|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Поиск информации в World Wide Web
Интернет имеет три функции: коммуникационную, информационную и управленческую. Разные службы могут обеспечивать разные функции. Хотя в рамках службы World Wide Web есть сервисы, исполняющие коммуникационные и управленческие функции, основное назначение этой службы — информационное. Когда нам нужно разыскать какие-то сведения, мы обращаемся за данными в первую очередь в информационное пространство Web. Это пространство отличается гигантскими размерами. На момент написания данной книги в нем представлено более двух миллиардов Web-документов. Найти среди них именно то, что нужно, — это особая, отнюдь не простая задача. Разумеется, можно пользоваться рекомендациями знакомых, коллег по работе, адресами URL, опубликованными в средствах массовой информации, но службе WWW совершенно необходимы свои поисковые сервисы, и они существуют. Эти сервисы работают бесплатно. Экономическую основу их деятельности обеспечивает высочайший (по сравнению с другими сервисами) коэффициент возврата клиентов, о решающей роли которого для электронной коммерции рассказано в главе «Информационные технологии электронной коммерции». Поисковая система представляет собой специализированный Web-узел. Пользователь сообщает поисковой системе данные о содержании искомой Web-страницы, а система выдает ему список гиперссылок на страницы, соответствующие запросу. Существует несколько моделей, на которых основана работа поисковых систем, но исторически две модели приобрели наибольшую популярность — это поисковые каталоги и поисковые указатели.
Поисковые каталоги Поисковые каталоги устроены по тому же принципу, что и тематические каталоги крупных библиотек. Обратившись к поисковому каталогу, мы находим на его основной странице сокращенный список крупных тематических категорий, например таких, как Экономика и предпринимательство (Business & Economy), как показано на примере поискового каталога Yahoo! (рис. 7.6).
Рис. 7.6. Основная страница поискового каталога Yahoo!
Каждая запись в списке категорий — это гиперссылка. Щелчок на ней открывает следующую страницу поискового каталога, на котором данная тема представлена подробнее, например по предметам: Предпринимательское право, Защита прав потребителей, Экономические показатели и индикаторы рынка, Реклама и маркетинг, Электронная коммерция и мн. др. Щелчок на названии темы (например Электронная коммерция) открывает страницу со списком разделов (Электронные платежные системы, Интернет-магазины, Налогообложение предприятий электронной коммерции, Программное обеспечение и т. д.). Продолжая погружение в тему, можно дойти до списка конкретных Web-страниц и выбрать себе тот ресурс, который лучше подходит для решения задачи. Работа с поисковыми каталогами интуитивно проста. В них поиск информации практически всегда завершается более или менее плодотворно. Однако за этой простотой скрывается высочайшая сложность создания и ведения каталога. Поисковые каталоги создаются вручную. Высококвалифицированные редакторы лично просматривают информационное пространство WWW, отбирают то, что по их мнению представляет общественный интерес, и заносят адреса в каталог. Крупнейшим поисковым каталогом мира является каталог Yahoo! (www.yahoo.com). Его обслуживают порядка 150 редакторов, но и при этом общий объем каталогизированных Web-ресурсов составляет чуть более миллиона Web-страниц, то есть менее десятой доли процента от всех ресурсов WWW. Несмотря на столь низкий коэффициент охвата, поисковые каталоги пользуются огромной популярностью. Их принято использовать для первичного, реферативного поиска информации по заданной теме. Если для пользователя тема является совершенно новой и неисследованной, то он вряд ли нуждается в расширенных результатах поиска. Прежде всего ему нужны указатели на классические, наиболее содержательные ресурсы, а именно это и обеспечивают поисковые каталоги. Человеческий фактор, связанный с тем, что над составлением каталога работают люди, а не программы, обеспечивает качественный отбор наиболее важных ресурсов по каждой из тем. Количество поисковых каталогов в мире сравнительно невелико. Это связано с высокой трудоемкостью их содержания и обслуживания, а также с недостатком квалифицированных кадров редакторов. Крупнейший поисковый каталог мира мы уже назвали, а крупнейший поисковый каталог России — «Атрус» (atrus.aport.ru)
