
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
ЛЕКЦИЯ № 1 Состав ПО коммутационных станцийСтр 1 из 8Следующая ⇒
Add ip route entry ip-адрес след.-сегмент ip-метрика Если адрес 10.0.0.0 достижим через сегмент 128.128.50.5 и находится на расстоянии трех сетевых сегментов (трех маршрутизаторов), то нужно ввести команду add ip route entry 10.0.0.0 255.0.0.0 128.128.50.5 3 CLI популярны среди сетевых администраторов, поскольку обеспечивают доступ к развитым средствам настройки конфигурации и мониторинга моста или маршрутизатора. Согласно нашей оценке, системы с CLI предлагают самый широкий спектр функций мониторинга пакетов в реальном времени; доступ к системе и к средствам регистрации событий; утилиты (информация отображается на экране в прокручиваемом окне консоли или в окне Telnet в ответ на команду display, show или в ответ на событие, происходящее в реальном времени). Однако такие средства достаточно сложны для пользователя, работающего дома или в малом офисе. Похоже, многие производители пришли к такому же выводу. Для упрощения начальной настройки конфигурации разработчики некоторых из протестированных нами устройств предлагают утилиты, в которых применяется метод интервью - простых вопросов и ответов, позволяющих задать начальную конфигурацию ISDN-устройства. Эти утилиты проектируются так, чтобы собрать достаточно информации от пользователя и создать на ее основе минимальную работающую конфигурацию. Подобные средства не требуют от пользователя понимания синтаксиса командной строки (если, конечно, он не захочет получить более сложную конфигурацию). Приложения управления конфигурацией Некоторые производители предлагают приложения управления конфигурацией, которые могут функционировать на ПК или на рабочей станции UNIX в системе, поддерживающей работу с окнами. Для применения таких приложений нужно соединить ПК с последовательным портом или с портом консоли конфигурируемого маршрутизатора или включить этот ПК в TOI же сегмент Ethernet, в котором находится данный маршрутизатор (в нашем сценарии ISDN-продукт нужно соединить с сетью Ethernet и с сервисом ISDN). В большинстве случаев приложение управления конфигурацией допускает инсталляцию или загрузку конфигурации в ISDN-устройство. Для настройки конфигурации маршрутизатора ISDN в сети Ethernet нужно, чтобы программное обеспечение маршрутизатора и приложение на ПК имели сведения об адресах друг друга. Одни производители требуют задания адреса IP для маршрутизатора через интерфейс консоли. Другие используют более творческий подход и заранее конфигурируют маршрутизатор, присваивая ему заданный по умолчанию адрес IP (например, 1.1.1.1), либо используют адресацию MAC (media access control) или протоколы, поддерживающие MAC, IP Multicast или адресацию с широковещательной рассылкой. Приложения с оконной средой предлагают для настройки конфигурации маршрутизаторов и мостов простые методы типа " укажи и щелкни" и часто обеспечивают гипертекстовые ссылки на файлы справки. Подобные приложения собирают информацию конфигурации, вводимую пользователем с помощью окон, значков, меню и форм. Как и утилиты, использующие метод интервью, приложения с оконной средой получают от пользователя информацию, достаточную для построения функционирующей конфигурации. После ввода этой информации приложение устанавливает соединение с ISDN-устройством, загружает конфигурацию и (для внешних устройств) перезагружает маршрутизатор, мост или модем. В некоторых случаях приложение будет повторно устанавливать соединение с устройством и выполнять " пробный прогон" конфигурации для вызова удаленного абонента. В случае отказа приложение идентифицирует его причины и пытается помочь пользователю исправить конфигурацию. Программное обеспечение платы ISDN-адаптера для ПК Для платы ISDN-адаптера на ПК необходимы сетевой драйвер, поддерживающий работу с платой операционной системы, и интерфейсные программы (например, Windows). Существуют самые разнообразные продукты операционных систем, интерфейсные программы, сетевые драйверы и драйверы пакетов локальной сети. На ПК используются такие драйверы, как NDIS (Network Device Interface Specification), ODI (Open Datalink Interface), TCP/IP, NetBEUI и NetBIOS. Если для работы устройства требуется драйверы, отличные от тех, что обычно включаются в состав DOS, Windows, Windows 95 или OS/2 Warp, их должен предоставить производитель аппаратных средств ISDN. Если системе " не нравится" стек, используемый в настоящий момент, возможно, придется установить другой стек TCP/IP. Например, если применяется Trumpet Winsock под WfW и протокол SLIP для соединения с Интернетом, может возникнуть необходимость перейти на Microsoft TCP/IP-32, так как драйверы NDIS не всегда могут обеспечить взаимодействие Trumpet с платой ISDN. Это вовсе не проблема, так как TCP/IP-32 распространяется корпорацией Microsoft бесплатно. Однако сказанное дает представление о том, насколько сложным может быть программное обеспечение для платы сетевого адаптера ISDN и насколько упростится жизнь при применении устройства plug-and-play