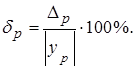|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Простейшая обработка данных. Линейная регрессия.Стр 1 из 8Следующая ⇒
Лабораторная работа №1. Простейшая обработка данных. Линейная регрессия. Коэффициент корреляции. Его значимость Цель: научиться находить коэффициент корреляции и определять его начимость; находить коэффициенты регрессии и строить уравнение регрессии.
Основные сведения Парная регрессия – это уравнение связи двух переменных у и х: y=f(х), где у – зависимая переменная (результат, отклик); х – независимая, объясняющая переменная (фактор). Различают линейные и нелинейные регрессии. Линейная регрессия: Построение уравнения регрессии сводится к оценке ее параметров. Для оценки параметров регрессий, линейных по параметрам, используют метод наименьших квадратов (МНК). МНК позволяет получить такие оценки параметров, при которых сумма квадратов отклонений фактических значений результативного признака у от теоретических у x минимальна. Для линейных и нелинейных уравнений, приводимых к линейным, решается следующая система относительно а и в:
Можно воспользоваться готовыми формулами, которые вытекают из этой системы:
Параметр b называется коэффициентом регрессии. Его величина показывает среднее изменение результата с изменением фактора на одну единицу. Тесноту связи изучаемых явлений оценивает линейный коэффициент парной корреляции r xy для линейной регрессии Теснота линейной связи между переменными может быть оценена на основании шкалы Чеддока:
Положительное значение коэффициента корреляции говорит о положительной связи между х и у, когда с ростом одной из переменных другая тоже растет. Отрицательное значение коэффициента корреляции означает, с ростом одной из переменных другая убывает, с убыванием одной из переменной другая растет. Оценку статистической значимости коэффициента корреляции проводят с помощью t-критерия Стьюдента. Выдвигают гипотезу Н0 о статистически незначимом отличии коэффициента от нуля. Оценка значимости коэффициента корреляции с помощью t-критерия Стьюдента проводится путем сопоставления его значения с величиной случайной ошибки: tr=r/mr. Стандартная (случайная) ошибка коэффициента корреляции определяется по формуле:
Сравнивая фактическое и табличное (критическое) значения t-статистики –tтабл. и tфакт. – принимает или отвергаем гипотезу Н0. Если tтабл. < tфакт., то гипотеза Н0 отклоняется, коэффициент корреляции не случайно отличается от. Если tтабл. > tфакт , то гипотеза Н0 не отклоняется и признается случайная природа формирования коэффициента корреляции.
Порядок выполнения работы. По заданной выборке исследовать зависимость результата у от фактора х. Для этого 1. Создать таблицу данных. 2. Найти средние значения 3. Найти коэффициент корреляции и проверить его значимость. 4. Найти коэффициенты линейного уравнения регрессии. 5. Построить график прямой регрессии.
Пример выполнения лабораторной работы. В табл. 1.1 приведены данные об объеме производства у (тыс.ед.) в зависимости от численности занятых х (тыс.чел.) некоторой фирмы. Таблица 1.1. Исходные данные
1. В диапазоне В3:C11 подготовим исходные данные.
2. Вводим следующие формулы:
Получим следующие результаты (см. рис. 1.1). Рис. 1.1. Результаты простейшей обработки данных
3. Для определения коэффициента корреляции воспользуемся формулой =( D 12- B 12* C 12)/КОРЕНЬ( A 17* B 17) Из расчетов следует, что коэффициент корреляции r=0,97. Это свидетельствует о том, что связь между объемом выпуска продукции и численностью занятых весьма высокая и положительная. 4. Для проверки значимости коэффициента корреляции введем вспомогательные данные: Ячейки К16 9 число предприятий; К17 0,05 уровень значимости.
5. Далее вводим следующие формулы:
Таким образом, получим данные, представленные на рис 1.2.
