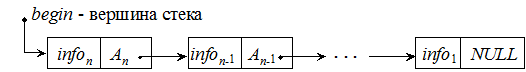|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Дополнительные файловые функции
В заключение рассмотрим наиболее распространенные функции, с помощью которых можно организовать работу с файлами: int fileno (FILE * f ) – определяет и возвращает значение дескриптора (fd) файла f, т.е. число, определяющее номер файла; long filelength (int fd ) – возвращает длину файла, имеющего дескриптор fd, в байтах; int chsize (int fd, long pos ) – выполняет изменение размера файла, имеющего номер fd, признак конца файла устанавливается после байта с номером pos; int feof (FILE * f ) – возвращает ненулевое значение при правильной записи признака конца файла; int fgetpos (FILE * f, long * pos ) – определяет значение текущей позиции pos файла f.
Пример программы работы с файлом структур Создать программу, в которой реализованы создание, добавление и просмотр файла, содержащего информацию о фамилии и среднем балле студентов. Процесс добавления информации заканчивается при нажатии точки. #include < stdio.h> #include < stdlib.h> struct Sved { char Fam[30]; double S_Bal; } zap, zapt; char Spis[]=" c: \\work\\Sp.dat"; FILE *F_zap; FILE* Open_file(char*, char*); void main (void) { int i, j, kodR, size = sizeof(Sved), kod_read; while(1) { puts(" Создать – 1\n Добавить– 3\nПросмотреть– 2\nВыход – 0" ); scanf(" %d", & kodR); switch(kodR) { case 1: case 3: if(kodR==1) F_zap = Open_file (Spis, " w+" ); else F_zap = Open_file (Spis, " a+" ); while(2) { puts(" \n Fam (. – end) " ); scanf(" %s", zap.Fam); if((zap.Fam[0])=='.') break; puts(" \n Ball: " ); scanf(" %lf", & zap.S_Bal); fwrite(& zap, size, 1, F_zap); } fclose(F_zap); break; case 2: F_zap = Open_file (Spis, " r+" ); int nom=1; while(2) { if(! fread(& zap, size, 1, F_zap)) break; printf(" %2d: %20s %5.2lf\n", nom++, zap.Fam, zap.S_Bal); } fclose(F_zap); break; case 0: return; // exit(0); } // Закрывает switch() } // Закрывает while() } // Функция обработки ошибочной ситуации при открытии файла FILE* Open_file(char *file, char *kod) { FILE *f; if(! (f = fopen(file, kod))) { puts(" Open File Error! " ); exit(1); } return f; }
Советы по программированию При выполнении вариантов заданий придерживайтесь следующих ключевых моментов. 1. Объекты типов структуры и объединения применяются для логически связанных между собой данных различных типов. 2. После описания шаблона структурного типа данных ставится точка с запятой. 3. Элементы данных, входящие в структуры и объединения, называются полями. Поля могут быть любого базового (стандартного) типа данных, массивом, указателем, объединением или структурой. 4. Для обращения к полю используется операция принадлежности (привязки, выбора) «.» (точка) при обращении через ID структуры, или «–> » (стрелка) при обращении через указатель. 5. Структуры одного типа можно присваивать друг другу с использованием стандартной функции memcpy. 6. Ввод-вывод структур выполняется поэлементно. 7. Структуры, память под которые выделяет компилятор, можно инициализировать значениями их полей. 8. Файл – это именованный объект, хранящий данные на каком-либо носителе, хотя может располагаться и на электронном диске в ОП. 9. Файл не имеет фиксированной длины, т.е. может увеличиваться или уменьшаться в процессе обработки. 10. Перед работой файл необходимо открыть (функция fopen), а после работы закрыть (функция fclose).
ЗАДАНИЕ 6. Создание и обработка структур
Первый уровень сложности Написать программу по обработке массива структур, содержащего следующую информацию о студентах: – фамилия и инициалы; – год рождения; – номер группы; – оценки за семестр: физика, математика, информатика, химия; – средний балл. Организовать ввод исходных данных, средний балл рассчитать по введенным оценкам. 1. Распечатать анкетные данные студентов, сдавших сессию на 8, 9 и 10. 2. Распечатать анкетные данные студентов-отличников, фамилии которых начинаются с интересующей вас буквы. 3. Распечатать анкетные данные студентов-отличников из интересующей вас группы. 4. Распечатать анкетные данные студентов, фамилии которых начинаются с буквы А и сдавших математику на 9 и 10. 5. Распечатать анкетные данные студентов интересующей вас группы, имеющих оценку 9 по физике и оценку 10 по высшей математике. 6. Распечатать анкетные данные студентов интересующей вас группы. Фамилии студентов начинаются с букв В, Г и Д. 7. Распечатать анкетные данные студентов, не имеющих оценок 4 и 5 по информатике и математике. 8. Вычислить общий средний балл всех студентов и распечатать список студентов со средним баллом выше общего среднего балла. 9. Вычислить общий средний балл всех студентов и распечатать список студентов интересующей вас группы, имеющих средний балл выше общего среднего балла. 10. Распечатать анкетные данные студентов интересующей вас группы, имеющих оценки 3 и 4. 11. Распечатать анкетные данные студентов интересующей вас группы, имеющих оценку 9 по информатике. 12. Распечатать анкетные данные студентов, имеющих оценку 8 по физике и оценку 9 по высшей математике. 13. Вычислить общий средний балл студентов интересующей вас группы и распечатать список студентов этой группы, имеющих средний балл выше общего среднего. 14. Распечатать анкетные данные студентов-отличников интересующей вас группы. 15. Распечатать анкетные данные студентов интересующей вас группы, имеющих средний балл выше введенного с клавиатуры.