в Windows 95. Программное обеспечение моста или маршрутизатора ISDN для сети Ethernet Последний уровень - это мост или маршрутизатор ISDN, включаемый в сеть Ethernet. Предполагается, что на компьютере установлена плата Ethernet, и он работает в сети. В данном случае нужно решить проблемы с драйверами платы Ethernet, аналогичные тем, что возникают при инсталляции плат сетевых адаптеров. Между тем для взаимодействия компьютера с мостом/маршрутизатором не нужно инсталлировать никакого дополнительного программного обеспечения и драйверов. Однако не все так просто, поскольку необходимо изменить конфигурацию сети для распознавания дополнительного устройства. При работе в сети Novell или в другой " серьезной" сетевой среде требуется помощь сетевого администратора, который выполнит конфигурацию, не создавая в сети других проблем. Кроме того, нужно инсталлировать программное обеспечение TCP/IP, позволяющее мосту/маршрутизатору ISDN устанавливать соединение с ISP. Бесплатное и условно-бесплатное ПО Немногочисленные условно-бесплатные программы в основном представляют собой драйверы пакетов TCP/IP и продукты маршрутизации. Многие из них разработаны в Германии для европейского рынка MS- DOS/Windows и UNIX. Часть таких продуктов протестирована с изделиями, продаваемыми в США. Об этих пакетах рассказывается ниже. Управляющие устройства В большинстве современных цифровых АТС используется архитектура, представляющая собой что-то среднее между двумя подходами - централизованной и распределенной архитектур программного управления. Сегодняшние варианты архитектуры управления цифровой коммутацией можно разделить на три типа: централизованное управление, иерархическое управление и распределенное управление. Недостатки каскадной модели · в основе модели лежит последовательная линейная структура, в результате чего каждая попытка вернуться на одну или две фазы назад, чтобы исправить какую-либо проблему или недостаток, приведет к значительному увеличению затрат и сбою в графике; · пользователи не могут убедиться в качестве разработанного продукта до окончания всего процесса разработки. Они не имеют возможности оценить качество, если нельзя увидеть готовый продукт разработки; · у пользователя нет возможности постепенно привыкнуть к системе. Процесс обучения происходит в конце жизненного цикла, когда ПО уже запущено в эксплуатацию; · каждая фаза является предпосылкой для выполнения последующих действий, что превращает такой метод в рискованный выбор для систем, не имеющих аналогов, так как он не поддается гибкому моделированию; · для каждой фазы создаются результативные данные, которые по его завершению считаются замороженными. Это означает, что они не должны изменяться на следующих этапах жизненного цикла продукта. Если элемент результативных данных какого-либо этапа изменяется (что встречается весьма часто), на проект окажет негативное влияние изменение графика, поскольку ни модель, ни план не были рассчитаны на внесение и разрешение изменения на более поздних этапах жизненного цикла; · все требования должны быть известны в начале жизненного цикла. Модель не рассчитана на динамические изменения в требованиях на протяжении всего жизненного цикла, так как получаемые данные " замораживаются". · возникает необходимость в жестком управлении и контроле, поскольку в модели не предусмотрена возможность модификации требований; · модель основана на документации, а значит, количество документов может быть избыточным; · весь программный продукт разрабатывается за один раз. Нет возможности разбить систему на части. Фазы V-образной модели Ниже подано краткое описание каждой фазы V-образной модели, начиная от планирования проекта и требований вплоть до приемочных испытаний: · планирование проекта и требований – определяются системные требования, а также то, каким образом будут распределены ресурсы организации с целью их соответствия поставленным требованиям. (в случае необходимости на этой фазе выполняется определение функций для аппаратного и программного обеспечения); · анализ требований к продукту и его спецификации – анализ существующей на данный момент проблемы с ПО, завершается полной спецификацией ожидаемой внешней линии поведения создаваемой программной системы; · архитектура или проектирование на высшем уровне – определяет, каким образом функции ПО должны применяться при реализации проекта; · детализированная разработка проекта – определяет и документально обосновывает алгоритмы для каждого компонента, который был определен на фазе построения архитектуры. Эти алгоритмы в последствии будут преобразованы в код; · разработка программного кода – выполняется преобразование алгоритмов, определенных на этапе детализированного проектирования, в готовое ПО; · модульное тестирование – выполняется проверка каждого закодированного модуля на наличие ошибок; · интеграция и тестирование – установка взаимосвязей между группами ранее поэлементно испытанных модулей с целью подтверждения того, что эти группы работают также хорошо, как и модули, испытанные независимо друг от друга