|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Простые коды с проверкой на четность.Стр 1 из 5Следующая ⇒
Тема 2: Теория кодирования. Основные понятия.
Рассматриваемый канал передачи данных – дискретный. Данные передаются в виде двоичной информации (последовательность 0 и 1). Информация передается по каналу, подверженному случайным ошибкам. Задача кодирования – добавление к информационным символам дополнительных символов, чтобы принимающая сторона могла обнаружить и исправить ошибки.
2.1. Понятие
Классификация кодов: - блоковые коды; - древовидные коды.
Блоковые коды определяются над произвольным конечным алфавитом, состоящего из
Определение: Блоковый код мощности Если Скорость
Древовидные коды оперируют с бесконечными последовательностями информационных символов, поступающих со скоростью
Основные характеристики блоковых кодов: - длина блока - длина информационной части - минимальное расстояние
Понятие расстояния
Определение: Расстоянием по Хэммингу между двумя Пример: Пусть
Определение: Пусть
Пример: Код (3, 3) может быть описан как код (3, 3, 1), т.к. минимальное расстояние по Хэммингу в счетчиковой последовательности от 000 до 111 равно 1: Тема 3: Простейшие коды. Простые коды с проверкой на четность.
Высокоскоростные коды с плохими корректирующими характеристиками. К заданным
Пример: 000 – 000(0); 001 – 001(1); 010 – 010(1); 011 – 011(0); и т.д.
Это Минимальное расстояние кода равно 2. Никакие ошибки исправлены быть не могут. Используется только для обнаружения ошибок нечетной кратности.
Простые коды с повторением
Низкоскоростные коды с хорошими корректирующими характеристиками. Один информационный символ повторяется n раз.
Пример: 0 – 000; 1 – 111. Это
Коды Хэмминга
Данные коды позволяют исправлять одну ошибку. Описание кода: для каждого
Пусть дан код Хэмминга (7, 4, 3) для
Операция + означает сложение по модулю 2, т.е. 0+0=0, 0+1=1, 1+0=1, 1+1=1. Кодовое слово v для передачи по дискретному каналу представляет собой блок из 7 битов:
По мере поступления кодового слова получателю декодер канала на основе информационных и проверочных битов вычисляет значения битов синдрома
Такой синдром нацелен на обнаружения факта наличия только однократной ошибки. Возможные значения битов синдрома являются уникальными для всевозможных конфигураций однократной ошибки в пределах переданного кодового слова. В случае отсутствия ошибки в слове, декодер канала всегда вычисляет синдром равный нулю. Данное свойство кодов Хэмминга позволяет конструировать цифровую логику, которая по ненулевому значению синдрома способна произвести коррекцию ошибочного бита. Для этого необходимо, чтоб ненулевое значение синдрома
Размещение информационных и проверочных битов по адресам равным значениям синдрома
Тема 6. Линейные коды.
Совокупность всех наборов элементов поля длины n образует векторное пространство. Некоторое множество векторов длины n называется линейным блоковым кодом тогда и только тогда, когда оно является подпространством векторного пространства всех наборов длины n.
Метрики Хэмминга и Ли.
Вес Хэмминга вектора v, обозначаемый как w(v), определяется как число ненулевых компонент этого вектора. Расстояние Хэмминга между двумя векторами v1 и v2 равно числу компонент, которыми они отличаются:
Пример: q=2, n=5. Совокупность векторов: (00000) (10011) (01010) (11001) (00101) (10110) (01111) (11100) образует векторное пространство V1 (линейный двоичный код). Минимальный вес равен 2, следовательно, минимальное расстояние равно 2.
Вес Ли набора
где
Расстоянием Ли между двумя наборами длины n называется вес Ли разности этих наборов. При q=2 и q=3 расстояние Ли и расстояние Хэмминга совпадают; при q> 3 расстояние Ли между двумя наборами длины n больше или равно расстоянию Хэмминга между этими наборами.
Пример: q=5, n=6. Расстояние Ли между двумя наборами длины 6 A=(200234), B=(204000) равно весу набора, составленного из разностей соответствующих компонент по модулю 5: A-B=(001234). Тогда wL(A-B)=0+0+1+2+2+1=6.
Синдромное декодирование.