Второй уровень сложности Написать программу предыдущего варианта, создав из предложенных анкетных данных динамический массив введенной с клавиатуры размерно-
сти. Полученные данные упорядочить: для символьных данных – по алфавиту (выбрав нужное поле), для числовых данных – по возрастанию (убыванию). ЗАДАНИЕ 7. Создание и обработка файлов Первый уровень сложности Написать программу по обработке файла, состоящего из структур, содержащих информацию задания 6. Средний балл рассчитать программно по введенным оценкам. Массив структур не использовать. В программе реализовать следующие действия по обработке файла: – создание; – просмотр; – добавление нового элемента; – удаление (редактирование); – решение индивидуального задания (первый уровень сложности задания 6). Результаты выполнения индивидуального задания записать в текстовый файл. Второй уровень сложности Задачи шифровки. Составить программу, которая вводит строку с клавиатуры; признак окончания ввода – нажатие клавиши Enter, шифрует введенный текст в файл на диске по определенному алгоритму. Программа должна считывать эту строку из файла и далее дешифровать текст, выводя его на экран и записывая в выходной файл. В программе реализовать следующие действия: – ввод с клавиатуры исходной строки текста и запись в файл a.txt; – считывание строки из файла и вывод на экран; – шифровка текста; – расшифровка. Алгоритмы шифровки: 1. Каждая буква от «а» до «ю» заменяется на следующую по алфавиту, а «я» заменяется на «а». 2. Первая буква «а» заменяется на 11-ю, вторая «б» – на 12-ю, третья – на 13-ю, ..., последняя «я» – на 10-ю. 3. После каждой согласной буквы вставляется буква «а». 4. После каждой согласной буквы вставляется слог «ла». 5. Каждая пара букв «ле» заменяется на «ю», «са» – на «щ», «ик» – на «ж». 6. Каждая из пары букв «си», «ли» и «ти» заменяются соответственно на «иис», «иил» и «иит». 7. После каждой гласной буквы вставляется буква «с». 8. После каждой гласной буквы вставляется слог «ла». 9. Каждая из букв «а», «о», «и» заменяется соответственно на «ц», «ш», «щ». 10. Каждая буква заменяется на следующую в алфавите по часовой стрелке. 11. Каждая буква заменяется на следующую в алфавите против часовой стрелки. 12. Каждая буква «а» заменяется на слог «си», а «и» – на «са». 13. Четные и нечетные символы меняются местами. 14. Символы, кратные двум по порядку следования, заменяются на единицы. 15. Символы, кратные двум по порядку следования, заменяются на свой порядковый номер. ГЛАВА 15. Динамические структуры данных Линейные списки Некоторые задачи исключают использование структур данных фиксированного размера и требуют введения структур, способных увеличивать или уменьшать свой размер уже в процессе работы программы. Основу таких структур составляют динамические переменные. Динамическая переменная хранится в некоторой области ОП, обращение к которой производится через переменную-указатель. Как правило, динамические переменные организуются в списковые структуры данных, элементы которых имеют тип struct. Для адресации элементов в структуру включается указатель (адресное поле) на область размещения следующего элемента. Такой список называют однонаправленным (односвязным). Если добавить в каждый элемент ссылку на предыдущий, получится двунаправленный список (двусвязный), если последний элемент связать указателем с первым, получится кольцевой список. Например, пусть необходимо создать линейный список, содержащий целые числа, тогда каждый элемент списка должен иметь информационную (infо) часть, в которой будут находиться данные, и адресную часть (р), в которой будут размещаться указатели связей, т.е. элемент такого списка имеет вид
а шаблон структуры будет иметь вид struct Spis { int info; Spis *p; }; Каждый элемент списка содержит ключ, идентифицирующий этот элемент. Ключ обычно бывает либо целым числом, либо строкой и является частью поля данных. В качестве ключа в процессе работы со списком могут выступать разные части поля данных. Например, если создается линейный список из записей, содержащих фамилию, год рождения, стаж работы и пол, любая часть записи может выступать в качестве ключа. При упорядочивании такого списка по алфавиту ключом будет являться фамилия, а при поиске, например, ветеранов труда – ключом будет стаж работы. Как правило, ключи должны быть уникальными, но могут и совпадать. В случае совпадения ключей лучше всего использовать схемы организации структур данных по принципам «хеширования». Над списками можно выполнять следующие операции: – начальное формирование списка (создание первого элемента); – добавление элемента в список; – обработка (чтение, удаление и т.п.) элемента с заданным ключом; – вставка элемента в заданное место списка (до или после элемента с заданным ключом); – упорядочивание списка по ключу. Если программа состоит из функций, решающих вышеперечисленные задачи, то необходимо соблюдать следующие требования: – все параметры, не изменяемые внутри функций, должны передаваться с модификатором const; – указатели, которые могут изменяться, передаются по адресу. Например, при удалении из списка последнего элемента, измененный указатель на конец списка требует корректировки, т.е. передачи в точку вызова.
