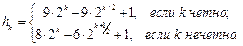|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Алгоритмы сортировки массивовСтр 1 из 11Следующая ⇒
Введение Содержание и структура пособия
Это пособие посвящено одному из наиболее интересных и практически ценных разделов информатики – алгоритмам и структурам данных, используемым для решения задач сортировки и поиска. Цель пособия – в компактном объеме дать студентам достаточно широкий обзор различных вариантов постановки задач сортировки и поиска и при этом рассмотреть основные алгоритмы решения этих задач с такой степенью подробности, которая позволила бы использовать полученные знания в практической работе. В разделе 2 рассматривается задача поиска в таблице и показывается преимущество бинарного поиска в сортированном массиве перед линейным просмотром массива. Отсюда вытекает важность задачи сортировки массивов, способы решения которой подробно рассматриваются в разделе 3. При этом демонстрируется поразительное повышение эффективности сортировки, достигаемое путем замены простых алгоритмов на более изощренные усовершенствованные алгоритмы. В разделе 4 рассмотрены проблемы, возникающие, когда операции поиска должны чередоваться с добавлением и удалением записей в таблицу. В качестве решения этих проблем рассматривается использование бинарных и страничных деревьев поиска, в том числе такого широко распространенного аппарата, как B-деревья. В разделах 5 и 6 рассмотрены методы сортировки и поиска, выходящие за рамки обычного подхода, основанного на сравнении ключей. Показано, что в специальных случаях эти методы способны обеспечить существенное ускорение работы. Особое внимание уделено такому важному методу, как хеширование ключа. В разделе 7 рассматриваются две задачи, лежащие несколько в стороне от проблемы поиска в таблицах, но тесно связанные с ней по постановке и по методам решения. Это задача определения порядковых статистик и задача поиска подстроки в строке. В конце каждого раздела приведены вопросы и упражнения, позволяющие закрепить и углубить понимание рассмотренных вопросов. Излагаемые алгоритмы и методы являются результатом исследований, проводившихся многими специалистами в течение нескольких десятилетий. В книгах [1, 2, 3, 4, 5] можно найти более подробное описание этих алгоритмов, их теоретический анализ, а также много интересных алгоритмов и структур, не упомянутых в данном пособии. Учебное пособие не является справочником по алгоритмам, поэтому тексты программ на Паскале или на псевдокоде приводятся только в тех случаях, когда это проще, чем объяснить детали алгоритма на словах. В остальных случаях реализация алгоритма оставлена для выполнения студентами в рамках лабораторных или самостоятельных занятий. Задачи поиска в информатике Задачи поиска данных занимают в информатике исключительно важное место. С одной стороны, информационный поиск вообще является одним из важнейших предназначений современной компьютерной техники. Из огромного количества прикладных задач, связанных с поиском, можно назвать, например, выполнение запросов к базам данных, поиск заданного текста в файле, поиск страниц в Интернете. В этих примерах сама постановка задачи явно указывает на необходимость выполнения поиска данных. С другой стороны, при подробном рассмотрении алгоритмов, по которым работают различные системные и прикладные программы, можно обнаружить, что значительное место в их работе занимают процедуры поиска данных в разного рода внутренних таблицах. Когда пользователь вводит с клавиатуры команду, система должна отыскать эту команду в таблице, чтобы выполнить соответствующие действия. При работе транслятора с любого языка программирования постоянно выполняется поиск в таблицах имен, ключевых слов и операций. В таких случаях понятие поиска не входит в исходную постановку, а возникает как необходимое условие успешной реализации алгоритмов, решающих задачу. По некоторым оценкам, разнообразные виды поиска занимают больше половины всего времени работы процессора в типичных вычислительных системах. Отсюда следует чрезвычайная важность эффективной реализации процедур поиска для повышения скорости работы программ и общей производительности системы. Задача поиска в таблице В данном пособии основное внимание уделено задаче поиска данных в таблице по заданному значению ключа. Под таблицей мы будем понимать совокупность записей, в которой каждая запись состоит из поля ключа и поля данных. Задачу поиска в таблице можно сформулировать следующим образом. Дано значение ключа. Требуется определить, имеется ли в таблице запись с этим ключом. Если такая запись есть, то требуется получить к ней доступ. При этом в одних случаях достаточно только получить значение поля данных (доступ на чтение), в других случаях нужна также возможность изменять поля записи или удалять запись (доступ на изменение). Если искомый ключ отсутствует в таблице, то можно потребовать, чтобы процедура поиска определила место, куда может быть вставлена новая запись с этим ключом. В этом случае говорят о задаче поиска со вставкой. Самым распространенным представлением таблицы в памяти является массив записей (рис. 1.1, а). Однако массив – не единственная возможная форма представления таблицы. Иногда более удобным или более эффективным может оказаться представление таблицы в виде линейного списка, дерева или более сложной структуры (например, дерева массивов, массива списков и т.п.). Кроме того, весьма важен случай таблиц, хранящихся в файлах на внешнем носителе, при этом размещение записей в файле не обязательно должно быть последовательным. Некоторые представления таблиц показаны на рис. 1.1.
