
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Взаимосвязь эконометрики с экономической теорией, статистикой и экономико-математическими методамиСтр 1 из 16Следующая ⇒
Дисциплина «ЭКОНОМЕТРИКА» Для студентов-заочников дистанционной формы обучения
Текст лекций
Арженовский С.В., Федосова О.Н.
Учебное пособие
Ростов-на-Дону УДК 330.43(075.8)
Арженовский С.В., Федосова О.Н. Эконометрика: Учебное пособие/Рост. гос. экон. унив. - Ростов н/Д., - 2002. - 102 с. - ISBN 5-7972-0495-9.
В учебном пособии кратко изложено основное содержание лекционного курса эконометрики. Особое внимание уделено иллюстрации основных теоретических положений примерами из практики эконометрического моделирования. Для студентов, обучающихся по специальностям экономического направления.
Рецензенты: Л.И.Ниворожкина, д.э.н., профессор, зав. кафедрой СМиП РГЭУ " РИНХ" Т.В.Алексейчик, к.э.н., доцент кафедры ФиПМ РГЭУ " РИНХ"
Утверждено в качестве учебного пособия редакционно-издательским советом РГЭУ " РИНХ"
Оглавление
Введение В последнее время специалисты, обладающие знаниями и навыками проведения прикладного экономического анализа с использованием доступных математических и программных средств, пользуются спросом на рынке труда. Одной из центральных дисциплин в подготовке таких специалистов является дисциплина " Эконометрика". Эконометрика является областью знаний, которая охватывает вопросы применения статистических методов к теоретическим моделям, описывающим реальные экономические процессы. Очевидно, что с помощью моделей можно получить много информации об экономических процессах, объяснить те или иные явления или процессы, но никогда не удастся получить всю информацию и однозначно определить истинный механизм экономического процесса или явления. И даже в тех случаях, когда достаточно адекватная исходным данным эконометрическая модель построена и вопрос только в использовании ее для объяснения экономической ситуации или принятия решения, следует весьма осторожно подходить к выводам и рекомендациям, следующим из модельных оценок. Эконометрический анализ, как правило, проводят с помощью ПЭВМ. В последние несколько лет сформировался обширный набор из пакетов прикладных программ, позволяющих автоматизировать процессы такого анализа. К наиболее распространенным относятся пакеты SAS, SPSS, Stata, Eviews и др. Имеются простейшие опции для проведения эконометрического анализа в Excel. В настоящем пособии даются основные понятия, модели и методы эконометрики, рассматриваются примеры. Содержание пособия полностью соответствует требованиям государственного стандарта высшего профессионального образования за исключением темы " Системы одновременных уравнений". Для работы с предлагаемым изданием необходимы базовые знания некоторых разделов следующих учебных дисциплин: высшая математика, теория вероятностей, математическая статистика, общая теория статистики. Эффективным является использование данной книги в сочетании с самостоятельным разбором примеров с использованием доступного статистического программного обеспечения. Авторы благодарят рецензентов за советы при подготовке учебного пособия. 1. Предмет и задачи дисциплины " Эконометрика" 1.1. Определение эконометрики Сложность экономических процессов и необходимость их количественного измерения не позволяют современному экономисту ограничиваться в своей работе применением инструментов отдельных экономических дисциплин. Так, например, невозможно сделать прогноз о том, будет ли пользоваться спросом новый продукт (сорт кофе), если рассматривать этот процесс только с точки зрения экономической теории, то есть закона спроса и предложения. На практике для осуществления прогноза экономисту необходимо применить целый комплекс экономических наук, синтез которых и является сутью научной дисциплины - эконометрики. Основной целью эконометрики является модельное описание конкретных количественных взаимосвязей, обусловленных общими качественными закономерностями, изученными в экономической теории. Эконометрика – относительно молодая научная дисциплина, сформировавшаяся во второй половине ХХ века и развивающаяся на стыке экономической теории, статистики и математики (см. рис. 1.1).
Рис. 1.1. Эконометрика и ее место в ряду других экономических и статистических дисциплин Впервые термин эконометрика был введен норвежским ученым Рагнаром Фришем в 1926 году и в буквальном переводе означает «измерение в экономике». Однако на сегодняшний день эта трактовка чересчур широка. Более четко определение эконометрики предложено известным российским ученым, профессором С.А. Айвазяном.
