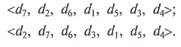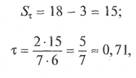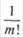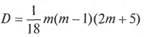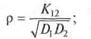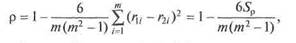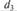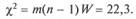|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Методы обработки и анализа экспертных оценок
Основными задачами обработки и анализа экспертных оценок являются [12, 36, 50, 57, 69]: 1) оценка степени согласованности мнений экспертов; 337 2) получение коллективного (обобщенного) мнения экспертной группы; 3) выделение подгрупп экспертов с близкими мнениями; 4) оценка и учет компетентности экспертов. Эти задачи, кроме последней, перечислены в той последовательности, в которой они должны решаться на практике. Действительно, прежде чем получать обобщенное мнение, следует убедиться в достаточно высокой согласованности мнений экспертов. Если такая согласованность отсутствует, то «усреднение» всех мнений противоречило бы исходной предпосылке о том, что ответы экспертов лишь случайно и независимо отклоняются от некоторой истинной единственно правильной точки зрения, которую и надлежит выявить при экспертизе. При этом обобщенное мнение будет неустойчивым в том смысле, что небольшие изменения обрабатываемого материала (например, исключение оценок нескольких экспертов или добавление новых) могут его значительно изменить. Таким образом, при невысокой согласованности мнений экспертов вначале следует выделить наиболее оригинальные из них и разбить экспертную группу на подгруппы экспертов с близкими мнениями. Общее мнение необходимо получать для каждой из таких подгрупп «усреднением» мнений ее членов. После этого необходимо провести содержательный анализ полученных результатов и выяснить причины наличия нескольких точек зрения. Оценку и учет компетентности экспертов следует проводить до или в процессе выработки решения. Оценка степени согласованности мнений экспертов. Обработка и анализ ранжировок. Рассмотрим методы анализа экспертных оценок, получаемых в результате ранжирования т заданных объектов из множества предъявления (см. формулу (24.1)). Каждый эксперт располагает эти объекты по убыванию или возрастанию интенсивности проявления некоторого признака. Как уже указывалось, полученные таким путем упорядоченные наборы объектов называют ранжировками. Каждой ранжировке соответствует вполне определенный квазипорядок R на множестве объектов D. Этот квазипорядок можно задать одним из рассмотренных ранее способов. Рассмотрим случай, когда каждый эксперт все объекты ранжирует строго. В теории и практике экспертного оценивания рангом /} объекта dj при прямом ранжировании принято считать номер места, которое он занимает в строгай ранжировке. Например, для ранжировки < d2, d}, dx > имеют r2 = 1, гъ = = 2,'/i = 3. Понятно, что ранг /}• показывает, что впереди dj стоит объект dj_ [. Сумма всех рангов гх + г2 + ... + гт равна т(т + 1)/2 (как сумма арифметической прогрессии 1 + 2 + ... + т). Оценка согласованности мнений двух экспертов. Ранжировки, указанные разными экспертами, редко полно- 338 стью совпадают, поэтому необходимо оценить степень соответствия (согласованности, согласия) мнений двух экспертов. В статистике зависимость между двумя переменными характеризуется коэффициентом корреляции. Применительно к рассматриваемому случаю оценки согласованности двух ранжировок такой коэффициент должен обладать следующими свойствами: 1) если обе ранжировки полностью совпадают, т.е. если каждый объект занимает в них одно и то же место, то коэффициент равен +1; 2) если одна ранжировка противоположна другой, т. е. в одной из них объекты расположены в обратном порядке по сравнению с другой, то коэффициент равен -1; 3) в остальных случаях значение коэффициента лежит между предельными значениями, причем его возрастание от -1 до +1 в некотором смысле характеризует увеличивающееся согласие между двумя ранжировками. Вид коэффициента корреляции зависит от того, как конкретизируется третье из указанных требований. В практике проведения различных экспертиз наиболее распространенными являются коэффициенты ранговой корреляции Кендалла (х) и Спирмена (р). Выясним, как определяется первый из этих коэффициентов. Рассмотрим ранжировки двух экспертов: <dn, dn, •••, dXm> и <d2\, d22, ■■-, d2m>. Возьмем какую-либо пару объектов (db dt). Если в обеих ранжировках порядок расположения этих объектов совпадает (например, 1-й объект стоит впереди t -то), то пару {dh dt) называют согласованной. В противном случае пара является несогласованной. Известно, что из т объектов можно выбрать всего
разных пар. Если обозначить через S+ число согласованных, а через S~ — число несогласованных пар, то чем больше число S+, тем выше согласованность ранжировки. Заметим, что сумма согласованных и несогласованных пар равна их общему возможному числу, т. е. С2т. Естественно, степень согласованности мнений экспертов оценивать разностью
При этом ее знак указывает, каких пар больше — согласованных или несогласованных. Нормирование этой разности общим числом возможных пар обеспечит выполнение третьего требования к коэффициенту согласованности, т. е. его нахождения в пределах от -1 до +1. Первые два требования выполняются по услови- 339 ям введения коэффициента. Итак, коэффициент Кендалла рассчитывается по формуле:
В частности, если ранжировки совпадают, то S+ = C2m, S~ = О и ST = С2т, а коэффициент т равен единице. Если же одна ранжировка обратна другой, то S+ = О, $~ - Сгт и Sz = -C]m а коэффициент Кендалла х = -1. В качестве примера рассмотрим две ранжировки семи экономических объектов:
Выпишем все возможные пары объектов
рассортировав их по типам: 1) согласованные пары: (d{, d2); (du d4); (d\, d5); (du d6); (du 2) несогласованные пары: (db d3); (d2, d-i); (d3, ds).