Рис. 1.1. Варианты представления таблиц: а – массив; б – бинарное дерево; в – массив списков Конечно, на самом деле записи таблицы могут иметь более сложную структуру. Данные часто занимают не одно поле, а несколько полей, однако это никак не сказывается на выполнении поиска. Более существенно то, что ключевых полей тоже может быть несколько, при этом выбор ключа для поиска определяется видом конкретного запроса. В данном пособии этот вопрос будет затронут лишь кратко, основное же внимание будет уделено поиску по единственному ключу. Возникают также вопросы, связанные с уникальностью или неуникальностью ключа. Ключ называется уникальным, если таблица не может содержать двух или более записей с одинаковыми значениями ключа. В случае неуникального ключа следует точно оговорить, что должно считаться результатом успешного поиска: одна из записей с искомым значением ключа (и какая именно) или множество всех таких записей. На практике вопрос уникальности ключа не столь существен для большинства алгоритмов, а потому этот вопрос будет затрагиваться только в случае необходимости. Сделаем одно существенное упрощение. Чтобы не загромождать примеры обозначениями полей записи, мы в дальнейшем не будем выделять в записях таблицы поле ключа и поле данных. Будем считать, что таблица состоит из простых элементов, которые сравниваются и переставляются как единое целое. Такую упрощенную таблицу можно назвать просто массивом, однако при этом не надо забывать, что элементы не обязательно расположены последовательно, они могут образовывать списки, деревья и другие структуры данных. Запишем некоторые определения данных, которые будут использоваться в дальнейшем изложении.
const N =...; {Размер таблицы (произвольная константа)} type KeyType =...; {Здесь может быть любой тип данных, допускающий операции сравнения и присваивания; например, Integer} RecordType = KeyType; {Как сказано выше, мы не будем отличать запись от ее ключа} TableType = array [1..N] of RecordType; Поиск в массивах Линейный поиск Рассмотрим простейшую задачу поиска элемента в массиве. Дан массив A, состоящий из n элементов, и дано значение x:
var A: TableType; {Таблица (массив) данных} x: KeyType; {Искомый элемент}
Требуется определить, содержится ли в массиве A элемент, равный x, и если содержится, то на каком месте (при каком значении индекса массива). Если элементы в массиве A расположены в произвольном порядке, то единственный способ решить поставленную задачу заключается в последовательном просмотре всех элементов. Соответствующая функция может выглядеть, например, так:
function LinearSearch(A: TableType, x: KeyType ): Integer; var i: Integer; begin i: = 1; while (i < = N) and (A[i] < > x) do i: = i+1; if i < = N then LinearSearch: = i {Успех} else LinearSearch: = 0; {Неудача} end; {LinearSearch}
Этот простейший алгоритм называется линейным поиском в массиве. Он сравнивает искомый ключ x последовательно с каждым элементом массива. Функция возвращает индекс найденного элемента либо 0, если ключ не найден в массиве. В программе намеренно не использован цикл for. Это сделано для более наглядного сравнения с алгоритмом, который будет описан ниже. Оценим эффективность алгоритма линейного поиска. Очевидно, время его работы будет пропорционально числу элементов в массиве: T(n) = O(n). В таких случаях говорят, что алгоритм имеет линейную оценку относительно размера массива. Если проанализировать время выполнения более детально, то можно сказать, что максимальное количество итераций равно n (в случае, если искомый ключ находится в последней позиции массива или вообще отсутствует), а среднее число итераций при успешном поиске