Таким образом, суть эконометрики состоит в синтезе экономической теории, экономической статистики и математико-статистического инструментария.
Парная регрессия Постановка задачи регрессии Поставим задачу регрессии Y на X. Пусть мы располагаем n парами выборочных наблюдений над двумя переменными X и Y:
Функция f(X) называется функцией регрессии Y по X, если она описывает изменение условного среднего значения результирующей переменной Y в зависимости от изменения значений объясняющей переменной X: f(X)=E(Y |X). Таким образом, имеет место уравнение регрессионной связи между Y и X: Yi =f(Xi)+ui, i=1, …, n. (2.2) Присутствие в модели (2.2) случайной " остаточной" компоненты u, также называемой случайным членом, обусловлено следующими причинами: 1. Ошибки спецификации. Среди них выделяют невключение важных объясняющих переменных, агрегирование (объединение) переменных, неправильную функциональную спецификацию модели. 2. Ошибки измерения. Связаны со сложностью сбора исходных данных и использованием в модели аппроксимирующих переменных для учета факторов, непосредственное измерение которых невозможно. 3. Ошибки, связанные со случайностью человеческих реакций. Обусловлены тем, что поведение и непосредственное участие человека в ходе сбора и подготовки данных может быть достаточно непредсказуемым и вносит, таким образом, свой вклад в случайный член. Мы хотим на основе выборочных наблюдений с учетом дополнительных требований, налагаемых на u, статистически оценить функцию f(X), проверить оптимальность полученной оценки и использовать уравнение для построения прогноза. Допущения модели. Относительно u необходимо принять ряд гипотез, известных как условия Гаусса-Маркова: 1. Eui=0, i=1, …, n. Это требование состоит в том, что математическое ожидание случайного члена в любом наблюдении должно быть равно нулю. Иногда случайный член будет положительным, иногда отрицательным, но он не должен иметь систематического смещения ни в одном из двух возможных направлений. Свойство непосредственно вытекает из смысла функции регрессии. Возьмем в (2.2) матожидание от обеих частей при фиксированном значении X, получим: E(Y|X) =E(f(X))+E(u), по свойству матожидания Þ E(Y|X) =f(X)+E(u), а поскольку с учетом определения функции регрессии должно быть f(X)=E(Y |X), то необходимо E(u)=0. 2. Первая строчка означает требование постоянства дисперсии регрессионных остатков (независимость от того, при каких значениях объясняющей переменной производятся наблюдения i), которое называют гомоскедастичностью остатков. Вторая строчка предполагает отсутствие систематической связи между значениями случайного члена в любых двух наблюдениях, которые должны быть абсолютно независимы друг от друга. 3. X1, …, Xn – неслучайные величины. Таким образом, задача регрессии имеет вид: Yi =f(Xi)+ui, i=1, …, n. а. Eui=0, i=1, …, n. (2.3) б. в. X1, …, Xn – неслучайные величины. (2.5) При выборе вида функции f в (2.2) обычно руководствуются следующими рекомендациями: § используется априорная информация о содержательной экономической сущности анализируемой зависимости – аналитический способ, § предварительный анализ зависимости с помощью визуализации – графический способ, § использование различных статистических приемов обработки исходных данных и экспериментальных расчетов.
Таблица 2.1 Индивидуальное потребление и личные доходы (США, 1954-1965 гг.)
