
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
КОНЕЧНЫЕ АВТОМАТЫ И РЕГУЛЯРНЫЕ ЯЗЫКИ
Тема 1. Синтаксис языков Алфавит, слово, язык Рассмотрим самое простое понятие теории языков — понятие алфавита. Алфавит — это произвольное непустое конечное множество V = {а 1, ..., а n}, элементы которого называют буквами или символами. Обычно задают определенную нумерацию алфавита (как, скажем, для русского алфавита: «а» — первая буква, «б» — вторая и т. д. до 33-й — «я»). Впредь договоримся, фиксируя алфавит, записывать его буквы в порядке их номеров. Определение 7.1. Словом или цепочкой в алфавите V называют произвольный кортеж из множества Vk( k -й декартовой степени алфавита V ) для различных k = 0, 1, 2,... Например, если V = { a , b , c }, то (а ), ( b ), (с ), (а, b ), (а, b , с ), (с, b , a , а, с ) и т. д. есть слова в V . При k = 0 получаем пустой кортеж, называемый в данном контексте пустым словом или пустой цепочкой и обозначаемый λ . Множество всех слов в алфавите V обозначают V * , а множество всех непустых слов в V — как V +. Слова, ради удобства чтения и простоты записи, будем записывать без скобок и запятых (ср. с записями кортежей). Так, для записанных выше слов получим: а, b , с, ab , abc , cbaac . Такая запись слова согласуется с его интуитивным пониманием как цепочки следующих друг за другом символов. Тогда пустое слово — это слово, не имеющее символов, «пустой лист бумаги», на котором еще ничего не написано. По определению, длина слова ω — число компонент кортежа, т. е. если ω ∈ V r, то длина слова ω равна r . Длину слова ω договоримся обозначать | ω |. Ясно, что для пустого слова | λ | = 0. Длину слова тем самым можно понимать как число составляющих это слово букв. Докажем, что множество V * счетно. Для этого достаточно построить какую-либо нумерацию этого множества. Рассмотрим здесь нумерацию, называемую лексикографической. В данной нумерации пустому слову присваивается номер 0, а буквам a 1, ..., апалфавита V — номера 1, ..., п соответственно. Если слово х имеет лексикографический номер lx, то слову х aiприсваивается номер nlx+ i . Отсюда следует, что лексикографический номер слова
Заметим, что последняя сумма напоминает запись числа в системе счисления по модулю n (мощности алфавита) с тем липа, различием, что используется цифра п, но не допускается цифра 0. Итак, по любому слову в алфавите V однозначно вычисляется его лексикографический номер. Обратно, любое натуральное число однозначно раскладывается по степеням п указанным выше образом. Действительно, если дано число N , то при 0 ≤ N ≤ n оно служит номером пустого слова ( N = 0) или некоторой буквы алфавита. Иначе представим N в виде N = k 1n + r 0, где 1 < r 0< п. Если k 1≤ n , то N есть номер слова С числом k 2поступаем точно так же, как и с k 1. После конечного числа шагов получим разложение числа N в виде
где каждое число ri(0 ≤ i ≤ m ) находится в диапазоне от 1 до п. По полученному разложению N однозначно восстанавливается слово в V , имеющее номер N:
Пример 7.1. Вычислим номер слова cbaac в алфавите { a , b , с }. Имеем З4· 3 + З3· 2 + З2· 1 + З1· 1 + 3 = 279. Решим обратную задачу, найдя слово в данном трехбуквенном алфавите, имеющее номер 321. Согласно приведенному выше алгоритму, получим
Следовательно, искомое слово есть cbbac. Лексикографическая нумерация напоминает способ упорядочения слов в словарях: однобуквенные слова следуют в порядке номеров букв в алфавите, среди двух двухбуквенных слов меньший номер имеет слово, начинающееся буквой с меньшим номером, и т. д. Но полного совпадения нет, так как в словаре слова группируются по начальной букве, а не по длине. Нам будет удобно в дальнейшем использовать следующую запись непустого слова х в алфавите V по буквам: x = x (1) x (2)… x ( k ), где x ( i ), 1 ≤ i ≤ k , — i -я буква слова х. Определение. Языком в алфавите V называется произвольное подмножество множества V *. Множество всех языков в алфавите V , т. е. множество 2 V*, есть булеан счетного множества, и, следовательно, оно в силу теоремы Кантора имеет мощность континуума. Наша следующая задача — определить на множестве 2 V*всех языков в произвольном (но фиксированном! ) алфавите V алгебраическую структуру. На множестве 2 V*можно определять различные операции. Прежде всего языки — это множества, следовательно, над ними можно производить все те же операции, что и над множествами: объединение, пересечение, разность, дополнение и т. п. Универсальное множество в данном случае есть множество слов V * , которое называют универсальным языком. Кроме перечисленных теоретико-множественных операций можно рассматривать и специальные операции над языками. Прежде чем обратиться к этим операциям, определим операцию соединения (или конкатенации ) слов. Соединением слов х = х (1)х (2)... х ( k ) и y = у (1)у (2)... у (т ) называют слово ху = х (1)х (2)... х ( k ) у (1)у (2)... у (т ). По определению, считаем х λ = λ х = х для любого х. Соединение иногда обозначают точкой (.). Неформально соединение ху