Предположим, что линейный код является нулевым пространством матрицы H размерности (
Теорема 4. Два вектора v1 и v2 принадлежат одному и тому же смежному классу тогда и только тогда, когда их синдромы равны. Доказательство: Два элемента группы v1 и v2 принадлежат одному и тому же смежному классу тогда и только тогда, когда
Поскольку для умножения матриц справедлив дистрибутивный закон, то
Таким образом, вектор Процесс декодирования может быть значительно упрощен за счет использования модифицированной таблицы декодирования. Таблица строится так, что в ней приводятся образующие смежных классов и синдромы для каждого из 2n-k смежных классов. После того как получен вектор, вычисляется его синдром. Затем то таблице отыскивается образующий смежного класса, являющийся предполагаемым набором ошибок и вычитается из полученного вектора. В результате образуется предположительно исходный кодовый вектор.
Пример:
(0000) 1011 0101 1110 (00) (1000) 0011 1101 0110 (11) (0100) 1111 0001 1010 (01) (0010) 1001 0111 1100 (10)
0101®1101®1101 (+) 1000 = 0101
Синдромное декодирование позволяет сократить объем памяти при декодировании. Так, для кода (100, 80) необходимо в случае декодировании по лидеру смежного класса 2100 входов, а в случае синдромного декодирования 220 входов.
Коды Хэмминга.
Двоичный код Хэмминга удобнее всего задавать при помощи его проверочной матрицы. Проверочной матрицей кода Хэмминга является матрица, столбцами которой являются все ненулевые наборы разрядности m. Пример:
Поскольку сумма любых двух столбцов этой матрицы не равна нулю и поскольку единственным отличным от нуля скаляром поля GF(2) является «1», то не существует ни одной нулевой линейной комбинации из двух столбцов матрицы H. Следовательно, нулевое пространство этой матрицы имеет минимальный вес равный 3, и является кодом, исправляющим все одиночные ошибки. Другие важные параметры кода Хэмминга: - длина кодового вектора: 2m-1; - число проверочных символов: m; - число информационных символов: Поскольку все Таким образом, код Хэмминга является совершенным. Линейный код, совокупность образующих смежных классов которого в точности совпадает с совокупностью всех последовательностей веса t или меньше, называется совершенным. Можно построить код Хэмминга любой длины n, Если выбрать матрицу H для наименьшего значения m, удовлетворяющего условию Добавлением к двоичному коду Хэмминга одного проверочного соотношения, проверяющего на четность совокупность всех символов кода можно получить код с минимальным весом, равным 4, т.е. так называемый расширенный код Хэмминга. Пример:
Декодирование такого кода осуществляется следующим образом:
Если проверка на четность дает «0», а хотя бы один из остальных проверочных символов равен «1», то обнаружена неисправимая ошибка.
Коды Рида-Маллера.
Достоинства: можно получить большое Хэммингово расстояние и легко поддаются декодированию. Для любых m и r< m существует код Рида-Маллера, для которого:
Рассмотрим следующую совокупность векторов над полем из двух элементов (0 и 1). Пусть V0 – вектор длины 2m, все компоненты которого равны 1, V1, V2, …, Vm – строки матрицы, столбцами которой являются все возможные двоичные наборы длины m. Определим следующим образом векторное произведение двух векторов:
Рассмотрим совокупность векторов, образованную произведениями векторов vi, взятых по два, три, четыре и т.д. вплоть до m.
v0 = ( 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 )
v4 = ( 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 ) v3 = ( 0 0 0 0 1 1 1 1 0 0 0 0 1 1 1 1 ) v2 = ( 0 0 1 1 0 0 1 1 0 0 1 1 0 0 1 1 ) v1 = ( 0 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1 )
v4v3 = ( 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 ) v4v2 = ( 0 0 0 0 0 0 0 0 0 0 1 1 0 0 1 1 ) v4v1 = ( 0 0 0 0 0 0 0 0 0 1 0 1 0 1 0 1 ) v3v2 = ( 0 0 0 0 0 0 1 1 0 0 0 0 0 0 1 1 ) v3v1 = ( 0 0 0 0 0 1 0 1 0 0 0 0 0 1 0 1 ) v2v1 = ( 0 0 0 1 0 0 0 1 0 0 0 1 0 0 0 1 ) v4v3v2= … v4v3v1= … v4v2v1= … v3v2v1= … v4v3v2v1= …
Код Рида-Маллера порядка r определяется как код, базисом которого являются вектор v0, v1, …, vm и все векторные произведения из r или меньшего числа этих векторов. Очевидно, что скалярное произведение двух векторов равно 0, если число единиц в векторном произведении четно и равно 1, если оно нечетно. Для любого вектора v v2=v. Единственным произведением, содержащим нечетное число единиц, является произведение всех векторов v1, …, vm. Векторное произведение любого вектора из базиса кода порядка r на любой вектор из базиса кода порядка m-r-1 является вектором из базиса кода порядка m-1 и в нем содержится четное число единиц. Таким образом, любой вектор, принадлежащий коду порядка r, ортогонален любому базисному вектору, являющемуся произведением m-r-1 или меньшего числа векторов v1, …, vm. Из этого также следует, что код Рида-Маллера порядка r является нулевым пространством матрицы, образованной векторами v0, v1, …, vm и всеми векторными произведениями этих векторов в количестве не более чем m-r-1, взятыми в качестве ее строк. Важнейшая особенность кодов Рида-Маллера состоит в том, что декодирование для них может быть проведено достаточно простым способом.