равно n/2 (искомое значение может с равной вероятностью находиться в любой позиции, в среднем это даст n/2), а при неудаче поиска среднее число итераций равно максимальному n. Важно отметить, что в любом случае число итераций (а стало быть, и время выполнения) остается пропорциональным размеру массива. Линейная оценка – хорошо это или плохо? Если бы речь шла о какой-либо сложной и редко решаемой задаче, то такая оценка была бы верхом мечтаний. Но для столь массовой задачи, как поиск в таблице, следует поискать более быстрый алгоритм. Можно добиться некоторого ускорения работы, оставаясь в рамках линейного поиска. Известен, например, полезный прием, который называется барьерным поиском. Для его использования необходимо, чтобы в конце (или в начале) массива оставалось одно свободное место. Поэтому предположим временно, что тип массива описан так: var TableType1 = array [1..N+1] of RecordType; При этом число записей по-прежнему равно n, а позиция n+1 не содержит данных. Тогда функция барьерного поиска будет выглядеть следующим образом:
function BarrierSearch(var A: TableType1, x: KeyType ): Integer; var i: Integer; begin i: = 1; A[N+1]: = x; {Установка барьера} while A[i] < > x do i: = i+1; if i < = N then BarrierSearch: = i {Успех} else BarrierSearch: = 0; {Неудача} end; {BarrierSearch}
Отличие от предыдущего алгоритма заключается в том, что искомый элемент x искусственно добавляется в массив. В результате этого можно быть уверенным, что x будет найден в любом случае. Вопрос только в том, будет ли он найден среди n «настоящих» элементов массива или же встретится только в «искусственной» позиции n+1. В чем выигрыш от использования барьера? Можно заметить, что это позволило упростить проверку в заголовке цикла. Поскольку же итерация цикла всего-то состояла из двух проверок и одного присваивания, отмена одной из проверок может уменьшить время выполнения процентов на 30. Это не меняет линейного характера оценки O(n), но не стоит пренебрегать существенным улучшением, которое достигается так просто. Однако напомним, что для применения барьера необходимо, чтобы с одного из концов массива была свободная позиция, причем доступная для записи. Барьерный поиск – это типичный пример «мелкой оптимизации», которая мила сердцу почти каждого программиста, позволяет кое-что выиграть только за счет программистской техники, но не дает кардинального улучшения решения. Чтобы получить более значительное ускорение поиска, надо искать принципиально другой подход. Бинарный поиск Теперь предположим, что массив A является сортированным, т.е. значения в нем расположены по возрастанию значений ключа. В этом случае можно применить совершенно иной, более быстрый алгоритм поиска, не требующий проверки всех подряд элементов. Вместо этого сравним искомый ключ x со значением среднего по порядку элемента массива, т.е. элемента с индексом (n+1)/2. Если n четное, то неважно, какой из двух средних элементов будет выбран. Если x окажется меньше, чем проверяемый средний элемент, то ясно, что искомое значение может содержаться только в левой половине массива (или нигде). И наоборот, если x больше проверяемого элемента, то поиск надо продолжать в правой половине массива. В том и другом случае выполнение одной проверки позволяет в два раза уменьшить размер той части массива, в которой следует искать x. Далее та же процедура применяется к выбранной половине массива (т.е. проверяется элемент с индексом либо (n+1)/4, либо 3(n+1)/4) и т.д., пока не будет найден нужный элемент либо не обнаружится его отсутствие. Описанный алгоритм называется бинарным поиском в массиве. Соответствующая функция поиска приведена ниже.
