
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Недостатки спиральной модели ⇐ ПредыдущаяСтр 8 из 8
· если проект имеет низкую степень риска или небольшие размеры, модель можетоказаться дорогостоящей. Оценка рисков после прохождения каждой спирали связана с большими затратами; · модель имеет усложненную структуру, поэтому может быть затруднено ее применение разработчиками, менеджерами и заказчиками; · серьезная нужда в высокопрофессиональных знаниях для оценки рисков; · спираль может продолжаться до бесконечности, поскольку каждая ответная реакция заказчика на созданную версию может порождать новый цикл, что отдаляет окончание работы над проектом (принятие общего решения о прекращении процесса разработки); · большое количество промежуточных стадий может привести к необходимости в обработке внутренней дополнительной и внешней документации; · использование модели может оказаться дорогостоящим и даже недопустимым по средствам, так как время, затраченное на планирование, повторное определение целей, выполнение анализа рисков и прототипирование, может быть чрезмерным; · при выполнении действий на этапе вне процесса разработки возникает необходимость в переназначении разработчиков; · могут возникнуть затруднения при определении целей и стадий, указывающих на готовность продолжать процесс разработки на следующей итерации;
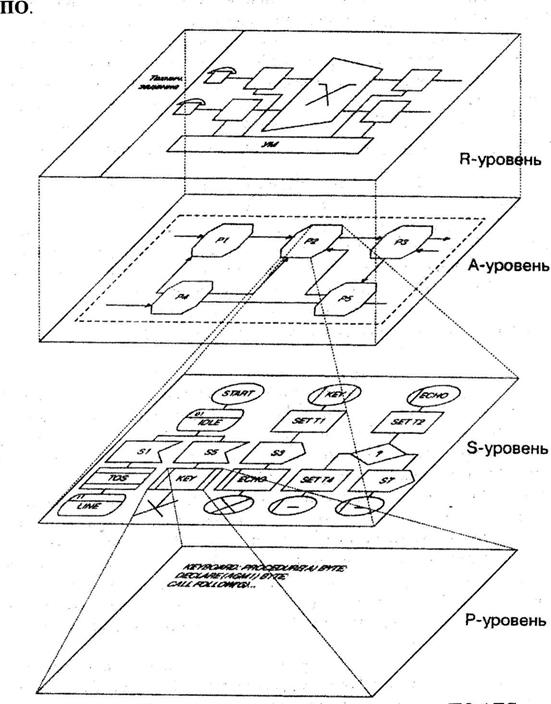
Не вдаваясь в детали других фаз жизненного цикла ПО, сосредоточимся на процессе разработки телекоммуникационного программного обеспечения. В схеме этого процесса, приведенной на рис., предусмотрена иерархическая декомпозиция процесса разработки на последовательность шагов, уточняющих проект. Такими укрупненными шагами (уровнями проектирования) являются: - анализ и формализация требований и интерфейсов коммутационного оборудования (R-уровень), - определение архитектуры (системной и функциональной) и модульной структуры ПО системное проектирование (А-уровень), - разработка SDL-спецификаций модулей (блоков, процессоров, процедур, макросов, структур данных) и межмодульных интерфейсов детальное проектирование (S-уровень) - программирование и отладка программ (Р-уровень); эксплуатация ПО.
