
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Базы данных при решении задач в области конструкторско-технологического обеспечения машиностроенияСтр 1 из 12Следующая ⇒
Базы данных при решении задач в области конструкторско-технологического обеспечения машиностроения Лекция 2. Технологическое обеспечение машиностроения (CAМ, CAPP)
Конечный продукт конструкторского проектирования (чертеж детали, трехмерная модель, спецификация) является точкой отсчета для проектирования технологического. На полученный чертеж детали технолог проектирует заготовку:
После чего проектирует маршрут технологического процесса изготовления детали, либо сборки:
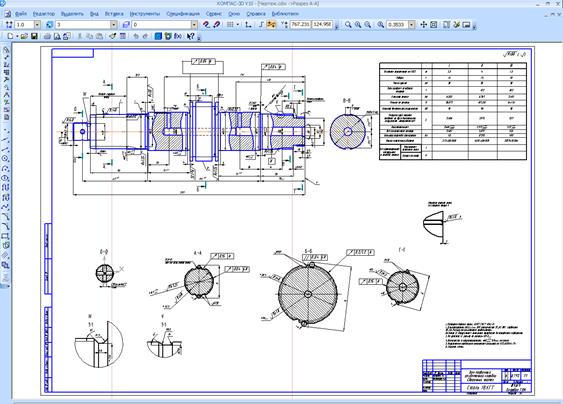
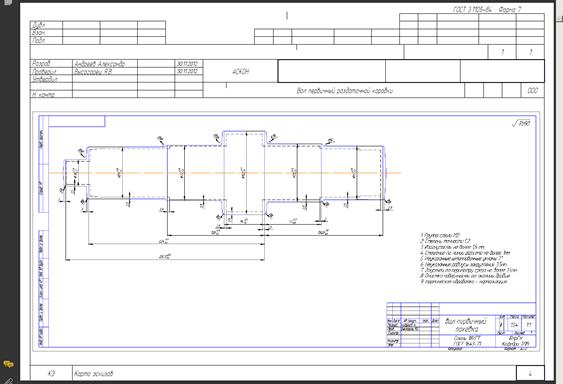
Далее описываются операции технологического процесса, включая станки, режущий и измерительный инструмент, станочные приспособления, СОЖ, СИЗ, режимы резания, нормы времени, операционные эскизы. При этом рабочий вид CAM-системы:
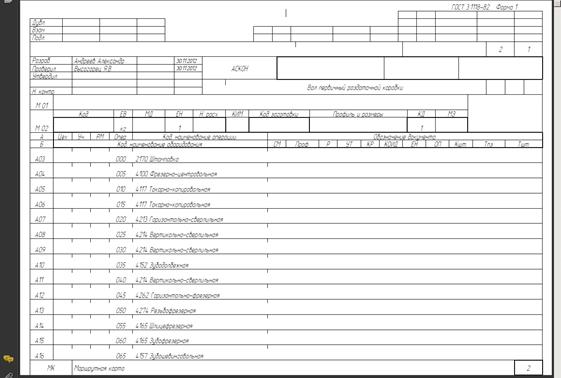
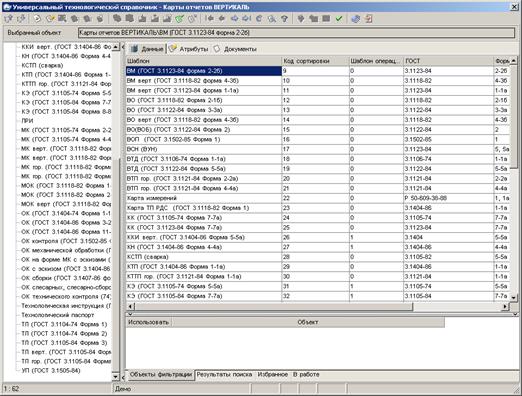
Конечным продуктом технологического труда является комплект технологической документации, которая формируется ПО в автоматическом режиме, при этом существует возможность выбора конкретных карт из различных ГОСТ’ов — это CAPP.
В комплекте документов как правило присутствует титульный лист, а также маршрутные карты, операционные карты, маршрутно-операционные карты и карты эскизов.