Пример: m=4, r=2, (16, 11) Информационные символы этого кода кодируются следующим вектором:
Задача состоит в том, чтобы определить значения a по полученному вектору, несмотря на возможные ошибки. Очевидно, что сумма первых четырех компонент как элементов поля из двух элементов (0 и 1) равна нулю для всех базисных векторов, за исключением v2v1. Таким образом, если ошибок не было, то:
В общем случае можно записать
может быть вычтено из полученного вектора. Тогда, если ошибок не было, останется вектор
так, что следующая совокупность коэффициентов может быть определена аналогичным путём:
Идентичные уравнения можно записать для a2, a3, a4. Если предположить, что ошибок не было, то
Этот вектор должен быть нулевым, если a0=0 и единичным, если a0=1, поэтому a0 нужно выбирать равным тому из этих элементов, который появляется в векторе чаще. Поскольку при такой системе декодирования могут быть исправлены все комбинации из Схему для определения того, суммы каких именно символов полученного вектора должны быть равны заданному информационному символу, можно описать следующим образом. Расположим символы в каждом из первоначальных векторов v1, …, vm, и назовем компоненту, соответствующую j-ому нулю в векторе vi, и компоненту, соответствующую j-ой единице в векторе vi, парными компонентами вектора vi. Тогда 2(m-1) сумм парных компонент vi используются для определения ai. Далее, каждая из 2(m-2) сумм четырех компонент, используемых для определения aij, образуется некоторыми двумя парными компонентами вектора vi и парными для этих уже выбранных компонент компонентами вектора vj. Аналогично каждое соотношение, определяющее aijk, представляет собой сумму некоторых парных компонент вектора vi плюс сумму компонент вектора vj, парных к этим компонентам, и сумму компонент вектора vk, парных к уже выбранным компонентам, так, что в каждой сумме получается всего 8 слагаемых. Этот процесс можно продолжить аналогичным образом. Пример: a3: v3=(0000111100001111)
a3=(b1+b5)=(b2+b6)=(b3+b7)=(b4+b8)=(b9+b13)=(b10+b14)=(b11+b15)=(b12+b16).
v3=(0000111100001111) v1=(0101010101010101)
Алгоритм Евклида.
Пусть даны числа 973 и 301. НОД: d-? 973 = 3 x 301 + 70 301 = 4 x 70 + 21 70 = 3 x 21 + 7 21 = 3 x 7 + 0
Так как число d является делителем 973 и 301, то оно должно быть делителем и остатка 70. Т.к. d – делитель 301 и 70, оно является делителем 21. Т.к. d – делитель 70 и 21, то оно является делителем 7. С другой стороны, 7 является делителем 21, 70, 301 и 973. Поэтому d=7. 7 = 70 - 3 x 21 = 70 – 3 x (301 – 4 x 70) = -3 x 301 + 13 x 70 = -3 x 301 + 13 x (973-3 x 301) = 13 x 973 – 42 x 301.
Теорема 1: Совокупность целых чисел образует идеал тогда и только тогда, когда она состоит из всех чисел, кратных некоторому целому числу.