function BinarySearch(A: TableType, x: KeyType ): Integer; var i, j, q: Integer; begin i: = 1; j: = N; repeat q: = (i + j) div 2; if A[q] < x then i: = q + 1 else j: = q – 1; until (A[q] = x) or (i > j); if A[q] = x then BinarySearch: = q {Успех} else BinarySearch: = 0; {Неудача} end; {BinarySearch}
Переменные i и j играют роль подвижных границ той части массива, в которой может находиться значение искомого ключа. Каждое сравнение приводит к сужению вдвое интервала поиска за счет перемещения одной из этих границ. Оценим эффективность алгоритма. Каждая итерация цикла (включающая проверку значения и смещение одной из границ) сокращает интервал поиска по меньшей мере в два раза. Поиск завершается, когда интервал сведется к одному элементу. Для этого придется выполнить не более log2n итераций. Таким образом, можно сказать, что алгоритм бинарного поиска имеет логарифмическую оценку эффективности T(n) = O(log(n)). Сопоставим это с числом итераций линейного поиска, примерно равным n. Соответствующие значения для разных n приведены в табл. 2.1. Таблица 2.1
Если учесть, что одна итерация бинарного поиска заметно сложнее, чем одна итерация линейного поиска, то можно сделать примерно следующие выводы. Для очень маленьких таблиц, имеющих около 10 элементов, использование бинарного поиска не дает существенного выигрыша по сравнению с линейным. Для таблиц размером около 100 выигрыш уже ощутим, но необходимость использования бинарного поиска еще можно считать спорной (потому что на современных процессорах экономия составит не более нескольких микросекунд). Однако при размерах от 1000 и выше спорить уже не приходится, поскольку бинарный поиск работает просто несравнимо лучше, чем линейный. Не будем только забывать, что для применимости бинарного поиска требуется, чтобы массив был сортированным. Вопросы и упражнения 1. Как следует изменить алгоритм барьерного поиска, если свободная позиция находится не в конце, а в начале массива? 2. Есть такая математическая игра. Один человек задумывает число от 1 до 1 000, а другой должен определить это число, задав десять вопросов, на которые первый отвечает «Да» или «Нет». Какие вопросы следует задавать? Сколько потребуется вопросов, если задумано число от 1 до 1 000 000? 3. Дан массив целых чисел A = (–5, –2, 3, 8, 12, 12, 15, 20, 30, 35, 40, 41, 41, 49, 50). Выполните вручную алгоритм бинарного поиска для ключа x = 12 и для ключа x = 42, выписывая значения i, j, q, A[q]. Алгоритм Шелла (ShellSort) Идея этого алгоритма в следующем. Разобьем элементы сортируемого массива на h цепочек, каждая из которых состоит из элементов, отстоящих друг от друга на расстояние h (здесь h – произвольное натуральное число). Первая цепочка будет содержать элементы a1, ah+1, a2h+1, a3h+1 и т.д., вторая – a2, ah+2, a2h+2 и т.д., последняя цепочка – ah, a2h, a3h и т.д. Отсортируем каждую цепочку как отдельный массив, используя для этого метод простых или бинарных вставок. Затем выполним все вышеописанное для ряда убывающих значений h, причем последний раз – для h = 1. Очевидно, массив после этого окажется сортированным. Неочевидно, что все проходы при h > 1 не были пустой тратой времени. Тем не менее, оказывается, что дальние переносы элементов при больших h настолько приближают массив к сортированному состоянию, что на последний проход остается очень мало работы. Большое значение для эффективности алгоритма Шелла имеет удачный выбор убывающей последовательности значений h. Казалось бы, самая естественная убывающая последовательность чисел это степени двойки: …, 64, 32, 16, 8, 4, 2, 1. Сам автор алгоритма Дональд Шелл первоначально предложил использовать именно эти числа. На самом же деле выбор этой последовательности – один из самых неудачных! Пусть, например, в исходном массиве все нечетные по номеру элементы отрицательны, а четные – положительны. Как будет выглядеть такой массив после выполнения всех проходов, кроме последнего (с h = 1)? Поскольку все использованные h были четными, ни один элемент не мог переместиться с четного места на нечетное и наоборот. Таким образом, все нечетные элементы по-прежнему будут отрицательны (хотя и отсортированы между собой), а четные – положительны. Подобный массив трудно назвать «почти сортированным»! На последний проход алгоритма вставки остается слишком много работы. Чтобы избежать подобной неприятности, желательно, чтобы при соседних значениях k значения hk не были кратны друг другу. В литературе обычно рекомендуется использовать одну из двух