Поисковые указатели
Основной проблемой поисковых каталогов является чрезвычайно низкий коэффициент охвата ресурсов WWW. И хотя для реферативного поиска это не выглядит критичным, все-таки существуют потребности в поиске актуальной, уникальной, специальной информации, которая не охвачена и не может быть охвачена поисковыми каталогами. Чтобы многократно увеличить коэффициент охвата ресурсов Web, из процесса наполнения базы данных поисковой системы необходимо исключить человеческий фактор — работа должна быть автоматизирована. Разумеется, при этом значительно падает качество ссылок, предоставляемых системой по результатам поиска, но одновременно увеличивается их количество. Автоматическую каталогизацию Web-ресурсов и удовлетворение запросов клиентов выполняют так называемые поисковые указатели. Основной принцип работы поискового указателя заключается в поиске Web-ресурсов по ключевым словам. Пользователь описывает искомый ресурс с помощью ключевых слов, после чего дает задание на поиск. Поисковая система анализирует данные, хранящиеся в своей базе, и выдает список Web-страниц, соответствующих запросу. Вместе с гиперссылками выдаются краткие сведения о найденных ресурсах, на основании которых пользователь может выбрать нужные ему ресурсы (рис. 7.7). Сегодня в мире существует около 10 тысяч поисковых указателей. Вершину списка занимают около двух десятков зарубежных систем: AltaVista (www.atavista.com), Excite (www.excite.com), Fast Search (www.alltheweb.com), Go/Infoseek (www.go.com), GoTo (www.goto.com), Google (www.google.com), HotBot (hotbot.lycos.com), Inktomi (www.inktomi.com), Lycos (www.lycos.com), Netscape Search (search.netscape.com), Northern Light (www.northernlight.com), WebCrawler (www.webcrawler.com) и другие. В России также имеется несколько поисковых указателей, из которых наиболее крупными и популярными являются следующие: «Апорт 2000» (www.aport.ru), «Яndех» (www.yandex.ru) и «Рэмблер» (www.rambler.ru). Разные поисковые указатели могут использовать разные информационные технологии для обработки запросов пользователей. Чтобы эффективно выполнять поиск информации в WWW, надо представлять достоинства и недостатки каждой из систем и хотя бы в общих чертах понимать принципы их работы.
Рис. 7.7. За сотую долю секунды поисковый указатель Fast Search отобрал более миллиона Web-страниц, посвященных электронной коммерции Три этапа работы поискового указателя. Работу поискового указателя можно условно разделить на три этапа. Из них два этапа являются подготовительными — они незаметны для клиента, и лишь на третьем этапе происходит взаимодействие с пользователем, но от каждого из этапов зависят функциональные свойства поисковой системы и эффективность работы с ней. Сбор первичной базы данных. На первом этапе поисковая система занимается сканированием информационного пространства World Wide Web. Для этого используют специальные агентские программы — черви. Не следует путать агентов поисковых систем с разновидностью сетевых компьютерных вирусов, тоже именуемых червями. Черви поисковых систем совершенно безобидны для серверов и клиентов WWW. По своей сути это очень эффективные малоразмерные броузеры. Им не надо выполнять функции просмотра и воспроизведения содержимого — их задача состоит только в том, чтобы автоматически разыскивать в Сети Web-ресурсы, следуя по гиперссылкам, и, убедившись, что этот ресурс системе еще не известен, копировать его в свою базу данных. Так же происходит и обновление ранее принятых документов, но измененных за время после предыдущего копирования. От эффективности работы поискового червя во многом зависит содержательная часть поискового указателя. Каждая система использует собственную поисковую программу и хранит в тайне алгоритм ее работы от конкурентов. Индексация базы данных. Собранная база данных сетевых Web-ресурсов — это хорошая, но не достаточная основа для функционирования поисковой системы. С ее помощью уже можно обслуживать запросы клиентов, но нельзя делать это быстро. Поиск ключевых слов, введенных пользователем, в обширной базе — это весьма продолжительная операция. Нежелательно задерживать клиента более чем