|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Сегментно-страничное распределение
Данный метод – попытка объединить достоинства обоих методов. Здесь, как и при сегментной организации памяти, виртуальное адресное пространство процесса разделено на сегменты. Это позволяет определять разные права доступа к разным данным. Перемещение данных между памятью и диском осуществляется не сегментами, а страницами. Для этого каждый сегмент и физическая память делятся на страницы равного размера, что позволяет минимизировать фрагментацию. В большинстве современных реализаций сегментно-страничной организации
диапазонов адресов при сегментной организации все виртуальные сегменты образуют одно непрерывное линейное виртуальное адресное пространство.
Координаты байта при этом можно задать двумя способами. Во-первых, линейным виртуальным адресом, который равен сдвигу данного байта относительно границы общего линейного виртуального пространства, во вторых, парой чисел, одно из которых является номером сегмента, а другое – смещением относительно сегмента. При этом в отличие от сегментной модели для однозначного задания виртуального адреса вторым способом необходимо указать также начальный виртуальный адрес сегмента с данным номером. Чаще всего используется второй способ, так как он позволяет непосредственно определить принадлежность адреса некоторому сегменту и проверить права доступа процесса к нему. Для каждого процесса ОС создает отдельную таблицу сегментов, в которой содержатся дескрипторы (описатели ) всех сегментов процесса. Описание сегмента включает назначенные ему права доступа и другие характеристики, подобные тем, которые содержатся в дескрипторах сегментов при сегментной организации памяти. Однако есть отличия. В поле базового адреса указывается не начальный физический адрес сегмента, а начальный линейный виртуальный адрес сегмента в пространстве виртуальных адресов. Его наличие позволяет однозначно преобразовать адрес, заданный парой (g, s) в линейный виртуальный адрес байта, который затем преобразуется в физический адрес страничным механизмом. Деление общего линейного виртуального адресного пространства процесса и физической памяти на страницы осуществляется так же, как это делается при страничной организации памяти. Базовые адреса таблицы сегментов и таблицы страниц процесса являются частью его контекста. При активизации процесса эти адреса загружаются в специальные регистры процессов и используются механизмы преобразования адресов. Преобразование виртуального адреса в физический происходит в два этапа.
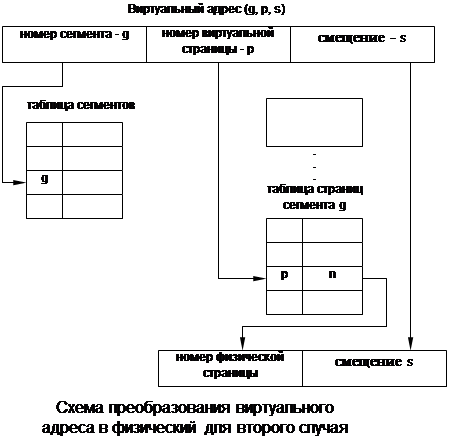
1. На первом этапе работает механизм сегментации. Исходный виртуальный адрес пары (g, s) преобразуется в линейный виртуальный адрес. Для этого на основании базового адреса сегментов и номера сегмента вычисляется поле дескриптора и выполняется проверка возможности выполнения заданной операции. Если доступ к сегменту разрешен, то вычисляется линейный виртуальный адрес путем сложения базового адреса сегмента, извлеченного из дескриптора, и смещения, заданного в исходном виртуальном адресе. 2. Второй этап использует страничный механизм. Линейный виртуальный адрес преобразуется в физический. В результате преобразования линейный виртуальный адрес представляется в том виде, в котором он используется при страничной организации памяти (пара: номер страницы, смещение в странице). Далее как уже изучали ранее. Старшие разряды линейного виртуального адреса, содержащие номер виртуальной страницы, заменяются номером физической операции, взятым из таблицы страниц, а младшие разряды виртуального адреса, содержащие смещение, остаются без изменения. Как следует из рассмотрения, механизм сегментации и страничный