Рис. 1.2. Анализ значимости коэффициента корреляции
6. Для определения коэффициентов уравнения линейной регрессии на основе формул
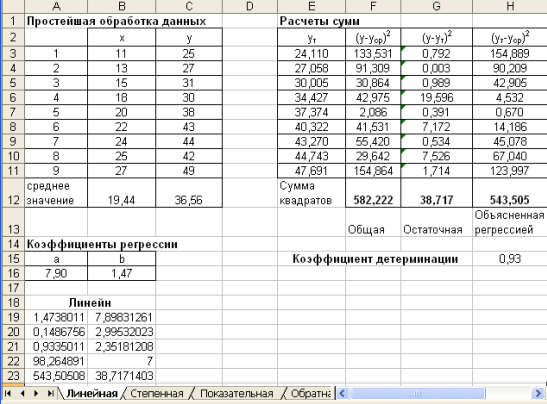
следует в ячейки I3, I4 ввести соответственно следующие формулы: =(D12-B12*C12)/A17; =C12-I3*B12. Уравнение регрессии у=7,9+1,47х. Значение коэффициента b=1,47 говорит о том, что при увеличении численности занятых на 1 тыс.чел. объем продукции увеличится на 1,74 тыс.ед. Результаты расчетов приведены на рис.1.3.
Рис. 1.3. Результаты расчетов
7. Для построения графика выделим диапазон В3:С11. Вызовем Мастер диаграмм. Чтобы ось отражала фактические данные, выберем тип диаграммы Точечная. После чего нажмем кнопку Готово. На построенной диаграмме выделим график функции, щелкнув по нему левой кнопкой мыши. Выделение обозначается светлыми маркерами на функции. Нажав правую кнопку мыши, выведем контекстно-зависимое меню, в котором выберем опцию Добавить линию тренда. В окне Линия тренда по вкладке Тип выберем тип функции Линейная, а во вкладке Параметры – установим флажок показывать уравнение на диаграмме. В результате на диаграмме появиться вид теоретической кривой – тренда и ее уравнение (рис.1.4).
Рис. 1.4. Графики фактических данных и построенной регрессии
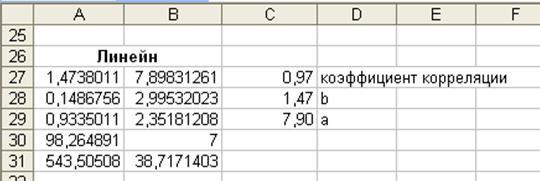
8. Вычисление параметров регрессии с помощью статистических функций Excel: КОРРЕЛ(массив1;массив2) вычисляет коэффициент корреляции между двумя переменными; значения первой из них приведены в диапазоне массив1, значения второй – в диапазоне массив2; НАКЛОН(известные_значения_y;известные_значения_x) служит для определения коэффициента b; ОТРЕЗОК(известные_значения_y;известные_значения_x) служит для определения коэффициента a. Вводим формулы:
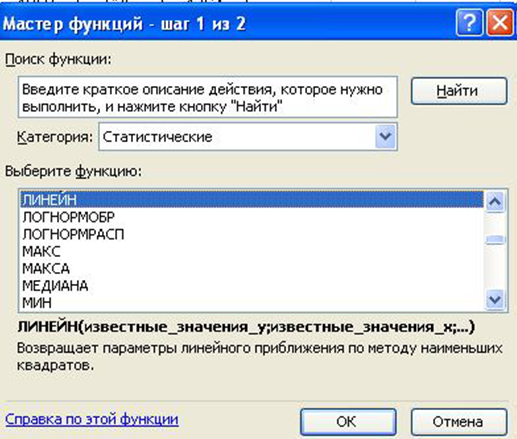
Встроенная статистическая функция ЛИНЕЙН определяет параметры линейной регрессии. Порядок вычислений следующий: 1) выделите область пустых ячеек 5х2 (5 строк, 2 столбца) с целью вывода результатов регрессионной статистики (А27:В3); 2) в главном меню выберите Вставка/Функция; 3) в строке Категория (рис.1.5) выберите Статистические, в окне Функция – ЛИНЕЙН. Щелкните ОК.
Рис. 1.5. Диалоговое окно «Мастер функций»
4) Заполните аргументы функции (рис.1.6.):
Известные_значения_у – диапазон, содержащий данные результативного признака;
Известные_значения_х – диапазон, содержащий данные факторов независимого признака;
Константа – логическое значение, которое указывает на наличие или на отсутствие свободного члена в уравнении; если Константа = 1, то свободный член рассчитывается обычным образом, если Константа = 0, то свободный член равен 0.