на этапе поэлементного тестирования; · системное и приемочное тестирование – выполняется проверка функционирования программной системы в целом (полностью интегрированная система), после помещения в ее аппаратную среду в соответствии со спецификацией требований к ПО; · производство, эксплуатация и сопровождение – ПО запускается в производство. На этой фазе предусмотрены также модернизация и внесение поправок; · приемочные испытания (на рис. не показаны) – позволяет пользователю протестировать функциональные возможности системы на соответствие исходным требованиям. После окончательного тестирования ПО и окружающее его аппаратное обеспечение становятся рабочими. После этого обеспечивается сопровождение системы. Качество ПО Наибольшую популярность приобрели некоторое время назад численные оценки качества программ, предложенные Холстедом. Согласно предложенной им метрике, длина программы N определяется как: N=g 1 log2g i+g2log2g2, где 131 — число простых операторов, a t)2 — число простых операндов в программе. В настоящее время используются модели оценки качества ПО, из которых мы упомянем две — одну, предложенную Институтом разработки программного обеспечения (SEI) университета Карнеги Меллона и называемую моделью мандатной зрелости (СММ), и другую, разработанную ISO (ТС-176). Обе модели поддерживают процесс сертификации организаций-разработчиков программного обеспечения. ЛЕКЦИЯ № 4 Программно-аппаратные средства контроля Э УС Представление сообщений в цифровой форме с помощью первичных кодов отличается малой избыточностью или даже её отсутствием. Вследствие этого, безызбыточный код обладает большой «чувствительностью» к помехам. Ошибка в приеме только одного символа зачастую приводит к воспроизведению комбинации, отличной от переданной, так как в безызбыточном коде отдельные комбинации могут отличаться друг от друга только в одной позиции (в одном разряде). Если для передачи сообщений использовать не все комбинации первичного кода, а только те, которые отличаются друг от друга не менее чем в двух позициях, то одиночная ошибка при приеме переведет используемую (разрешенную) комбинацию в запрещенную. Это позволяет обнаружить указанную ошибку, появляющуюся вследствие помех приему. В данном случае одна разрешенная комбинация может перейти в другую разрешенную (не обнаруживаемая ошибка) только при двойной ошибке. Вероятность этого значительно меньше вероятности одиночной ошибки. Коды, у которых используются только некоторые из комбинаций, могут повысить помехоустойчивость приема. Поэтому они называются избыточными, или корректирующими. Корректирующие свойства избыточных кодов зависят от их структуры и параметров (длительности символов, числа разрядов, избыточности и т. п.). Простейшим примером корректирующего кода является код с проверкой на четность, который образуется следующим образом. К кодовым комбинациям безызбыточного первичного двоичного n-разрядного кода добавляется дополнительный разряд (позиция), называемый проверочным, или контрольным. Если число символов 1 в исходной кодовой комбинации четное, то в дополнительном разряде формируют контрольный символ 0, если число символов 1 нечетное, то в дополнительном разряде формируют контрольный символ 1. В результате общее число символов 1 в любой кодовой комбинации всегда должно быть четным. Добавление дополнительного разряда увеличивает общее число возможных комбинаций вдвое по сравнению с числом комбинаций исходного первичного кода, а условие четности разделяет все комбинации на разрешенные и неразрешенные. Таким образом, код с проверкой на четность позволяет обнаруживать одиночную ошибку, поскольку она переводит разрешенную комбинацию в неразрешенную. Увеличивая число дополнительных разрядов и формируя по определенным правилам проверочные символы 0 или 1, соответствующие этим разрядам, усиливают корректирующие свойства кода так, чтобы он позволял не только обнаруживать, но и исправлять ошибки. Поэтому избыточные или корректирующие коды разделяются на коды, обнаруживающие ошибки, и коды, исправляющие ошибки. Таким образом, для обнаружения ошибки достаточно установить факт, что в данной кодовой комбинации произошла ошибка (одиночная, двойная и т. п.). Для исправления ошибки необходимо не только обнаружить ошибку, но и указать ту позицию в кодовой комбинации, где эта ошибка произошла. Задача исправления ошибки более сложная, чем ее обнаружение, и требует применения более сложных кодов. В настоящее время наиболее широко используются двоичные равномерные корректирующие коды, обладающие хорошими корректирующими свойствами и простотой реализации. Данные коды разделяют на блочные и непрерывные. При использовании блочных кодов цифровая информация передается в виде отдельных блоков кодовых комбинаций равной длины. Кодирование и декодирование каждого блока осуществляется независимо друг от друга. Почти все блочные коды относятся к разделимым кодам, кодовые комбинации которых состоят из двух различающихся частей: информационной и проверочной. Информационные и проверочные разряды во всех кодовых комбинациях