на доли секунды, поэтому собранные базы данных проходят предварительную обработку, называемую индексацией. На этапе индексации создаются специализированные документы — поисковые указатели. С простейшим указателем вы знакомы по работе с учебными пособиями. Нередко в конце книг приводится предметный указатель, с помощью которого можно по термину быстро найти страницу книги, на которой этот термин раскрывается. Аналогично устроены и поисковые указатели. Простейший тип поискового указателя называется обратным файлом. Это просто словарь, в который входят все слова, встреченные при просмотре Web-ресурсов. Против каждого слова приводится список ссылок, указывающих на местоположение соответствующих ресурсов в базе данных. При получении списков ключевых слов от пользователя просмотр поискового указателя происходит очень быстро, так как он предварительно отсортирован по алфавиту. В результате клиент достаточно быстро получает список ссылок с интересующими его Web-ресурсами. Рафинирование результирующего списка. Это третий этап работы, в ходе которого осуществляется взаимодействие с пользователем. На этом этапе создается список ссылок, который будет передан пользователю в качестве результирующего. Пользовательское представление о качестве работы поисковой системы напрямую зависит от технологий, использованных на этом этапе. Рафинирование результирующего списка заключается в фильтрации и ранжировании результатов поиска. Под фильтрацией понимается отсев ссылок, которые выдавать пользователю нецелесообразно. Прежде всего проверяется наличие дубликатов. Если система в одном списке выдает множество ссылок, ведущих к одному и тому же Web-ресурсу, это говорит о том, что ее средства добросовестно отработали два первых этапа, но ничего не сделали на третьем этапе. Дублирующиеся ссылки перегружают результирующий список и затрудняют выбор действительно полезных ресурсов. Ранжирование заключается в создании специального порядка представления результирующего списка, при котором наиболее «полезные» (с точки зрения поисковой системы) ссылки приводятся в вершине списка, а наименее полезные — в его конце. Понимание критерия «полезности» для клиента той или иной ссылки может быть самым разнообразным. Именно поэтому разные поисковые системы, даже работающие с одинаковыми базами ресурсов, выдают разные результаты поиска. Прежде всего, при ранжировании учитывается количество появлений ключевых слов в Web-документе. Принцип «чем больше, тем лучше» достаточно очевиден, но не слишком корректен. На самом деле хорошо, когда искомое слово появляется достаточно часто в начале документа, в его первых 5-10 абзацах, а прочие части документа учитываются меньше. Очень хорошо, когда ключевые слова встречаются в заголовках документа и в подрисуночных подписях. Интеллектуальные системы могут проверять также наличие сопутствующих слов. Так, например, по результатам анализа содержимого множества Web-страниц, выполненного еще на этапе индексации, может быть установлено, что словам электронная коммерция очень часто сопутствуют слова цифровая подпись и платежные системы. Если поисковая система об этом знает, то, получив от клиента запрос на поиск по словам электронная коммерция, она в вершине списка расположит те Web-страницы, на которых также встречаются упоминания о цифровой подписи и о платежных системах. Всюду, где можно, автоматические системы стремятся полагаться на «человеческий фактор». Автоматической системе сделать это непросто, но специальные технологии имеются. Так, например, еще на этапе индексации высокий рейтинг могут получать те страницы, на которые имеется больше ссылок с других Web-страниц. Поскольку гиперссылки создают люди, а не машины, то этот факт можно использовать в качестве субъективной оценки более высокой «полезности» тех документов, которые чаще цитируются. В рамках этой книги мы не можем охватить все те приемы, которые используют поисковые системы на этапе формирования результирующего списка, но роль этого этапа трудно переоценить. Попробуйте работу с несколькими поисковыми системами и посмотрите, как у них обстоит дело с фильтрацией и ранжированием результатов. Вы, наверное, заметите, что тщательная фильтрация и разумное ранжирование воспринимаются потребителем как показатель качества работы системы.