Доказательство: Пусть r – наименьшее целое положительное число в идеале и s – любое другое целое число, принадлежащее идеалу. Тогда НОД этих чисел d принадлежит идеалу, потому что по определению идеала оба слагаемых в правой части соотношения (i.2) принадлежат идеалу, и, следовательно, их сумма также принадлежит идеалу. Так как r – наименьшее положительно число в идеале, то r≤ d. Поскольку r делится на d, то d≤ r. Следовательно, r=d и s делится на r, т.е. на r делиться любое целое число, принадлежащее идеалу. Наконец, любое число, кратное r, принадлежит идеалу по определению идеала. Идеал, который состоит из всех элементов, кратных одному из элементов кольца, называется главным идеалом, а кольцо, в котором каждый идеал главный, называется кольцом главных идеалов. Идеал, который состоит из всех чисел, кратных положительному целому числу m, обозначается через (m). Кольцо классов вычетов, образованное классами вычетов по идеалу (m), называется кольцом целых чисел по модулю m.
Теорема 2: Каждый класс вычетов по модулю m содержит либо 0, либо целое положительное число, меньшее m. Нуль является элементом идеала, а все остальные целые положительные числа меньше m, принадлежат различным классам вычетов. Доказательство: Если s – любой элемент некоторого класса вычетов, то поскольку
Теорема 3: Кольцо классов вычетов по модулю m является полем тогда и только тогда, когда m – простое число. Доказательство: Если m – не простое число, то m=rs для некоторых целых чисел r и s, которые не кратны m. Поэтому Теперь остается показать, что если m – простое число, то для каждого класса вычетов, кроме 0(идеала), существует обратный. Каждый такой класс вычетов содержит целое число s, которое меньше чем m и не равно 0. Поскольку 1 совпадает с обратным к ней элементом, можно предположить, что s> 1. Так как m по предположению – простое число, то наибольший общий делитель s и m должен быть равен либо m, либо 1. Но m> s, и, следовательно, s не может делиться на m. Поэтому НОД m и s равен 1. В силу соотношения (i.2): Построенные таким образом поля называются кратными полями или полями Галуа из p элементов GF(p).
Полиномиальные коды.
Определим полиномиальный (n, k)-код как множество всех многочленов степени n—1 или меньше, делящихся на g(x). Степень g(x) равна
то множество многочленов вида
образует (6, 3)-код. Заметим, что существует ровно восемь различных многочленов в соответствии с восемью различными способами выбора коэффициентов а0, а1, а2 в поле GF (2). Один из способов применения этого кода состоит в том, чтобы взять а0, а1, а2 в качестве информационных символов и выполнить соответствующие умножения. Результат будет
Устройство, производящее это умножение, показано на рис. 1. Хотя такой метод кодирования вполне пригоден, его недостаток состоит в том, что полученный код обычно оказывается несистематическим. (В данном примере код является систематическим в позициях 1, 5, 6; однако в общем случае это не так.) Полиномиальные (n, k)-коды обладают тем свойством, что их всегдаможно сделать систематическими в первых k позициях. В рассматриваемом примере положим
b0 = а0 , b2 = а0 + а1, b2 = а1 + а2.
Решив систему уравнений относительно ai и подставив результат в (*), получим кодовый многочлен вида
с(x) =b0 + b1 x +b2 x2+ (b1 + b2)x3 + (bo+b1)x4 + (bo+b1+b2)x5.
Рис. Схема для умножения произвольного многочлена ao+ a2x +a2x2 на g(x) = 1+x+x3
Например, выбрав последние три символа, получим c(x) = (b0 +b2) + (bo + b1 + b2)x + (b1 + b2)x2 + b0 x 3 + b1 x 4 + b2 x 5 (**) Такой выбор обычно оказывается более предпочтительным по причинам, которые скоро станут ясными. Очевидно, как построить кодер для каждого из систематических вариантов полученного кода. Вначале нужно выразить элементы ai в виде линейных комбинаций элементов bi, а затем использовать схему на рис. 1 для осуществления соответствующих умножений. Второй метод, который, по существу, является объединением этих двух шагов, состоит в следующем. Предположим, что умножаем многочлен b0 + b1 x + b2 x2 на x 3, получая b0 х3 + b1 х4 + b2 х5. Разделив полученный многочлен на 1 + х + х3, найдем частное (bo+ b2) + b1x + b2x2 и остаток (b0+b2) + (b0 + b1 + b2)x+ (b1 + b2)x2. Заметим, что, прибавив остаток к делимому, получим кодовое слово (**) в систематическом виде. Эта процедура состоит в применении алгоритма Евклида, согласно которому делимое = (частное) (делитель) + остаток. В случае общего (n, k)-кода предварительное умножение всегда производится на xn-k Степень остатка всегда меньше степени делителя, которая равна п — k. Поскольку кодируемая последовательность умножалась на xn-k, в делимое входят лишь члены степени, не меньшей п—k. Поэтому добавление остатка к частному не изменяет ни одного из членов в обоих многочленах. Выбирая в качестве делителя порождающий многочлен, можно добиться того, что результатом всегда будет кодовое слово.