Уровни проектирования различаются как степенью конкретизации (возрастающей сверху вниз), так и языковыми средствами описания. Представление системы ПО на вышестоящем уровне является в известном смысле «общим прародителем» семейства ее представлений на нижестоящих уровнях. На всех уровнях проектирования (а не только на S-уровне) производится последовательная спецификация задач, которые решает ПО. Под спецификацией здесь понимается описание в терминах, характерных для самой задачи, а не для ее реализации, служащее основой для дальнейшей детализации и разработки телекоммуникационного ПО. Можно считать, что каждый уровень проектирования получает спецификации от вышестоящего уровня и, в свою очередь, вырабатывает данные необходимые, для спецификации одного (или более) из нижестоящих уровней. Отличительные свойства спецификаций - однозначность, точность, формальность, понятность и читаемость. Как отмечено язык программирования более высокого уровня может считаться языком спецификаций по отношению к языку более низкого уровня.При этом спецификация программного модуля не обязана быть короче самого модуля, ибо от нее требуется не краткость, а точность и понятность. Определение и спецификация требований к ПО узла коммутации являются основными задачами R-уровня проектирования. На этом уровне разрабатываются технические требования, структурная схема станции, интерфейсы ПО с коммутационным оборудованием и т.д. Языком описания, как правило, служит естественный язык со всеми присущими ему недостатками - неоднозначностью, связанной с тем, что естественный язык недостаточно точен для описания программных систем, и разные разработчики могут по-разному понять одну и ту же фразу технического задания, и неполнотой описания ПО, которая усугубляется тем, что при разработке большой и сложной системы телекоммуникационных программ проходит много времени, прежде чем становится ясно, какой информации R-уровня недостает. Еще одна трудность, возникающая на R-уровне проектирования, -невозможность удержать семантику описания требований на одинаковом уровне детализации. В результате одни описания R-уровня оказываются несколько туманными, другие - излишне детализированными, предоставляя элементы реализации, причем, возможно, не самой удачной, выбранной без рассмотрения остальных частей системы и не позволяющей разработчикам следующих уровней проектирования использовать эффективные структуры данных или приемы программирования. После завершения R-уровня проектирования, т.е. когда точная внешняя спецификация системы программного управления коммутационного узла заменит ее неформальное описание, начинается разработка архитектуры ПО (А уровень). А уровень проектирования можно условно разделить на два подуровня: разработка функциональной архитектуры, разработка системной архитектуры. На том же А-уровне проектирования разрабатывается структурная модель программной системы, состоящая из иерархии содержательных функций, эффект выполнения которых влияет на функционирование коммутационного узла и обслуживание вызовов. Такая структурная модель в рекомендованном ITU-T языке спецификаций и описаний SDL называется диаграммой дерева блоков. Блок представляет собой наиболее крупный объект в SDL, который, в свою очередь, содержит один или несколько процессов. Разбиение системы ПО на составные части делается таким образом, чтобы каждая из частей была небольшой, удобной для восприятия и соответствующей естественному функциональному разбиению, и чтобы связи между частями, возникающие в результате разбиения, были как можно более слабыми. На каждом этапе разбиения специфицируются также каналы, входные сигналы, выходные сигналы и данные. Программная документация А- уровня служит исходными данными для проектирования SDL-спецификаций программных процессов, процедур и макросов, что в отечественной литературе иногда именуется алгоритмическим обеспечением АТС. Неформально алгоритм можно определить как совокупность правил, определяющих эффективную процедуру решения любой задачи из некоторого заданного класса задач. Детальное проектирование S-уровня включает в себя уточнение спецификаций интерфейсов программных модулей структур данных и проектирование SDL-диаграмм модулей. Проектирование SDL- диаграмм на S-уровне тоже выполняется сверху вниз методом пошаговых уточнений каналов, сигналов, процессов, процедур, макроопределений. Завершающим шагом разработки ПО является кодирование и отладка программ (Р-уровень проектирования). Именно Р-уровень многие называют программированием. В течение этого этапа программная разработка конвертируется в коды, которые могут исполняться в управляющих процессорах. Первые системы программного управления коммутацией создавались на языке Ассемблер. При успешном завершении испытаний оборудования и ПО на месте установки начинается процесс нормальной эксплуатации АТС. В процессе эксплуатации АТС с