разделимого кода всегда занимают одни и те же позиции. Разделимые коды обычно обозначаются в виде (n, k ), где n указывает значность кода (общее число позиций в блоке), k – число информационных позиций. Иными словами, величина n определяет общее число символов в блоке, a k – только число информационных символов. Число проверочных символов в разделимых кодах равно r = n – k. Среди разделимых кодов различают систематические и несистематические коды. В систематических кодах проверочные символы образуются линейными комбинациями информационных символов. Теоретической основой получения таких комбинаций является аппарат линейной алгебры, позволяющий формировать проверочные символы по определенной системе – отсюда и происхождение термина «систематические» коды. Использование указанного аппарата привело к тому, что данные коды также называются алгебраическими. Среди систематических кодов наиболее известны циклические коды Хэмминга, коды Боуза-Чоудхури и др. Основное свойство циклических кодов состоит в том, что циклический сдвиг любой разрешенной кодовой комбинаций также является разрешенной комбинацией. Циклические коды обладают хорошими корректирующими свойствами, а реализация кодеров и декодеров таких кодов оказывается проще, чем для других систематических кодов. Такие коды характеризуются тем, что в них проверочные символы перемежаются с информационными, и нет четкого деления последовательности символов на выходе кодера на отдельные кодовые комбинации. Формирование проверочных символов в непрерывных кодах ведется по рекуррентным правилам. Кодирование и декодирование этих кодов несколько проще, чем блочных систематических. Непрерывные коды могут иметь хорошие корректирующие свойства, особенно в случае пакетов ошибок. Основными параметрами корректирующих кодов являются их избыточность, кодовое расстояние, а также число обнаруживаемых или исправляемых ошибок Избыточностью корректирующего кода называют величину:
w = r / n = (n - k) / n = 1 – k / n (1)
где n - значность кода (общее число позиций в блоке); k – число информационных позиций в блоке; r - число проверочных символов в разделимых кодах.
Откуда следует: k / n = 1 – w (2) Величину k/n, которая показывает, какую часть общего числа символов кодовой комбинации составляют информационные символы, называют скоростью кода. Она характеризует относительную скорость передачи информации. Если производительность источника информации равна Н символов в секунду, то скорость передачи этой информации после кодирования R окажется равной: R = Hk / n (3) Если число ошибок, которые нужно обнаружить или исправить, велико, то необходимо иметь код с большим числом проверочных символов. Чтобы при этом скорость передачи оставалась достаточно высокой, необходимо в каждом кодовом блоке одновременно увеличивать как общее число символов, так и число информационных символов. При этом длительность кодовых блоков будет существенно возрастать, что приведет к задержке информации при передаче и приеме. Чем сложнее кодирование, тем больше временная задержка передачи информации. Кодовым или расстоянием Хэмминга d между двумя кодовыми комбинациями называют число позиций, в которых эти комбинации имеют разные символы. Например, расстояние между комбинациями 0001101 и 1001010 равно четырем (d = 4). Расстояние между различными комбинациями конкретного кода может быть различным. Так, в частности, в безызбыточном первичном натуральном коде это расстояние для различных комбинаций может различаться от единицы до величины m, равной значности кода. Особую важность для характеристики корректирующих свойств кода имеет минимальное или хэмминговое расстояние dmin между кодовыми комбинациями. Это расстояние называют кодовым. В безызбыточном коде все комбинации являются разрешенными и, следовательно, его кодовое расстояние равно единице. Поэтому достаточно исказить один символ, чтобы вместо переданной комбинации была принята другая разрешенная комбинация. Чтобы код обладал корректирующими свойствами, необходимо ввести в него некоторую избыточность, которая обеспечивала бы минимальное расстояние между разрешенными комбинациями не менее двух. Кодовое расстояние является основным параметром, характеризующим корректирующие способности данного кода. Если код используется только для обнаружения ошибок кратности а, то необходимо и достаточно, чтобы минимальное расстояние было равно:
dmin
В этом случае никакая комбинация из а ошибок не может перевести одну разрешенную кодовую комбинацию в другую разрешенную. Таким образом, условие обнаружения всех ошибок кратности а можно записать в виде:
a обн
Для исправления всех ошибок кратности а и менее, необходимо иметь минимальное расстояние
dmin
В этом случае любая кодовая комбинация с числом ошибок а отличается от каждой разрешенной комбинации не менее, чем в а+1 позициях. Если условие (11) не выполнено, возможен случай, когда ошибка кратности а исказит переданную комбинацию так, что она станет ближе к одной из разрешенных комбинаций, чем к переданной, или даже перейдет в другую разрешенную комбинацию.