Заметим, что исходные данные должны быть выражены величинами примерно одного порядка. Вычисления удобно организовать, как показано в таблице 2.2. Сначала рассчитываются Оцененное уравнение регрессии запишется в виде Следующая важная проблема состоит в том, чтобы определить, насколько " хороши" полученные оценки и уравнение регрессии. Этот вопрос рассматривается по следующим стадиям исследования: квалифицирование (выяснение условий применимости результатов), определение качества оценок, проверка выполнения допущений метода наименьших квадратов. Относительно квалифицирования уравнения Таблица 2.2 Рабочая таблица расчетов (по данным табл. 2.1)
Полученное уравнение Заметим, что ошибка прогноза ei фактически является оценкой значений ui. График ошибки ei представлен на рис. 2.2. Следует отметить факт равенства нулю суммы Sei=0, что согласуется с первым ограничением модели парной регрессии - Eui=0, i=1, …, n. Ñ
Рис. 2.2. График ошибки прогноза
В модели (2.2) функция f может быть и нелинейной. Причем выделяют два класса нелинейных регрессий: q регрессии, нелинейные относительно включенной объясняющей переменной, но линейные по параметрам, например полиномы разных степеней - Yi =a0 + a1Xi + a2Xi2+ ui, i=1, …, n или гипербола - Yi =a0 + a1/Xi + ui, i=1, …, n; q регрессии нелинейные по оцениваемым параметрам, например степенная функция - Yi =a0 В первом случае МНК применяется так же, как и в линейной регрессии, поскольку после замены, например, в квадратичной параболе Yi =a0 + a1Xi + a2Xi2+ ui переменной Xi2 на X1i: Xi2=X1i, получаем линейное уравнение регрессии Yi =a0 + a1Xi + a2X1i+ ui, i=1, …, n. Во втором случае в зависимости от вида функции возможно применение линеаризующих преобразований, приводящих функцию к виду линейной. Например, для степенной функции Yi =a0 Однако для, например, модели Yi =a0+a2 Таблица дисперсионного анализа
Пример. Для примера табл. 2.1, с учетом предыдущих вычислений, будем иметь таблицу анализа дисперсии - табл. 2.4. Применяя формулу (2.19), получим Таблица 2.4 Таблица анализа дисперсии (пример в табл. 2.1)
Предположения модели Пусть мы располагаем выборочными наблюдениями над k переменными Yi и
Предположим, что существует линейное соотношение между результирующей переменной Y и k объясняющими переменными X1, X3, ..., Xk. Тогда с учетом случайной ошибки ui запишем уравнение:
В (3.1) неизвестны коэффициенты Относительно переменных модели в уравнении (3.1) примем следующие основные гипотезы: E(ui)=0; (3.2)
X1, X3, ..., Xk – неслучайные переменные; (3.4) Не должно существовать строгой линейной зависимости между переменными X1, X3, ..., Xk. (3.5) Первая гипотеза (3.2) означает, что переменные ui имеют нулевую среднюю. Суть гипотезы (3.3) в том, что все случайные ошибки ui имеют постоянную дисперсию, то есть выполняется условие гомоскедастичности дисперсии (см. подробнее раздел 4). Согласно (3.4) в повторяющихся выборочных наблюдениях источником возмущений Y являются случайные колебания ui, а значит, свойства оценок и критериев обусловлены объясняющими переменными X1, X3, ..., Xk. Последняя гипотеза (3.5) означает, в частности, что не существует линейной зависимости между объясняющими переменными, включая переменную X0, которая всегда равна 1. Понятно, что условия (3.2)-(3.4) соответствуют своим аналогам для случая двух переменных в п.2.2.
Таблица 3.1
В данном примере мы располагаем пространственной выборкой объема n=20, число объясняющих переменных k=2. Модель специфицируем в виде линейной функции:
Следовательно, система нормальных уравнений для модели (3.9) будет иметь вид
Рассчитаем по данным табл. 3.1 необходимые для составления указанной системы суммы:
Получим систему нормальных уравнений (3.10) в виде:
Решая последнюю систему линейных алгебраических уравнений, например методом Крамера, получим:
Уравнение регрессии имеет вид: Y=-17, 31+1, 16× X1+15, 10× X2. Или, с учетом (3.8) и расчетов:
уравнение регрессии в стандартизованном масштабе:
То есть с ростом веса груза на одну сигму при неизменном расстоянии стоимость грузовых автомобильных перевозок увеличивается в среднем на 0, 77 сигмы. Поскольку 0, 77> 0, 56, то влияние веса груза на стоимость грузовых автомобильных перевозок больше, чем фактора расстояния. Рассчитаем коэффициенты эластичности
