|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Иерархическая архитектура взаимодействия агентов
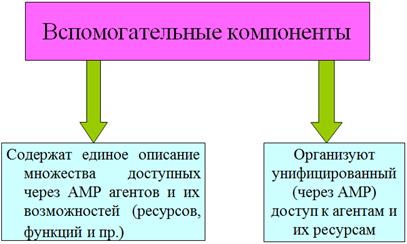
Простейший вариант иерархической организации взаимодействия агентов - использование агента «метауровня» (Агента-Координатора), осуществляющего координацию решением задач (и) агентами. Агент-Координатор. Может быть привязан к конкретному серверу - называется «местом встречи агентов». Место встречи агентов (AMP — Agent Meeting Place) — это агент, играющий роль брокера между агентами, запрашивающими некоторые требующиеся им ресурсы, и агентами, которые эти ресурсы могут предоставить. Архитектура AMP - архитектура обычного агента, дополненная вспомогательными компонентами - функциями координатора взаимодействия других агентов.
Вспомогательные компоненты AMP и их функции: 1. Объекты базовых сервисов (удаленный вызов объектов, упорядочение объектов, дублирование объектов и др., поддерживемые той или иной платформой открытой распределенной обработки, например, OMG/CORBA). 2. Связные порты, (прием и отправку агентов в AMP с помощью соответствующих протоколов). 3. Компонента установления подлинности агента по имени (опознание агента, «авторизация»). 4. Консьерж (проверка полномочий поступающего агента, контроль наличия на AMP запрашиваемой услуги, оказание помощи агенту в выборе дальнейшего маршрута перемещения и др.). 5. Поверхностный маршрутизатор (интерфейс между агентами и компонентами AMP; агенты и компоненты сами регистрируются в этом маршрутизаторе; поддерживает ограниченный словарь для удовлетворения агентских запросов). 6. Глубинный маршрутизатор (используется при более специальных или сложных запросах). 7. Лингвистический журнал (база данных, помогающая агентам и AMP понимать друг друга в процессе коммуникаций. В нем регистрируются словари и языки, но не описания языков или смысл терминов, а лишь ссылки на них, т.е. журнал предоставляет информацию о том, что может быть понято в AMP). 8. Менеджер ресурсов (регистрирует агентов на AMP и связанные с ними ресурсы, управляет ресурсами AMP). 9. Среда реализации агента (регистрируется в AMP и управляет доступом к компонентам агента; она интерпретирует сценарии, обеспечивает доступ к базовым возможностям и др.). 10. Система доставки событий. Источниками событий могут быть локальные средства, резидентные агенты AMP и др. (регистрирует события и выполняет поиск агентов для соответствующего типа событий, сообщений).
28. Индуктивные системы. Обобщение примеров по принципу от частного к общему сводится к выявлению подмножеств примеров, относящихся к одним и тем же подклассам, и определению для них значимых признаков. Процесс классификации примеров осуществляется следующим образом: 1. Выбирается признак классификации из множества заданных (либо последовательно, либо по какому-либо правилу, например, в соответствии с максимальным числом получаемых подмножеств примеров); 2. По значению выбранного признака множество примеров разбивается на подмножества; 3. Выполняется проверка, принадлежит ли каждое образовавшееся подмножество примеров одному подклассу; 4. Если какое-то подмножество примеров принадлежит одному подклассу, т.е. у всех примеров подмножества совпадает значение классообразующего признака, то процесс классификации заканчивается (при этом остальные признаки классификации не рассматриваются); 5. Для подмножеств примеров с несовпадающим значением классообразующего признака процесс классификации продолжается, начиная с пункта 1. (Каждое подмножество примеров становится классифицируемым множеством). Процесс классификации может быть представлен в виде дерева решений, в котором в промежуточных узлах находятся значения признаков последовательной классификации, а в конечных узлах – значения признака принадлежности определенному классу. Пример построения дерева решений на основе фрагмента таблицы примеров (таблица 1.1) показан на рис. 1.11. Таблица 1.1 Рис. 1.11. Фрагмент дерева решений Анализ новой ситуации сводится к выбору ветви дерева, которая полностью определяет эту ситуацию. Поиск решения осуществляется в результате последовательной проверки признаков классификации. Каждая ветвь дерева соответствует одному правилу решения: Если Спрос = «низкий» и Издержки = «маленькие» То Цена = «низкая» Примерами инструментальных средств, поддерживающих индуктивный вывод знаний, являются 1st Class (Programs in Motion), Rulemaster (Radian Corp.), ИЛИС (ArgusSoft), KAD (ИПС Переяславль-Залесский).
29. Интеллектуальный анализ данных. Интеллектуальный анализ данных (Data Mining) — выявление скрытых закономерностей или взаимосвязей между переменными в больших массивах необработанных данных. Процесс автоматического поиска закономерностей в больших массивах данных. 30. Информационные хранилища. Хранилище данных (англ. Data Warehouse) — предметно-ориентированная информационная база данных, специально разработанная и предназначенная для подготовки отчётов и бизнес-анализа с целью поддержки принятия решений в организации. Строится на базе систем управления базами данных и систем поддержки принятия решений. Данные, поступающие в хранилище данных, как правило, доступны только для чтения. Данные из OLTP-системы копируются в хранилище данных таким образом, чтобы построение отчётов и OLAP-анализ не использовал ресурсы транзакционной системы и не нарушал её стабильность. Как правило, данные загружаются в хранилище с определённой периодичностью, поэтому актуальность данных может несколько отставать от OLTP-системы. |
Последнее изменение этой страницы: 2019-04-19; Просмотров: 350; Нарушение авторского права страницы