получается приписыванием слова у справа к слову х. Таким образом, для любых двух слов х ∈ Vkи у ∈ Vmконкатенация ху ∈ Vk+m( k , m > 0). Следовательно, |ху | = | x | + | y |. Из определения также следует, что соединение слов ассоциативно, т. е. для произвольных трех слов x , у, z имеет место x ( yz ) = (ху ) z , и поэтому — с учетом написанного выше свойства пустого слова — множество V * всех слов в алфавите V с операцией соединения образует моноид ( V * , ..., λ ). Единица моноида — пустое слово. Этот моноид есть не что иное, как свободный моноид, порожденный алфавитом V . Для него используют то же обозначение, что и для самого множества всех слов в алфавите V , т. е. V * . На основе понятия соединения слов определим понятие вхождения одного слова в другое. Определение. Вхождение слова х ∈ V * в слово у ∈ V * — это упорядоченная тройка слов ( u , х, v ), такая, что y = uxv . При этом слово и называют левым, а слово v — правым крылом указанного вхождения. Слово х называют основой вхождения. Говорят, что слово х входит в слово у, если существует вхождение х в у. При этом также слово (цепочку) х называют подсловом (или подцепочкой ) слова (цепочки) у. Подцепочку х цепочки у называют началом (или префиксом ) цепочки у, если у = xz для некоторой непустой цепочки z ; если же для некоторой непустой цепочки z имеет место у = zx , то цепочку х называют концом (или постфиксом ) цепочки у. Заметим, что каждое слово входит в себя само и пустое слово входит в любое слово. Например, слова «цикл» и «циклоп» входят в слово «энциклопедия». Соответствующие вхождения записывают следующим образом: (эн, цикл, опедия), (эн, циклоп, едия). Может существовать несколько разных вхождений одного и того же слова х в некоторое слово у. Так, слово «абра» дважды входит в слово «абракадабра». Число вхождений пустого слова в данное слово р на единицу больше длины слова р. Среди всех вхождений слова х в слово у вхождение с наименьшей длиной левого крыла называют первым или главным вхождением x в y . Так, вхождение ( λ , абра, кадабра) есть первое вхождение слова «абра» в слово «абракадабра». Определение. Говорят, что вхождения (и, х, v ) и ( s, z , t ) слов х и z в одно и то же слово у не пересекаются , если существуют такие (может быть, и пустые) слова р и q , что у = uxpzt (и тогда v = pzt , a s = uxp ) или у = szqxv (и тогда и = szq , a t = qxv ) (рис. 7.1). В противном случае говорят, что указанные вхождения пересекаются.
Рис. 7.1 Так, вхождения слов «цикл» и «циклоп» в слово «энциклопедия» пересекаются, а два разных вхождения слова «абра» в слово «абракадабра» не пересекаются. Мы иногда будем использовать обозначение х ⊑ у для утверждения «слово х входит в слово y ». Можно доказать, что ⊑ — отношение порядка. Определив таким образом операцию соединения слов, введем теперь операцию с таким же названием, но уже для языков. Перед этим обратим внимание на то, что всякий раз, говоря о языках и операциях над ними, мы полагаем фиксированным какой-то алфавит V . Он не всегда явно упоминается, но нужно четко усвоить, что нельзя говорить просто о слове, просто о языке, но всегда — о слове или языке в том или ином алфавите. Определение. Соединением (конкатенацией ) языков L 1и L 2называют язык L 1L 2, состоящий из всех возможных соединений слов ху, в которых слово х принадлежит первому, а слово у — второму языку, т. е.
Итерацией языка L называют объединение всех его степеней:
Рассматривая объединение всех степеней языка L , начиная с первой, получим позитивную итерацию
Сформулируем основное алгебраическое свойство множества всех языков в алфавите V. Теорема. Алгебра Проверка аксиом полукольца сводится к доказательству: 1) того, что по операции объединения множество всех языков образует коммутативный и идемпотентный моноид (с пустым множеством в качестве нейтрального элемента (нуль полукольца )); это тривиально ввиду известных свойств операции объединения множеств; 2) того, что по операции конкатенации множество языков образует моноид (с языком { λ }, состоящим из одного пустого слова, в качестве нейтрального элемента (единицы полукольца )); для этого достаточно доказать, что операция соединения языков ассоциативна, а также доказать для любого языка L тождество { λ } L = L { λ } = L , что вытекает из ассоциативности операции соединения слов и из тождества λ х = х λ = х для любого слова x ; 3) следующих тождеств:
(эти тождества определяют свойство дистрибутивности операции соединения относительно объединения). Популярное:
|
Последнее изменение этой страницы: 2016-03-16; Просмотров: 1294; Нарушение авторского права страницы
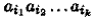 будет равен
будет равен
 . Иначе раскладываем k 1в виде
. Иначе раскладываем k 1в виде  где 1 < r 1< п. Тогда N = k 2n 2 + r 1n + r 0.
где 1 < r 1< п. Тогда N = k 2n 2 + r 1n + r 0.



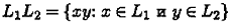
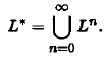

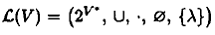 есть замкнутое полукольцо.
есть замкнутое полукольцо.