управлением по записанной программе в ПО могут вноситься изменения. Эти изменения могут быть связаны: с расширением станции и изменением характеристик, использующих её абонентов; исправлением ошибок, обнаруженных в процессе эксплуатации; повышением эффективности ПО; модификацией оборудования и появлением новых потребностей пользователей (абонентов). Качество ПО Наибольшую популярность приобрели некоторое время назад численные оценки качества программ, предложенные Холстедом. Согласно предложенной им метрике, длина программы N определяется как: N=g 1 log2g i+g2log2g2, где 131 — число простых операторов, a t)2 — число простых операндов в программе. В настоящее время используются модели оценки качества ПО, из которых мы упомянем две — одну, предложенную Институтом разработки программного обеспечения (SEI) университета Карнеги Меллона и называемую моделью мандатной зрелости (СММ), и другую, разработанную ISO (ТС-176). Обе модели поддерживают процесс сертификации организаций-разработчиков программного обеспечения. ЛЕКЦИЯ № 4 Программно-аппаратные средства контроля ЭУС Представление сообщений в цифровой форме с помощью первичных кодов отличается малой избыточностью или даже её отсутствием. Вследствие этого, безызбыточный код обладает большой «чувствительностью» к помехам. Ошибка в приеме только одного символа зачастую приводит к воспроизведению комбинации, отличной от переданной, так как в безызбыточном коде отдельные комбинации могут отличаться друг от друга только в одной позиции (в одном разряде). Если для передачи сообщений использовать не все комбинации первичного кода, а только те, которые отличаются друг от друга не менее чем в двух позициях, то одиночная ошибка при приеме переведет используемую (разрешенную) комбинацию в запрещенную. Это позволяет обнаружить указанную ошибку, появляющуюся вследствие помех приему. В данном случае одна разрешенная комбинация может перейти в другую разрешенную (не обнаруживаемая ошибка) только при двойной ошибке. Вероятность этого значительно меньше вероятности одиночной ошибки. Коды, у которых используются только некоторые из комбинаций, могут повысить помехоустойчивость приема. Поэтому они называются избыточными, или корректирующими. Корректирующие свойства избыточных кодов зависят от их структуры и параметров (длительности символов, числа разрядов, избыточности и т. п.). Простейшим примером корректирующего кода является код с проверкой на четность, который образуется следующим образом. К кодовым комбинациям безызбыточного первичного двоичного n-разрядного кода добавляется дополнительный разряд (позиция), называемый проверочным, или контрольным. Если число символов 1 в исходной кодовой комбинации четное, то в дополнительном разряде формируют контрольный символ 0, если число символов 1 нечетное, то в дополнительном разряде формируют контрольный символ 1. В результате общее число символов 1 в любой кодовой комбинации всегда должно быть четным. Добавление дополнительного разряда увеличивает общее число возможных комбинаций вдвое по сравнению с числом комбинаций исходного первичного кода, а условие четности разделяет все комбинации на разрешенные и неразрешенные. Таким образом, код с проверкой на четность позволяет обнаруживать одиночную ошибку, поскольку она переводит разрешенную комбинацию в неразрешенную. Увеличивая число дополнительных разрядов и формируя по определенным правилам проверочные символы 0 или 1, соответствующие этим разрядам, усиливают корректирующие свойства кода так, чтобы он позволял не только обнаруживать, но и исправлять ошибки. Поэтому избыточные или корректирующие коды разделяются на коды, обнаруживающие ошибки, и коды, исправляющие ошибки. Таким образом, для обнаружения ошибки достаточно установить факт, что в данной кодовой комбинации произошла ошибка (одиночная, двойная и т. п.). Для исправления ошибки необходимо не только обнаружить ошибку, но и указать ту позицию в кодовой комбинации, где эта ошибка произошла. Задача исправления ошибки более сложная, чем ее обнаружение, и требует применения более сложных кодов. В настоящее время наиболее широко используются двоичные равномерные корректирующие коды, обладающие хорошими корректирующими свойствами и простотой реализации. Данные коды разделяют на блочные и непрерывные. При использовании блочных кодов цифровая информация передается в виде отдельных блоков кодовых комбинаций равной длины. Кодирование и декодирование каждого блока осуществляется независимо друг от друга. Почти все блочные коды относятся к разделимым кодам, кодовые комбинации которых состоят из двух различающихся частей: информационной и проверочной. Информационные и проверочные разряды во всех кодовых комбинациях разделимого кода всегда занимают одни и те же позиции. Разделимые коды обычно обозначаются в виде (n, k ), где n указывает значность кода (общее число позиций в блоке), k – число