих между собой независимых переменных Х. 5 Отобрать независимые переменные на начальном этапе исследования (сразу отказываться от переменных, " говорящих об одном и том же" ).
Популярное:
|
Последнее изменение этой страницы: 2016-05-03; Просмотров: 679; Нарушение авторского права страницы
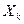 является ли влияние данного
является ли влияние данного 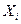 существенным или слагаемое с этой переменной может быть в функции регрессии опущено? На этот вопрос можно ответить после изучения соответствующего значения t.
существенным или слагаемое с этой переменной может быть в функции регрессии опущено? На этот вопрос можно ответить после изучения соответствующего значения t.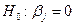 справедлива, проверочная статистика t со значением
справедлива, проверочная статистика t со значением  имеет t-распределение с числом степеней свободы df= n-k-1. Здесь
имеет t-распределение с числом степеней свободы df= n-k-1. Здесь  - это коэффициент при j-й независимой переменной в полученном методом наименьших квадратов уравнении регрессии, а
- это коэффициент при j-й независимой переменной в полученном методом наименьших квадратов уравнении регрессии, а  - оценка стандартного отклонения (стандартная ошибка).
- оценка стандартного отклонения (стандартная ошибка). при выборе одной из гипотез
при выборе одной из гипотез  гипотеза
гипотеза 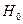 отклоняется, если
отклоняется, если  (
(  - верхний
- верхний 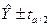 (стандартная ошибка прогноза)
(стандартная ошибка прогноза) является важным компонентом. Фактически, если n велико и все Х – независимые переменные, приблизительный 100(1-
является важным компонентом. Фактически, если n велико и все Х – независимые переменные, приблизительный 100(1- 

 - коэффициент детерминации из регрессии j-й независимой переменной по оставшимся (k-1) независимым переменным. Для k=2 независимых переменных это значение равно
- коэффициент детерминации из регрессии j-й независимой переменной по оставшимся (k-1) независимым переменным. Для k=2 независимых переменных это значение равно 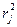 (квадрату их выборочного коэффициента корреляции).
(квадрату их выборочного коэффициента корреляции). и
и  . Если зависимость имеет место, то
. Если зависимость имеет место, то  . Значение
. Значение  , близкое к 1, говорит о том, что для этой переменной проблемы мультиколлинеарности не существует. Оценка ее коэффициента и значение t-статистики не изменятся значительно, если другие независимые переменные будут добавлены в уравнение регрессии или удалены из него. Значение
, близкое к 1, говорит о том, что для этой переменной проблемы мультиколлинеарности не существует. Оценка ее коэффициента и значение t-статистики не изменятся значительно, если другие независимые переменные будут добавлены в уравнение регрессии или удалены из него. Значение 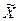 , посредством масштабирования всех независимых переменных по следующей формуле:
, посредством масштабирования всех независимых переменных по следующей формуле: 