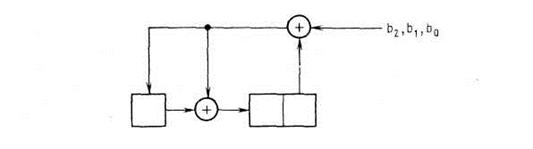
Рис. Схема для одновременного умножения на х3 и деления на 1+x+x3
Схема, реализующая этот алгоритм для (6, 3)-кода, показана на рис. 2. При использовании этой схемы последовательность b2, b1, b0 подается на вход по одному символу за такт. Содержимое различных ячеек после каждого сдвига показано на рис. 2. После трех сдвигов остаток (три проверочных символа) запоминается в трех ячейках регистра сдвига. Произведя длинные операции деления, можно удостовериться в том, что согласно этой схеме операции сдвига и вычитания повторяются на каждом шаге. При необходимости частное может быть получено в виде последовательных членов в цепи обратной связи.
Рис. Регистр обратной связи и соответствующая последовательность состояний при поступлении на вход одного символа 1 Полезной может оказаться еще одна точка зрения. Сделаем, чтобы схема, изображенная на рис. 2, начала работать таким образом, чтобы в самой левой ячейке появился символ 1. Производя в схеме несколько сдвигов и не подавая ничего на ее вход, будем получать содержимое регистров, показанное на рис. 3. Можно заметить, что полученные тройки совпадают со столбцами проверочной матрицы, и если остановиться после семи шагов, то полученная матрица будет совпадать с проверочной матрицей (7, 4)-кода Хемминга. Сделав меньше семи шагов, получим проверочную матрицу укорочения этого кода. Заметим также, что, произведя больше семи сдвигов, получим уже встречавшиеся тройки. Полученную матрицу по-прежнему можно рассматривать как проверочную матрицу кода, однако кодовое расстояние теперь уменьшилось до 2, поскольку один и тот же столбец повторился несколько раз. Работу согласно схеме на рис. 2 можно также рассматривать с помощью порождающей матрицы. Порождающая матрица (7, 4)-кода Хемминга имеет вид
Если подать на вход символ 1 и сделать один сдвиг, то в соответствующих ячейках появится набор 1 1 0. После второго сдвига появится набор 0 11, после третьего 1 1 1 и после четвертого 1 0 1. Эти четыре тройки совпадают с четырьмя строками проверочной части порождающей матрицы. При вводе в регистр последовательности 1 0 0 0 (начиная с самого правого символа) получим проверочную последовательность 1 1 0. Аналогично при вводе в регистр последовательности 0 0 0 1 появятся проверочные символы 101. Кроме того, рассматриваемое устройство является линейным, так что при вводе в регистр последовательности 1 0 0 1 результатом будет 0 11. Эти проверочные символы возникают при сложении первой и четвертой строк порождающей матрицы.
Циклические коды.
При некоторых значениях п полиномиальные коды обладают свойством цикличности. Это значит, что циклическая перестановка
Заметим прежде всего, что 1+x+x3 точно делит многочлен 1—х7. Это можно проверить непосредственным делением или с помощью схемы на рис. 3. Напомним, что эта схема порождает цикл длиной 7. Поэтому, если подать на вход символ 1, осуществить сдвиг семь раз и затем подать еще один символ 1 (т.е. разделить х7—1), второй входной символ сократит содержимое регистра и в качестве остатка получится нулевой многочлен. Предположим теперь, что взято кодовое слово (7, 4)-кода, порожденного многочленом 1 + х + х3, и сдвинуто циклически на один элемент вправо. Это значит, что каждый символ передвинут на одно место вправо и самый правый символ переведен на левый конец. Математически это эквивалентно умножению на х и замене х7 на 1, т. е. приведению многочлена по модулю х7—1. Предположим, что выбрано кодовое слово, самый правый символ которо-го) равен 1. Это кодовое слово может быть записано в виде с(х) = (1+ х + х3)р(х), где р(х) — многочлен степени 3. Тогда хс(х)≡ хс(х) — (х7—1) тоd (х7 — 1). Поскольку х7—1 делится на 1 + х + х3, многочлен в правой части этого равенства очевидно делится на 1+х+х3. Поэтому циклический сдвиг данного кодового слова снова дает кодовое слово. Заметим, что если самый правый символ кодового слова равен 0, то циклический сдвиг эквивалентен умножению на х и наше утверждение по-прежнему справедливо. Популярное:
|
Последнее изменение этой страницы: 2016-07-13; Просмотров: 3982; Нарушение авторского права страницы
 -кодов
-кодов 
 символов
символов  .