Статистика – логическое значение, которое указывает выводить дополнительную информацию по регрессионному анализу или нет. Если Статистика = 1, то дополнительная информация выводится, если Статистика = 0, то выводится только оценки параметров уравнения. Далее ОК.
Рис.1.6. Диалоговое окно ввода аргументов функции ЛИНЕЙН 5) В левой верхней ячейке выделенной области появится первый элемент итоговой таблицы. Чтобы раскрыть всю таблицу, нажмите на клавишу F2, а затем – на комбинацию клавиш CTRL+SHIFT+ENTER. Дополнительная регрессионная статистика будет выводиться в порядке, указанном в следующей схеме:
Результаты регрессионного анализа представлены на рис.1.7.
Рис. 1.7.Результаты регрессионного анализа
Индивидуальное задание к лабораторной работе №1
По предприятиям легкой промышленности региона получена информация, характеризующая зависимость объема выпуска продукции ( y ,млн. руб.) от объема капиталовложений ( x , млн. руб.)
Лабораторная работа №2 Основные сведения Оценку качества построенной модели дает коэффициент (индекс) детерминации Средняя ошибка аппроксимации – среднее отклонение расчетных значений от фактических:
Допустимый предел значений средней ошибки аппроксимации – не более 8–10%. Согласно основной идее дисперсионного анализа, общая сумма квадратов отклонений переменной y от среднего значения
где
Определение дисперсии на одну степень свободы приводит дисперсии к сравнимому виду. Сопоставляя факторную и остаточную дисперсии в расчете на одну степень свободы, получим величину F - критерия Фишера:
Фактическое значение F -критерия Фишера (1.9) сравнивается с табличным значением Для парной линейной регрессии m = 1, поэтому
Величина F -критерия связана с коэффициентом детерминации
В парной линейной регрессии оценивается значимость не только уравнения в целом, но и отдельных его параметров. С этой целью по каждому из параметров определяется его стандартная ошибка: m b и m a . Стандартная ошибка коэффициента регрессии определяется по формуле:
где Величина стандартной ошибки совместно с t – распределением Стьюдента при n - 2 степенях свободы применяется для проверки существенности коэффициента регрессии и для расчета его доверительного интервала. Для оценки существенности коэффициента регрессии его величина сравнивается с его стандартной ошибкой, т.е. определяется фактическое значение t -критерия Стьюдента: Стандартная ошибка параметра a определяется по формуле:
Процедура оценивания существенности данного параметра не отличается от рассмотренной выше для коэффициента регрессии. Вычисляется t -критерий: Если в границы доверительного интервала попадает ноль, т.е. нижняя граница отрицательна, а верхняя положительна, то оцениваемый параметр принимается нулевым, т.к. он не может одновременно принимать и положительное, и отрицательное значения.
Пример выполнения лабораторной работы.
1. В диапазоне А2:C11 подготовим исходные данные. 2. Введем вспомогательные данные:
Проверка значимости коэффициента b. 1) Для расчетов сумм квадратов отклонений введем формулы:
2) Стандартная ошибка параметра b определяется по формуле:
поэтому введем в ячейку D24 формулу: =(E12/((C16-2)*F12))^0,5. 3) В ячейке D25 рассчитана t-статистика параметра b как отношение величины этого параметра к его стандартной ошибке: =C19/D24. 4) Критическое значение t-статистики определим в ячейке D26 с помощью функции СТЬЮДРАСПОБР, у которой первым аргументом является пороговая значимость или вероятность (в нашем случае примем ее равной 0,05), а вторым – число степеней свободы (n–2=9–2=7). Таким образом, формула, введенная в D26, должна иметь вид: =СТЬЮДРАСПОБР($C$17;$C$16-2). 5) Для того чтобы автоматически был получен вывод о значимости параметра b построим в ячейке D27 формулу: =ЕСЛИ(ABS(D25)>D26;"Значим";"Незначим"). 6) Для расчета доверительного интервала определяем предельную ошибку в ячейке D28: =D26*D24. 7) Нижняя граница доверительного интервала в ячейке D29: =C19-D28. 8) Верхняя граница доверительного интервала в ячейке D30: =C19+D28. Таким образом, доверительный интервал параметра b имеет вид (1,12; 1,83).