Основные проблемы современных поисковых указателей
Большинство крупнейших поисковых указателей мира в настоящее время находятся в кризисном состоянии. У общего кризиса поисковых систем есть ряд объективных причин. Все они связаны с объективными противоречиями, возникающими в ходе развития World Wide Web. В разных странах эти кризисные явления проявляются по-разному. Забегая вперед, скажем, что для российских поисковых систем эти проблемы пока незаметны. Основным противоречием, определяющим кризисную ситуацию в поисковых системах, является несоответствие динамики развития информационного пространства Web и самих поисковых систем. На ранних этапах, когда поисковые системы еще только формировались в виде лабораторных проектов, коэффициент охвата Web-ресурсов достигал 50%. В 1994 г. количество Web-ресурсов составляло немногим более 100 млн Web-страниц, из которых десятки миллионов были проиндексированы. К 1999 г. коэффициент охвата упал примерно до 30%, а в 2000 г. не превышает 20%, причем с каждым днем он продолжает падать. Пространство Web развивается усилиями десятков миллионов людей, и несколько поисковых систем просто не успевают его индексировать. Второе противоречие — чисто экономическое. На рубеже 1997-1998 гг. развитие информационного пространства Web достигло таких масштабов, что для его индексации потребовалось привлекать намного более мощные аппаратные, программные и кадровые ресурсы, чем ранее. В этот же период интересы крупных инвесторов начали обращаться к информационным службам Интернета. В результате произошло акционирование ряда поисковых систем. Это повлияло на характер их работы, поскольку администрации поисковых систем были вынуждены сосредоточиться не столько на индексации бурно растущего Web-пространства, сколько на обеспечении интересов акционеров. Ряд крупных поисковых систем начали после 1997 г. искусственно тормозить индексацию Web-ресурсов и сосредоточились на коммерческой стороне деятельности. По сути, многие из популярных в прошлом поисковых систем превратились сегодня в удобные и красивые Web-порталы, но с задачами научного поиска справляются неудовлетворительно. По мере роста WWW наметились и противоречия, связанные с интересами клиентов. Их уже не устраивают исчерпывающие списки гиперссылок, ведущих к нужным Web-ресурсам. Когда поисковая система выдает слишком много ссылок, воспользоваться ими столь же трудно, как когда она выдает их слишком мало. Клиенту нужно столько ссылок, сколько он в состоянии охватить, причем ему желательны «самые лучшие» ссылки. Это также притормозило в последние два года работы по индексации Web. Некоторые поисковые системы вообще прекратили заниматься сбором информации и ее анализом. Вместо этого они переадресуют запросы клиентов другим поисковым системам, хорошо оснащенным технически, а сами сосредотачиваются только на третьем этапе — фильтрации и ранжировании полученных результатов. Так, например, многие поисковые системы опираются на поисковую систему Inktomi (www.inktomi.com), которая выполняет поисковые операции по заказу других поисковых систем. Выше мы сказали, что кризисные явления пока не затронули отечественные поисковые системы. Это действительно так, и связано с тем, что российские поисковые системы используют технологии 2000 г., работая с информационным пространством всего лишь в несколько десятков миллионов Web-страниц, что примерно соответствует ситуации 1993 г. для стран Запада. Это дает российским поисковым системам хорошее преимущество и запас в несколько лет, прежде чем они столкнутся с кризисными явлениями.
Новейшие поисковые технологии Автоматическая каталогизация. Противоречие между размерами исследованного и неисследованного Web-пространства для поисковых каталогов еще острее, чем для поисковых указателей. Тем не менее, здесь есть перспективные направления развития. Они основаны на внедрении так называемых SMART-технологий автоматической каталогизации. Существует множество теоретических изысканий в области SMART-технологий, но наиболее перспективной является модель векторного информационного пространства. Представим себе эксперта в какой-то области, например в юриспруденции. Если ему поставить задачу, то, наверное, он сможет составить словари, характерные для таких областей, как Авторское право, Гражданское право, Уголовное право и т. п. Проанализировав множество документов, относящихся к этим научным областям, он сможет не только указать характерные термины и понятия, но и дать им весовые оценки. Так, например, достаточно очевидно, что слово «договор» имеет больший вес в документах гражданского права, чем уголовного. Комбинируя термины и весовые коэффициенты, можно строить многомерные системы координат, в которых различные области знания описывались бы разными