.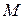 над алфавитом из
над алфавитом из 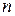 , называемых кодовыми словами.
, называемых кодовыми словами.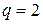 , то символы называются битами. Обычно
, то символы называются битами. Обычно 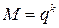 .
.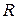 блокового кода определяется равенством:
блокового кода определяется равенством: 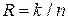 .
.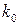 символов за один интервал времени. Это отображается в непрерывную последовательность символов кодового слова со скоростью
символов за один интервал времени. Это отображается в непрерывную последовательность символов кодового слова со скоростью 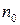 символов за один интервал времени (кадр). При этом скорость кода вычисляется как
символов за один интервал времени (кадр). При этом скорость кода вычисляется как 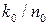 .
.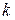 ;
; 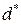 .
. и
и 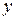 длины
длины  .
.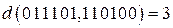 . Пусть
. Пусть  .
. – код. Тогда минимальное расстояние
– код. Тогда минимальное расстояние 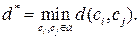
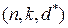 -кодом.
-кодом.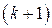 -й бит так, чтобы полное число единиц в кодовом слове было четным (нечетным) (это есть бит проверки на четность (нечетность)).
-й бит так, чтобы полное число единиц в кодовом слове было четным (нечетным) (это есть бит проверки на четность (нечетность)).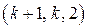 -код или
-код или 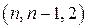 -код.
-код.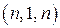 -код. Минимальное расстояние
-код. Минимальное расстояние 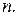 Может быть исправлено
Может быть исправлено 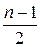 ошибок.
ошибок.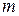 существует
существует 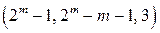 -код Хэмминга. При больших
-код Хэмминга. При больших 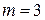 . Его можно описать при помощи следующей реализации. При заданных четырех информационных битах
. Его можно описать при помощи следующей реализации. При заданных четырех информационных битах 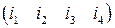 вычисляются три проверочных бита согласно следующим равенствам:
вычисляются три проверочных бита согласно следующим равенствам: 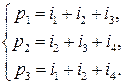
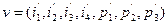 .
.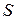 :
: 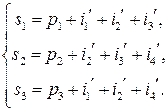
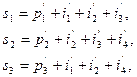
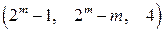 -коды. В отличие от обычных кодов добавляется еще один дополнительный разряд проверки на четность. Такие коды позволяют корректировать однократные ошибки и обнаруживать двукратные и ошибки нечетных кратностей.
-коды. В отличие от обычных кодов добавляется еще один дополнительный разряд проверки на четность. Такие коды позволяют корректировать однократные ошибки и обнаруживать двукратные и ошибки нечетных кратностей.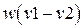 . Если v1 и v2 являются кодовыми словами линейного кода, то разность
. Если v1 и v2 являются кодовыми словами линейного кода, то разность 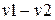 также должна быть кодовым словом, т.к. множество всех кодовых слов есть векторное пространство. Следовательно, расстояние между двумя кодовыми векторами равно весу некоторого третьего кодового вектора, и минимальное расстояние для линейного кода равно минимальному весу его ненулевых векторов.
также должна быть кодовым словом, т.к. множество всех кодовых слов есть векторное пространство. Следовательно, расстояние между двумя кодовыми векторами равно весу некоторого третьего кодового вектора, и минимальное расстояние для линейного кода равно минимальному весу его ненулевых векторов. длины n, где элементы ai выбираются из множества
длины n, где элементы ai выбираются из множества  , а q – произвольное положительное число, определяется как:
, а q – произвольное положительное число, определяется как:  ,
, 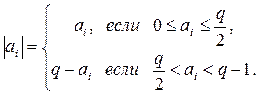
 )*n. Для любого любого полученного на выходе вектора v вектор
)*n. Для любого любого полученного на выходе вектора v вектор 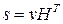 с
с 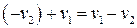 есть элемент подгруппы, которой в данном случае является кодовое векторное пространство. Если кодовое пространство – это нулевое пространство матрицы H, то вектор
есть элемент подгруппы, которой в данном случае является кодовое векторное пространство. Если кодовое пространство – это нулевое пространство матрицы H, то вектор 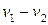 принадлежит кодовому пространству тогда и только тогда, когда
принадлежит кодовому пространству тогда и только тогда, когда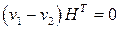 .