Проверка значимости коэффициента a . Вводим формулы:
Лабораторная работа №3 Основные сведения Если между экономическими явлениями существуют нелинейные соотношения, то они выражаются с помощью соответствующих нелинейных функций. Различают два класса нелинейных регрессий: 1. Регрессии, нелинейные относительно включенных в анализ объясняющих переменных, но линейные по оцениваемым параметрам, например – полиномы различных степеней – – равносторонняя гипербола – – полулогарифмическая функция – 2. Регрессии, нелинейные по оцениваемым параметрам, например – степенная – – показательная – – экспоненциальная – Регрессии нелинейные по включенным переменным приводятся к линейному виду простой заменой переменных, а дальнейшая оценка параметров производится с помощью метода наименьших квадратов. Несколько иначе обстоит дело с регрессиями нелинейными по оцениваемым параметрам, которые делятся на два типа: нелинейные модели внутренне линейные (приводятся к линейному виду с помощью соответствующих преобразований, например, логарифмированием) и нелинейные модели внутренне нелинейные (к линейному виду не приводятся). К внутренне линейным моделям относятся, например, степенная функция К внутренне нелинейным моделям можно, например, отнести следующие модели: Приведем формулы для расчета параметров наиболее часто используемых типов уравнений регрессии (табл. 1.3): Таблица 1.3.
В случае нелинейной зависимости тесноту связи между величинами оценивают по величине корреляционного отношения:
Интервал изменения корреляционного отношения Оценку качества построенной модели дает индекс детерминации Коэффициент детерминации характеризует долю дисперсии, объясняемую регрессией, в общей дисперсии результативного признака у.
Чем ближе коэффициент детерминации к 1, тем выше качество уравнения регрессии, тем в большей мере оно объясняет поведение отклика.
Порядок выполнения работы. Используя данные лабораторной работы №1, построить линейную, степенную, показательную, экспоненциальную, полулогарифмическую, гиперболическую и обратную модели и с помощью коэффициента детерминации сравнить эти модели. Для чего необходимо: 1. Найти уравнение регрессии. 2. Найти общую сумму квадратов отклонений и остаточную сумму квадратов отклонений. 3. Найти коэффициент детерминации. 4. Найти параметры регрессии с помощью статистической функции ЛИНЕЙН.
Пример выполнения лабораторной работы. Создадим новую рабочую книгу с семью листами.
Будем использовать данные из лабораторной работы №1.
1. Лист Линейная оформим, как показано на рис.1.3:
Рис. 1.3. Лист Линейная На этом листе коэффициенты линейной регрессии определяются с помощью статистических функций (см. лабораторную работу №1). Для расчета сумм, которые понадобятся при определении коэффициента детерминации (и при выполнении следующей лабораторной работы), введем формулы:
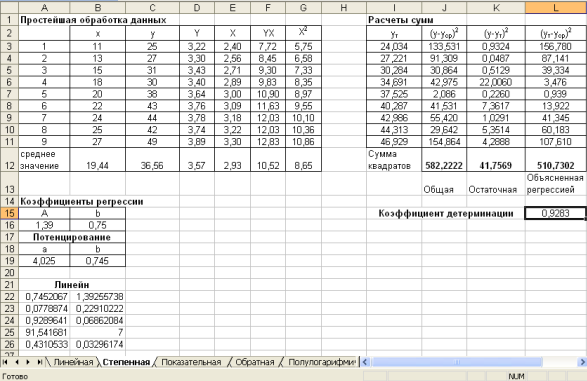
Замечание. В приведенных формулах неоднократно используется абсолютная адресация, содержащая знак «$». Это необходимо для того, чтобы при копировании формул данный адрес не изменялся. Для того чтобы превратить относительный адрес А16 в абсолютный ($A$16), достаточно нажать клавишу F4 в то время, когда курсор находится на ячейке А16. Для вычисления коэффициента детерминации в ячейку Н15 введем формулу: =1-G12/F12. 2. Регрессия в виде степенной функции имеет вид: Для нахождения параметров регрессии Y=A+bX, где Y=ln y, X=ln x, A=ln a. Составляем вспомогательную таблицу для преобразованных данных (рис. 2.3):
Рис. 2.3 Лист Степенная Вводим формулы:
Для вычисления коэффициентов регрессии введем следующие формулы:
После потенцирования находим искомые коэффициенты регрессии:
Тогда уравнение регрессии будет иметь вид:
Для расчета сумм введем формулы:
Для вычисления коэффициента детерминации в ячейку L15 введем формулу: =1-K12/J12. Проведем расчеты параметров регрессии с помощью статистической функции ЛИНЕЙН. Выделим диапазон А22:В26. введем формулу =ЛИНЕЙН(D3:D11;E3:E11;1;1). В левой верхней ячейке выделенной области появится первый элемент итоговой таблицы. Чтобы раскрыть всю таблицу, нажмите на клавишу F2, а затем – на комбинацию клавиш CTRL+SHIFT+ENTER.