последовательностей: hk+1 = 3hk+1 или hk+1 = 2hk+1. В обоих случаях в качестве начального hk выбирается такое значение из последовательности, при котором все сортируемые цепочки имеют длину не меньше 2. Чтобы воспользоваться, например, первой из этих формул, надо сначала положить h1: =1, а затем в цикле увеличивать значение h по формуле hk+1: = 3*hk+1, пока для очередного hk не будет выполнено неравенство hk ³ (n–1) div 3. Это значение hk следует использовать на первом проходе алгоритма, а затем можно получать следующие значения по обратной формуле: hk–1: = (hk–1) div 3, вплоть до h1=1. Для каждой из этих двух последовательностей время работы в худшем случае оценивается как Tмакс(n) = O(n3/2). Это значительно лучше, чем O(n2) для простых алгоритмов. Для среднего времени работы известны только эмпирические оценки, показывающие, что время растет примерно как O(n1.25) или O(n1.3). Ряд авторов на основе теоретического анализа сортировки Шелла предложили использовать более сложные последовательности, повышающие эффективность алгоритма. Одной из лучших считается последовательность, предложенная Р.Седжвиком:
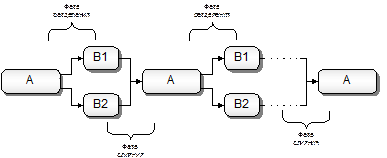
Доказано, что при выборе hk по Седжвику максимальное время работы алгоритма есть O(n4/3). Среднее время по эмпирическим оценкам равно примерно O(n7/6). На практике удобно раз и навсегда вычислить достаточное количество членов последовательности Седжвика (вот они: 1, 5, 19, 41, 109, 209, 505, 929, 2 161, 3 905, 8 929, 16 001, 36 289, 64 769, 14 6305, 260 609, 587 521, 1 045 505, ...), затем по заданному n выбрать такое k, при котором hk > = (n–1) div 3, а далее в цикле выбирать значения последовательности hk по убыванию k. Задача внешней сортировки Все ранее рассматривавшиеся алгоритмы сортировки были ориентированы на работу с массивом, полностью помещающемся в оперативной памяти компьютера. Между тем, несмотря на постоянное возрастание емкости памяти современных компьютеров, не теряют своей актуальности задачи сортировки и поиска в больших наборах данных, которые хранятся в файлах и не могут быть полностью считаны в оперативную память. В частности, подобные задачи возникают при работе систем управления базами данных. Задача сортировки данных, расположенных во внешней памяти и только по частям считываемых в оперативную память, называется задачей внешней сортировки (в отличие от задачи внутренней сортировки, которую мы рассматривали до сих пор). Формально говоря, любой из описанных алгоритмов может быть применен и к задаче внешней сортировки. Это возможно хотя бы потому, что современные операционные системы позволяют работать с файлами как с виртуальными массивами, т.е. обращаться к их записям по индексу, возложив на систему планирование и выполнение операций чтения и записи данных на внешнее устройство. Однако попытка применить, например, QuickSort или HeapSort для сортировки файла вызовет катастрофическое замедление работы, как только файл перестанет целиком помещаться в оперативной памяти, отведенной программе. Это связано с тем, что алгоритмы внутренней сортировки оптимизированы по количеству операций, выполняемых над данными в оперативной памяти, прежде всего операций сравнения ключей и операций присваивания (перестановки) записей. Делая оценки эффективности алгоритмов, мы подсчитывали количество итераций циклов, а основным содержанием каждой итерации были как раз сравнения и присваивания. Как известно, операции обмена с внешней памятью (т.е. чтения и записи на устройства) выполняются во много раз медленнее. При этом надо учитывать не только более низкую скорость передачи данных, но и существенное замедление работы при поиске требуемого блока данных (сектора диска). Поэтому при оценке алгоритмов внешней сортировки следует подсчитывать в первую очередь количество операций обращения к устройству, а операциями, выполняемыми в оперативной памяти, можно в большинстве случаев вообще пренебречь. Если с этой точки зрения посмотреть на алгоритмы QuickSort, HeapSort и ShellSort, то картина окажется невеселой. Все эти алгоритмы резво скачут из конца в конец сортируемого массива, обеспечивая высокую эффективность прежде всего за счет дальних пересылок элементов. Для этих алгоритмов чуть ли не каждое обращение к элементу массива может потребовать выполнения операции чтения или записи в файл. Совершенно по-другому ведет себя сортировка слиянием. Обычно этот алгоритм для файлов реализуют как чередование двух фаз работы: фазы разделения и фазы слияния (рис. 3.3).