Данный согласованный с начальством комплект документов отправляется в цех, где согласно ему станочниками, слесарями, сборщиками, котроллерами и др. рабочими осуществляется изготовление изделия согласно конструкторской документации (чертежу) и технологической документации (комплекту документов). Далее несколько слов о терминологии и основных представителях технологического ПО в РФ. В области автоматизации технологического труда выделяют CAM-системы (computer-aided manufacturing) и CAPP-системы (Computer Aided Process Planning). Computer-Aided Process Planning (CAPP) («автоматизированная система технологической подготовки производства») — это программные продукты, помогающие автоматизировать процесс подготовки производства, а именно планирование (проектирование) технологических процессов. Задача CAPP следующая: по заданной модели изделия, выполненной в CAD-системе, составить план его производства — маршрут изготовления. В этот маршрут входят сведения о последовательности технологических операций изготовления детали, а также сборочных операциях (при необходимости); оборудование, используемое на каждой операции, приспособление и инструмент, при помощи которого на операциях выполняется обработка. Обычно технологическая подготовка производства заключается в проектировании технологических процессов на новые изделия, или адаптация технологических процессов по уже имеющейся базе типовых технологических процессов.
CAM-продукты предназначены для проектирования обработки изделий на станках с ЧПУ и выдачи программ для этих станков (фрезерных, сверлильных, эрозионных, пробивных, токарных, шлифовальных и др.). CAM-системы еще называют системами технологической подготовки производства. В настоящее время они являются практически единственным способом для изготовления сложнопрофильных деталей и сокращения цикла их производства. В CAM-системах используется трехмерная модель детали, созданная в CAD-системе.
Примеры CAM: PowerMill, MasterCAM, EdgeCAM, Adem, ComCNC, CIMCO.
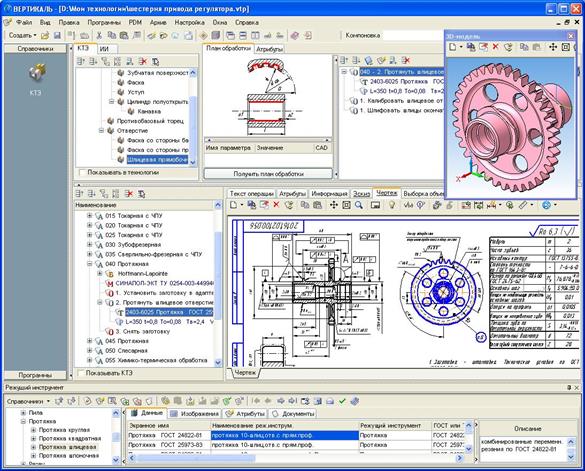
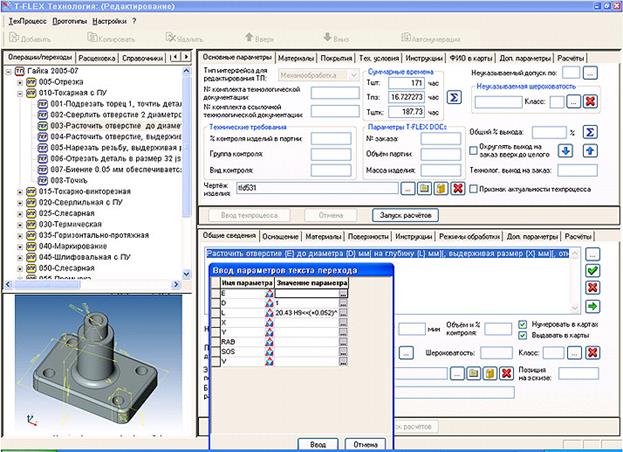
Отечественными лидерами в области технологической автоматизации машиностроения являются АСКОН (Вертикаль) и Топ Системы (T-Flex Технология, ТехноПро).