3. Расчеты на остальных листах во многом повторяют расчеты, произведенные на листе Степенная, поэтому остальные листы лучше всего получить копированием листа Степенная. Для этого необходимо: · находясь на листе Степенная, выделить его полностью, щелкнув мышью на пересечении названий столбцов и строк; с помощью кнопки (Копировать) скопировать лист в Буфер обмена; · перейти на следующий лист и выделив ячейку А1,щелкнуть мышью по кнопке (Вставить).
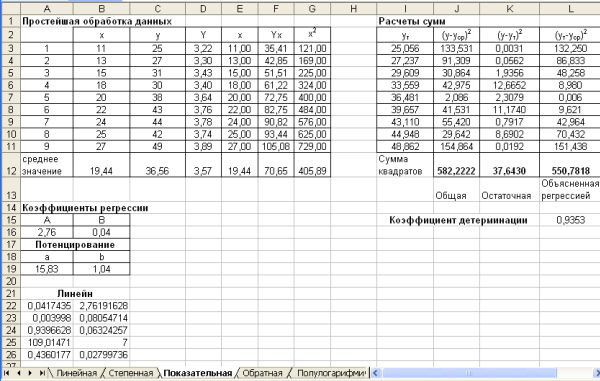
Получим следующие результаты (рис. 3.3-7.3): Рис. 3.3. Лист Показательная
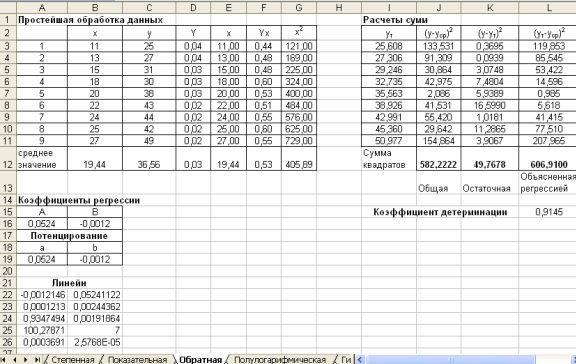
Рис. 4.3. Лист Обратная
Рис. 5.3. Лист Полулогарифмическая
Рис. 6.3. Лист Гиперболическая
Рис. 7.3. Лист Экспоненциальная
Выберем наилучшую модель, для чего объединим результаты построения парных регрессий в одной таблице (табл. 2.1). Все уравнения регрессии достаточно хорошо описывают исходные данные. Некоторое предпочтение можно отдать показательной или экспоненциальной функции, для которых значение коэффициента детерминации наибольшее.
Лабораторная работа №4 Основные сведения. Пусть по заданной выборке объема n найдено выборочное уравнение линейной регрессии у=а+bх. С помощью этого уравнения можно прогнозировать значение результата у р при определенном прогнозном значении фактора х р. Прогнозное значение у р определяется путем подстановки в уравнение регрессии у=а+bх соответствующего прогнозного значения х р. Точное уравнение регрессии нам неизвестно. Поэтому мы не можем сделать точный прогноз. Можно только утверждать, что прогнозное значение результата у р при данном х р с вероятностью γ попадет в доверительный интервал γр. Вероятность γ называется уровнем надежности. Ошибка прогноза составляет:
где Предельная ошибка прогноза, составит:
Доверительный интервал прогноза:
Точность прогноза можно оценить с помощью относительной ошибки прогноза:
Порядок выполнения работы. Используя данные к лабораторной работе №1 при х р=20: 1. найти уравнение регрессии; 2. рассчитать доверительный интервал прогноза при значениях уровня надежности 80%, 90%, 95%; 3. найти относительную ошибку прогноза; 4. построить графики линии регрессии с доверительными границами.