. .
.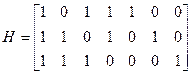
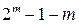 /
/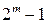 векторов, задающих одиночные ошибки принадлежат различным смежным классам, то этими смежными классами и кодовым пространством исчерпываются все 2m смежных классов.
векторов, задающих одиночные ошибки принадлежат различным смежным классам, то этими смежными классами и кодовым пространством исчерпываются все 2m смежных классов.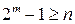 , а затем отбросить все лишние столбцы, оставив n столбцов. При этом можно выбрать столбцы таким образом, чтобы получился квазисовершенный код.
, а затем отбросить все лишние столбцы, оставив n столбцов. При этом можно выбрать столбцы таким образом, чтобы получился квазисовершенный код.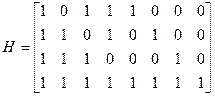 .
.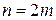 – разрядность кодового вектора,
– разрядность кодового вектора,  – число информационных бит,
– число информационных бит, 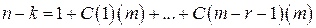 – число проверочных бит,
– число проверочных бит, 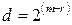 – минимальный вес кодового слова.
– минимальный вес кодового слова.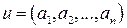 ,
, 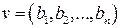
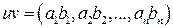 .
.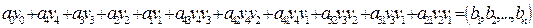
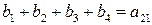
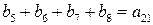
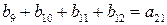
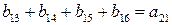
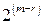 независимых соотношений. Ошибки могут сделать некоторые из этих соотношений несправедливыми, но каждая ошибка влияет только на одно из соотношений. Следовательно, если выбрать a21 равным величине, появляющейся наиболее часто в выражениях, то при любой комбинации из
независимых соотношений. Ошибки могут сделать некоторые из этих соотношений несправедливыми, но каждая ошибка влияет только на одно из соотношений. Следовательно, если выбрать a21 равным величине, появляющейся наиболее часто в выражениях, то при любой комбинации из  или меньшего числа ошибок значение a21 будет декодировано правильно. Аналогичным образом определяются a31, a32, a41, a43. После того как они определены, выражение
или меньшего числа ошибок значение a21 будет декодировано правильно. Аналогичным образом определяются a31, a32, a41, a43. После того как они определены, выражение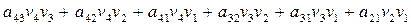
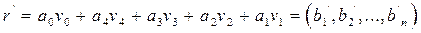 ,
, 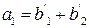
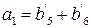

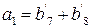

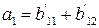
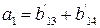
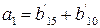
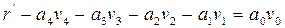 .
.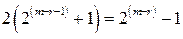 , а так как все кодовые векторы имеют четный вес, то оно должно быть равно самое меньшее
, а так как все кодовые векторы имеют четный вес, то оно должно быть равно самое меньшее 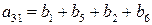
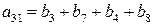
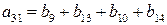
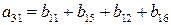
 , r – принадлежит тому же самому классу вычетов и
, r – принадлежит тому же самому классу вычетов и 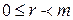 . Если r и s принадлежат одному и тому же классу вычетов, то разность r-s является элементом идеала, и, следовательно, кратна m. Если r≠ s то, очевидно, эти числа не могут быть оба меньше чем m и неотрицательны.
. Если r и s принадлежат одному и тому же классу вычетов, то разность r-s является элементом идеала, и, следовательно, кратна m. Если r≠ s то, очевидно, эти числа не могут быть оба меньше чем m и неотрицательны. , и если класс вычетов {r} обладает обратным
, и если класс вычетов {r} обладает обратным 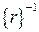 , то
, то  , что противоречит предположению. Поэтому класс вычетов {r} не может иметь обратного и кольцо классов вычетов не является полем.
, что противоречит предположению. Поэтому класс вычетов {r} не может иметь обратного и кольцо классов вычетов не является полем. . И отсюда следует, что
. И отсюда следует, что  , т.е. класс вычетов {b} является обратным к классу вычетов {s}.
, т.е. класс вычетов {b} является обратным к классу вычетов {s}.

 .
.