Данные программные продукты позволяют решить проблему автоматизации технологического труда на машиностроительных предприятиях страны. Других достойных представителей данного рынка назвать сложно, т.к. конкуренция в этой сфере слаба, и автоматизация труда технологов на машиностроительных предприятиях страны по сути еще только начинается. Далее — лекционный материал курса по БД Памяти Натальи Евгеньевны Василенко – моему первому редактору – посвящается
ВВЕДЕНИЕ
Использование баз данных и информационных систем становится неотъемлемой составляющей деловой деятельности современного человека и функционирования шагающих в ногу со временем организаций. В связи с этим большую актуальность приобретает освоение принципов построения и эффективного применения соответствующих технологий и программных продуктов. От правильного выбора инструментальных средств создания информационных систем, определения подходящей модели данных, обоснования рациональной схемы построения базы данных, организации запросов к хранимым данным и ряда других моментов во многом зависит эффективность функционирования разрабатываемых систем. Все это требует осознанного применения теоретических положений и инструментальных средств разработки баз данных и информационных систем. Целью изучения дисциплины «Базы данных» является формирование у студентов знаний, умений и навыков, необходимых при проектировании баз данных. В рамках дисциплины выполняется курсовая работа. После изучения курса студенты сдают письменный экзамен. Экзаменационный билет составляется из вопросов и заданий, аналогичных приведенным в конце каждого раздела данного пособия.
ВВЕДЕНИЕ В БАНКИ ДАННЫХ
Понятие банка данных
Банк данных (БнД) является современной формой организации хранения и доступа к информации. Существует много определений банка данных. Мы будем использовать следующее определение: « Банкданных – это система специальным образом организованных данных (баз данных), программных, технических, языковых, организационно–методических средств, предназначенных для обеспечения централизованного накопления и коллективного многоцелевого использования данных». Термин банк данных не является общепризнанным. В литературе встречается также термин система баз данных, близкий по своему содержанию к понятию банка данных. Мы будем использовать термин банк данных. Однако очевидно, что нельзя отождествлять понятия база данных и банк данных. Требования к БнД: · адекватность отображения предметной области (полнота, целостность и непротиворечивость данных, актуальность информации (т.е. ее соответствие состоянию объекта на данный момент времени)); · возможность взаимодействия пользователей разных категорий и в разных режимах, обеспечение высокой эффективности доступа для разных приложений; · дружелюбность интерфейсов и малое время на освоение системы, особенно для конечных пользователей; · обеспечение секретности и конфиденциальности для некоторой части данных; определение групп пользователей и их полномочий; · обеспечение взаимной независимости программ и данных; · обеспечение надежности функционирования БнД, защита данных от случайного и преднамеренного разрушения; возможность быстрого и полного восстановления данных в случае их разрушения; технологичность обработки данных, приемлемые характеристики функционирования БнД (стоимость обработки, время реакции системы на запросы, требуемые машинные ресурсы и др.). Компоненты банка данных
БнД является сложной человеко-машинной системой, включающей в свой состав различные взаимосвязанные и взаимозависимые компоненты, а именно: · информационная компонента; · программные средства; · языковые средства; · технические средства; · организационно–методические средства; · администраторы БнД. Ядром БнД является база данных (БД). Базаданных – это поименованная совокупность взаимосвязанных данных, находящихся под управлением системы управления базой данных (СУБД). Системойуправлениябазойданных называется совокупность языковых и программных средств, облегчающих для пользователей выполнение всех операций, связанных с организацией хранения данных, их корректировки и доступа к ним. В качестве технических средств для БнД используется ЭВМ. Организационно – методические средства представляют собой различные инструкции, методические и регламентирующие материалы, предназначенные для пользователей разных категорий, взаимодействующих с БнД. Функционирование БнД невозможно без администраторов БнД - специалистов, обеспечивающих создание, функционирование и развитие БнД. Классификация банков данных
Классификация банков данных может быть произведена по разным признакам (одни признаки относят к БнД в целом, другие – к отдельным его компонентам, третьи могут быть отнесены как к отдельному компоненту, так и к нескольким компонентам или банку в целом). Классификация БД. Рассмотрим классификацию БД по типу используемой модели. Хранимые в базе данные имеют определенную логическую структуру – иными словами, описываются некоторой моделью представления данных (моделью данных), поддерживаемой СУБД. К числу классических относят следующие модели данных: · иерархическую; · сетевую; · реляционную. Кроме того, в последние годы появились и стали активно внедряться на практике следующие модели данных: · постреляционная; · многомерная; · объектно-ориентированная. Разрабатываются также всевозможные системы, основанные на других моделях данных, расширяющих известные модели. Классификация по типу модели распространяется не только на БД, но и на СУБД и БнД в целом. Классификация СУБД. Рассмотрим классификацию СУБД по числу уровней в архитектуре. Под архитектурным уровнем СУБД понимают функциональный компонент, механизмы которого служат для поддержки некоторого уровня абстракции данных (логический, физический, внешний уровень). По числу уровней в архитектуре различают одноуровневые, двухуровневые и трехуровневые системы.