Рис. 3.3. Двухфазное слияние файлов На фазе разделения исходный файл A просматривается от начала до конца и из него выделяются серии записей, упорядоченные по возрастанию. Нечетные по счету серии записываются во вспомогательный файл B1, четные – в файл B2. На фазе слияния просматриваются файлы B1 и B2, прочитанные из них серии попарно сливаются и записываются в файл A. Фазы разделения и слияния повторяются до тех пор, пока в A не будет записана единственная серия, содержащая все элементы в отсортированном виде. Число проходов разделения/слияния может быть значительно сокращено, если на первом проходе сразу после чтения очередной порции данных из файла выполнить внутреннюю сортировку этой порции любым эффективным алгоритмом (например, QuickSort). Это будет эквивалентно созданию очень длинных возрастающих серий, размер которых ограничен только доступным объемом оперативной памяти. Чтение и запись файлов как на фазе разделения, так и на фазе слияния выполняется только последовательно, от начала к концу. Эта особенность алгоритмов слияния была особенно важна в старые времена, когда основным видом внешних носителей данных были магнитные ленты. Однако и при работе с устройствами произвольного доступа (дисками) желательно как можно меньше пользоваться этим самым произвольным доступом, поскольку он приводит к слишком частым перемещениям читающих головок и, следовательно, к замедлению работы. Основной недостаток алгоритмов слияния – потребность во вспомогательном массиве – для случая сортировки файлов выступает как потребность в двух вспомогательных файлах B1 и B2, суммарный размер которых равен размеру сортируемого файла. Конечно, это не очень приятное свойство, однако дисковое пространство обычно является менее дефицитным ресурсом, чем оперативная память. Оценка эффективности методов внешней сортировки «в смысле O-большое», приводит к результату, на первый взгляд парадоксальному. Одна и та же оценка T(n) = O(n× log(n)) получается и для «подходящего» MergeSort, и для «неподходящего» QuickSort. Но здесь надо вспомнить, что оценка с точностью до O-большого характеризует только скорость роста времени при увеличении n, конкретные же значения T(n) очень сильно различаются для разных алгоритмов. В первом приближении можно считать, что для алгоритмов слияния значение n как бы делится на число записей таблицы, помещающихся в одном секторе диска. Вопросы и упражнения 1. Сколько сравнений выполняется при сортировке массива из n элементов по алгоритму пузырька? 2. При каком условии алгоритм пузырька может завершить сортировку массива за n –2 прохода? за n –3 прохода? На сколько операций сравнения меньше будет выполнено в этих случаях? 3. Предположим, что в алгоритме вставок значение переменной r сравнивается со значениями элементов массива не в обратном порядке ( ak, ak–1, ak–2 …, a1 ), а в прямом ( a1, a2, a3 …, ak ). Повлияет ли это на правильность и эффективность алгоритма? Какой из двух вариантов больше подходит для сортировки Шелла? 4. Объясните, почему в нерекурсивном варианте QuickSort при занесении в стек более длинных отрезков глубина стека оказывается меньше, чем при занесении более коротких. 5. Объясните, почему в рекурсивном варианте QuickSort глубина используемого стека оказывается значительно больше, чем в нерекурсивном. 6. Запрограммируйте смешанный вариант QuickSort, в котором разделение массива и сортировка меньшего из получившихся отрезков выполняется в цикле, а для сортировки большего отрезка используется рекурсивный вызов (при этом нет необходимости явно использовать переменную-стек). 7. Какая глубина стека может потребоваться для реализации QuickSort, описанной в предыдущем упражнении? 8. Алгоритм сортировки называется устойчивым, если элементы массива, имеющие одно и то же значение ключа, сохраняют после сортировки свое взаимное положение. Какие из рассмотренных в разделе алгоритмов являются устойчивыми? 9. Дан массив чисел A = (10, 50, 30, 32, 11, 40, 20, 5, 16, 37, 12, 1). Выполнить сортировку массива по алгоритму ShellSort, используя значения h = 7, 3, 1. Показать состояние массива после каждого прохода. 10. Дан массив чисел A = (20, 13, 5, 25, 16, 18, 40, 32, 21, 11, 1, 30). Выполнить сортировку массива по алгоритму QuickSort. В качестве разделяющего выбирать первый элемент отрезка. Показать состояние массива после каждой операции разделения. 11. Дан массив чисел A = (35, 8, 24, 12, 42, 15, 31, 40, 14, 50). Выполнить преобразование массива в пирамиду (1-я фаза алгоритма HeapSort) и два первых прохода второй фазы алгоритма. Показать состояние массива после каждой операции просеивания. Задача поиска со вставкой До сих пор мы предполагали, что сортировка массива является предварительно выполняемой операцией, после которой многократно выполняется поиск по сортированному массиву. Однако на практике едва ли не чаще встречается несколько иная ситуация, когда операции поиска чередуются с операциями модификации массива, т.