многомерными векторами. Автоматически получив новую Web-страницу, поисковая система может построить для нее математический вектор, основанный на формальном анализе содержания. А сравнивая этот вектор с уже рассчитанными векторами для различных областей знания, система может без участия человека предположить, к какой категории, теме и разделу относится тот или иной документ. При таком подходе не обязательно хранить копии всех известных Web-страниц, как не надо хранить и их поисковые указатели. Вполне достаточно для каждого Web-документа хранить лишь его URL-адрес и число, соответствующее вектору. В настоящее время конкретные алгоритмы SMART-технологий не публикуются, поскольку представляют ноу-хау, но мы можем предположить, что они уже работают, например в поисковых системах реального времени, таких, как Alexa (www.alexa.com). Поисковые системы реального времени. Это новое направление в технологиях поиска информации мы рассмотрим на примере поисковой службы Alexa (www.alexa.com). Для работы с этой службой пользователь должен подключиться к ее центральному серверу, получить оттуда и установить на своем компьютере клиентскую программу. Эта программа подключается к броузеру и работает как дополнительная панель в окне Microsoft Internet Explorer или Netscape Navigator. При каждом запуске броузера клиентская программа устанавливает соединение со своим центральным сервером и далее работает с ним в паре. Она передает серверу копии всех Web-страниц, которые посещает пользователь, то есть выполняет те же функции, что и автоматический червь, копирующий Web-ресурсы на сервер традиционной поисковой системы. Однако при этом есть два существенных различия: · во-первых, человек в ходе навигации в WWW руководствуется не теми принципами, что автоматическая программа, поэтому сервер получает копии не всех Web-ресурсов, а только тех, что заинтересовали кого-то из его клиентов; · во-вторых, понятно, что когда поставкой Web-ресурсов занимаются несколько миллионов постоянных клиентов, то индексация Web-пространства происходит намного быстрее. В свою очередь, пользователь тоже имеет важное преимущество. На какой бы Web-странице он ни находился, система всегда готова предложить ему список других Web-страниц, имеющих близкое по тематике содержание. Она готовит этот список на основании предшествующего опыта, полученного в работе с другими людьми. Так можно получить рекомендации, которые было бы очень трудно (а зачастую и невозможно) разыскать в WWW традиционными поисковыми средствами. Работа с поисковой системой реального времени превращает обычную навигацию по Web-ресурсам в увлекательное интерактивное исследование (рис. 7.8).
Рис. 7.8. При просмотре Web-страницы Центра электронной коммерции Alexa предлагает ссылки на другие Web-страницы, тоже посвященные электронной коммерции
Рекомендации по приемам эффективного поиска
Для проведения реферативного поиска, когда тема задана достаточно широко, рекомендуется пользоваться поисковыми каталогами, такими, как Yahoo! (www.yahoo.com) или «Атрус» (atrus.aport.ru). Это позволит быстро установить местоположение основных первоисточников. При ознакомлении с первоисточниками следует прежде всего, уделять внимание понятийной базе. Знание основных понятий и терминов позволит перейти к углубленному поиску в поисковых указателях с использованием ключевых слов, наиболее точно характеризующих тему. При наличии первичных сведений по теме поиска, документы можно разыскивать в поисковых указателях. При этом следует различать приемы простого, расширенного, контекстного и специального поиска. Под простым поиском понимается поиск Web-ресурсов по одному или нескольким ключевым словам. Недостаток простого поиска заключается в том, что обычно он выдает слишком много документов, среди которых трудно выбрать наиболее подходящие. При использовании расширенного поиска ключевые слова связывают между собой операторами логических отношений. Расширенный поиск применяют в тех случаях, когда приемы простого поиска дают слишком много результатов. С помощью логических отношений поисковое задание формируют так, чтобы более точно детализировать задание и ограничить область отбора, например по дате публикации или по типу данных. Контекстный поиск — это поиск по точной фразе. Он удобен для реферативного поиска информации, но доступен далеко не во всех поисковых системах. Прежде всего, чтобы обеспечивать такую возможность, система должна работать не только с индексированными файлами, но и с полноценными образами Web-страниц. Эта операция достаточно медленная, и ее выполняют не все поисковые системы. Специальный поиск применяют при розыске Web-страниц, содержащих ссылки на заданные адреса URL, а также содержащих заданные данные в служебных полях, например в поле заголовка.