С увеличением среднего веса груза на 1% от его среднего уровня средняя стоимость перевозок возрастет на 0, 71% от своего среднего уровня, при увеличении среднего расстояния перевозок на 1% средняя стоимость доставки груза увеличится на 1, 05%. Различия в силе влияния факторов на результат полученные при сравнении уравнения регрессии в стандартизованном масштабе и коэффициентов эластичности объясняются тем, что коэффициент эластичности рассчитывается исходя из соотношения средних, а стандартизованные коэффициенты регрессии из соотношения средних квадратических отклонений. Поскольку обычно статистики используют показатель грузооборота, вычисляемый как сумма произведений массы перевезенных грузов на расстояние перевозки, то построим регрессию стоимости 1 км грузовых автомобильных перевозок Y на грузооборот Q (Q=X1X2): P = 5, 88 + 0, 48× Q - 0, 003× Q2, причем регрессор Q2 = Q*Q включен исходя из соображений известного экономического закона убывающей предельной полезности, согласно которому в данном случае стоимость перевозки на 1 км должна уменьшаться с ростом грузооборота, т.е. коэффициент при Q2 должен иметь (и в построенном уравнении имеет) отрицательный знак.Ñ Как уже говорилось в разделе 2.3, регрессионные модели не ограничиваются классом линейных функций. Линеаризация нелинейных функций в уравнении регрессии имеет особенности, рассмотренные в примере. Пример 2. Исследуется зависимость между выпуском Q (млн. $) и затратами труда L (чел.) и капитала K (млн. $) в металлургической промышленности по 27 американским компаниям. Исходные данные приведены в таблице 3.2. Таблица 3.2
Мы располагаем пространственной выборкой объема n=27, число объясняющих переменных k=2. Модель зависимости между выпуском и затратами труда и капитала, как правило, специфицируется в виде производственной функции, чаще всего Кобба-Дугласа:
Поскольку модель (3.11) является нелинейной, преобразуем ее к виду линейной по параметрам. Для этого возьмем логарифм от обеих частей в уравнении (3.11):
Переобозначим для удобства Y=lnQ, b0=lnA, X1=lnL, X2=lnK, u=lne, тогда имеем линейную модель вида:
Исходные данные к модели вида (3.11) получаются логарифмированием чисел, представленных в таблице 3.2. Соответственно получим табл. 3.3. После процедуры лианеризации система нормальных уравнений для модели (3.11) будет иметь такой же вид, как и система (3.10) Рассчитаем по данным табл. 3.3 необходимые для составления указанной системы суммы:
Таблица 3.3
Получим систему нормальных уравнений после подстановки соответствующих значений в (3.10) в виде:
Решая последнюю систему методом Крамера, получим:
Уравнение регрессии имеет вид: Y=1, 11+0, 56× X1+0, 41× X2. Или, с учетом (3.8) и расчетов:
Нетрудно восстановить (учитывая, что A=
Эластичность выпуска продукции Q по труду L равна 0, 56, а эластичность выпуска продукции Q по капиталу K равна 0, 41. Следовательно увеличение затрат труда на 1% приведет к росту выпуска продукции на 0, 56%, а увеличение затрат капитала на 1% приведет к росту выпуска продукции на 0, 41%. Очевидно, что обе величины Продолжая интерпретацию результатов регрессии
Таблица 3.4 Таблица дисперсионного анализа
Если F> Fe, то гипотеза об отсутствии связи между переменными Пример (продолжение примера 1). Заполним таблицу дисперсионного анализа: Таблица дисперсионного анализа
|
Последнее изменение этой страницы: 2017-05-05; Просмотров: 104; Нарушение авторского права страницы



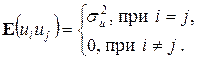
 , затем xi, yi. Результаты заносятся в столбцы 3 и 4. Далее определяются xi2, xiyi и заносятся в 5 и 6 столбцы таблицы 2.2. По формулам (2.8) получим искомые значения параметров
, затем xi, yi. Результаты заносятся в столбцы 3 и 4. Далее определяются xi2, xiyi и заносятся в 5 и 6 столбцы таблицы 2.2. По формулам (2.8) получим искомые значения параметров 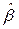 =43145/46510=0, 9276;
=43145/46510=0, 9276;  =321, 75-0, 9276.350=-2, 91.
=321, 75-0, 9276.350=-2, 91.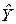 =-2, 91+0, 9276X.
=-2, 91+0, 9276X. =350, 00
=350, 00
 =321, 75
=321, 75
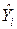 и дана в последнем столбце рабочей таблицы.
и дана в последнем столбце рабочей таблицы.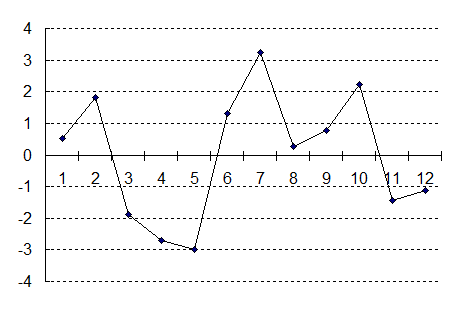
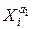 ui, i=1, …, n, или показательная функция - Yi =
ui, i=1, …, n, или показательная функция - Yi = 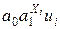 , i=1, …, n.