е. со вставками и удалениями элементов массива, изменениями значений элементов. В качестве примера можно рассмотреть информационную подсистему по контингенту студентов. Запросы типа «найти такого-то студента» могут перемежаться корректировками контингента: одного студента отчислить, другого зачислить в порядке перевода из другого вуза, у такой-то студентки изменить фамилию. Другой пример связан с работой компилятора, использующего таблицы имен переменных. При появлении имени в тексте компилируемой программы компилятор должен выяснить, встречалось ли это имя ранее (чтобы определить, была ли переменная описана до ее употребления, нет ли повторного описания и т.п.), и если обнаружится, что имя встречается впервые, его следует занести в таблицу имен. Как организовать эффективный поиск в подобной ситуации? Конечно, можно при каждой корректировке массива предпринимать действия для сохранения его сортированности. Но это потребует времени порядка O(n) на каждую корректировку. Например, при вставке нового элемента потребуется сначала определить, на какое место он должен быть вставлен (это бинарный поиск, т.е. O(log(n))), а потом сдвинуть последующие элементы на одну позицию, чтобы освободить выбранное место. В среднем придется сдвигать половину элементов массива, что и дает оценку O(n). А если не заботиться о сохранении сортированности? Тогда корректировки могут быть выполнены очень быстро, за время порядка O(1) (например, можно вставлять новые элементы всегда в конец массива), но поиск при этом замедляется до O(n) (линейный, а не бинарный поиск). Возможно ли такое решение проблемы, чтобы оценка времени как для поиска, так и для вставки/удаления элементов не превышала «хорошего» O(log(n))? Да, возможно, но для этого придется отказаться от использования такой структуры данных, как массив, и воспользоваться более гибкими сцепленными структурами. В связи с вышесказанным, в данном разделе мы будем рассматривать не чистую задачу поиска, а задачу поиска со вставкой, которую можно сформулировать следующим образом. Дана таблица A, представленная некоторой структурой данных. Дано также значение ключа x. Требуется проверить наличие в таблице записи с данным ключом, в случае отсутствия такой записи вставить ее в таблицу и в любом случае предоставить доступ к найденной или вставленной записи. Обратная операция, а именно удаление записи с заданным ключом, не будет подробно рассматриваться в данном пособии. Как правило, если известно, как добавляется новая запись, то нетрудно понять и как она должна удаляться. В некоторых случаях будут отмечены особенности операции удаления записей. Заметим еще, что алгоритмы поиска со вставкой делают фактически ненужной отдельную процедуру сортировки таблицы. Вместо того, чтобы сначала вводить данные в несортированную таблицу и затем выполнять их сортировку, можно начать с пустой таблицы и заполнить ее с помощью последовательной вставки всех необходимых элементов. Если время поиска и вставки одного элемента будет иметь оценку O(log(n)), то заполнение таблицы из n элементов займет время порядка O(n·log(n)), что сопоставимо с лучшими алгоритмами сортировки. Бинарные деревья поиска Напомним, что под бинарным деревом понимается такая структура данных, которая либо является пустой, либо состоит из вершины, называемой корнем дерева и связанной с двумя другими бинарными деревьями, называемыми левым и правым сыновьями корня. Мы будем рассматривать такие бинарные деревья, у которых с каждой вершиной связано значение этой вершины. Это значение может в общем случае состоять из поля ключа и поля данных, т.е. бинарное дерево можно рассматривать как иное представление таблицы, отличное от более привычного ее представления в виде массива. Как и раньше, мы для простоты будем считать, что значение вершины содержит только ключ. Бинарным деревом поиска называется такое бинарное дерево, у которого для каждой вершины A все значения вершин левого поддерева A не превышают значения A, а все значения вершин правого поддерева A не меньше, чем значение A. По-другому можно сказать, что бинарное дерево поиска – это такое дерево, при обходе которого слева направо значения вершин будут перечисляться в порядке возрастания. Поиск ключа по бинарному дереву имеет много общего с процедурой бинарного поиска в массиве. В том и другом случае после проверки на совпадение с искомым ключом одного из значений (раньше это было значение из середины массива, теперь – значение корня дерева) выполняется переход либо к меньшим, либо к большим значениям ключей. Разница в том, что вместо вычисления индекса следующего проверяемого элемента здесь просто выполняется переход либо к левому, либо к правому сыну проверенной вершины. Опишем структуры данных для представления таблицы в виде бинарного дерева.