т.е. степень согласованности экспертов достаточно высокая. Существует другой способ определения числа согласованных пар. Для тех же ранжировок ранги объектов представлены в табл. 24.2. Таблица 24.2 Исходная таблица рангов объектов
340 Таблица 24.3 Итоговая таблица рангов объектов
Переставив столбцы в табл. 24.2 таким образом, чтобы у эксперта 1 ранги располагались по возрастанию, получим табл. 24.3. Понятно, что S+ равно числу таких пар рангов (г,-, rj), где rt < /}•, которые в последней строке табл. 24.3 расположены в возрастающем порядке. Первым в третьем столбце стоит ранг 2. Правее него имеется пять превосходящих его чисел. Правее ранга 1 — также пять чисел, каждое из которых больше единицы. Правее ранга 3 стоит четыре числа, каждое из которых больше трех. Правее ранга 5 — всего два превосходящих его числа, правее ранга 6 — одно и правее ранга 4 — тоже одно. Таким образом,
В итоге получаем уже известный результат: х = 0,71. Если мнения двух экспертов близки, то указанные ими ранжировки будут мало отличаться от «истинной» и коэффициент корреляции окажется высоким. Однако практически рассуждения приходится вести в обратном порядке, т. е. о близости мнений судить по корреляции ранжировок, которые эти мнения выражают. Для решения поставленного вопроса используется подход, связанный с проверкой статистических гипотез. Предположим, что хотя бы один из экспертов полностью некомпетентен и независимо от другого случайным образом с одинаковой вероятностью указывает одну из т\ возможных строгих ранжировок т объектов. При справедливости этого допущения или нулевой гипотезы Щ коэффициент х оказывается случайной величиной. Распределение оказывается симметричным относительно математического ожидания М[т] = 0, причем чем больше по абсолютной величине возможное значение х, тем меньше вероятность получить это значение. Поскольку нас интересует вероятность получения больших значений, то критическая область, соответствующая уровню значимости а, задается неравенством х > ха. Однако с целью некоторого упрощения вычислений используют равносильное неравенство ST > Sa. 341 Справедливость нулевой гипотезы проверяют обычным порядком при помощи специальных таблиц. Эти таблицы дают значения вероятности а = Р($х > Sa) при различных значениях т и Sx. При т > 10 распределение % весьма близко к нормальному с нулевым математическим ожиданием и дисперсией
и можно использовать таблицы функции Лапласа Fx стандартного нормального распределения N(0, 1), так как
Для рассмотренных ранжировок было получено достаточно высокое значение х = 0,71, причем Sx = 15. Табличное значение вероятности а = P(SX > 15) = 0,015. Эта вероятность весьма незначительна, поэтому можно считать, что мнения экспертов действительно хорошо согласованы (т.е. высокая согласованность мнений экспертов скорее всего неслучайна).
Коэффициент ранговой корреляции р по Спирмену определяется по обычно используемой в теории вероятностей формуле для расчета коэффициента корреляции дискретных случайных величин: где Kyi — корреляционный момент.