Пример выполнения лабораторной работы. Расчеты для каждого из уровней надежности производить на отдельных листах, которые назовем , соответственно: 80%, 90%, 95%. I. Лист 80%. 5. В диапазоне А2:C11 подготовим исходные данные. 6. В ячейку В12 запишем значение хр=15,5, для которого необходимо спрогнозировать значение результата ур. 7. Вводим следующие формулы:
8. Для графического представления полученных результатов: · Вводим следующие формулы:
Таким образом получим данные, представленные на рис. 1.4. · Выделим одновременно диапазоны В2:С11, E2:E11, H2:I11 (поскольку эти диапазоны несмежные, при этом должна быть нажата клавиша Ctrl); · Вызовем Мастер диаграмм. Чтобы ось отражала фактические данные, выберем тип диаграммы Точечная; · Для добавления на диаграмму прогнозируемых значений в Мастере диаграмм на шаге 2 перейдем на вкладку Ряд (рис. 2.4). Щелкнем по кнопке Добавить и введем с помощью левой кнопки мыши: Имя − Прогноз, Значения Х – В12, Значения Y – С29. Щелкнув по кнопке Готово, получим диаграмму, представленную на рисунке 3.4.
Отформатируем диаграмму. Для этого щелкнем дважды по фону и выберем заливку прозрачная, затем щелкнем дважды по линии регрессии и выберем тип линии, цвет и толщину, а переключатель маркера поставим в положение отсутствует. Аналогичным образом форматируются линии, представляющие границы доверительных интервалов, и точки, отображающие прогнозируемые значения. В итоге получим диаграмму, представленную на рис. 4.4.
II. Лист 90% и 95%. Чтобы получить расчеты для уровней надежности 90% и 95%, достаточно скопировать лист 80% на листы 90% и 95% и ввести на них в ячейку С21 соответственно значения 0,9 и 0,95. При этом диаграммы, полученные при таком копировании, следует удалить и построить заново на основе расчетов, полученных на листах 90% и 95% (рис. 5.4 и 6.4).
Рис. 1.4. Прогнозирование на основании линейной модели при уровне надежности 80%
Рис. 2.4. Шаг 2 Мастера диаграмм
Рис. 3.4. Диаграмма, построена с помощью Мастера
Рис. 4.4. Итоговый вид диаграммы при уровне надежности 80%
Рис. 5.4. Прогнозирование на основании линейной модели при уровне надежности 90%
Рис. 6.4. Прогнозирование на основании линейной модели при уровне надежности 95%
Сравним относительные погрешности прогнозов при различных уровнях надежности, для х р=15,5:
Повышение уровня надежности с 80% до 95% снижает точность прогноза в 19,6/11,7≈1,68 раза.
Лабораторная работа №1. Простейшая обработка данных. Линейная регрессия. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Последнее изменение этой страницы: 2019-04-20; Просмотров: 1498; Нарушение авторского права страницы
 .
.
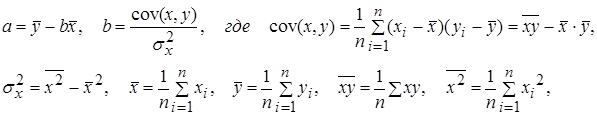
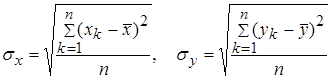 .
.
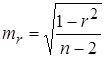 .
. , выборочные дисперсии
, выборочные дисперсии  исправленные средние квадратические отклонения
исправленные средние квадратические отклонения  .
.
 . Для этого в ячейку Е16 вводим формулу
. Для этого в ячейку Е16 вводим формулу







 , а также средняя ошибка аппроксимации.
, а также средняя ошибка аппроксимации. .