Рис. 1.1. Классификация СУБД по числу уровней в архитектуре (пример трехуровневой архитектуры)
На рис. 1.1 сделана попытка совместить терминологию, встречающуюся в разных литературных источниках. Нумерация уровней на рисунке условна, но, тем не менее, отражает их значимость (физическая модель может быть построена только на основе даталогической; эти два уровня могут быть совмещены, но поддерживаются СУБД всегда; внешний уровень в архитектуре СУБД может отсутствовать).
Тесты для самоконтроля
1. Базой данных называют: а) функциональный компонент, механизмы которого служат для поддержки некоторого уровня абстракции; б) совокупность языковых и программных средств, облегчающих для пользователей выполнение всех операций, связанных с хранением и изменением данных; в) совокупность взаимосвязанных данных, находящихся под управлением системы управления базой данных. 2. Система управления базой данных является: а) компонентом банка данных; б) системой специальным образом организованных данных; в) современной формой организации хранения и доступа к информации. 3. Различаются следующие модели данных: а) даталогическая, физическая, внешняя; б) иерархическая, сетевая, реляционная; в) одноуровневая, двухуровневая, трехуровневая. 4. Понятия базы данных и банка данных: а) нельзя отождествлять; б) тождественны. МОДЕЛИ ДАННЫХ
Иерархическая модель
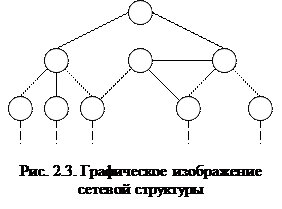
Иерархическая структура представляет совокупность элементов, связанных между собой по определенным правилам. Графическим способом представления иерархической структуры является дерево (рис. 2.1).
Рис. 2.2. Пример иерархической структуры К достоинствам иерархической модели данных относятся эффективное использование памяти ЭВМ и неплохие показатели времени выполнения операций над данными. Недостатком иерархической модели является ее громоздкость для обработки информации с достаточно сложными логическими связями. На иерархической модели данных основано сравнительно ограниченное количество СУБД, в числе которых можно назвать зарубежные системы IMS, PC/Focus, Team-Up и Data Edge, а также отечественные системы Ока, ИНЭС и МИРИС. Сетевая модель данных
Отличие сетевой структуры от иерархической заключается в том, что каждый элемент в сетевой структуре может быть связан с любым другим элементом (рис. 2.3). Пример простой сетевой структуры показан на рис. 2.4.
Достоинством сетевой модели данных является возможность эффективной реализации по показателям затрат памяти и оперативности. Недостатком сетевой модели данных являются высокая сложность и жесткость схемы БД, построенной на ее основе. Наиболее известными сетевыми СУБД являются IDMS, db_VistaIII, СЕТЬ, СЕТОР и КОМПАС. Реляционная модель данных
Реляционная модель данных была предложена Е.Ф. Коддом, известным исследователем в области баз данных, в 1969 году, когда он был сотрудником фирмы IBM. Впервые основные концепции этой модели были опубликованы в 1970. Реляционная база данных представляет собой хранилище данных, организованных в виде двумерных таблиц (рис. 2.5). Любая таблица реляционной базы данных состоит из строк (называемых также записями) и столбцов (называемых также полями). Строки таблицы содержат сведения о представленных в ней фактах (или документах, или людях, одним словом, - об однотипных объектах). На пересечении столбца и строки находятся конкретные значения содержащихся в таблице данных. Данные в таблицах удовлетворяют следующим принципам: 1) Каждое значение, содержащееся на пересечении строки и столбца, должно быть атомарным[1]. 2) Значения данных в одном и том же столбце должны принадлежать к одному и тому же типу, доступному для использования в данной СУБД. 3) Каждая запись в таблице уникальна, то есть в таблице не существует двух записей с полностью совпадающим набором значений ее полей. 4) Каждое поле имеет уникальное имя. 5) Последовательность полей в таблице несущественна. 6) Последовательность записей в таблице несущественна. Несмотря на то, что строки таблиц считаются неупорядоченными, любая система управления базами данных позволяет сортировать строки и столбцы в выборках из нее нужным пользователю способом. Поскольку последовательность полей в таблице несущественна, обращение к ним производится по имени, и эти имена для данной таблицы уникальны (но не обязаны быть уникальными для всей базы данных). Поле или комбинацию полей, значения которых однозначно идентифицируют каждую запись таблицы, называют возможным ключом (или просто ключом ). Если таблица имеет более одного возможного ключа, тогда один ключ выделяют в качестве первичного. Первичный ключ любой таблицы обязан содержать уникальные непустые значения для каждой строки. Поле, указывающее на запись в другой таблице, связанную с данной записью, называется внешним ключом. Иначе говоря, внешний ключ - это поле или набор полей, чьи значения совпадают с имеющимися значениями первичного ключа другой таблицы. Подобное взаимоотношение между таблицами называется связью. Связь между двумя таблицами устанавливается путем присвоения значений внешнего ключа одной таблицы значениям первичного ключа другой. Группа связанных таблиц называется схемойбазыданных. Информация о таблицах, их полях, первичных и внешних ключах, а также иных объектах базы данных, называется метаданными. Достоинство реляционной модели данных заключается в простоте, понятности и удобстве физической реализации на ЭВМ. Именно простота и понятность для пользователя явились основной причиной ее широкого использования.