Рекомендации по использованию поисковых систем
Для проведения научных поисков, в частности по темам, относящимся к праву и экономике, рекомендуется пользоваться поисковой системой Northern Light (www.northernlight.com). Эта система имеет один из лучших коэффициентов охвата Web-пространства, и ее администрация прилагает специальные усилия для поддержания актуальности своих указателей. Кроме того, система удачно сочетает свойства поискового указателя и каталога. По наиболее популярным темам в ней можно найти специальные разделы каталожного типа — они называются Special Editions и подготавливаются вручную. Дополнительно система предоставляет платные услуги по поставке актуальных научных документов. Они находятся в разделе Special Collection. Самым большим поисковым указателем обладает поисковая система Fast Search (www.alltheweb.com). К моменту написания данной книги он охватывает более 400 млн. уникальных Web-страниц и очень быстро развивается. Всего за один год после запуска эта поисковая система вышла на первое место в мире по объему проиндексированного пространства, и, как предполагается, в течение 2001 г. первой достигнет психологического рубежа одного миллиарда уникальных Web-страниц. Исторически одной из наиболее популярных считается поисковая система Alta Vista (www.altavista.com), однако начиная с 1997 г. она отстает в динамике развития и все более ориентируется на коммерческие решения. Тем не менее, она по-прежнему считается одной из лучших для операций контекстного поиска, хотя в последние дни система Fast Search тоже начала предоставлять услуги контекстного поиска. В России в настоящее время действуют три примерно одинаковых по мощности поисковых указателя: «Апорт 2000» (www.aport.ru), «Рэмблер» (www.rambler.ru) и Яndех (www.yandex.ru). Все они обладают примерно одинаковым «знанием» о ресурсах российского сектора WWW и работают достаточно быстро. Систему «Апорт 2000» удобно использовать в операциях простого поиска — ее отличает особо внимательный подход к фильтрации и ранжированию результатов. В этой системе приняты специальные меры по устранению дубликатов, удалению неактуальных ссылок и наглядному представлению результатов поиска. Система «Рэмблер» по своей сути является не только поисковой, но и выполняет функции удобного Web-портала. Систему «Яndех» удобно использовать при формировании сложных поисковых заданий, поскольку она обладает наиболее гибким языком для расширенного поиска.
Практическое занятие
Упражнение 7.1. Настройка начальной страницы броузера Microsoft Internet Explorer
10 мин 1. Запустите программу Internet Explorer (Пуск → Программы → Internet Explorer). 2. Если сразу после запуска программа пытается загрузить какую-то Web-страницу, прервите загрузку щелчком на кнопке Стоп. По записи в строке Адрес установите URL-aдpec страницы, которую броузер использовал в качестве начальной. 3. Дайте команду Сервис → Свойства обозревателя. В открывшемся диалоговом окне Свойства обозревателя откройте вкладку Общие. 4. На панели Домашняя страница разыщите поле Адрес. По записи в этом поле установите URL-адрес страницы, которую броузер должен использовать в качестве начальной. 5. Щелкните на кнопке С пустой. Убедитесь, что в поле адреса начальной страницы появилась запись about: blank. Это говорит о том, что при последующих запусках программа не будет автоматически загружать никакую Web-страницу в качестве начальной. 6. Щелкните на кнопке Применить, после чего закройте диалоговое окно Свойства обозревателя щелчком на кнопке ОК. 7. Закройте окно программы. 8. Повторно запустите программу, как указано в п. 1. 9. Убедитесь, что после запуска программы не загружается никакая начальная страница, а в поле Адрес записано выражение about: blank. 10. Закройте окно программы.
► Мы научились настраивать броузер таким образом, чтобы он не выполнял загрузку начальной страницы при запуске. Это полезно, чтобы внешние загрузки не мешали нам заниматься другими настройками программы. Если в будущем понадобится задать начальную страницу, это можно будет сделать соответствующими настройками в диалоговом окне Сервис → Свойства обозревателя → Общие.
Упражнение 7.2. Настройка рабочего окна броузера Microsoft Internet Explorer
20 мин
В состоянии поставки броузер Microsoft Internet Explorer 5.0 рассчитан на работу с экраном, имеющим разрешение 1024 × 768 точек. Настройки панелей управления программы таковы, что если видеоподсистема компьютера имеет меньшее разрешение, то не все элементы управления могут отображаться в пределах рабочего окна. В этом упражнении мы научимся настраивать рабочее окно программы таким образом, чтобы с ним было удобно работать на компьютерах, имеющих экранное разрешение 800 × 600 и даже 640 × 480 точек. 1. Запустите программу Internet Explorer (Пуск → Программы → Internet Explorer). 2. Дайте команду Вид → Панели инструментов. В раскрывающемся меню убедитесь, что флажками отмечены только пункты Обычные кнопки и Адресная строка. Если отмечены другие пункты, сбросьте соответствующие флажки. 3. Дайте команду Вид → Панели инструментов → Настройка. Откроется диалоговое окно Настройка панели инструментов (рис. 7.9).