Итак, условием исправления всех ошибок кратности не более а является:
a испр
Корректирующие коды можно одновременно использовать и для обнаружения и для исправления ошибок. Минимальное расстояние, при котором можно исправить все ошибки кратности а или меньше и одновременно обнаружить все ошибки кратностью b> а или меньше, определяется условием:
dmin
Задача определения минимально необходимой избыточности, при которой код обладает нужными корректирующими свойствами, до сих пор не имеет полного решения. Известен лишь ряд верхних и нижних оценок (границ), которые устанавливают связь между максимально возможным минимальным расстоянием корректирующего кода и его избыточностью. В ряде случаев при передаче информации простым безызбыточным кодом получающаяся достоверность приема недостаточна. Одним из путей ее повышения является применение корректирующего кода. Выбор того или иного кода и его параметров зависит от конкретных условий решаемой задачи: требуемой достоверности приема, допустимой относительной скорости передачи, вида ошибок в канале и т. п. В теории помехоустойчивого кодирования различают два вида основных ошибок: статистически независимые (некоррелированные) и статистически зависимые (коррелированные) ошибки (пачки или пакеты ошибок). Покажем на простом примере возможность повышения помехоустойчивости с помощью корректирующего кода и определим, при каких условиях применение такого кода целесообразно. При этом будем полагать, что ошибки в канале независимы, а сам канал симметричен. Такие условия характерны для гауссовских каналов, в которых применяются посылки сигналов с одинаковыми энергиями. При независимых ошибках симметричный канал полностью характеризуется вероятностью ошибочного приема символа. Хотя соотношения, характеризующие распределение ошибок, при этом оказываются простыми, однако оценка корректирующих возможностей кода в данном случае является ориентировочной. В случае посимвольного (поэлементного) приема каждая посылка сигнала, соответствующая определенному символу кодовой комбинации, анализируется в приемном устройстве отдельно, а затем принимается решение, к какой из возможных кодовых комбинаций следует отнести полученную последовательность символов. В случае приема в целом анализируется сразу вся принятая кодовая комбинация. Такой анализ предполагает, что число оптимальных (или подоптимальных) фильтров или корреляторов в приемном устройстве равно числу используемых разрешенных кодовых комбинаций. Суть вероятностного, или последовательного декодирования состоит в том, что вся совокупность возможных кодовых комбинаций (включая разрешенные и запрещенные) разбивается на две группы: высоковероятные и маловероятные. Если принятая комбинация ближе к высоковероятной группе, она декодируется сразу же без проверки. Если же принятая комбинация ближе к маловероятным комбинациям, она декодируется с проверкой и исправлением ошибок. Иными словами, сильно искаженные комбинации исправляются, а слабо искаженные декодируются без исправления. Такое декодирование несколько уступает в помехоустойчивости оптимальному, но заметно проще в реализации. Суть алгебраического декодирования состоит в том, что исправляется только определенная часть ошибок, т. е. корректирующие возможности кода используются только частично. Это означает, что используется неоптимальный алгоритм декодирования, допускающий более простую схемную реализацию. Особенно удобны с точки зрения простоты декодирования циклические коды, являющиеся разновидностью систематических кодов. Для таких кодов разработаны эффективные методы алгебраического декодирования. Применение корректирующих кодов связано с некоторым усложнением систем передачи информации, особенно за счёт введения декодирующих устройств. Однако стремление к повышению скорости передачи по существующим линиям связи и возрастающие требования к достоверности передаваемой информации привели к широкому применению помехоустойчивого кодирования.