Рис. 2.5. Схема реляционной модели данных
К основным недостаткам реляционной модели относятся отсутствие стандартных средств идентификации отдельных записей и сложность описания иерархических и сетевых связей. Примерами зарубежных реляционных СУБД для ПЭВМ являются: DB2, Paradox, FoxPro, Access, Clarion, Ingres, Oracle. К отечественным СУБД реляционного типа относятся системы ПАЛЬМА и HyTech. Постреляционная модель
Классическая реляционная модель предполагает неделимость данных, хранящихся в полях записей таблиц. Постреляционная модель представляет собой расширенную реляционную модель, снимающую ограничение неделимости данных. Модель допускает многозначные поля – поля, значения которых состоят из подзначений. Набор значений многозначных полей считается самостоятельной таблицей, встроенной в основную таблицу. На рис. 2.6 на примере информации о накладных и товарах для сравнения приведено представление одних и тех же данных с помощью реляционной и постреляционной моделей. Из рис. 2.6 видно, что по сравнению с реляционной моделью в постреляционной модели данные хранятся более эффективно, а при обработке не потребуется выполнять операцию соединения данных из двух таблиц. а) Накладные Накладные-товары
б) Накладные
Рис. 2.6. Структуры данных реляционной (а) и постреляционной (б) моделей
Поскольку постреляционная модель допускает хранение в таблицах ненормализованных данных, возникает проблема обеспечения целостности и непротиворечивости данных. Эта проблема решается включением в СУБД соответствующих механизмов. Достоинством постреляционной модели является возможность представления совокупности связанных реляционных таблиц одной постреляционной таблицей. Это обеспечивает высокую наглядность представления информации и повышение эффективности ее обработки. Недостатком постреляционной модели является сложность решения проблемы обеспечения целостности и непротиворечивости хранимых данных. Рассмотренная постреляционная модель данных поддерживается СУБД uniVers. К числу других СУБД, основанных на постреляционной модели данных, относятся также системы Bubba и Dasdb.