type Tree = ^Node; {Дерево есть указатель на его корень} Node = record {Вершина дерева} key: KeyType; {Ключ} left, right: Tree; {Два сына (поддерева)} end;
Функция поиска по дереву со вставкой может в рекурсивном варианте выглядеть, как показано ниже.
function TreeSearch( var t: Tree; {Корень дерева} x: KeyType; {Искомый ключ} var found: Boolean {Найдено или вставлено? } ): Tree; {Возвращает указатель на вершину} begin if t = nil then begin {Вставка новой вершины} found: = false; {Не найдено, будет вставлено} New(t); t^.left: = nil; t^.right: = nil; t^.key: = x; TreeSearch: = t; end else if t^.key < x then TreeSearch: = TreeSearch(t^.right, x, found) else if t^.key > x then TreeSearch: = TreeSearch(t^.left, x, found) else begin {t^.key = x} found: = true; {Найдено! } TreeSearch: = t; end; end; {TreeSearch}
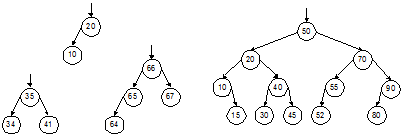
Пока значение ключа текущей вершины не равно искомому, функция выполняет спуск по дереву, переходя к левому или правому сыну вершины. Спуск заканчивается либо когда будет найден искомый ключ, либо когда очередное поддерево оказывается пустым. Это означает, что искомый ключ отсутствует в дереве и должен быть вставлен в соответствующем месте. Значением функции будет указатель на найденную либо вставленную вершину. Если функция выполнит вставку новой вершины, то исходное дерево изменится, однако оно сохранит свойства дерева поиска. Время работы функции определяется числом шагов спуска по дереву выполненных при поиске. Время выполнения вставки не зависит от размеров дерева, поэтому оно не повлияет на оценку в смысле O-большое. Максимальное число шагов спуска ограничено высотой дерева поиска. Как связана высота h с числом вершин дерева n? Это зависит от распределения вершин в дереве. Наиболее предпочтительным для поиска видом деревьев являются идеально сбалансированные деревья (ИС-деревья). Это такие бинарные деревья, у которых для каждой вершины количества вершин в ее левом и правом поддеревьях различаются не больше, чем на 1. Легко доказать, что длины всех ветвей ИС-дерева также различаются не более, чем на 1. Примеры ИС-деревьев поиска с разным числом вершин показаны на рис. 4.1.
Рис. 4.1. Примеры идеально сбалансированных деревьев поиска Нетрудно доказать, что ИС-дерево высоты h может иметь от 2h–1 до 2h – 1 вершин. Отсюда можно получить и обратную зависимость – оценку высоты для данного числа вершин: h £ log2n + 1. Получается, что время поиска по ИС-дереву имеет логарифмическую оценку: T(n) = O(log(n)), аналогично бинарному поиску в сортированном массиве. Проблема заключается в том, что сбалансированность дерева обеспечить трудно. Предположим, что на вход программы, строящей бинарное дерево поиска с помощью функции TreeSearch, поступает монотонно возрастающая последовательность ключей. Нетрудно видеть, что в этом случае каждая новая вершина будет включаться в дерево как правый сын предыдущей вершины, а левых сыновей в этом дереве не будет вовсе. Результатом будет крайне несбалансированное вырожденное дерево, по сути представляющее собой линейный список. Для вырожденного дерева его высота равна числу вершин, а стало быть, T(n) = O(n). Популярное:
|
Последнее изменение этой страницы: 2016-04-11; Просмотров: 1180; Нарушение авторского права страницы