информационных позиций. Иными словами, величина n определяет общее число символов в блоке, a k – только число информационных символов. Число проверочных символов в разделимых кодах равно r = n – k. Среди разделимых кодов различают систематические и несистематические коды. В систематических кодах проверочные символы образуются линейными комбинациями информационных символов. Теоретической основой получения таких комбинаций является аппарат линейной алгебры, позволяющий формировать проверочные символы по определенной системе – отсюда и происхождение термина «систематические» коды. Использование указанного аппарата привело к тому, что данные коды также называются алгебраическими. Среди систематических кодов наиболее известны циклические коды Хэмминга, коды Боуза-Чоудхури и др. Основное свойство циклических кодов состоит в том, что циклический сдвиг любой разрешенной кодовой комбинаций также является разрешенной комбинацией. Циклические коды обладают хорошими корректирующими свойствами, а реализация кодеров и декодеров таких кодов оказывается проще, чем для других систематических кодов. Такие коды характеризуются тем, что в них проверочные символы перемежаются с информационными, и нет четкого деления последовательности символов на выходе кодера на отдельные кодовые комбинации. Формирование проверочных символов в непрерывных кодах ведется по рекуррентным правилам. Кодирование и декодирование этих кодов несколько проще, чем блочных систематических. Непрерывные коды могут иметь хорошие корректирующие свойства, особенно в случае пакетов ошибок. Основными параметрами корректирующих кодов являются их избыточность, кодовое расстояние, а также число обнаруживаемых или исправляемых ошибок Избыточностью корректирующего кода называют величину:
w = r / n = (n - k) / n = 1 – k / n (1)
где n - значность кода (общее число позиций в блоке); k – число информационных позиций в блоке; r - число проверочных символов в разделимых кодах.
Откуда следует: k / n = 1 – w (2) Величину k/n, которая показывает, какую часть общего числа символов кодовой комбинации составляют информационные символы, называют скоростью кода. Она характеризует относительную скорость передачи информации. Если производительность источника информации равна Н символов в секунду, то скорость передачи этой информации после кодирования R окажется равной: R = Hk / n (3) Если число ошибок, которые нужно обнаружить или исправить, велико, то необходимо иметь код с большим числом проверочных символов. Чтобы при этом скорость передачи оставалась достаточно высокой, необходимо в каждом кодовом блоке одновременно увеличивать как общее число символов, так и число информационных символов. При этом длительность кодовых блоков будет существенно возрастать, что приведет к задержке информации при передаче и приеме. Чем сложнее кодирование, тем больше временная задержка передачи информации. Кодовым или расстоянием Хэмминга d между двумя кодовыми комбинациями называют число позиций, в которых эти комбинации имеют разные символы. Например, расстояние между комбинациями 0001101 и 1001010 равно четырем (d = 4). Расстояние между различными комбинациями конкретного кода может быть различным. Так, в частности, в безызбыточном первичном натуральном коде это расстояние для различных комбинаций может различаться от единицы до величины m, равной значности кода. Особую важность для характеристики корректирующих свойств кода имеет минимальное или хэмминговое расстояние dmin между кодовыми комбинациями. Это расстояние называют кодовым. В безызбыточном коде все комбинации являются разрешенными и, следовательно, его кодовое расстояние равно единице. Поэтому достаточно исказить один символ, чтобы вместо переданной комбинации была принята другая разрешенная комбинация. Чтобы код обладал корректирующими свойствами, необходимо ввести в него некоторую избыточность, которая обеспечивала бы минимальное расстояние между разрешенными комбинациями не менее двух. Кодовое расстояние является основным параметром, характеризующим корректирующие способности данного кода. Если код используется только для обнаружения ошибок кратности а, то необходимо и достаточно, чтобы минимальное расстояние было равно:
dmin
В этом случае никакая комбинация из а ошибок не может перевести одну разрешенную кодовую комбинацию в другую разрешенную. Таким образом, условие обнаружения всех ошибок кратности а можно записать в виде:
a обн
Для исправления всех ошибок кратности а и менее, необходимо иметь минимальное расстояние
dmin
В этом случае любая кодовая комбинация с числом ошибок а отличается от каждой разрешенной комбинации не менее, чем в а+1 позициях. Если условие (11) не выполнено, возможен случай, когда ошибка кратности а исказит переданную комбинацию так, что она станет ближе к одной из разрешенных комбинаций, чем к переданной, или даже перейдет в другую разрешенную комбинацию.