Многомерная модель
Многомерный подход к представлению данных появился практически одновременно с реляционным, но интерес к многомерным СУБД стал приобретать массовый характер с середины 90-х годов. Толчком послужила в 1993 году статья Э. Кодда. В ней были сформулированы 12 основных требований к системам класса OLAP (OnLine Analytical Processing – оперативная аналитическая обработка), важнейшие из которых связаны с возможностями концептуального представления и обработки многомерных данных. В развитии концепций информационных систем можно выделить следующие два направления: 1) системы оперативной (транзакционной) обработки; 2) системы аналитической обработки (системы поддержки принятия решений). Реляционные СУБД предназначались для информационных систем оперативной обработки информации и в этой области весьма эффективны. В системах аналитической обработки они показали себя несколько неповоротливыми и недостаточно гибкими. Более эффективными здесь оказываются многомерные СУБД. Многомерные СУБД являются узкоспециализированными СУБД, предназначенными для интерактивной аналитической обработки информации. Основные понятия, используемые в этих СУБД: агрегируемость, историчность и прогнозируемость. Агрегируемость данных означает рассмотрение информации на различных уровнях ее обобщения. В информационных системах степень детальности представления информации для пользователя зависит от его уровня: аналитик, пользователь, управляющий, руководитель. Историчность данных предполагает обеспечение высокого уровня статичности собственно данных и их взаимосвязей, а также обязательность привязки данных ко времени. Прогнозируемость данных подразумевает задание функций прогнозирования и применение их к различным временным интервалам. Многомерность модели данных означает не многомерность визуализации цифровых данных, а многомерное логическое представление структуры информации при описании и в операциях манипулирования данными. По сравнению с реляционной моделью многомерная организация данных обладает более высокой наглядностью и информативностью. Для иллюстрации на рис. 2.7 приведены реляционное (а) и многомерное (б) представления одних и тех же данных об объемах продаж автомобилей. Если речь идет о многомерной модели с мерностью больше двух, то не обязательно визуально информация представляется в виде многомерных объектов (трех-, четырех- и более мерных гиперкубов). Пользователю и в этих случаях более удобно иметь дело с двумерными таблицами или графиками. Данные при этом представляют собой «вырезки» из многомерного хранилища данных, выполненные с разной степенью детализации.
а) б)
Рис. 2.7. Реляционное (а) и многомерное (б) представление данных Основные понятия многомерных моделей данных: измерение и ячейка. Измерение – это множество однотипных данных, образующих одну из граней гиперкуба. В многомерной модели измерения играют роль индексов, служащих для идентификации конкретных значений в ячейках гиперкуба. Ячейка – это поле, значение которого однозначно определяется фиксированным набором измерений. Тип поля чаще всего определен как цифровой. В зависимости от того, как формируются значения некоторой ячейки, она может быть переменной (значения изменяются и могут быть загружены из внешнего источника данных или сформированы программно) либо формулой (значения, подобно формульным ячейкам электронных таблиц, вычисляются по заранее заданным формулам). В примере на рис. 2.7, б каждое значение ячейки Объем продаж однозначно определяется комбинацией временного измерения Месяц продаж и модели автомобиля. На практике зачастую требуется большее количество измерений. Пример трехмерной модели данных приведен на рис. 2.8.
Рис. 2.8. Пример трехмерной модели
В существующих многомерных СУБД используются две основные схемы организации данных: гиперкубическая и поликубическая. В поликубической схеме предполагается, что в БД может быть определено несколько гиперкубов с различной размерностью и с различными измерениями в качестве граней. Примером системы, поддерживающей поликубический вариант БД, является сервер Oracle Express Server. В случае гиперкубической схемы предполагается, что все ячейки определяются одним и тем же набором измерений. Это означает, что при наличии нескольких гиперкубов в БД, все они имеют одинаковую размерность и совпадающие измерения. Основным достоинством многомерной модели данных является удобство и эффективность аналитической обработки больших объемов данных, связанных со временем. Недостатком многомерной модели данных является ее громоздкость для простейших задач обычной оперативной обработки информации. Примерами систем, поддерживающими многомерные модели данных, является Essbase, Media Multi-matrix, Oracle Express Server, Cache. Существуют программные продукты, например Media/MR, позволяющие одновременно работать с многомерными и с реляционными БД.
Тесты для самоконтроля
1. Под элементами в иерархической структуре понимают: а) совокупность атрибутов, описывающих объекты; б) данные, организованные в виде двумерных таблиц; в) поля, значения которых однозначно определяются фиксированным набором измерений. 2. Каждый элемент может быть связан с любым другим элементом: а) в иерархической модели; б) в сетевой модели; в) в реляционной модели. 3. В таблицах реляционной базы данных: а) существенна последовательность полей и несущественна последовательность записей; б) несущественна и последовательность полей, и последовательность записей; в) несущественна последовательность полей и существенна последовательность записей. 4. В информационных системах оперативной обработки информации эффективны: а) реляционные СУБД; б) многомерные СУБД; в) иерархические СУБД. 5. Многомерность многомерной модели данных означает: а) многомерность визуализации данных; б) наличие многозначных полей; в) многомерное логическое представление структуры информации. 6. Возможность отображения информации о сложных взаимосвязях объектов имеется: а) в реляционной модели; б) в постреляционной модели; в) в объектно-ориентированной модели. 7. Комбинацию полей, значения которых однозначно идентифицируют каждую запись таблицы, называют: а) ключом таблицы; б) внешним ключом таблицы; в) первичным ключом таблицы. 8. Неделимость данных – обязательный принцип: а) постреляционной модели данных; б) реляционной модели данных; в) объектно-ориентированной модели. 9. В информационных системах аналитической обработки информации эффективны: а) реляционные СУБД; б) многомерные СУБД. МЕТОДОМ «СУЩНОСТЬ – СВЯЗЬ»
Существуют разные подходы к проектированию БД. Мы рассмотрим два метода проектирования: декомпозиционный и метод «сущность - связь», первым рассмотрим метод «сущность - связь».