Для упрощения расчетов обычно используют другую формулу, полученную в результате алгебраических преобразований: Как и всякий статистический коэффициент корреляции р изменяется от -1 до +1. Равенство р = +1 соблюдается при полном совпадении ранжировок, а равенство р = -1 имеет место, когда ранжировки противоположны друг другу. Проверка значимости согласованности двух ранжировок с использованием р осуществляется в том же общем порядке, который был описан ранее. При справедливости нулевой гипотезы распределение р симметрично относительно М[р] = 0, причем с ростом абсолютной величины возможного значения р вероятность его получения падает. Поэтому критическая область определяется неравенством р > ра. При небольших т (до 10) пользуются таблицами вероятностей Р($р > $), учитывая, что
а при т > 10 можно исходить из того, что распределение величины
весьма близко к распределению Стьюдента с т - 2 степенями свободы. При т > 30 распределение р практически совпадает с нормальным, имеющим нулевое математическое ожидание и дис- 1 Вернемся к последнему рассмотренному примеру. В табл. 24.4 приведены данные для расчета коэффициента Спирмена.
Суммировав значения в последней строке, получим Sp = 8 и Таблица 24.4 Исходные ранжировки и данные для расчета коэффициента р
343 равно 0,0062, так что гипотезу о независимости мнений экспертов следует отвергнуть. Мерой согласованности двух ранжировок может служить не только тот или иной коэффициент ранговой корреляции, но и расстояние d между квазипорядками, соответствующими этим ранжировкам. Расстояние d с рассмотренными коэффициентами корреляции соотносится так:
Следовательно, если оценку согласованности ранжировок осуществлять при помощи расстояния d, то проверку значимости степени согласованности можно проводить при помощи статистики х [59]. Оценка согласованности мнений п экспертов. Пусть перед каждым из п членов экспертной группы поставлена задача строго ранжировать т объектов из некоторого множества предъявления D. В результате опроса будет получено п строгих ранжировок этих объектов. Полученные ранжировки можно представить соответствующими последовательностями рангов:
где Гу — ранг, присвоенный объекту dj i -м экспертом. Степень согласованности мнений всех экспертов можно выразить через оценки близости мнений для отдельных пар экспертов, т.е. при помощи коэффициентов ранговой корреляции х или р.
Поскольку из экспертной группы можно выбрать всего
Чем выше согласованность мнений всех экспертов, тем больше значения введенных коэффициентов. В частности, если мнения экспертов полностью совпадают, т.е. каждый из них указал одну и ту же ранжировку, то т и р принимают свое наибольшее значение, равное единице. Также можно вычислить и дисперсии парных коэффициентов корреляции, которые также будут характеризовать степень групповой согласованности мнений. Однако вычислять средние значения тир ранговых коэффициентов и, тем более, их дисперсии весьма трудоемко, поэтому для оценки согласованности экспертов пользуются специальными показателями, называемыми коэффициентами конкордации (согласованности). Наиболее известным является коэффициент конкордации Кендалла W, который вводится следующим образом:
где
По физическому смыслу коэффициент конкордации Кендалла представляет собой некоторую обобщенную дисперсию Sw разброса мнений экспертов относительно среднего мнения
нормированную своим наибольшим значением
Коэффициент конкордации Кендалла меняется в пределах от нуля (или близкого к нулю значения в зависимости от четности и нечетности т и п) в случае наименьшей согласованности мнений, до единицы в случае абсолютной согласованности. Обратите внимание, что при оценке согласованности мнений нескольких экспертов понятие «противоположность мнений» теряет свой смысл, столь характерный для возможной полярности мнений двух экспертов. Пример. Десять экспертов ранжировали по значимости следующие четыре показателя, характеризующие эффективность инвестиционных проектов: dx — объем инвестиций; d2 — срок окупаемости; йъ — чистый 345 Таблица 24.5 Результаты ранжирования четырех показателей
дисконтированный доход; J4 — рентабельность инвестиций. Результаты ранжирования сведены в табл. 24.5. Поскольку Sw~ 118, то W~ 0,236. Так как число экспертов достаточно велико (больше семи), то вычислим %2 = т(п - l)W= 10 ■ 3 ■ 0,236 = 7,08. При уровне значимости а = 0,05 по таблице функции %2 распределение для п - 1 = 3 степеней свободы находим х2005 ~ 7,8, так что %20>05 > 7,08. Следовательно, нулевую гипотезу отклонять нет оснований, т. е. получено, что степень согласованности мнений экспертов W= 0,236 не только мала, но и незначима (это означает, что либо для решаемой задачи информационная база недостаточна, либо если информационная база достаточна, в экспертную группу включены некомпетентные специалисты, чьи оценки показателей эффективности инвестиционных проектов по каким-то причинам весьма различаются). Согласованность мнений экспертов можно также оценить, подсчитав среднее расстояние d между парами квазипорядков Д, соответствующих полученным ранжировкам (подобно тому подходу, который рассматривался применительно к получению осред-ненных коэффициентов тир). Напомним, что в качестве расстояния d между бинарными отношениями R', R" часто используют метрику Хемминга, определяемую как количество порязряд-ных несовпадений элементов соответствующих матриц смежности этих отношений:
346 Обработка и анализ балльных и точечных оценок. Пусть перед каждым экспертом была поставлена задача: непосредственно оценить заданные объекты dx, d2, ..., dm по установленной балльной шкале. Тогда в результате опроса экспертной группы, включающей п членов, будет получена совокупность чисел:
где by — число баллов, приписанное экспертом i объекту dj. Как уже отмечалось, балльная шкала является промежуточной между порядковой и интервальной. Специальных методов обработки оценок, полученных по подобного рода промежуточным шкалам, пока не создано. Поэтому при обработке балльных оценок поступают следующим образом. Если имеется уверенность, что все эксперты пользуются единой балльной шкалой (одинаково понимают цену балла), как это бывает, например, при наличии специальных эталонов, то балльная шкала приближается к интервальной и балльные оценки обрабатывают как количественные (о чем будет сказано далее). В противном случае балльные оценки считают качественными, объекты ранжируют в соответствии с оценками каждого эксперта и затем обрабатывают полученные п ранжировок методами, изложенными ранее. Однако и в первом случае целесообразно дважды обработать балльные оценки: как количественные и как качественные. Согласованность результатов, полученных при обоих подходах, будет свидетельствовать о том, что эти результаты действительно основаны на исходных данных, а не на способах их обработки. Если считать, что оценки количественные, то в соответствии с исходным допущением о том, что разница в ответах экспертов объясняется случайными независимыми флуктуациями относительно некоторых «истинных» величин, для обработки экспертных данных можно использовать обычные статистические методы точечного оценивания. Каждому объекту dj следует приписать средний балл:
Эти оценки и принимаются в качестве групповых. Согласованность мнений экспертов можно характеризовать дисперсиями бал- 347 льных оценок, приписываемых отдельным объектам. Оценки таких дисперсий вычисляются по известным формулам. При положительных балльных оценках часто используют так называемые вариации (коэффициенты вариации vj) и полагают, что согласованность экспертов удовлетворительная, если все vj < 0,3, и хорошая, если все ц < 0,2. Выделять «оригинальных» экспертов на основе их «нестандартных» баллов можно известными статистическими методами проверки аномальности результатов наблюдений. Аналогичным образом обрабатываются и точечные оценки, полученные по различным количественным шкалам. Заметим, что для точечных оценок широко применяется интервальное оценивание, позволяющее по результатам обработки указать интервал изменения оцениваемого параметра, в который «истинное» значение попадет с заданной вероятностью. Кроме того, аппарат статистики дает возможность оценить «аномальность» оценок некоторых экспертов, о чем речь пойдет далее. Обработка и анализ попарных сравнений. Рассмотрим названную задачу применительно к обработке результатов попарного сравнения с градациями. Как отмечалось, оценки попарной предпочтительности элементов множества предъявления из заданной (фиксированной) шкалы эксперт помещает в квадратную матрицу оценивания размерностью тхт. Поскольку попарное сравнение не требует соблюдения транзитивности, для обработки применяют итерационный метод Зейделя, позволяющий сначала оценить коэффициенты относительной важности каждого элемента множества предъявления, а затем по ним установить их ранжировку. Рассмотрим алгоритм метода. Шаг 0. Все объекты считаются равноценными:
Шаг 1. Коэффициенты относительной важности пересчитыва-ются по формуле
По сути, на первом шаге оценки суммируются построчно, а каждый коэффициент относительной важности рассчитывается путем деления на «сумму сумм» — общую сумму оценок, выставленных экспертом. 348 Шаг к. Коэффициенты относительной важности к-то приближения рассчитываются по рекуррентной формуле:
Возможны два условия останова алгоритма: либо заданное (требуемое) число шагов, либо достижение заданной (требуемой) точности вычислений:
Метод Зейделя, как правило, сходится весьма быстро — за две-три итерации, поэтому чаще используют первое условие прекращения вычислений. Итоговую ранжировку объектов определяют путем установления двойного соответствия: сначала ранжируют коэффициенты относительной важности, начиная с самого большого, ставя ранги от единицы до т; затем по полученным рангам переходят к ранжировке объектов множества предъявления. В общем случае таким образом определяется нестрогая ранжировка.