Итак, условием исправления всех ошибок кратности не более а является:
a испр
Корректирующие коды можно одновременно использовать и для обнаружения и для исправления ошибок. Минимальное расстояние, при котором можно исправить все ошибки кратности а или меньше и одновременно обнаружить все ошибки кратностью b> а или меньше, определяется условием:
dmin
Задача определения минимально необходимой избыточности, при которой код обладает нужными корректирующими свойствами, до сих пор не имеет полного решения. Известен лишь ряд верхних и нижних оценок (границ), которые устанавливают связь между максимально возможным минимальным расстоянием корректирующего кода и его избыточностью. В ряде случаев при передаче информации простым безызбыточным кодом получающаяся достоверность приема недостаточна. Одним из путей ее повышения является применение корректирующего кода. Выбор того или иного кода и его параметров зависит от конкретных условий решаемой задачи: требуемой достоверности приема, допустимой относительной скорости передачи, вида ошибок в канале и т. п. В теории помехоустойчивого кодирования различают два вида основных ошибок: статистически независимые (некоррелированные) и статистически зависимые (коррелированные) ошибки (пачки или пакеты ошибок). Покажем на простом примере возможность повышения помехоустойчивости с помощью корректирующего кода и определим, при каких условиях применение такого кода целесообразно. При этом будем полагать, что ошибки в канале независимы, а сам канал симметричен. Такие условия характерны для гауссовских каналов, в которых применяются посылки сигналов с одинаковыми энергиями. При независимых ошибках симметричный канал полностью характеризуется вероятностью ошибочного приема символа. Хотя соотношения, характеризующие распределение ошибок, при этом оказываются простыми, однако оценка корректирующих возможностей кода в данном случае является ориентировочной. В случае посимвольного (поэлементного) приема каждая посылка сигнала, соответствующая определенному символу кодовой комбинации, анализируется в приемном устройстве отдельно, а затем принимается решение, к какой из возможных кодовых комбинаций следует отнести полученную последовательность символов. В случае приема в целом анализируется сразу вся принятая кодовая комбинация. Такой анализ предполагает, что число оптимальных (или подоптимальных) фильтров или корреляторов в приемном устройстве равно числу используемых разрешенных кодовых комбинаций. Суть вероятностного, или последовательного декодирования состоит в том, что вся совокупность возможных кодовых комбинаций (включая разрешенные и запрещенные) разбивается на две группы: высоковероятные и маловероятные. Если принятая комбинация ближе к высоковероятной группе, она декодируется сразу же без проверки. Если же принятая комбинация ближе к маловероятным комбинациям, она декодируется с проверкой и исправлением ошибок. Иными словами, сильно искаженные комбинации исправляются, а слабо искаженные декодируются без исправления. Такое декодирование несколько уступает в помехоустойчивости оптимальному, но заметно проще в реализации. Суть алгебраического декодирования состоит в том, что исправляется только определенная часть ошибок, т. е. корректирующие возможности кода используются только частично. Это означает, что используется неоптимальный алгоритм декодирования, допускающий более простую схемную реализацию. Особенно удобны с точки зрения простоты декодирования циклические коды, являющиеся разновидностью систематических кодов. Для таких кодов разработаны эффективные методы алгебраического декодирования. Применение корректирующих кодов связано с некоторым усложнением систем передачи информации, особенно за счёт введения декодирующих устройств. Однако стремление к повышению скорости передачи по существующим линиям связи и возрастающие требования к достоверности передаваемой информации привели к широкому применению помехоустойчивого кодирования.
Популярное:
|
Последнее изменение этой страницы: 2016-04-10; Просмотров: 714; Нарушение авторского права страницы
 a+1 (4)
a+1 (4) dmin – 1 (5)
dmin – 1 (5)