действуют достаточно независимо друг от друга. Поэтому не трудно представить себе реализацию памяти, когда механизм сегментации выполняется, как было показано, а страничный механизм реализуется по двухуровневой схеме: виртуальное адресное пространство делится сначала на разделы, а уж потом на страницы. В таком случае преобразование виртуального адреса в физический происходит в несколько этапов. Сначала механизм сегментации обычным образом, используя таблицу сегментов, вычисляет линейный виртуальный адрес. Затем из этого адреса вычисляется номер раздела, номер страницы и смещение. По номеру раздела из таблицы разделов определяется адрес таблицы страниц, а затем по номеру виртуальной страницы из таблицы страниц определяется номер физической страницы, к которой приписывается смещение. Именно этот подход реализован в процессорах i386, i486 и Pentium. Рассмотрим еще одну схему управления памятью, основанную на сегментно-страничном подходе. Отличие этого подхода состоит в том, что виртуальные страницы нумеруются не в пределах всего адресного пространства процесса, а пределах сегмента. Виртуальный адрес в этом случае выражается тройкой (номер сегмента, номер страницы, смещение в странице). Загрузки процесса выполняются постранично. Для каждого процесса создается своя таблица сегментов, а для каждого сегмента - своя таблица страниц. Адрес таблицы сегментов загружается в специальный регистр процессора, когда. Таблицы страниц полностью аналогичны таблице страниц в предыдущем случае. В таблице сегментов имеются существенные отличия. Она состоит из дескрипторов сегментов, которые вместо информации о расположении сегментов в виртуальном адресном пространстве содержит описание расположения таблиц страниц в физической памяти.
1. По номеру сегмента, заданному в виртуальном адресе, из таблицы сегментов извлекается физический адрес соответствующей таблицы страниц. 2. По номеру виртуальной страницы, заданному в виртуальном адресе, из таблицы страниц извлекается дескриптор, в котором указан номер физической страницы. 3. К номеру физической страницы пристыковуется младшая часть виртуального адреса - смещение.
Разделяемые сегменты памяти Примером применения разделяемой области память может быть использование ее в качестве буфера при межпроцессном обмене данными. Один процесс пишет в разделяемую область, другой – читает. Для организации разделяемого сегмента при наличии системы виртуальной памяти достаточно поместить его в виртуальное адресное пространство каждого процесса, которому нужен доступ к данному сегменту, а затем настроить параметры отображения этих виртуальных сегментов так, чтобы они соответствовали одной и той же области оперативной памяти. Детали такой настройки зависят от памяти. «Попадание» виртуальных сегментов на общую часть оперативной памяти достигается либо за счет согласованной настройки ОС многочисленных дескрипторов для процессов, либо помещением единственного разделительного виртуального сегмента в общую часть виртуального адресного пространства процессов, которую обычно используют для модулей ОС. В этом случае настройка дескриптора сегмента и дескрипторов страниц выполняется один раз, а все процессы пользуются такой постройкой и совместно используют часть оперативной памяти. При работе с разделяемыми сегментами памяти необходимо соблюдать общие правила использования разделяемых ресурсов – семафоры, мониторы и т.п. Для отличия разделяемых сегментов памяти от индивидуальных. Дескриптор сегмента должен содержать поле, имеющий два значения shared(разделяемый) или private(индивидуальный). Разделяемые сегменты выгружаются на диск системой виртуальной памяти по тем же алгоритмам и с помощью тех же механизмов что и индивидуальные.