Рис. 7.9. Средства настройки панели инструментов Internet Explorer
4. В раскрывающемся списке Текст кнопки выберите пункт Без подписей к кнопкам. Это не помешает узнать назначение любой кнопки, поскольку при наведении на нее появляется всплывающая подсказка. 5. В раскрывающемся списке Размер значка выберите пункт Мелкие значки. 6. Сравните два списка: Имеющиеся кнопки и Панель инструментов. В списке Имеющиеся кнопки приведен список командных кнопок, которые можно отобразить на панели инструментов. В списке Панель инструментов приведен список кнопок, которые должны отображаться. Изменение состава кнопок выполняют с помощью командных кнопок Удалить и Добавить. 7. Удалите все «лишние» кнопки с панели инструментов, оставив только кнопки, связанные с навигацией в World Wide Web. Этих кнопок пять: Назад, Вперед, Остановить, Обновить и Журнал. 8. Закройте диалоговое окно Настройка панели инструментов щелчком на командной кнопке Закрыть. 9. Справа от панели Адрес разыщите кнопку Переход. Щелкните на ней правой кнопкой мыши и в открывшемся контекстном меню сбросьте флажок у пункта Кнопка «Переход». 10. Перетащите с помощью мыши (при нажатой левой кнопке) панель инструментов на правый край строки меню. Перетаскивание выполняется за рубчик, имеющийся на левом краю панели. В результате окно программы должно приобрести компактный вид, аналогичный представленному на рис. 7.10.
Рис. 7.10. «Компактное» окно Internet Explorer 11. Закройте окно программы Microsoft Internet Explorer.
► Мы научились настраивать окно броузера таким образом, чтобы с ним было удобно работать при низком экранном разрешении. Если понадобится восстановить настройки такими, какими они были заданы по умолчанию, это можно сделать командой Вид → Панели инструментов → Настройка → Сброс.
Упражнение 7.3. Настройка системы безопасности программы Microsoft Internet Explorer 5.0
Мин
1. Запустите программу Internet Explorer (Пуск → Программы → Internet Explorer). Если при запуске программы происходит автоматическая загрузка какой-либо Web-страницы, примите меры, как указано в упражнении 7.1. 2. Дайте команду Сервис → Свойства обозревателя — откроется диалоговое окно Свойства обозревателя. В этом окне выберите вкладку Дополнительно (рис. 7.11).
Рис. 7.11. Настройка системы безопасности броузера Internet Explorer
3. На вкладке Дополнительно сбросьте флажок Задействовать профиль — тогда программа не будет передавать сведения о личности пользователя по запросам удаленных серверов. 4. Там же сбросьте флажок Автоматически проверять обновления Internet Explorer, чтобы программа самостоятельно не обращалась к «своему» серверу без ведома пользователя. 5. Сбросьте флажок Использовать автозаполнение для веб-адресов. Функция автозаполнения позволяет посторонним лицам выяснять, куда обращался владелец системы. 6. Сбросьте флажок Разрешить счетчик попаданий на страницы. Этот счетчик связан с ведением на компьютере пользователя «журнала посещений», подконтрольного удаленным серверам, что далеко выходит за рамки стандартного протокола HTTP. 7. В разделе Поиск из панели адресов включите переключатель Не производить поиск из панели адресов. 8. Откройте вкладку Безопасность диалогового окна Свойства обозревателя. 9. Выберите зону Интернет и задайте настройку уровня безопасности для этой зоны с помощью кнопки Другой. Откроется диалоговое окно Правила безопасности. 10. В категории Java установите переключатель Отключить язык Java. 11. В категории Сценарии отключите все функции, установив переключатели Отключить. 12. В категории Файлы cookie установите переключатели Предлагать — тогда вы наглядно будете видеть, какие Web-узлы предлагают маркировать ваш компьютер своими метками. 13. Во всех разделах категории Элементы ActiveX и модули подключения включите переключатели Отключить. 14. Откройте вкладку Содержание диалогового окна Свойства обозревателя. 15. Щелкните на кнопке Автозаполнение — откроется диалоговое окно Настройка автозаполнения. В этом диалоговом окне отключите все функции автозаполнения. Очистите журнал автозаполнения с помощью кнопок Очистить формы и Очистить пароли. Закройте окно щелчком на кнопке ОК. 16. На вкладке Содержание диалогового окна Свойства обозревателя используйте командную кнопку Профиль — откроется диалоговое окно, в котором представлены персональные сведения о пользователе, известные программе. Проверьте эти сведения и убедитесь, что в них не содержится ничего лишнего. Подходите к ним, как к сведениям, сообщаемым кому попало. 17. Закройте открытые диалоговые окна. Завершите работу, с программой Internet Explorer.