. раскладывается на две части – «объясненную» и «необъясненную»:
раскладывается на две части – «объясненную» и «необъясненную»:
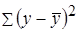 – общая сумма квадратов отклонений;
– общая сумма квадратов отклонений; 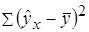 – сумма квадратов отклонений, объясненная регрессией (или факторная сумма квадратов отклонений);
– сумма квадратов отклонений, объясненная регрессией (или факторная сумма квадратов отклонений);  – остаточная сумма квадратов отклонений, характеризующая влияние неучтенных в модели факторов.
– остаточная сумма квадратов отклонений, характеризующая влияние неучтенных в модели факторов.

 при уровне значимости α и степенях свободы k1 = m и k2 = n – m - 1. При этом, если фактическое значение F -критерия больше табличного, то признается статистическая значимость уравнения в целом.
при уровне значимости α и степенях свободы k1 = m и k2 = n – m - 1. При этом, если фактическое значение F -критерия больше табличного, то признается статистическая значимость уравнения в целом.
 , и ее можно рассчитать по следующей формуле:
, и ее можно рассчитать по следующей формуле:

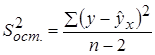 – остаточная дисперсия на одну степень свободы.
– остаточная дисперсия на одну степень свободы. которое затем сравнивается с табличным значением при определенном уровне значимости α и числе степеней свободы (n - 2). Доверительный интервал для коэффициента регрессии определяется как
которое затем сравнивается с табличным значением при определенном уровне значимости α и числе степеней свободы (n - 2). Доверительный интервал для коэффициента регрессии определяется как  .
.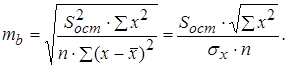
 , его величина сравнивается с табличным значением при n - 2 степенях свободы. Доверительный интервал для коэффициента регрессии определяется как
, его величина сравнивается с табличным значением при n - 2 степенях свободы. Доверительный интервал для коэффициента регрессии определяется как  .
.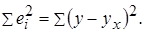
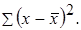
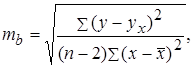
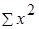
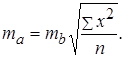
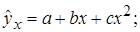
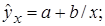
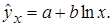
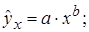
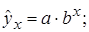
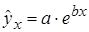 .
.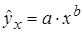 , показательная –
, показательная – 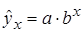 , экспоненциальная –
, экспоненциальная – 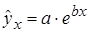 , обратная –
, обратная – 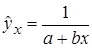 .
.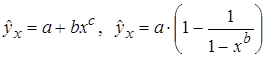 .
.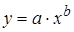
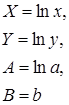
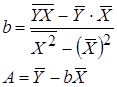
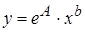
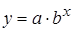
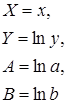
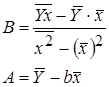
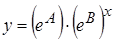
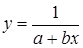
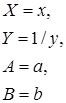
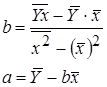
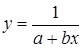
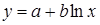
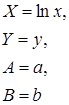
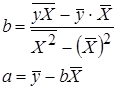
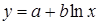
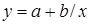
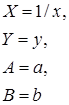
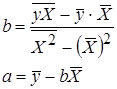
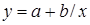
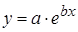
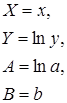
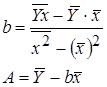
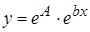
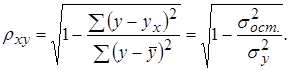
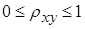 .
.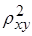 .
.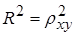 – квадрат индекса корреляции –
– квадрат индекса корреляции –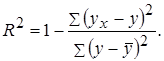
 .
Копируем диапазон E3:E11
.
Копируем диапазон E3:E11
 .
. .
Копируем диапазон I3:I11
.
Копируем диапазон I3:I11



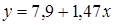

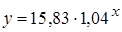
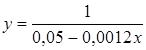


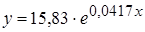
 ,
,
 - стандартная ошибка регрессии (дисперсия ошибки или остаточная дисперсия).
- стандартная ошибка регрессии (дисперсия ошибки или остаточная дисперсия).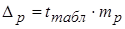 .
. .
.