Структура данных СТЕК Стек – упорядоченный набор данных, в котором размещение новых элементов и удаление существующих производится только с одного его конца, который называют вершиной стека, т.е. стек – это список с одной точкой доступа к его элементам. Графически это можно изобразить так:
Стек – структура типа LIFO (Last In, First Out) – последним вошел, первым выйдет. Стек получил свое название из-за схожести с оружейным магазином с патронами (обойма): когда в стек добавляется новый элемент, то прежний проталкивается вниз и временно становится недоступным. Когда же верхний элемент удаляется из стека, следующий за ним поднимается вверх и становится опять доступным. Максимальное число элементов стека ограничивается, т.е. по мере вталкивания в стек новых элементов память под него должна динамически запрашиваться и освобождаться также динамически при удалении элемента из стека. Таким образом, стек – динамическая структура данных, состоящая из переменного числа элементов одинакового типа. Состояние стека рассматривается только по отношению к его вершине, а не по отношению к количеству его элементов, т.е. только вершина стека характеризует его состояние. Операции, выполняемые над стеком, имеют специальные названия: push – добавление элемента в стек (вталкивание); pop – выталкивание (извлечение) элемента из стека, верхний элемент стека удаляется (не может применяться к пустому стеку). Кроме этих обязательных операций часто нужно прочитать значение элемента в вершине стека, не извлекая его оттуда. Такая операция получила название peek. Рассмотрим основные алгоритмы работы со стеком, взяв для простоты в качестве информационной части целые числа, хотя информационная часть может состоять из любого количества объектов допустимого типа, за исключением файлов. Алгоритм формирования стека Рассмотрим данный алгоритм для первых двух элементов. 1. Описание структуры переменной, содержащей информационное и адресное поля:
Шаблон структуры рекомендуется описывать глобально: struct Stack { int info; Stack *Next; }; 2. Объявление указателей на структуру: Stack *begin (вершина стека), *t (текущий элемент); 3. Так как первоначально стек пуст: begin = NULL; 4. Захват памяти под первый (текущий) элемент: t = (Stack*) malloc (sizeof(Stack)); или t = new Stack; формируется конкретный адрес ОП (обозначим его А1) для первого элемента, т.е. t равен А1. 5. Ввод информации (например, i1); а) формирование информационной части: t -> info = i1; б) формирование адресной части: значение адреса вершины стека записываем в адресную часть текущего элемента (там был NULL) t -> Next = begin;
6. Вершина стека переносится на созданный первый элемент: begin = t; в результате получается следующее:
7. Захват памяти под второй элемент: t = (Stack*) malloc (sizeof(Stack)); или t = new Stack; формируется конкретный адрес ОП (A2) для второго элемента. 8. Ввод информации для второго элемента (i2); а) формирование информационной части: t -> info = i2; б) в адресную часть записываем значение адреса вершины, т.е. адрес первого (предыдущего) элемента (А1): t -> Next = begin;
9. Вершина стека снимается с первого и устанавливается на новый элемент (A2): begin = t; получается следующая цепочка:
Обратите внимание, что действия 7, 8, 9 идентичны действиям 4, 5, 6, т.е. добавление новых элементов в стек можно выполнять в цикле, до тех пор, пока это необходимо. Функция формирования элемента стека для объявленного ранее типа данных может выглядеть следующим образом: Stack* Create(Stack *begin) { Stack *t = (Stack*)malloc(sizeof(Stack)); printf(“\n Input Info ”); scanf(“%d”, & t -> info); t -> Next = begin; return t; } Участок программы с обращением к функции Create для добавление необходимого количества элементов в стек может иметь следующий вид: ¼ Stack *begin = NULL; int repeat = 1; while(repeat) { // repeat=1 – продолжение ввода данных begin = Create(begin); printf(“ Stop - 0 ”); // repeat=0 – конец ввода данных scanf(“%d”, & repeat); } ¼ Если в функцию Сreate указатель на вершину передавать по адресу и использовать для захвата памяти операцию new, то она может иметь следующий вид: void Create(Stack **pt) { Stack *t = new Stack; printf(“\n Input Info ”); scanf(“%d”, & t -> info); t -> Next = *pt; } Обращение к ней в данном случае будет: Create(& begin);
Популярное:
|
Последнее изменение этой страницы: 2016-03-16; Просмотров: 1544; Нарушение авторского права страницы