, i=1, …, n.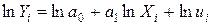 линейную функцию в логарифмах и применяем МНК.
линейную функцию в логарифмах и применяем МНК.
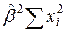

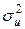

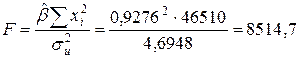 . Табличное значение F0, 01(1, 10)=10, 04, так что имеющиеся данные позволяют отвергнуть гипотезу об отсутствии связи между личными доходами и индивидуальным потреблением. Ñ
. Табличное значение F0, 01(1, 10)=10, 04, так что имеющиеся данные позволяют отвергнуть гипотезу об отсутствии связи между личными доходами и индивидуальным потреблением. Ñ 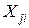 , j=1,..., k, i=1, 2, …, n, где n – количество наблюдений:
, j=1,..., k, i=1, 2, …, n, где n – количество наблюдений: 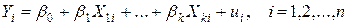 (3.1)
(3.1) , j=0, 2, …, k и параметры распределения ui. Задача состоит в оценивании этих неизвестных величин. Модель (3.1) называется классической линейной моделью множественной регрессии (КЛММР). Заметим, что часто имеют в виду, что переменная X0 при b0 равна единице для всех наблюдений i=1, 2, …, n.
, j=0, 2, …, k и параметры распределения ui. Задача состоит в оценивании этих неизвестных величин. Модель (3.1) называется классической линейной моделью множественной регрессии (КЛММР). Заметим, что часто имеют в виду, что переменная X0 при b0 равна единице для всех наблюдений i=1, 2, …, n.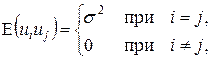 (3.3)
(3.3)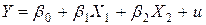 . (3.9)
. (3.9)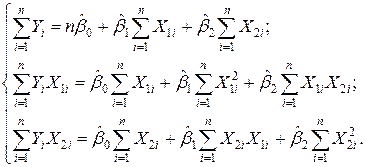 (3.10)
(3.10)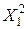 =5860, 9;
=5860, 9;
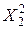 =61, 45;
=61, 45;
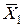 =13, 86;
=13, 86;
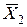 =1, 59;
=1, 59;
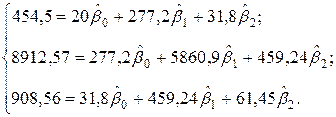
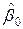 =-17, 31;
=-17, 31;  =1, 16;
=1, 16; 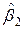 =15, 10.
=15, 10. =
= 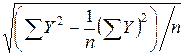 =
=  =19, 85,
=19, 85, 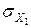 =
= 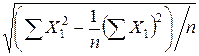 =
=  =10, 05,
=10, 05, 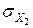 =
= 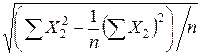 =
= 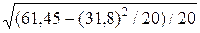 =0, 74.
=0, 74. =1, 16
=1, 16  =0, 77,
=0, 77,  =15, 10
=15, 10 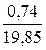 =0, 56
=0, 56 .
. = 1, 16× 13, 86/(-17, 31 + 1, 16× 13, 86 + 15, 10× 1, 59) = 0, 71,
= 1, 16× 13, 86/(-17, 31 + 1, 16× 13, 86 + 15, 10× 1, 59) = 0, 71,  = 1, 05.
= 1, 05.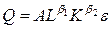 . (3.11)
. (3.11)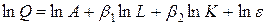 .
.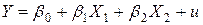 . (3.12)
. (3.12)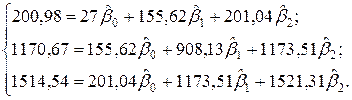
 =0, 48,
=0, 48,  =0, 52 уравнение регрессии в стандартизованном масштабе:
=0, 52 уравнение регрессии в стандартизованном масштабе:  .
.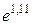 =3, 03) исходную модель (3.9)
=3, 03) исходную модель (3.9)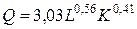 .
.
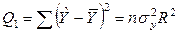



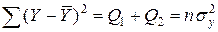
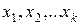 и y отклоняется, в противном случае гипотеза Н0 принимается и уравнение регрессии не значимо.
и y отклоняется, в противном случае гипотеза Н0 принимается и уравнение регрессии не значимо.