3.1. Этапы проектирования
В БД отражается информация об определенной предметной области. Предметнойобластью называют часть реального мира, представляющую интерес для данного использования. В автоматизированных информационных системах отражение предметной области представляется моделями данных нескольких уровней (число уровней зависит от особенностей СУБД). Независимо от того, поддерживаются ли в явном виде отдельно модели логического и физического уровня, с точки зрения методологии все равно можно выделить эти уровни и соответствующие им этапы проектирова- ния БД. Первый этап проектирования - инфологическое моделирование. Чтобы спроектировать структуру БД, необходима исходная информация о предметной области. Желательно, чтобы эта информация была представлена в формализованном виде. Описание предметной области, выполненное без ориентации на используемые в дальнейшем программные и технические средства, называется инфологическоймоделью предметнойобласти (ИЛМ). На втором этапе проектирования на основе инфологической модели строится даталогическаямодель БД (ДЛМ). Даталогическаямодель является моделью логического уровня и представляет собой отображение логических связей между элементами данных безотносительно к их содержанию и среде хранения. Модель строится в терминах информационных единиц, допустимых в той конкретной СУБД, в среде которой проектируется БД. Этап создания ДЛМ называется даталогическим проектированием. Описание логической структуры БД на языке СУБД называется схемой. Третий этап проектирования состоит в привязке ДЛМ к среде хранения с помощью модели данных физического уровня ( физическоймодели ). Описание физической структуры БД называется схемой хранения, соответствующий этап проектирования БД – физическим проектированием. В ряде СУБД, помимо описания общей логической структуры БД, есть возможность описать логическую структуру БД с точки зрения конкретного пользователя. Такая модель называется внешней, а ее описание называется подсхемой. Внешняя модель не всегда является точным подмножеством схемы. Если определена подсхема, то пользователь имеет доступ только к тем данным, которые отражены в соответствующей подсхеме, что является одним из способов защиты информации от несанкционированного доступа. Взаимосвязь этапов проектирования БД отражена на рис. 3.1. Из рисунка видно, что при проектировании БД возможны возвраты на предыдущие уровни. При этом есть возвраты, обусловленные необходимостью пересмотра результата проектирования, и есть возвраты, вызванные необходимостью уточнения предыдущей модели (обычно инфологической) с целью получения дополнительной информации для проектирования или при выявлении противоречий в модели.
Рис. 3.1. Взаимосвязь этапов проектирования БД
3.2. Общие сведения об инфологическом моделировании
Уточним понятие ИЛМ. Для описания предметной области может использоваться и естественный язык, но его применение имеет много недостатков. Основные: громоздкость описания и неоднозначность трактовки. Поэтому для описания предметной области обычно используют искусственные формализованные языковые средства. В связи со сказанным уточним определение инфологической модели. Инфологической моделью предметной области называют описание предметной области, выполненное с использованием специальных языковых средств и не зависящее от используемых в дальнейшем программных и технических средств. Требования, предъявляемые к ИЛМ: · адекватность отображения предметной области (основное требование); · ИЛМ должна быть непротиворечивой; · ИЛМ является конечной, но должна обладать свойством легкой расширяемости (для обеспечения ввода новых данных без изменения ранее определенных; то же самое можно сказать и об удалении данных); · язык спецификации ИЛМ должен быть одинаково применим как при ручном, так и при автоматизированном проектировании информационных систем; · ИЛМ должна легко восприниматься разными категориями пользователей. Компоненты ИЛМ: 1) описание объектов и связей между ними (ER – модель); 2) описание информационных потребностей пользователей; 3) алгоритмические связи показателей; 4) лингвистические отношения; 5) ограничения целостности. ER – модель (Е (entity) – сущность, R (relationship) – связь) является центральной компонентой ИЛМ. Вопросы ее построения подробно рассматриваются в подраз- деле 3.3. Для описания информационных потребностей пользователей используются специальные языковые средства.