► Мы научились выполнять первичные настройки броузера, связанные с безопасностью работы в Интернете. Обратите особое внимание на то, что они выполняются не только на вкладке Безопасность, но и на вкладках Дополнительно и Содержание.
Упражнение 7.4. Просмотр и сохранение Web-страниц
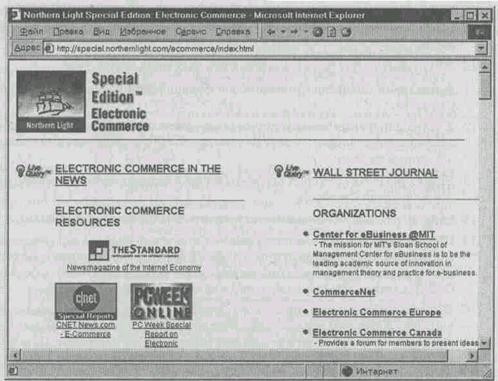
Мин 1. Подключитесь к Интернету с помощью программы Соединение удаленного доступа. 2. Когда значок работающего соединения появится на панели индикации, запустите программу Internet Explorer. 3. В поле адресной строки введите следующий URL-адрес: www.northernlight.com — произойдет загрузка титульной страницы поисковой системы Northern Light. 4. Разыщите на титульной странице раздел Special Editions и перейдите к нему щелчком на его гиперссылке. 5. В списке ссылок раздела Special Editions разыщите ссылку Electronic Commerce. Наведите на нее указатель мыши, щелкните левой кнопкой и перейдите в раздел, посвященный электронной коммерции. Просмотрите содержание раздела (рис. 7.12).
Рис. 7.12. Каталог ресурсов по электронной коммерции в поисковом указателе Northern Light
6. Двумя щелчками на кнопке Назад возвратитесь к титульной странице поисковой системы. 7. Двумя щелчками на кнопке Вперед вернитесь в раздел электронной коммерции. 8. Не закрывая окно броузера, на панели индикации щелкните правой кнопкой мыши на значке установившегося соединения. В открывшемся контекстном меню выберите пункт Отключиться — соединение с Интернетом будет разорвано. 9. Двумя щелчками на кнопке Назад возвратитесь к ранее просмотренным страницам, а потом двумя щелчками на кнопке Вперед вернитесь назад. Сделайте вывод о том, что, несмотря на отсутствие соединения с Интернетом, навигация по ранее принятым Web-страницам возможна. Такой режим работы называется автономным. В данном случае его возможность связана с тем, что принятые Web-страницы еще находятся в оперативной памяти компьютера. 10. Сохраните текущую Web-страницу на жестком диске. Для этого дайте команду Файл → Сохранить как — откроется диалоговое окно Сохранение веб-страницы. Здесь можно ввести содержательное имя для сохраняемой страницы, например Ресурсы по электронной коммерции. В качестве типа файла выберите Веб-страница полностью. В этом случае страница сохранится вместе со всеми встроенными элементами оформления, например рисунками. Реально сохраняется один файл (HTML) и одна связанная с ним папка. В файле содержится код Web-страницы, размеченный тегами HTML, а в папке — файлы встроенных объектов. Популярное:
|
Последнее изменение этой страницы: 2017-03-09; Просмотров: 841; Нарушение авторского права страницы