Пример. Пусть эксперт оценил попарную предпочтительность пяти экономических объектов и составил матрицу оценки: Результаты применения метода Зейделя для данного случая приведе Таблица 24.6 Результаты по методу Зейделя
Очевидно, что уже после второй итерации коэффициенты относительной важности практически остаются неизменными. На основании этих коэффициентов получаем итоговую ранжировку: d5 > d{ >йъ > d2 >- d4. Подобным образом обрабатывают и результаты традиционного (классического) попарного сравнения, используя, учитывая весьма низкую точность измерения предпочтительности, только результаты первой итерации. (Часто так поступают и при попарном сравнении с градациями, особенно в условиях отсутствия вычислительных задач, реализующих более точные алгоритмы.) Обобщение мнений экспертов. К решению этой задачи можно приступать лишь при достаточно высокой и статистически значимой согласованности мнений членов экспертной группы. В противном случае требуется дополнительная обработка (см. следующий пункт). Один из подходов к решению этой задачи состоит в том, чтобы групповой считать ранжировку, наиболее тесно коррелированную с п обрабатываемыми ранжировками. Другой подход состоит в том, чтобы групповую ранжировку искать как медиану индивидуальных. Наиболее простым в вычислительном отношении является метод сумм рангов, поэтому он значительно шире распространен на практике. Данный метод заключается в суммировании рангов объектов множества предъявления, выставленных каждым экспертом, и определении групповой (обобщенной) ранжировки на основе суммарных рангов. Групповая ранжировка может оказаться нестрогой даже при использовании каждым экспертом строгого ранжирования. Пример. Получены строгие (прямые) ранжировки пяти объектов 10 экспертами (табл. 24.7). Рассмотрим результаты обработки этих ранжировок. 350 Таблица 24.7 Ранжировки объектов экспертами
1. Результаты расчета коэффициента конкордации Кендалла следу Таким образом, степень согласованности мнений экспертов средняя. 2. Проведем статистическую проверку значимости степени согласо Рассчитаем значение %2:
Зададим уровень значимости а = 0,05. Тогда для числа степеней свободы п - 1 = 4 пороговое значение х2 распределения равно
Результаты статистической проверки показывают, что %2 = 22,32 больше xl = 9,49. Следовательно, степень согласованности мнений экспертов значима. 3. Выработаем коллективное мнение группы экспертов (табл. 24.8). значимой степени согласованности их частных ранжировок. Таблица 24.8 Выработка коллективного мнения
Таким образом, итоговая ранжировка имеет вид: d5 у d4 у d{ у d2 у d3. Заметим, что можно использовать и обратное ранжирование, но тогда групповая ранжировка, естественно, будет обратной: йъ у d2 у d] у d4 у d5. Поэтому так важно при постановке задачи экспертной группе четко определить конкретный способ выражения предпочтений каждым экспертом. Определение групповых ранжировок при использовании других способов выражения предпочтений экспертов также основано на усреднении соответствующих оценок (балльных, точечных, непосредственных числовых) и построении на основе средних результатов обобщенной ранжировки. Еще раз подчеркнем: подобным образом получать обобщенное мнение экспертов можно только в случае высокой (средней) и значимой согласованности мнений отдельных членов группы. Применение такого подхода при значительном расхождении частных мнений может привести к абсурдным результатам. Проиллюстрируем это таким примером. Пусть два эксперта выдали строгие ранжировки пяти объектов (табл. 24.9). Поскольку, очевидно, эти ранжировки свидетельствуют о противоположности мнений экспертов, оба ранговых коэффициента корреляции равны -1. Если же, несмотря на это, попытаться использовать суммарные ранги, то результат должен быть интерпретирован так: «оба эксперта считают все объекты равными по предпочтению». Но это совершенно неверно — ни один из экспертов так не считает! Следовательно, совершено несколько ошибок при обработке и анализе результатов экспертизы: не учтена оценка согласованности мнений экспертов, неверно выбран способ обобщения мнений и вследствие этого неправильно интерпретированы результаты. Выделение подгрупп экспертов с близкими мнениями. При слабой степени согласованности мнений группы экспертов следует провести содержательный анализ причин расхождения мнений специалистов. Наиболее распространенными причинами являются: • наличие в группе экспертов с нестандартными (оригинальными) мнениями; Таблица 24.9 |
Последнее изменение этой страницы: 2019-05-08; Просмотров: 435; Нарушение авторского права страницы