Описание предметной области всегда представлено в какой-то знаковой системе. Поэтому кроме отношений, присущих предметной области, возникают еще и отношения, обусловленные особенностями отображения предметной области в языковой среде. Поэтому при построении ИЛМ должны учитываться такие лингвистические категории, как синонимия, омонимия, изоморфизм и др. Важной компонентой ИЛМ являются ограничения целостности. Их рассмотрению посвящен восьмой раздел.
3.3. Построение ER - модели
Для описания ИЛМ используются как языки аналитического (описательного) типа, так и графические средства. Мы воспользуемся последними, как более наглядными. В предметной области в результате ее анализа выделяют классы объектов. Классомобъектов называют совокупность объектов, обладающих одинаковым набором свойств. Например, если в качестве предметной области рассмотреть высшее учебное заведение, то в данной предметной области можно выделить следующие классы объектов: учащиеся, преподаватели, аудитории, изучаемые дисциплины. Каждый объект в информационной системе представляется своим идентификатором, а каждый класс объектов представляется именем класса. Каждый объект обладает определенным набором свойств. Для объектов одного класса набор этих свойств одинаков, а их значения, естественно, различаются. Для изображения объектов и их свойств будем использовать следующие обозначения:
Связь между объектом и характеризующим его свойством будем изображать в виде линии. Связь может быть различной. Объект может обладать только одним значением какого-то свойства (например, каждый человек может иметь только одну дату рождения). Такие свойства будем называть единичным Популярное:
|
Последнее изменение этой страницы: 2016-07-13; Просмотров: 2219; Нарушение авторского права страницы








 Дерево представляет собой иерархию элементов, называемых узлами. Под элементами понимается совокупность атрибутов, описывающих объекты. В модели имеется корневой узел (корень дерева), который находится на самом верхнем уровне и не имеет узлов, стоящих выше него. У одного дерева может быть только один корень. Остальные узлы, называемые порожденными, связаны между собой следующим образом: каждый узел имеет только один исходный, находящийся на более высоком уровне, и любое число (один, два или более, либо ни одного) подчиненных узлов на следующем уровне.
Дерево представляет собой иерархию элементов, называемых узлами. Под элементами понимается совокупность атрибутов, описывающих объекты. В модели имеется корневой узел (корень дерева), который находится на самом верхнем уровне и не имеет узлов, стоящих выше него. У одного дерева может быть только один корень. Остальные узлы, называемые порожденными, связаны между собой следующим образом: каждый узел имеет только один исходный, находящийся на более высоком уровне, и любое число (один, два или более, либо ни одного) подчиненных узлов на следующем уровне.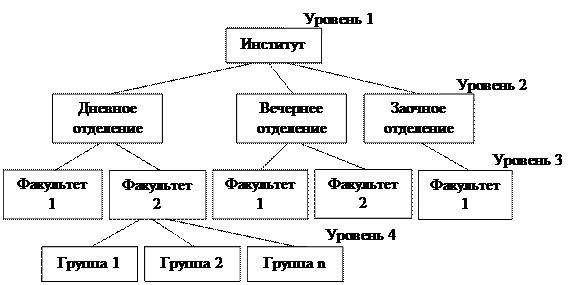 Примером простого иерархического представления может служить административная структура высшего учебного заведения: институт – отделение – факультет – студенческая группа (рис. 2.2).
Примером простого иерархического представления может служить административная структура высшего учебного заведения: институт – отделение – факультет – студенческая группа (рис. 2.2).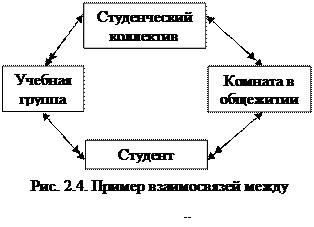



 Для отражения алгоритмических связей между показателями используются графы взаимосвязи показателей, отражающие, какие показатели служат исходными для вычисления других (рис. 3.2).
Для отражения алгоритмических связей между показателями используются графы взаимосвязи показателей, отражающие, какие показатели служат исходными для вычисления других (рис. 3.2).