
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Взаимосвязь размерности алфавита классов и эффективности СР
Мы пока еще не затрагивали вопросов такой взаимосвязи, хотя как алфавит классов, так и словарь признаков определили и имеем представление о их выборе. Однако, обсуждение вопросов составления словаря признаков и выбора алфавита классов никак не затрагивало их взаимосвязи. В то же время мы понимаем, что наличие связей двух явлений, объектов, процессов вообще достаточно часто позволяет выяснить некоторые ограничения составляющих. Попытаемся их поискать для таких объектов, как словарь признаков и алфавит классов. Оказывается, что отмеченные особенности и приведенные определения назначения и цели создания СР уже определяют взаимосвязи между классами и принимаемыми решениями. Рассмотрим, какие же это взаимосвязи, в чем их существо. Очевидно, главное, что накладывает на них отпечаток - это необходимость достижения высокой эффективности решений.
Отсюда можно утверждать, что в управлении высокая эффективность решений достигается:
1)Увеличением числа классов в принятом алфавите, то есть, повышением степени детализации распознаваемых объектов (явлений) по назначению и характеру. При этом чем детальнее классификация, тем легче предпринять адекватное управление. ( Вполне понятно, что распознать просто отказ двигателя автомобиля менее привлекательно, чем указать на выход из строя клапана или масляного насоса).
2)Повышением точности определения признаков распознавания, а значит снижением возможности ошибочных решений, часто опасных для управления (снижение ошибок классификации). Так, если ошибки измерения координат падающего КО большие, то можно как ошибочно самоуспокоиться, предполагая точку падания за пределами интересующей нас зоны ответственности, так и ошибочно объявить тревогу и даже вызвать панику.
В то же время увеличение числа классов в любой задаче, как можно понять только из соображений здравого смысла ( в дальнейшем мы это опишем более строго математически) не всегда просто, а иногда оказывается и невозможно. Но существует одна ситуация, когда это увеличение всего на один класс бесспорно важно. Так для того, чтобы результаты распознавания были более приемлемы для последующего управления, приходится дополнительно к имеющимся m классам вводить (m+1)-ый, когда отказываются от распознавания, а значит и от управления. Отказ от управления лучше, чем управление при ошибочности распознанной ситуации (если это возможно по назначению системы). Теперь постараемся понять имеющиеся связи, рассматривая отношения между числом классов и ошибками распознавания. Для удобства рассматриваем одномерный случай (вместо вектора признаков без ущерба для задачи, но для ясности физических представлений, имеем один признак.
Пусть заданы три класса объектов W1, W2, W3
- распределениями вероятностей f(x/W1), f(x/W2 ), f(x/W3 ), где x - вероятностный признак распознавания; - априорными вероятностями P(W1), P(W2), P(W3); - матрицей потерь при решениях
Теперь поймем, что если априорная вероятность отнесения объекта к i-му классу, в то время как он принадлежит к j-му классу (то есть, априорная вероятность ошибки) равна P(Wi /Wj ), то среднее значение платы за ошибочную классификацию всех m объектов в системе распознавания определяется как условное МОЖ потерь (зависимость от Wj
В целом средние потери классификации (то есть, потери по всем классам) определяются как среднее
Остается определить вероятность P(Wi /Wj ), так как априорное описание классов напрямую не дает ее значений. Изобразим ситуацию классификации в рассматриваемом нами примере в виде функций ПРВ параметра распознавания
a b X Рис. 4.1.1
Если теперь определить области возможного разброса параметра распознавания каждого класса как Gi, то легко определить записанную нами вероятность ошибки так
Обозначим указанные области Gi на рисунке. Здесь эти области в силу одномерности случая должны представлять собой отрезки. Поэтому достаточно указать границы
а - граница между 1-ым и 2-ым классами; b - граница между 2-ым и 3-им классами
Соответственно отрезки:
1-го класса ]- ¥ +a]; 2-го класса ]+a +b]; 3-го класса ]+b + ¥ [.
Теперь можно записать в соответствии с приведенной формулой условные риски ошибочных решений
Отсюда средний риск ошибочных решений в системе распознавания (то есть, риск ошибочной классификации всех классов):
Для простоты рассмотрения принимаем Сii = 0, Cij = C, Pi = P и, пользуясь рисунком, получим
Здесь обозначен средний риск индексом " 1", так как теперь рассмотрим вторую ситуацию, для которой постараемся уменьшить число классов, объединяя первый и второй классы в один - четвертый. Определим по правилам теории вероятностей ПРВ четвертого класса по ПРВ первого и второго классов
До этого мы упрощали представление вероятностей и плат за ошибки для трех классов. Добавим к этому и четвертый класс
C44=0; C14 =C41 = C.
На рисунке ПРВ классов изобразим ПРВ четвертого класса (пунктир).
Теперь можно записать, как и в первом случае (три класса), условные риски ошибочных решений для оставшихся 3-го и 4-го классов
(Условные риски R1 и R2 здесь отсутствуют, так как произошло объединение 1-го и 2-го классов в 4-ый. Кроме того, матрица плат за ошибки с учетом четвертого класса приняла сначала следующий вид
а затем из нее за счет того же объединения исключили столбцы и строки, имевшие индексы " 1" и " 2". В результате получили:
Средний риск для случая двух оставшихся классов W3 и W4 обозначим индексом " 2" и также, как для первого случая, после простых преобразований получим
Теперь, если подставим сюда вместо ПРВ f(x/W4) его выражение, определенное уже нами, то получим
Наконец мы можем сравнить средний риск R1 и R2 __ __ R1 > R2
Вывод: При заданном признаковом пространстве и прочих равных условиях уменьшение числа классов приводит к меньшению ошибок распознавания.
Следствие: При увеличении числа классов для уменьшения среднего риска (через уменьшение вероятности ошибочных решений) необходимо включать в состав словаря признаков такие, которые имеют меньший разброс. Действительно, для рассмотренного нами одномерного случая по приведенному рисунку можно проследить, что вероятности ошибочных решений снижаются, если распределения имеют меньший разброс. То есть, при этом опять-таки уменьшается риск ошибочных решений в системе и тем самым достигается большая эффективность, но теперь уже без уменьшения числа классов.
Л е к ц и я 4.2
|
Последнее изменение этой страницы: 2019-10-03; Просмотров: 207; Нарушение авторского права страницы


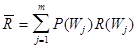
 для трех классов (Рис 4.1.1)
для трех классов (Рис 4.1.1)


 f(x/Wi)
f(x/Wi)


















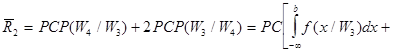
 .
.