ЛЕКЦИЯ № 1 Состав ПО коммутационных станций Язык программирования - это формализованный язык, который представляет собой совокупность алфавита, правил написания конструкций (синтаксис) и правил толкования конструкций (семантика). Алфавит - фиксированный для данного языка набор основных символов, допускаемых для составления текста программы на этом языке. Синтаксис - система правил, определяющих допустимые конструкции языка программирования из букв алфавита. Семантика - система правил однозначного толкования отдельных языковых конструкций, позволяющих воспроизвести процесс обработки данных. Языки программирования, если в качестве признака классификации взять синтаксис образования его конструкций, можно условно разделить на классы: · машинные языки – языки программирования, воспринимаемые аппаратной частью компьютера (машинные коды); · машинно-ориентированные языки – языки программирования, которые отражают структуру конкретного типа компьютера (ассемблеры); · алгоритмические языки – не зависящие от архитектуры компьютера языки программирования для отражения структуры алгоритма (Паскаль, Фортран, Бейсик и др.); · процедурно-ориентированные языки – языки программирования, где имеется возможность описания программы как совокупности процедур (подпрограмм); · проблемно-ориентированные языки – языки программирования, предназначенные для решения задач определенного класса (Лисп, РПГ, Симула и др.); · интегрированные системы программирования. Программирование ЭВМ можно осуществлять на языке машинных команд (машинных кодов), на языке, использующем символическое обозначение машинных команд, языке ассемблера и языке высокого уровня. Понятие уровня языка определяется аппаратно–программными средствами, с помощью которых инструкции, записанные на некотором языке, переводятся в язык, понятный для ЭВМ. Современные ЭВМ имеют несколько уровней, каждому из которых соответствует определенный язык (язык данного уровня). Самый нижний уровень — микропрограммный, который обеспечивает выполнение инструкций системы команд ЭВМ. Микропрограммный уровень определяется реализацией АЛУ, составом и назначением регистров в процессоре и т. д., т. е. ориентирован на конкретную ЭВМ (машинно-ориентирован). Следующим уровнем является машинный уровень, которому соответствует язык машинных команд. Взаимодействие между рассмотренными уровнями производится следующим образом: Каждая машинная команда, поступающая из памяти в процессор, анализируется и вызывает исполнение определенной микропрограммы, реализующей заданную командой операцию. Ассемблерный уровень является символической формой представления языка машинных команд. Язык ассемблера более удобен для программирования, но требует использования специальной программы для перевода на язык машинных, команд. Перечисленные низкие языковые уровни относятся к разряду машинно-ориентированных. Следующий уровень представлен языками высокого уровня (ЯВУ), которые часто называют проблемно-ориентированными, поскольку каждый из них разработан для решения определенного круга задач: научных (Алгол, Фортран, Бейсик), экономических (Кобол), управления в реальном масштабе времени Ада, Модула. ПРОГРАММИРОВАНИЕ НА ЯЗЫКЕ МАШИННЫХ КОМАНД Язык машинных команд воспринимается ЭВМ непосредственно. Чтобы заставить ЭВМ решить конкретную задачу, необходимо составить алгоритм ее решения, доведя его детализацию до уровня отдельных операций, предусмотренных в системе команд. Каждую команду необходимо записать в соответствующем для данной команды формате, т. е. в виде одного или нескольких машинных слов, содержащих 0 или 1 в каждом разряде. Поля, отведенные под указание конкретных адресов ОП и исходных значений операндов, должен заполнить непосредственно программист. Написанная таким образом программа в кодах машинных команд вводится в ОП ЭВМ, например с использованием дисплея. После этого можно произвести ее запуск, записав в счетчик команд адрес ячейки памяти, содержащей первую команду программы, и произведя инициализацию ее выполнения. Ввод программы должен быть произведен в ту область памяти, которая планировалась при написании программы. Программирование в машинных кодах имеет ряд трудностей. Одна из них состоит в определении адресов при планировании размещения программы в ОП. Поскольку при программировании используются истинные адреса ячеек ОП, то необходимо, чтобы распределение памяти было уже произведено. В то же время в процессе программирования у программиста нет еще достаточной информации о полном количестве команд в будущей программе, о том, в каких конкретно ячейках будут размещены эти команды и сколько ячеек понадобится для хранения промежуточных результатов. Поэтому к началу составления программы делается лишь ориентировочное распределение