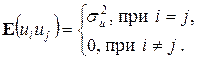|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Основные цели и задачи прикладного корреляционно-регрессионного анализа
Рассмотрим некоторый экономический объект (процесс, явление, систему) и выделим только две переменные, характеризующие объект. Обозначим переменные буквами Y и X. Будем предполагать, что независимая (объясняющая) переменная X оказывает воздействие на значения переменной Y, которая, таким образом, является зависимой переменной, т.е. имеет место зависимость: Y=f(X). (2.1) Зависимость (2.1) можно рассматривать с целью установления самого факта наличия или отсутствия значимой связи между Y и X, можно преследовать цель прогнозирования неизвестных значений Y по известным значениям X, наконец возможно выявление причинно-следственных связей между X и Y. При изучении взаимосвязи между переменными Y и X следует, прежде всего, установить тип зависимости (природу анализируемых переменных Y и X). Возможны следующие ситуации: q Y и X являются неслучайными переменными, т.е. значения Y строго зависят только от соответствующих значений X и полностью ими определяются. В этом случае говорят о функциональной зависимости, когда Y является некоторой функцией от переменной X и верна модель (2.1). Пример: q Y является случайной переменной, а X – неслучайной. В этом случае считают, что между переменными имеет место регрессионная зависимость. То есть верна модель Y=f(X)+u, где u – величина случайной ошибки. q Y и X зависят от множества неконтролируемых факторов, так что являются случайными по своей сущности. В этом случае к проблемам построения конкретного вида зависимости между указанными переменными присоединяется проблема исследования тесноты связи между этими переменными. Речь в этом случае идет о корреляционно-регрессионной зависимости между Y и X. Будем предполагать наличие второй из указанных ситуаций. Регрессионный анализ является инструментом решения следующих основных задач: 1. Для любых значений объясняющей переменной X построить наилучшие по некоторому критерию оценки для неизвестной функции f(X). 2. По заданным значениям объясняющей переменной X построить наилучший по некоторому критерию прогноз для неизвестного значения результирующей переменной Y(X). 3. Пусть известно, что искомая функция зависит от параметра q: f(X, q). Требуется построить наилучшую в определенном смысле оценку для неизвестного значения этого параметра. 4. Оценить удельный вес влияния переменной X на результирующий показатель Y. В следующих разделах параграфа рассмотрим процедуру решения этих задач. Постановка задачи регрессии Поставим задачу регрессии Y на X. Пусть мы располагаем n парами выборочных наблюдений над двумя переменными X и Y:
Функция f(X) называется функцией регрессии Y по X, если она описывает изменение условного среднего значения результирующей переменной Y в зависимости от изменения значений объясняющей переменной X: f(X)=E(Y |X). Таким образом, имеет место уравнение регрессионной связи между Y и X: Yi =f(Xi)+ui, i=1, …, n. (2.2) Присутствие в модели (2.2) случайной " остаточной" компоненты u, также называемой случайным членом, обусловлено следующими причинами: 1. Ошибки спецификации. Среди них выделяют невключение важных объясняющих переменных, агрегирование (объединение) переменных, неправильную функциональную спецификацию модели. 2. Ошибки измерения. Связаны со сложностью сбора исходных данных и использованием в модели аппроксимирующих переменных для учета факторов, непосредственное измерение которых невозможно. 3. Ошибки, связанные со случайностью человеческих реакций. Обусловлены тем, что поведение и непосредственное участие человека в ходе сбора и подготовки данных может быть достаточно непредсказуемым и вносит, таким образом, свой вклад в случайный член. Мы хотим на основе выборочных наблюдений с учетом дополнительных требований, налагаемых на u, статистически оценить функцию f(X), проверить оптимальность полученной оценки и использовать уравнение для построения прогноза. Допущения модели. Относительно u необходимо принять ряд гипотез, известных как условия Гаусса-Маркова: 1. Eui=0, i=1, …, n. Это требование состоит в том, что математическое ожидание случайного члена в любом наблюдении должно быть равно нулю. Иногда случайный член будет положительным, иногда отрицательным, но он не должен иметь систематического смещения ни в одном из двух возможных направлений. Свойство непосредственно вытекает из смысла функции регрессии. Возьмем в (2.2) матожидание от обеих частей при фиксированном значении X, получим: E(Y|X) =E(f(X))+E(u), по свойству матожидания Þ E(Y|X) =f(X)+E(u), а поскольку с учетом определения функции регрессии должно быть f(X)=E(Y |X), то необходимо E(u)=0. 2. Первая строчка означает требование постоянства дисперсии регрессионных остатков (независимость от того, при каких значениях объясняющей переменной производятся наблюдения i), которое называют гомоскедастичностью остатков. Вторая строчка предполагает отсутствие систематической связи между значениями случайного члена в любых двух наблюдениях, которые должны быть абсолютно независимы друг от друга. 3. X1, …, Xn – неслучайные величины. Таким образом, задача регрессии имеет вид: Yi =f(Xi)+ui, i=1, …, n. а. Eui=0, i=1, …, n. (2.3) б. в. X1, …, Xn – неслучайные величины. (2.5) При выборе вида функции f в (2.2) обычно руководствуются следующими рекомендациями: § используется априорная информация о содержательной экономической сущности анализируемой зависимости – аналитический способ, § предварительный анализ зависимости с помощью визуализации – графический способ, § использование различных статистических приемов обработки исходных данных и экспериментальных расчетов.
|
Последнее изменение этой страницы: 2017-05-05; Просмотров: 98; Нарушение авторского права страницы
 .
.