Кэширование данных Память ЭВМ – это иерархия ЗУ, отличающихся средним временем доступа к данным, объемом и стоимостью хранения 1 бита информации. Фундамент этой пирамиды – память на жестких дисках, но время доступа к диску исчисляется миллисекундами. Оперативная память – время доступа 10-20 наносекунд (от нескольких мегабайт до нескольких гигабайт) Сверхоперативная память (десятки сотни килобайт) – 8нсек. Внутренние регистры процессора – несколько десятков байт со временем доступа 2-3 наносекунд. Кэш память или просто кэш способ совместного функционирования двух типов запоминающих устройств, отличающихся временем доступа и стоимостью хранения данных, который за счет динамического копирования в быстрые ЗУ наиболее часто используемой информации из «медленного» ЗУ позволяет, с одной стороны, уменьшить среднее время доступа к данным, с другой - сэкономить более дорогую быстродействующую память. Особенностью кэширования является то, что система не требует никакой внешней информации об интенсивности использования данных, ни пользователи, ни программы не принимают никакого участия в перемещении данных из ЗУ одного типа в ЗУ другого типа, все это делается автоматически системными средствами. Кэшем часто называют не только способ организации двух типов запоминающих устройств, но и одно из устройств – «быстрое ЗУ». Оно дороже и сравнительно небольшого объема в противовес «медленному» ЗУ – оперативной памяти. Если кэширование используют для уменьшения среднего времени доступа к оперативной памяти, то в качестве КЭШа используют более дорогую и быстродействующую статическую память. Если кэширование используется системой ввода-вывода для ускорения доступа к данным, хранящимся на диске, роль кэш-памяти играют буфера, реализованные в оперативной памяти. Виртуальную память тоже можно рассматривать как частный случай кэширования.
Принцип действия кэш-памяти Содержимое кэш-памяти представляет собой совокупность записей обо всех загруженных в нее элементах данных из основной памяти. Каждая запись включает: · элементы данных; · адрес, который этот элемент имеет в основной памяти; · дополнительную информацию, которая используется для реализации алгоритма включает признак модификации и признак действительности данных. При каждом обращении к основной памяти по физическому адресу просматривается содержимое кэш-памяти с целью определения, не находятся ли там нужные данные. Кэш-память не является адресуемой, поэтому поиск нужных данных осуществляется по содержимому - по взятому из запроса значению поля адреса в оперативной памяти. Далее возможны два варианта развития: · данные обнаружены в кэш-памяти, т.е. произведено кэш-попадание (cache-hit), они считываются и передаются источнику запроса; · нужные данные отсутствуют, т.е. произошел кэш-перенос (cache-miss), они считываются из основной памяти, передаются источнику запроса и одновременно копируются в кэш-память. Эффективность кэширования зависит от вероятности попадания в кэш.
Если обозначить вероятность кэш-попадания через p, а время доступа к основной памяти через t1, время доступа через t2, то по формуле полной вероятности среднее время доступа будет равно: t=t2p+t1(1-p) Если p=1, время доступа равно t2. Вероятность обнаружения данных в кэше зависит от различных факторов, таких как: · объем кэша; · объем кэшируемой памяти; · алгоритм замещения данных в кэше; · особенностей выполняемой программы и т.п. На практике процент попаданий оказывается весьма высоким – порядка 90%. Такой процент объясняется наличием у данных объективных свойств таких как пространственной и временной локальности. Пространственная локальность. Если произошло обращение по некоторому адресу, то с высокой вероятностью в ближайшее время произойдет обращение по соседним адресам. Временная локальность. Если произошло обращение по некоторому адресу, то следующее обращение по тому же адресу с большой вероятностью произойдет в ближайшее время. Поскольку при выполнении программы очень высока вероятность, что команды выбираются из памяти одна за другой из соседних ячеек, имеет смысл загружать в кэш целый фрагмент программы. Аналогично и с массивами данных. В процессе работы содержимое кэш-памяти постоянно обновляется. Вытеснение данных означает либо просто объявление свободной некоторой области кэш-памяти (сброс бита действительности) менялись либо в дополнение к этому копирование данных в основную память, если они модифицировались. Наличие в компьютере двух копий данных – в основной памяти и в кэше – порождает проблему согласования данных. Существует два подхода к решению этой проблемы: · сквозная запись (write through). При запросе к основной памяти (в том числе при записи) просматривается кэш. Если данные по запрашиваемому адресу отсутствуют, запись выполняется только в основную память. Если данные находятся в кэше, запись делается и в кэш ив память. · обратная запись (write back). Выполняется просмотр кэша, если данных там нет, то запись делается в основную память. В противном случае запись делается только в кэш. При этом устанавливается признак модификации. При вытеснении данных из кэша эти данные будут переписаны в основную память.
Популярное:
|
Последнее изменение этой страницы: 2016-07-13; Просмотров: 573; Нарушение авторского права страницы