памяти, которое уточняется по ходу составления программы. По этой причине целый ряд команд невозможно сразу записать в окончательном виде. Некоторые поля адресов приходится временно оставлять пустыми, заполняя их по мере уточнения мест в памяти, на которые в этих написанных ранее командах имеются ссылки (например, команды передачи управления). Отсюда возникает необходимость постоянно обращаться к уже написанной части программы. В программы, написанные в машинных кодах, трудно вносить какие-либо изменения и исправления, особенно в том случае, когда они связаны с изменением распределения памяти. Написанная программа плохо читается и понимается, вследствие чего усложняются процесс поиска и исправления ошибок, документирование готовой программы. Немаловажным является также и то, что машинные коды трудно запоминать. Как следствие вышесказанного — производительность труда программиста в случае использования машинных кодов довольно низкая. В настоящее время такая форма программирования используется редко, например, в тех случаях, когда требуется. Повысить быстродействие работы программы при минимальном объеме ОП. ПРОГРАММИРОВАНИЕ НА ЯЗЫКЕ АССЕМБЛЕРА Программирование с использованием языка ассемблера свободно от описанных выше недостатков. В языке ассемблера используют символическое обозначение машинных команд, в котором при написании каждой команды информация в ее полях задается не в виде машинного кода операции и истинных адресов операндов, а в виде их условных символических обозначений. Эти обозначения специально выбираются таким образом, чтобы точно определить содержание каждой команды (так их легче запомнить) и обеспечить наглядность и простоту ее понимания. Программирование на языке ассемблера обеспечивает также независимость программы от конкретного распределения памяти. В качестве символического обозначения команд принято использовать сокращение английских или русских слов, определяющих выполняемую операцию. Программа, составленная с помощью символических обозначений, непонятна для ЭВМ, которая воспринимает только язык машинных команд. Поскольку, каждое символическое обозначение соответствует определеннойI машинной команде, то символическую программу можно перевести на язык машинных команд, например с помощью таблицы соответствия. Такой перевод может производить сама ЭВМ с помощью специальной программы, которая также называется ассемблером. Программа, написанная на исходном символическом языке, называется исходной, программа, переведенная на язык машинных команд с помощью программы ассемблера, называется объектной. В общем случае программы, преобразующие программу, написанную на одном языке, в программу на другом языке, называются трансляторами (в данном случае транслятором является программа ассемблер), а сам процесс перевода называется трансляцией. В программе, написанной на языке ассемблера, используется два типа команд: · символические команды для ЭВМ. · обращенные к ассемблеру (псевдокоманды), служащие для управления процессом трансляции. Псевдокоманды могут определять такие директивы для транслятора, как начало программы на языке ассемблера, зарезервировать указанное число ячеек памяти без установки (или с установкой) начального значения, начало новой программы и т. д. Формат оператора на языке ассемблера состоит из четырех полей: поля метки, поля операции, поля операндов и поля комментария. Для программирования на языке ассемблера ЭВМ должна быть укомплектована дисплеем и печатающим устройством для воспроизведения листинга — печатной копии программы, подготавливаемой транслятором, включающей операторы исходного языка и оттранслированную программу. Кроме программы транслятора используется еще ряд программ. Редактирующая программа оперирует исходной программой как с обычным текстом, позволяет добавлять, исключать или заменять части исходной программы. Компоновочная программа используется для объединения нескольких объектных программ (модулей) в одну общую программу, которая после этого получает название загрузочного модуля. Обычно программа состоит из нескольких частей — модулей. Модули могут транслироваться по отдельности, в результате чего получается несколько объектных модулей, которые должны войти в состав общей программы. Задачей компоновочной программы является объединение (связывание) всех модулей и привязка всей программы к абсолютным адресам ОП. Компоновочную программу называют также редактором связей. Другой классификацией языков программирования является их деление на языки, ориентированные на реализацию основ структурного программиров Популярное:
|
Последнее изменение этой страницы: 2016-04-10; Просмотров: 727; Нарушение авторского права страницы
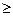 a+1 (4)
a+1 (4) dmin – 1 (5)
dmin – 1 (5)